
Table of Contents
Machine learning is at the peak of its popularity today. Despite this, a lot of decision-makers are in the dark about what exactly is needed to design, train, and successfully deploy a machine learning algorithm. The details about collecting the data, building a dataset, and annotation specifics are neglected as supportive tasks.
However, reality shows that working with datasets is the most time-consuming and laborious part of any AI project, sometimes taking up to 70% of the time overall. Moreover, building up a high-quality machine learning dataset requires experienced, trained professionals who know what to do with the actual data that can be collected.
Let’s start from the beginning by defining what a dataset for machine learning is and why you need to pay more attention to it.
What Is a Dataset in Machine Learning and Why Is It Essential for Your AI Model?
According to the Oxford Dictionary, a dataset definition in machine learning is “a collection of data that is treated as a single unit by a computer”. This means that a dataset contains a lot of separate pieces of data, but can be used to teach the machine learning algorithm to find predictable patterns inside the whole dataset.
Data is an essential component of any AI model and, basically, the sole reason for the spike in popularity of machine learning that we witness today. Due to the availability of data, scalable ML algorithms became viable as actual products that can bring value to a business, rather than being a by-product of its main processes.
Your business has always been based on data. Factors such as what the customer bought, the popularity of the products, seasonality of the customer flow have always been important in business making. However, with the advent of machine learning, now it’s important to collect this data into datasets.
Sufficient volumes of data allow you to analyze the trends and hidden patterns and make decisions based on the dataset you’ve built. However, while it may look rather simple, working with data is more complicated. It requires proper treatment of the data you have, from the purposes of using a dataset to the preparation of the raw data for it to be actually usable.
Splitting Your Data: Training, Testing, and Validation Datasets in Machine Learning
Usually, a dataset is used not only for training purposes. A single training set that has already been processed is usually split into several types of datasets in machine learning, which is needed to check how well the training of the model went. For this purpose, a testing dataset is typically separated from the data. Next, a validation dataset, while not strictly crucial, is quite helpful to avoid training your algorithm on the same type of data and making biased predictions.
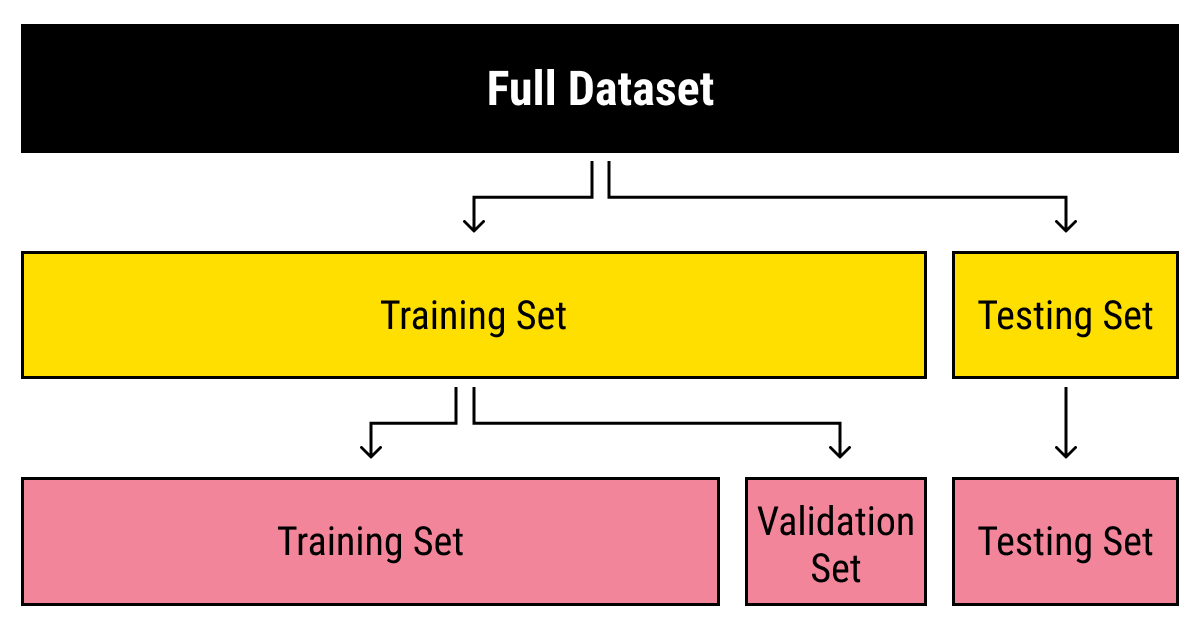
If you want to know more about how to split a dataset, we’ve covered this topic in detail in our article on training data.
Features of the Data: How to Build Yourself a Proper Dataset for a Machine Learning Project?
Raw data is a good place to start, but you obviously cannot just shove it into a machine learning algorithm and hope it offers you valuable insights into your customers’ behaviors. There are quite a few steps you need to take before your dataset becomes usable.
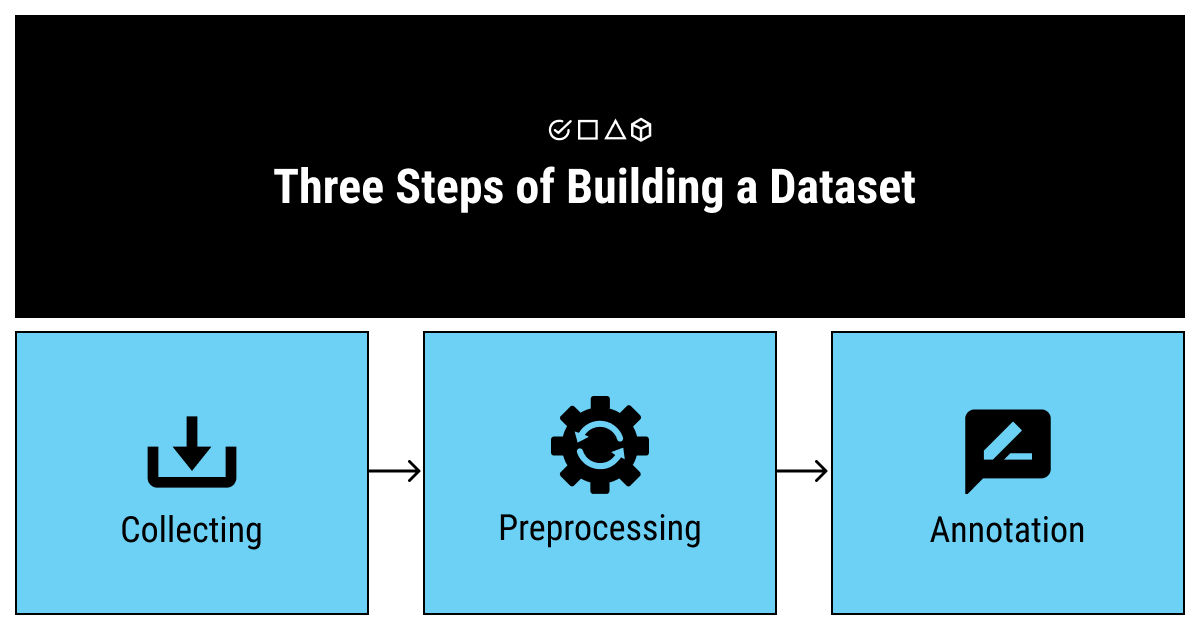
- Collect. The first thing to do when you’re looking for a dataset is deciding on the sources you’ll be using for data collection in ML. Usually, there are three types of sources you can choose from: the freely available open-source datasets, the Internet, and the generators of artificial data. Each of these sources has its pros and cons and should be used for specific cases. We’ll talk about this step in more detail in the next section of this article.
- Preprocess. There’s a principle in data science that every experienced professional adheres to. Start by answering this question: has the dataset you’re using been used before? If not, assume this dataset is flawed. If yes, there’s still a high probability you’ll need to re-appropriate the set to fit your specific goals. After covering the sources, we’ll talk more about the features that constitute a proper dataset (you can click here to skip to that section now).
- Annotate. After you’ve ensured your data is clean and relevant, you also need to make sure it’s understandable for a computer to process. Machines do not understand the data the same way as humans do (they aren’t able to assign the same meaning to the images or words as we). This step is where a lot of businesses often decide to outsource the task to experienced data tagging services, since keeping a trained annotation professional is not always viable. We have a great article on building an in-house labeling team vs. outsourcing this task to help you understand which way is the best for you.
Quest for a Dataset in Machine Learning: Where to Find It and What Sources Fit Your Case Best?

The sources for collecting an AI/ML dataset vary and strongly depend on your project, budget, and size of your business. The best option is to get help from professional data collection services that directly correlate with your business goals. However, while this way you have the most control over the data that you collect, it may prove complicated and demanding in terms of financial, time, and human resources.
Other ways like automatically generated datasets require significant computational powers and are not suitable for any project. For the purposes of this article, we’d like to specifically distinguish the free, ready-to-use datasets for machine learning. There are large, comprehensive repositories of public datasets that can be freely downloaded and used for the training of your machine learning algorithm.
The obvious advantage of free datasets is that they’re, well, free. On the other hand, you’ll most likely need to tune any of such downloadable datasets to fit your project, since they were built for other purposes initially and won’t fit precisely into your custom-built ML model. Still, this is an option of choice for many startups, as well as small and medium-sized businesses, since it requires fewer resources to collect a proper dataset.
The Features of a Proper, High-Quality Dataset in Machine Learning

However, before you decide on what sources to use while collecting a dataset for your ML model, consider the following features of a good dataset.
Quality of a Dataset: Relevance and Coverage
High data quality is the essential thing to take into consideration when you collect a dataset for a machine learning project. But what does this mean in practice? First, the data pieces should be relevant to your goal. If you are designing an ML algorithm for an autonomous vehicle, you will have no need even for the best of datasets that consist of celebrity photos.
Furthermore, it’s important to ensure the pieces of data are of sufficient quality. While there are ways of cleaning the data and making it uniform and manageable before annotation and training processes, it’s best to have the data correspond to a list of required features. For example, when building a facial recognition model, you will need the training photos to be of good enough quality.
In addition, even for relevant and high-quality datasets, there is a problem of blind spots and biases that any data can be subject to. An imbalanced dataset in ML poses the dangers of throwing off the prediction results of your carefully built ML model. Let’s say you’re planning to build a text classification model to arrange a database of texts by topic. But if you only use NLP datasets that don’t cover enough topics, your model will likely fail to recognize the rarer ones.
Tip: try to use live data and expert text annotation services. Fake data might seem like a good idea when you’re building your model (it is cheaper, cleaner, and is available in large volumes). But if you try to cut costs by using a fake dataset, you might end up with a weirdly trained algorithm. Fake data might turn out to be too predictable or not predictable enough. Either way, it’s not a great start for your AI project.
Sufficient Quantity of a Dataset in Machine Learning
Not only quality but quantity matters, too. It’s important to have enough data to train your algorithm properly. There’s also a possibility of overtraining an algorithm (known as overfitting), but it’s more likely you won’t get enough high-quality data.
There’s no perfect recipe for how much data you need. It’s always a good idea to get advice from a data scientist. Professionals with extensive experience usually can roughly estimate the volume of the dataset you’ll need for a specific AI project.
Before Deploying, Analyze Your Dataset

Alas, it is not sufficient to collect your dataset and make sure it corresponds to all the features we’ve listed above. There is one more step you need to take before starting the training of your ML model: analysis of the dataset.
There are cases that range from hilarious to horrifying about how strongly an ML algorithm depends on the exhaustive analysis of its dataset. One of such cases told by Martin Goodson, a guru of data science, shows the story of a hospital that decided to cut treatment costs for pneumonia patients. The highly accurate neural network that was built based on the clinic data could determine the patients with a low risk of developing complications. These patients could just take antibiotics at home without the need to visit the hospital.
However, when the model was considered for practical use, it was found that it sent all patients with asthma home even though these patients were actually at high risk of developing fatal complications. The problem was that human doctors knew this and always sent such patients to intensive care. For this reason, the historic dataset of the hospital had no recorded deaths for asthmatics with pneumonia, which resulted in the algorithm deciding asthma was not an aggravating condition. If employed in a practical setting, the algorithm would potentially result in human deaths, even though the dataset was relevant, comprehensive, and of high quality.
This case demonstrates that machines still cannot do the analytic work of humans and are merely tools that require supervision and control. When your dataset is collected, cleansed, annotated, and seems ready, analyze it before deploying the data as a training tool for your model.
In Summary: What You Need to Know About Datasets in Machine Learning
Collecting different types of datasets in machine learning might seem like an easy task that can be done in the background while you pour most of your time and resources into building the machine learning model. However, as practice shows, time and time again, dealing with data might take most of your time due to the sheer scale that this task might grow to. For this reason, it’s important to understand what a dataset in machine learning is, how to collect the data, and what features a proper dataset has.
A machine learning dataset is, quite simply, a collection of data pieces that can be treated by a computer as a single unit for analytic and prediction purposes. This means that the data collected should be made uniform and understandable for a machine that doesn’t see data the same way as humans do. For this, after collecting the data, it’s important to preprocess it by cleaning and completing it, as well as annotate the data by adding meaningful tags readable by a computer.
Moreover, a good dataset should correspond to certain quality and quantity standards. For smooth and fast training, you should make sure your dataset is relevant and well-balanced. Try to use live data whenever possible and consult with experienced professionals about the volume of the data and the source to collect it from.
Following these tips won’t guarantee you collect a perfect dataset for your ML project. However, it will help you avoid some major pitfalls on your way to success.
Besides, if you’re looking for a trusted partner, give us a call, and we’ll gladly help you with dataset collection for machine learning and annotation!
FAQ
What is dataset analysis in ML?
Dataset analysis in machine learning involves inspecting, cleansing, transforming, and modeling data with the aim of discovering useful information by informing conclusions and supporting decision-making. A dataset is analyzed for further training of an ML algorithm.
Why is the dataset important in ML?
The dataset lays the groundwork for machine learning, shaping the model’s ability to learn and make accurate predictions. First, a dataset allows you to train your ML model, and, second, it provides a benchmark for measuring the accuracy of the model.
What is the purpose of the datasets?
ML datasets are used to provide organized and structured collections of data that enable advanced algorithms to learn patterns, make predictions, and give meaningful insights. For instance, a medical dataset holds information, such as medical records or insurance records, and it can be used by a program running on the system.
Table of Contents
![]() Get Notified ⤵
Get Notified ⤵
Receive weekly email each time we publish something new: