
Table of Contents
I bet you're already tired of hearing that AI is one of the defining trends of the century and arguably the primary focus on high-tech professionals. However, this seems to be true enough. The self-isolation mode of the COVID-19 has distilled the major issues modern civilization faces and has shown us that artificial intelligence is capable of dealing with the problems that can make our lives easier, more convenient, and much more comfortable.
Yet it's always worth remembering that a solution to any problem doesn't come without sufficient efforts put in. For AI, the efforts are concentrated in the careful, thoughtful design of the machine learning models and even more so in the process of creating high-quality training data. The latter is probably the single most overlooked sphere, where the mistakes made often lead to failures and inadequate reactions from smart algorithms.
What Is Training Data in Machine Learning?
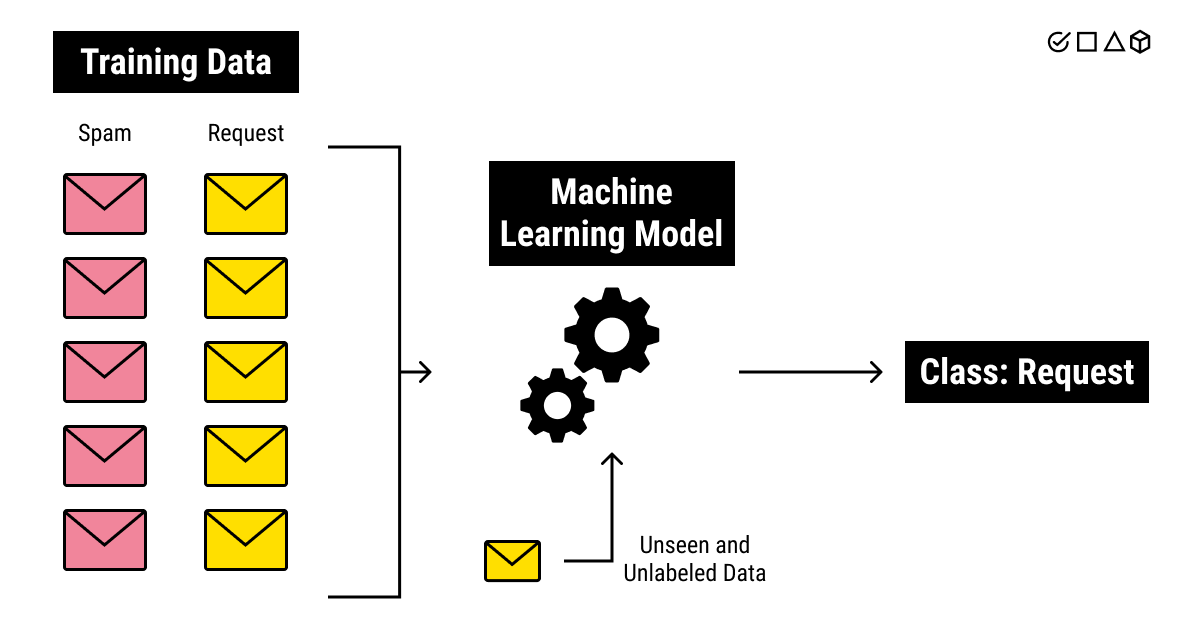
We'll be answering the question of what do we use training data for in machine learning. But first, let us get a proper understanding of what training data is.
Training data is a set of samples (such as a collection of photos or videos, a set of texts or audio files, etc.) with assigned relevant and comprehensive labels (classes or tags) used to fit the parameters (weights) of a machine learning model with the goal of training it by example. Click to TweetThis means that training datasets are an essential part of any ML model. They are necessary to teach the algorithm how to make accurate predictions in accordance with the goals of an AI project.
Just like people learn better from examples, machines also require them to start seeing patterns in the data. Unlike human beings, however, computers need a lot more examples because they do not think in the same way as humans do. They do not see objects in the pictures or cannot recognize people in the photos as we can. They speak their own, programming languages that are structured in a different way. They require substantial work and a lot of data for training a machine learning model to identify emotions from videos.
When you teach a child what a cat is, it's sufficient to show a single picture. If you try teaching a computer to recognize a cat, you'll need to show thousands of images of different cats, in different sizes, colors, and forms, in order for a machine to accurately tell a cat from, say, a dog.
On the other hand, when an ML model is sufficiently sophisticated, it can deliver more accurate results than a human. This may feel counterintuitive but it also has to deal with the differences in how we and the machines process information.
But we'll talk about that a bit later. For now, let's take a dive into other important concepts like testing data, different types of data, and methods of machine learning.
Splitting Your Data Set: Training Data vs Testing Data in Machine Learning
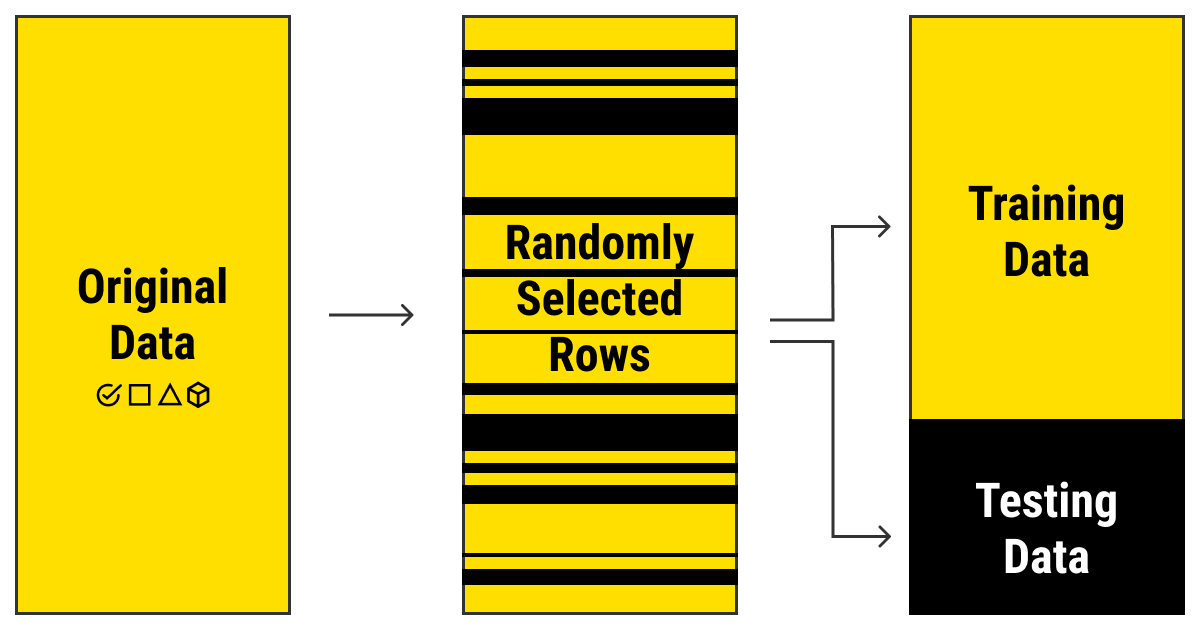
Now here's another concept you should know when talking about training ML models: testing data sets. Training data and test data sets are two different but important parts in machine learning. While training data is necessary to teach an ML algorithm, testing data, as the name suggests, helps you to validate the progress of the algorithm's training and adjust or optimize it for improved results.
In simple words, when collecting a data set that you'll be using to train your algorithm, you should keep in mind that part of the data will be used to check how well the training goes. This means that your data will be split into two parts: one for training and the other for testing.
There are different methods for splitting the dataset, the most common following the Pareto ratio of 80:20 or sometimes 70:30.
There are, of course, more sophisticated splitting methods but usually, the simple 80:20 ratio suffices. There's one more thing to remember: splitting should be randomized unless you want to end up with imbalanced, biased data full of blind spots. Surely, there are a number of problems with randomized splitting, as well, yet, for many ML problems, it will do the job just fine.
Machine Learning with Training, Test, and… Validation Data?
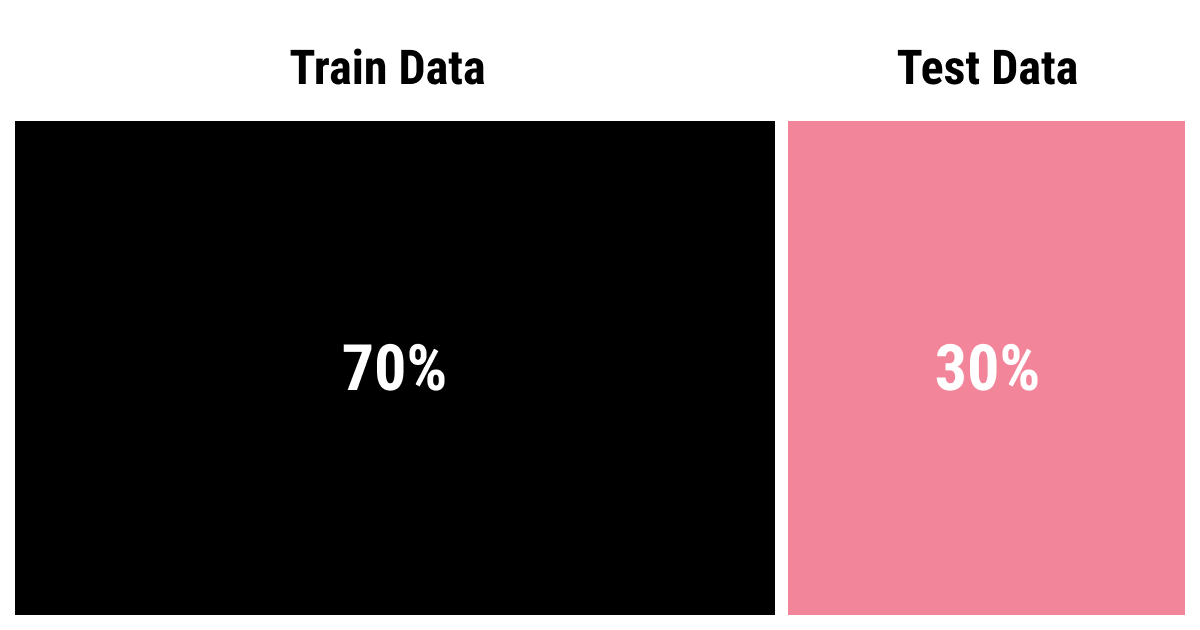
Okay now, what is this new beast? Well, you see, you can do away with just the testing and training data in machine learning. But if you do that, you risk dealing with the errors that your algorithm made by trying to improve during the training process, the errors that your testing data set will surely show.
Adequate training requires the algorithm to see the training data multiple times, which means that the model will be exposed to the same patterns if it runs over the same data set. To avoid this, you need a different set of data that will help your algorithm to see different patterns. But at the same time, you don't want to involve your testing data set before the training ends since you need it for different purposes.
So what do you do? The obvious answer is splitting your data set again, this time only taking the training data and allocating a part of it for validation. This validation will help your model fill in the blind spots it could've missed earlier and improve faster.
But you've already split your data set into training and testing data, didn't you? How do you split it again? Most commonly, it's 80:20 (or 70:30) principle again, just like before.
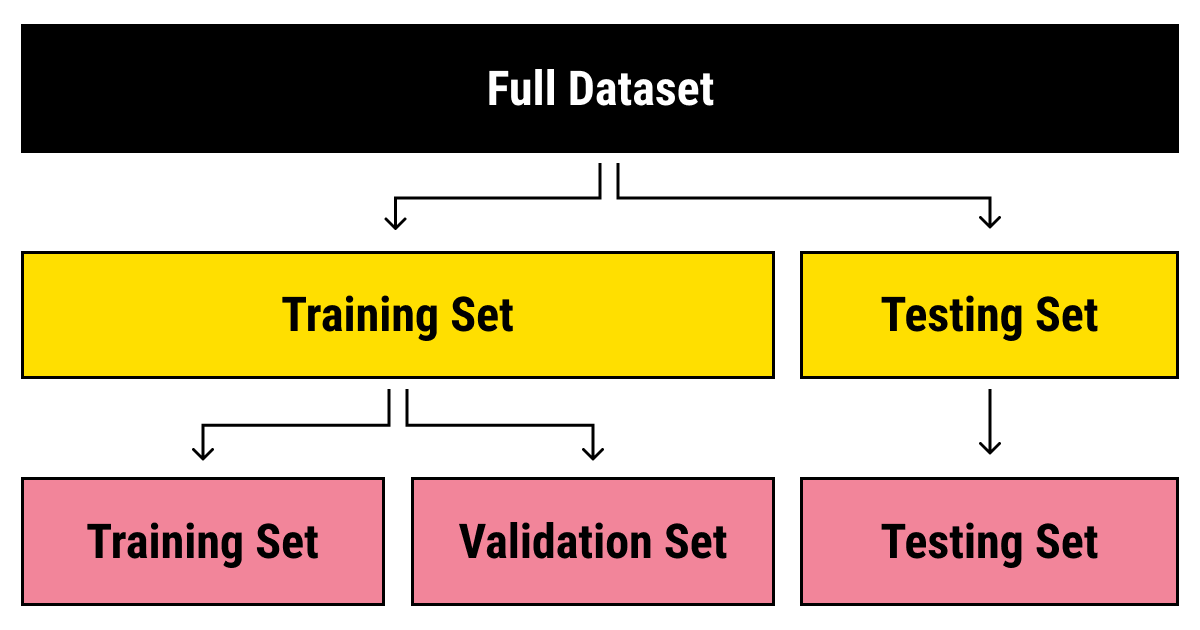
This way, you end up with three data sets each suited for its own purpose.
Where to Get Training Data?

Before we unpack how training data is used in machine learning, let's make a short detour to see where to look for it. There are quite a few different sources to get the training data sets from, and the choice of these sources depends on your goals, the requirements of your machine learning project, as well as your budget, time, and personnel restrictions.
- Open-source training data sets. This might be an acceptable solution if you're very lucky or otherwise for smaller businesses and start-ups that don't have enough free resources to spend on data collection and labeling. The great benefit of this option is that it's free and it's already collected. But there's a catch (isn't there always?): such data sets were not initially tailored for your algorithm's specific purposes but for some other project. What this means for you is that you'll need to tweak and probably re-annotate the data set to fit your training needs.
- Web and IoT. This is a very common way of collecting training data sets that most middle-sized machine learning companies use. This means that you use the Internet to collect the pieces of data. Alternatively, sensors, cameras, and other smart devices may provide you with the raw data that you will later need to annotate by hand. This way of gathering a training data set is much more tailored to your project because you're the one collecting and annotating the data. On the downside, it requires a lot of time and resources, not to mention the specialists you know how to clean, standardize, anonymize, and label the data.
- Artificial training data sets. This is the way that starts to gain traction in recent years. What it basically means is that you first create an ML model that will generate your data. This is a great way if you need large volumes of unique data to train your algorithm. It is sparing in terms of financial and personnel resources as it only needs to spend them on designing the model to create your data. Still, this method of collecting training data requires a lot of computational power, which is not usually in free access for small and middle-sized businesses. Besides, if you need truly vast amounts of data, it will take some time to generate a voluminous high-quality training data set.
Families of Machine Learning Methods and How They Rely on Training Data
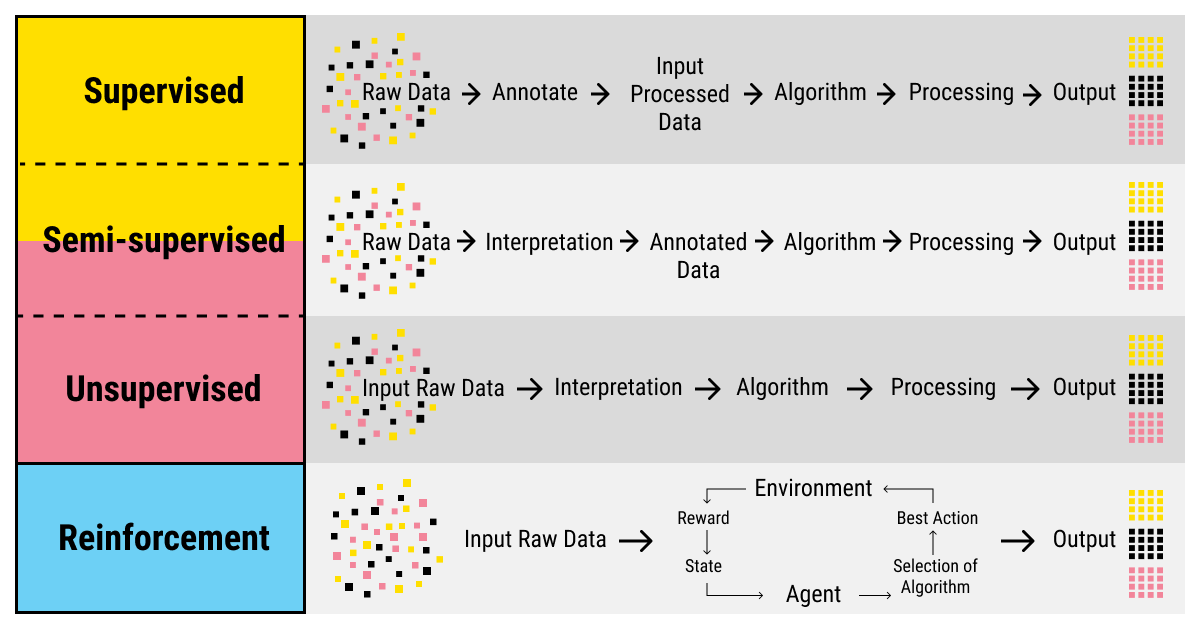
Now that we've set the essentials of training data straight along with learning some basic vocabulary and the sources to scout for training data, let's take a look at the methods of machine learning. There are two large families of methods of machine learning, and training data holds a different place in each of them (for the purposes of this article, we'll skip the reinforcement learning methods since such models in their basic form don't require any training data).
Unsupervised Learning and Training Data
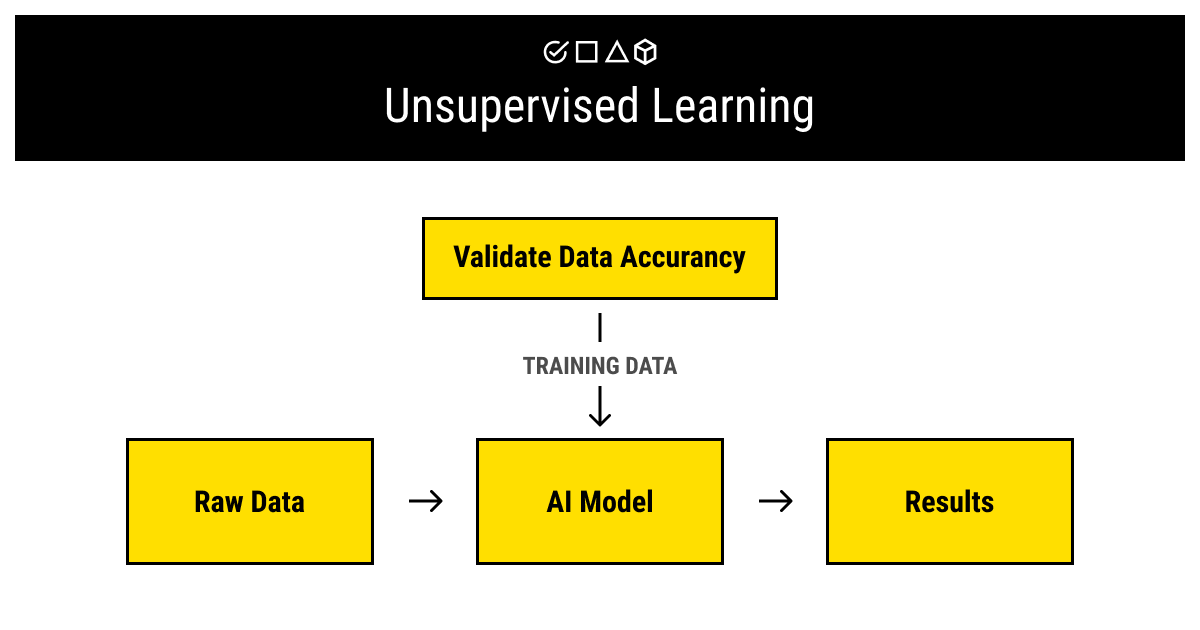
Unsupervised learning is a family of ML methods that uses unlabeled data to look for the patterns in the raw data sets. Unlabeled data is the unprocessed data that doesn't have any meaningful tags or labels that a machine can use for training. We've covered this topic in detail a while back in our article on unlabeled data.
As you've probably guessed, unsupervised ML doesn't really use training data since, by definition, it's machine learning without training data. It relies on the raw data without any labels to perform tasks like clustering or association. So why do you need to know about it? Because, even for unsupervised methods of ML, it's useful to have a (comparatively) small amount of labeled data for validation and testing of the results of your unsupervised ML model. Trust us, it'll make your life that much easier.
Supervised Learning and Training Data
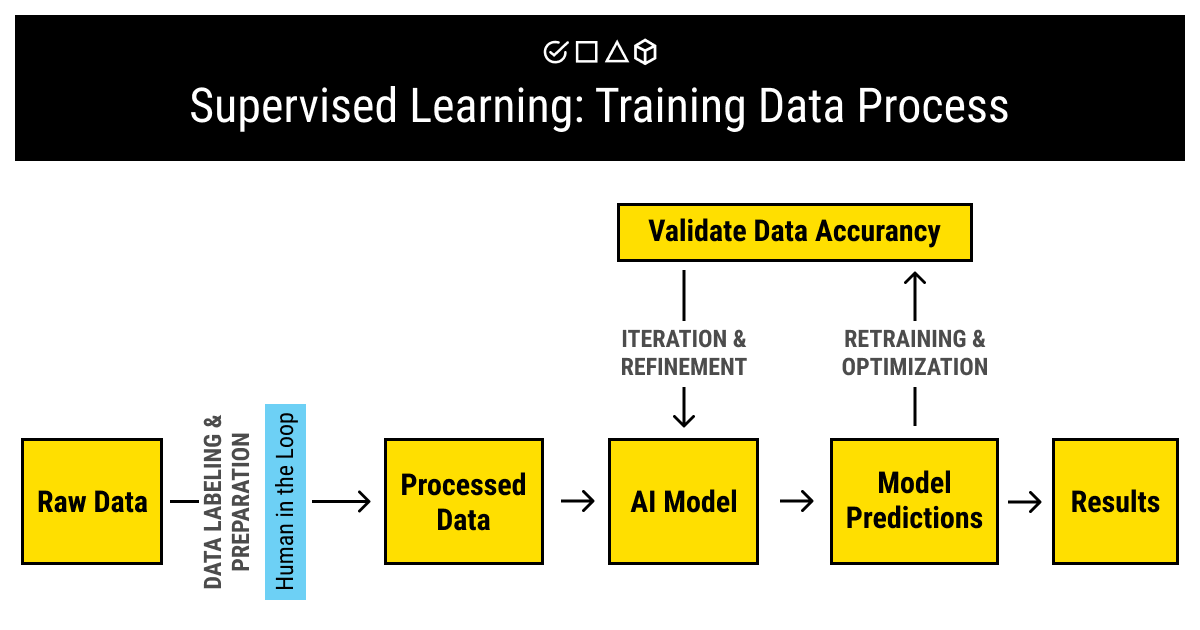
Supervised learning is another big family of ML methods. It relies on labeled data, which is the data that has been assigned with relevant labels during the process known as annotation or labeling. You can learn more about labeled data and supervised learning in the dedicated article. You can also give a read to our piece on the process of labeling data for machine learning.
In a nutshell, supervised learning relies on supervision, obviously, which means there must be a human to enable and observe its progress. This approach is often referred to as human-in-the-loop.
Human-in-the-Loop and The Quality of Training Data
There are a number of tasks for the human experts to handle before starting to train a supervised learning algorithm. Their main goal is to get you not just any training data set but the one that will be of high quality and relevant to the mission of your project:
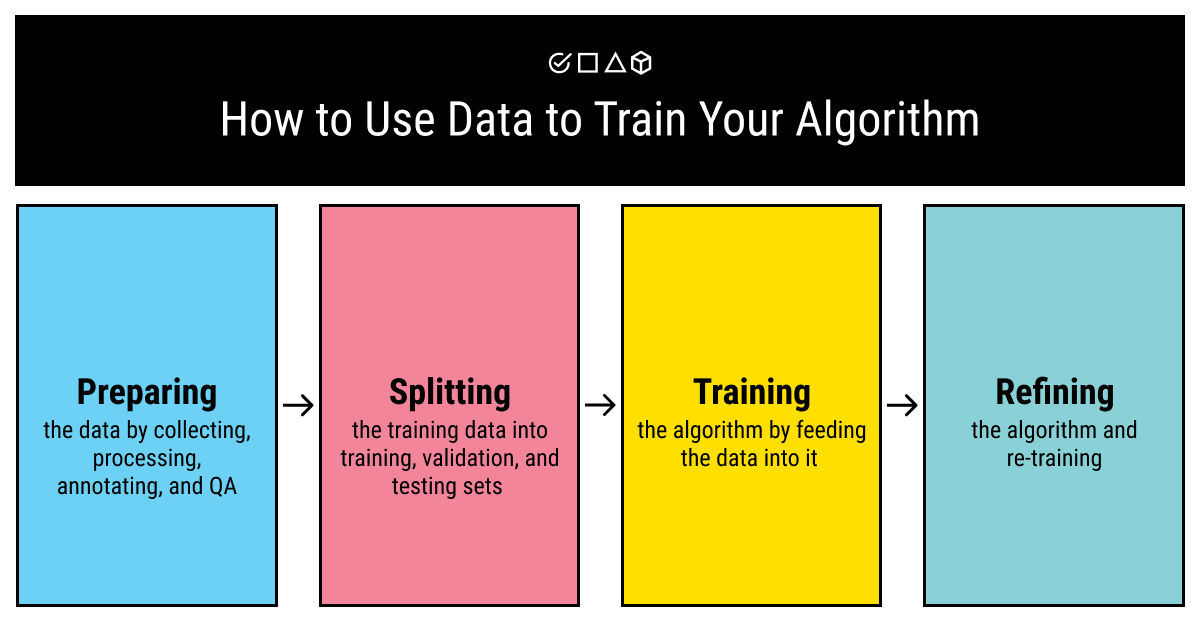
- Collect the data. To train your model, you'll need to gather the raw data that will further be processed. There are a few requirements to take into consideration when you collect the data: it should be high-quality, relevant, comprehensive, and (preferably) big. Why do these requirements matter? Because you don't want to end up with a machine learning model that you cannot give an order to your training data did not cover. There's quite a debate going on about which of the requirements to prioritize. If you want to know more about it, click here.
- Prepare the data. When you've collected your data that is relevant to your goals and ticks all the important boxes on the requirements list, it's time to make it manageable, as well as make sure that it will cover every possible case your model will have to deal with in the future. This means your human experts will need to improve the data by:
- cleaning it
- removing duplicate values present
- reformatting it to fit the desired file formats
- anonymizing if applicable
- making it normalized and uniform
For more information on this step, you can read this excerpt.
- Annotate the data. Some prefer to include this step into the previous one but we are experts at what we do and as such believe that labeling is a complex process that deserves separate attention. If you want your model to train well, it's important for the labels assigned to your data to be consistent and of high quality (go here if you want to know why).
- Analyze the data. This is the final step that is rarely separated from the rest since it is about the training data quality control. It goes without saying that lack of QA can double your work. It's essential to find all the small bugs that plague your project at the earliest possible stages, and the same goes for the preparation of your training data sets. It's better to spend some time when you collect and annotate your data rather than start the training from scratch.
As you can see, the process of getting yourself a training data set for a supervised learning algorithm is rather complex. Moreover, in data science, getting a proper training data set usually takes up the majority of the time. We at Label Your Data specialize in data annotation but we can also help you collect the data and we'll definitely have a QA round to make sure the percentage of mistakes is as low as possible.
If you don't want to collect and annotate the data yourself, don't have the capacity, don't know how to test the accuracy of your training data, or just don't want to deal with all that, think about outsourcing the whole deal. Just beware of the security issues that might arise: it's important to ensure that treatment and management of your training data comply with the data privacy regulations and standards. The best advice is to choose a trusted partner. If you wish to step up your game and make sure your project is handled by professionals, just give us a call.
Semi-Supervised Learning and Training Data
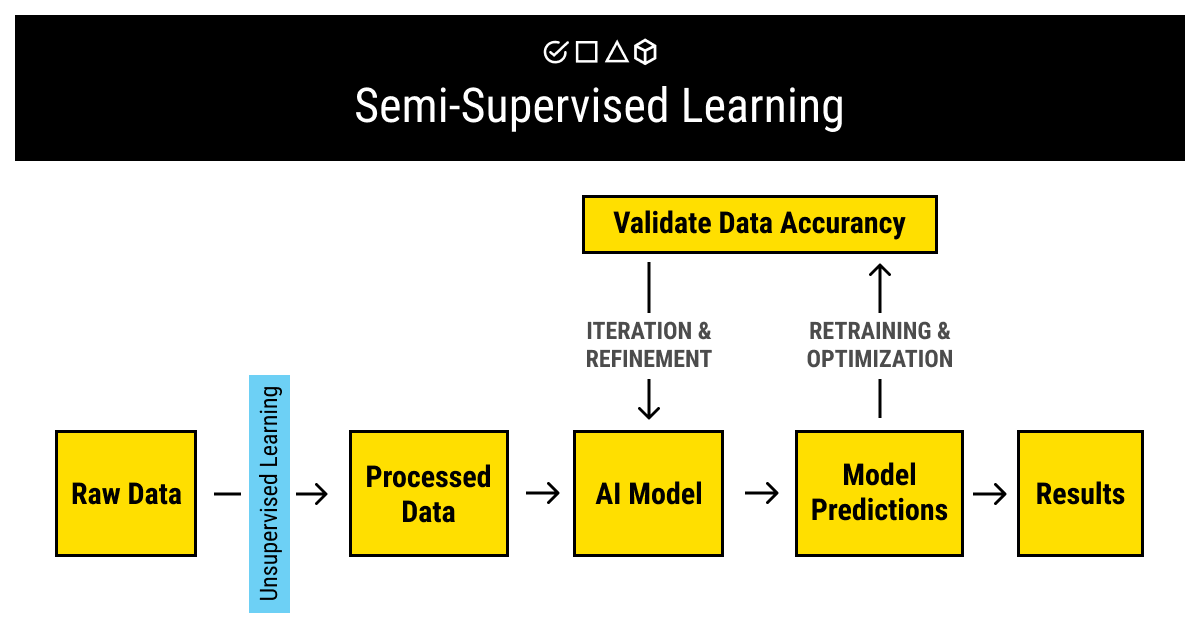
Labeled data provides a great basis for training an ML algorithm. However, the process of collecting, labeling, and refining the data may be overwhelming — not to mention, expensive in terms of cost, human resources, and time. What if you had a way to dramatically reduce the involvement of the humans in the loop?
Enter semi-supervised learning, which is not a separate family of ML methods, strictly speaking, but a hybrid between unsupervised and supervised learning. It utilizes both unlabeled and labeled data and combines the methods to improve the data accuracy and reduce the time of training of an algorithm.
The models of semi-supervised learning require a small amount of labeled data, which can be used to annotate the much larger volume of raw, unlabeled data using unsupervised learning methods. After the unlabeled data are annotated this way, you can proceed to train your ML algorithm as intended.
Semi-supervised learning is still reliant on labeled data and, as such, human annotators who can provide it. However, the volume required is significantly smaller, which increases the efficiency of the annotating and training process.
Diving In: Deep Learning with Training Data
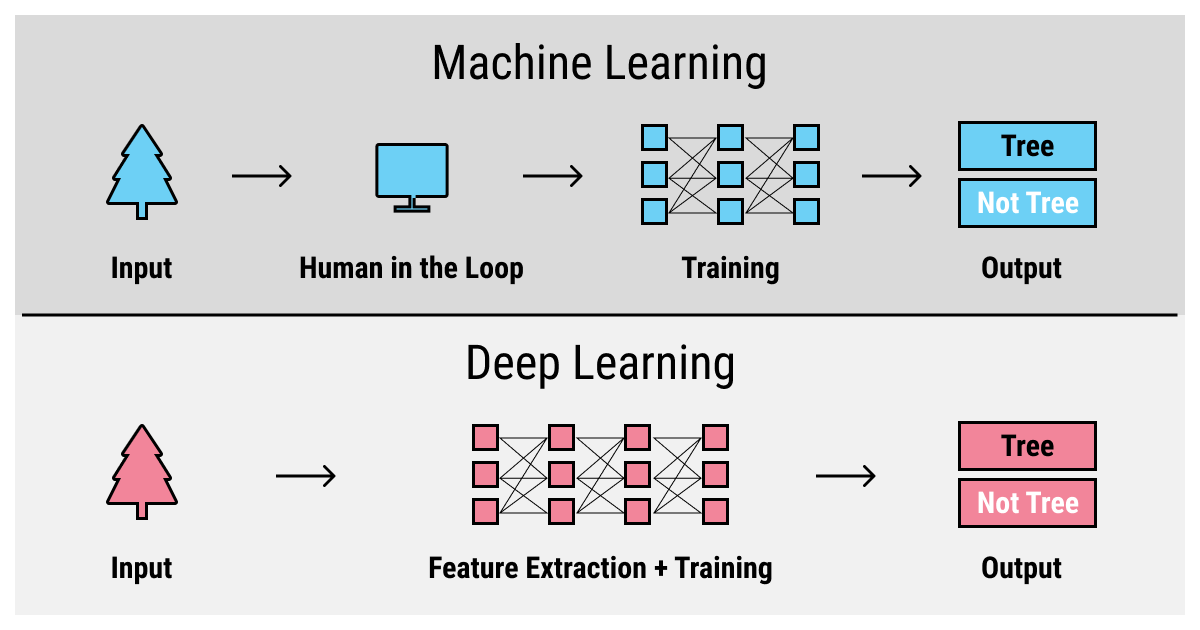
Today, “deep learning” became the expression that you probably hear even more often than “machine learning”. The big sell of deep learning is its performance when compared to other machine learning algorithms.
The efficiency and accuracy of deep learning algorithms are attributed to its ideological roots of the functioning of neural networks of a biological brain. Actually, the naming is quite misleading since an artificial neural network (ANN) and a biological one are very different from each other. But they both function on the similar principle of communication nodes.
The “deep” part in “deep learning” refers to the multiple layers that are connected by these nodes. This allows a deep learning algorithm to solve several tasks where other, linear machine learning algorithms are dedicated to solving just one. If you wish to know more about deep learning, we've recently published a big article on it, where we dive into the details of the topic.
What you should keep in mind is that the ability of deep learning algorithms to outperform other ML algorithms is dependent on the amount of training data they have. Your new, fancy model may have the best algorithm out there but it will not help you build MVP without enough training data to actually make it smart.
It's no secret that big data as a concept has gained a lot of traction in recent years. Today, it's widely accepted that more data means better, more accurate predictions. But how much exactly is it? Let's try to answer the question that has no correct answer: how much data to collect for training and testing of your machine learning model?
How Much Training Data Is Enough?
The short answer is, there is no correct answer. The slightly longer answer: every specific project will require a different amount of training data, and the only way to know how much you'll need is by trial and error.
There are a few very broad guidelines that might help you get a basic idea about why this question has no answer:
- Usually, more sophisticated models with more attributes and links between them (like the ANNs) will require more data to train properly.
- The scope of application along with the complexity of the real-life phenomena that your model is being trained to predict also plays a role in how much training data will be needed. Beware of the exceptions and blind spots.
- With time, you will likely need to re-train or tweak your model as the trends that it predicts change, which will require more data in the long-term.
As you can see, a lot of factors play into the understanding of how much training data is enough. As a rule of thumb, experienced engineers have at least a general idea about the amount of data that will suffice to train your model. You should start listening to them, and then get more training data as you go.
Not that you know that you need a lot of training data that is relevant and high-quality, let's take a look at where to find the data you need.
You Got Yourself a Training Data Set… What's Next?
At this point, you've chosen the preferred way to collect the training data, made sure that it is of high quality and right volume, that it's correctly processed and labeled, and split into training and testing data sets. You also have your machine learning model at the ready. Now it's time to put your training data to good use. Yet beware: there are still pitfalls you want to avoid.
Overfitting or Underfitting: Don't Abuse Your Training Data
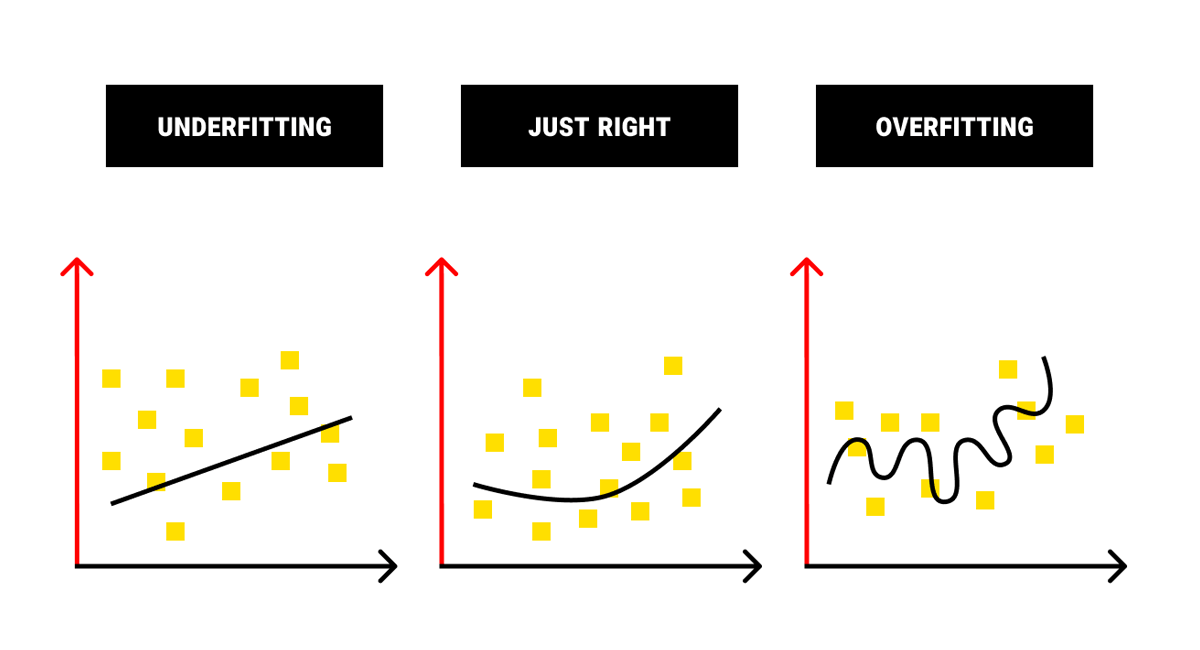
How do you train a machine learning model? As a rule of thumb, you take your training data in small batches and feed it to your algorithm. A time period marked by feeding the whole of your training data set to the model is known as an epoch.
You'll need to repeat the process to start seeing at least half-decent results from your algorithm. If you don't repeat this process enough, you'll face a phenomenon known as underfitting, which results in low accuracy of machine learning predictions.
One might think the more the better but it's not the case this time. If you overtrain your model, you'll fall victim to overfitting, which will lead to the poor ability to make predictions when faced with novel information. And this extreme is dangerous because, if you don't have your backups, you'll have to restart the training process from the very beginning.
Final Steps: Testing, Tuning, and All That Jazz
After you've trained your machine learning model, it's time to use the 20% you've saved from your training data set to test it. This is your chance to fine-tune your model and make sure it works as intended. Do not be discouraged if it doesn't: we're yet to see a case with no hitches on the initial stages of model building.
Moreover, be prepared that you'll need to tweak and refine your machine learning model even after it goes live. Any algorithm is akin to a living organism: it needs to be fed and cared for in order to work properly and deliver the best results. Treat it well, and it'll respond by giving you the accurate predictions you've worked so hard to get.
This Was a Long One; Let's Recap
Sometimes you just don't have the time for long-read articles. Here's a TL;DR where we summarize the most important points that you should know about training data.
- Training data is an essential element of any machine learning project. It's preprocessed and annotated data that you will feed into your ML model to tell it what its task is.
- Aside from training data, you'll need testing data, which you can take out of the initial data set by splitting it 80:20. You can also split the training data to make a validation set.
- Collecting training data sets is a work-heavy task. Depending on your budget and time constraints, you can take an open-source set, collect the training data from the web or IoT sensors, or build a machine learning algorithm to generate artificial data.
- Your model requires proper training to make accurate predictions. If you want it to be able to tell trees and people apart, you'll need to show it pictures of trees, photos of people and then tell which is where. This is also known as supervised learning.
- You can do without annotated data if you build an unsupervised machine learning model. However, its capabilities will be limited, and training data still would be great for the purposes of testing the accuracy of your model.
- The middle ground between supervised and unsupervised, semi-supervised machine learning requires training data but in much smaller quantities. This allows such models to have the flexibility of supervised models while saving a lot of time and resources on annotating the data.
- Deep learning requires a lot of training data. There are no strict rules as to how much training data is enough. It depends on a variety of factors including the complexity of your machine learning model, the nature of the real-world phenomenon you want to predict, and the need to update the model in the future.
- After you've collected, processed, and annotated the training data, you use it to train your model. Make sure not to undertrain (underfitting) or overtrain (overfitting) your algorithm unless you want inaccurate or irrelevant predictions.
- Keep in mind your work doesn't stop after you've trained your machine learning algorithm. Fine-tuning and maintenance of the model is a non-stop task.
As you can see, training data is one of the central components of any machine learning project. If you have a model (or even an idea) but don't have a clue how to collect and annotate a training data set, contact us. We'll help you get high-quality, relevant, and big training data to fit your purposes!
Table of Contents
![]() Get Notified ⤵
Get Notified ⤵
Receive weekly email each time we publish something new: