OCR Deep Learning: The Curious Machine Learning Case

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- What’s Deep Learning?
- A Few Problems for Deep Learning to Solve
- The Basics and Challenges of OCR in Machine Learning
-
Deep Learning and OCR Models: The Mechanics
- The Steps of an OCR Deep Learning Model
- Deep Learning OCR with a Convolutional Recurrent Neural Network (CRNN)
- Attention Mechanisms and Transformers in OCR Algorithms: Why Add Them to Your Neural Nets?
- RAM and DRAM: Recurrent Attention Models in Deep Learning OCR
- Datasets to Use in an OCR Deep Learning Project
- What About Annotation for OCR? Here’s How Label Your Data Can Help
- About Label Your Data
- FAQ

TL;DR
- Use deep learning techniques like CNNs and RNNs for effective OCR solutions.
- Preprocess input images thoroughly to simplify them, detect edges, and define text outlines for better OCR performance.
- Apply attention mechanisms or transformers to improve text detection and recognition in OCR models.
- Train your OCR model using the right datasets (e.g., MNIST, SVHN) to ensure it handles complex tasks like noisy or varied text.
- Consider outsourcing data annotation for OCR projects to save time and resources while ensuring high-quality results.
What’s Deep Learning?

Deep learning is a subset of machine learning that includes a family of methods most commonly built on the principle of neural networks inspired by the functioning of a human brain.
The “deep” in “deep learning” refers to the multiple number of layers that are used to perform separate tasks, which corresponds to the structured nature of neural networks. This means that a complex task can be completed by a single trained model, which would not be possible with a linear algorithm.
For example, image recognition is a common example of deep learning in action. The lowest layer identifies the edges of an object of interest, while the highest layers recognize and classify the relevant objects, such as human faces. In OCR, the lower layers of a neural network may similarly identify the edges of letters, but it’s the work of the higher layers to make sense of the words. But we’ll get there; let’s take one step at a time.
OCR using deep learning involves the use of neural networks to provide a new spin on the old problem and revive the interest of both business owners and ML engineers.
Is Deep Learning Different from a Neural Network?
Artificial neural networks (ANNs, also referred to simply as neural networks) are the most common foundation for deep learning, but they’re not synonymous. ANNs consist of:
- neurons (processors) aggregated into layers;
- edges (transmitters) that are loosely based on biological neurons and synapses.
The edges pass the signals between neurons, and the system of weights controls the strength of the signals. The weights change as the training of the model continues, which enables the process of learning.
Although ANNs are inspired by the biological brains, the architectural similarity is rather vague. There are a variety of differences between an organic and an artificial brain (for example, our brains are analog; ANN, however, is symbolic). And while ANNs are naturally less complex than biological neural networks, they are quite effective at the tasks they were designed to solve.
A Few Problems for Deep Learning to Solve
There are quite a few real-life applications for deep learning aside from OCR that make this family of methods so popular today. We’ll tell you about a few of them, just to give you the general idea about what neural networks can do.
Image Recognition with Deep Learning
From simple image classification to facial analysis to medical scans analysis, image recognition is among the essential deep learning tasks. With the multiple layers at the models’ disposal, it’s possible to work in a variety of spheres that can be problematic even for people. Deep learning also extends to complex fields like geospatial annotation, where neural networks help identify, classify, and interpret geographic features from satellite images, supporting applications in mapping and spatial analysis.
Neural Networks for Speech Recognition
Another traditional set of tasks that deep learning solves best is automatic speech recognition. Virtual assistants such as Siri, Alexa, Google Now, and Cortana all have the core based on deep learning architectures. The technology keeps evolving by covering larger vocabularies, recognizing accents and dialects, and improving interpretation.
Customer Relationship Management Using Deep Learning
While most of the deep learning models are based on supervised machine learning, certain tasks require other forms of ML. CRM offers a few tasks that are best solved with the adoption of deep reinforcement learning. It allows predicting the value of marketing strategy steps for a long-term period, a feat that would be impossible without the utilization of deep learning.
The Basics and Challenges of OCR in Machine Learning
Now, let’s briefly discuss what OCR using machine learning is and how it works. If you’ve already seen one of the articles on automation with OCR algorithm, feel free to skip this section.
In a nutshell, OCR is recognizing the text from an analog image source and transforming it into a digital copy that could be easily stored, managed, and edited. Imagine that you attended a business meeting, and each of the potential partners presented you with their business cards. Would it be easier to show each of these cards to a scanner that would automatically add the essential info to your phone book, or enter each piece of this dataset manually? No need to answer, that was a rhetorical question ;)
Despite the high utility of OCR and machine learning, the ever-increasing scale of tasks included in such models presents a significant challenge to the ML engineers. First, it’s a complex task as it exists on the verge of two fields of AI:
- Computer Vision (CV), which trains the ML models to see and interpret the visual world in a way similar to how people see and interpret it;
- Natural Language Processing (NLP) that deals primarily with text and speech-to-text transcription data and is focused on teaching machines to understand human speech.
This means that the OCR models need to perform a set of smaller-scale tasks often relying on data annotation for training accuracy, starting with image recognition of the letters and finishing with the interpretation of the final texts.
The OCR problems become more complex when the texts that need to be recognized are found in natural environments (for example, license plates on cars, street signs, random graffiti on the buildings or handwritten shopping lists). An additional layer of complexity appears in cases when the algorithm is required not only to transform the text into a digital copy, but also to interpret the specific data that the text contains.
While OCR was solved by a variety of methods from contour detection to image classification, these methods perform best for the template-based text patterns that have comparable text size and font, image quality, and location of the text. That’s to say, such methods aren’t effective for large-scale, heterogeneous texts.
Given the multiplicity of small tasks that aggregate into an OCR project and the diversity of both text features and applications, deep learning obviously becomes the primary choice for the ML engineers for designing an optical character recognition algorithm.
Deep Learning and OCR Models: The Mechanics
As deep learning evolves, the problem of OCR receives more solutions. At the moment, there are a lot of ways to achieve the goal of transforming an analog text into digital form. We’ll be looking at several of the most interesting ones.
But first, let’s outline the scope of the OCR tasks and the main OCR implementations.
The Steps of an OCR Deep Learning Model
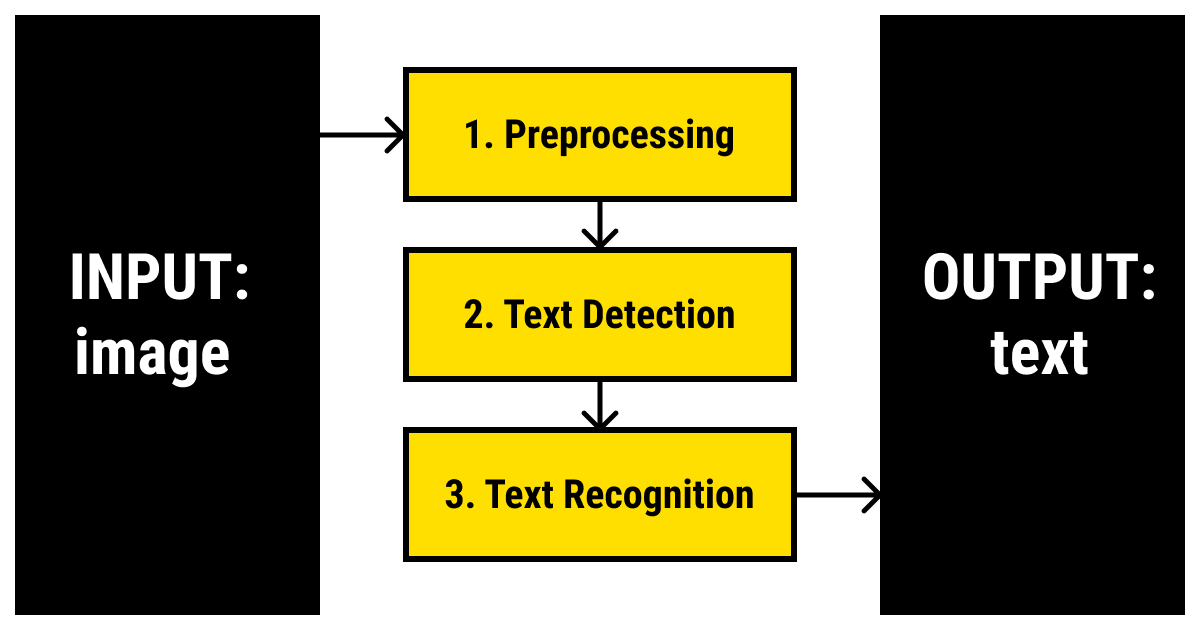
Any OCR algorithm includes three basic steps:
- Preprocessing an input image. This OCR step includes simplification, detection of meaningful edges, and defining the outline of the text characters. This is a common step for any task that has an image recognition component in it. If you’re interested, we’ve discussed a similar approach in more detail in our article on image recognition.
- Detection of the text. This step of an OCR project requires drawing a bounding box around the pieces of text found on the image. A few of the legacy techniques used for this step include SSD, real-time (YOLO) and region-based detectors, sliding window technique, Mask R-CNN, EAST detector, etc. You can read more on some of them in this article. (ML models for image recognition don't perform well for OCR due to text’s unique features.)
- Recognition of the text. The final OCR step is to recognize the text that was put in the bounding boxes. For this task, one or a combination of convolutional and recurrent neural networks and attention mechanisms is frequently used. Sometimes this step may also include the interpretation step, which is characteristic for more complex OCR tasks like handwriting recognition and IDC.
We won’t be talking about the process of building an OCR model, as we’ve already covered that in detail in our article on OCR. Instead, let’s focus on the latter two steps of text detection and text recognition that are quite specific for OCR tasks, and see how OCR using deep learning works.
Deep Learning OCR with a Convolutional Recurrent Neural Network (CRNN)
This method follows the two steps after the images were preprocessed for OCR:
- Convolutional neural network (CNN) to extract the features;
- Recurrent neural network (RNN) to predict the location and value of the text characters.
CNNs are one of the best techniques to use for deep learning based on OCR for the step of text detection. Convolution layers are commonly used for image classification tasks due to their efficiency in feature extraction. They allow detecting the meaningful edges in an image and (on a higher level) shapes and complex objects. Compared to fully-connected layers, for example, convolutional layers decrease the complexity of an OCR algorithm by reusing the pattern-detection filters throughout an image.
RNNs are used next to identify the relationship between the characters. Recurrent networks are great at processing the sequences of inputs that have variable lengths, such as speech recognition or unstructured text (e.g., handwriting recognition for OCR). Most commonly, long short-term memory (LSTMs) cells are used to avoid the vanishing gradient problem.
If you’re interested to see how this works in practice, here’s a curious example of a deep learning CRNN architecture designed with an OCR goal in mind.
Attention Mechanisms and Transformers in OCR Algorithms: Why Add Them to Your Neural Nets?
Additions to CRNN models can be used to improve the prediction of the text in the input images. One such popular addition is an attention mechanism that is commonly added to optical character recognition algorithms to create attention-OCR models.
Attention was initially introduced for the neural machine translation approach. It’s used to predict the target text units based on the context vectors, as well as previously-generated target data pieces. Attention vector allows evaluating the weight of a target data piece (such as a word for an OCR model) by its correlation with other data pieces (words). To put it simply, attention mechanisms are used for long-range dependencies prediction that CRNNs and LSTMs are not capable of on their own. If you want more information about how exactly an attention mechanism works, this tutorial offers an explanation and a short example.
The accuracy can be further improved with multi-head attention: this is when an attention mechanism is run in parallel several times. This allows us to separately evaluate different dependencies (e.g., long-term vs. short-term). The resulting concatenated output then can be further used to make the predictions of the deep learning OCR algorithm more precise.
What about transformers? They are another popular way of increasing the accuracy of OCR architectures. A transformer basically performs a similar function to LSTM with the difference that, unlike an RNN, it doesn’t require processing the input data in order (that is, from beginning to end). This can significantly decrease the time necessary for OCR model training. A few well-known and widely acknowledged NLP transformer models are BERT, as well as GPT-2 and GPT-3. You can read more about transformers following this link, with examples and a few visualization schemes.
LLM fine tuning on transformer models, such as GPT-3, further enhances model performance by adapting it to specific OCR tasks, resulting in improved accuracy and relevance in text extraction.
RAM and DRAM: Recurrent Attention Models in Deep Learning OCR
As neural networks are vaguely based on the functioning of the biologic brains, similarly recurrent attention models (RAMs) use the idea that a certain part of a new image attracts the attention of a human eye. During the visual attention OCR process, an image is divided into “glimpses” of data to be processed for information. This allows creating glimpse vectors that contain meaningful features from every piece of an image. An RNN then processes these glimpse vectors to predict other pieces of an image to process next. Backpropagation is used to ensure the accuracy of the output data.
DRAM (Deep Recurrent Attention Model) is similar to RAM but uses two RNNs instead of one, which makes the OCR processing of the image with the text more efficient. The first RNN is dedicated to analyzing the next glimpse location. The second RNN is used for the classification task, as it assigns the data labels to the text characters.
Datasets to Use in an OCR Deep Learning Project
In order for the OCR algorithm to function properly, it is necessary to train it. And you’re probably wondering how to train an OCR model. Well, there are a lot of datasets that can be used for a deep learning OCR model to train, and their specificity depends on the tasks the model is to solve. Here are a few of the most popular datasets:
- MNIST Dataset: it trains a neural network OCR by showing it one of the numerical digits at a time;
- SVHN (Street View House Number) Dataset: training of an OCR model on house numbers, as the name suggests, with the challenge that each number is written in a digger size, font, shape, and writing style;
- SVT (Street View Text) Dataset: an OCR algorithm trains on images captured outdoors, which means they are often noisy, of low quality, with additional artifacts and complex backgrounds;
- Scene Text Dataset: a combination of text and digits allows training an optical character recognition model in English and Korean languages;
- Devanagari Character Dataset: this is an example of the dataset for OCR training in a different language from English.
What About Annotation for OCR? Here’s How Label Your Data Can Help
Training your deep learning OCR model on an existing dataset is a good possibility if your task coincides with the issues these datasets were created to solve. However, more often than not, an OCR algorithm requires unique training and the introduction of state-of-the-art techniques to fit with the initial business project goals. In such cases, it is important to have your own dataset that will be ready to go into the OCR model.
An OCR training dataset is not just a set of photos of the text that you want to feed into the algorithm. It requires expert processing and data annotation services in order to be ready for the OCR task. Yet seldom do businesses possess the necessary resources, whether financial, human, or time, to perform annotation on a professional level without exceeding the budget. Outsourcing an OCR annotation project is the most viable option for most businesses who need to take care of their core goals first and foremost.
Label Your Data is an experienced data annotation company that can provide you with high-quality and timely execution of your OCR labeling project. We are compliant with the security industry standards and norms such as GRPD, CCPA, and PCI DSS. With us, you don’t need to worry about the leak or loss of any sensitive data, which may be especially crucial for an OCR project.
We will help you not only with annotation but also with the collection of the data for your OCR dataset if needed. In addition, we would be delighted to further our collaboration by assisting with the model validation to ensure that the data collected and annotated works perfectly with your OCR model and delivers the results that match your expectations.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Check our performance based on a free trial
Pay per labeled object or per annotation hour
Working with every annotation tool, even your custom tools
Work with a data-certified vendor: PCI DSS Level 1, ISO:2700, GDPR, CCPA
FAQ
How to train an OCR model?
- Gather labeled images with diverse fonts, sizes, and backgrounds that match your OCR needs. Standardize images (e.g., resize, grayscale) and ensure accurate labeling.
- Choose a model architecture like Tesseract, CRNN, or a custom option based on your text’s complexity.
- Train the model using the labeled dataset, adjusting hyperparameters and monitoring accuracy. This may require substantial computing power.
- Refine the model to boost accuracy, applying techniques like data augmentation and error analysis.
- Test on new data and evaluate using metrics such as accuracy, precision, and recall for real-world effectiveness.
Does OCR use neural networks?
Optical character recognition using deep learning is a popular approach that involves training a neural network to recognize and extract text from images. For instance, convolutional neural networks (CNNs) are used for image recognition and text extraction.
What algorithm does OCR use?
OCR uses various algorithms such as convolutional neural networks (CNNs), support vector machines (SVMs), and hidden Markov models (HMMs) to recognize text from images.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.