
- What Metrics Exist for Measuring Data Quality in the Annotation Process
- How to Measure Quality of Data Labeling: The Gold Standards We Adhere to at Label Your Data
- Consequences of Poorly Managed Data Labeling Quality
- How Label Your Data Can Elevate Your Dataset Quality
- FAQ
Given that data annotation is one of the most critical components of successful machine learning projects, its quality is at the forefront. While the labeling process is done according to the set benchmarks of the project, measuring data quality is an inevitable step before the annotation is completed.
The quality of data labeling has a direct impact on the final performance of machine learning algorithms. That’s why our team at Label Your Data has a set of data labeling standards that we stick to. Besides, we use various approaches to measure the final result and ensure we provide the best quality. And we’re going to share them with you in this guide.
What Metrics Exist for Measuring Data Quality in the Annotation Process
The process of data annotation is tedious and time-consuming. Since the initial ML dataset can differ in number and complexity, a few people can take part in the quality assurance. To avoid inconsistency in final labels, the accuracy of data labeling is controlled on all stages.
To ensure that the quality of data annotation meets the initial guidelines of the project, we refer to various data quality control procedures. From guidelines to final result, they address different aspects of the annotation process. The most common QA procedures used by annotation teams are listed below.
Inter-Annotator Agreement (IAA) Metrics
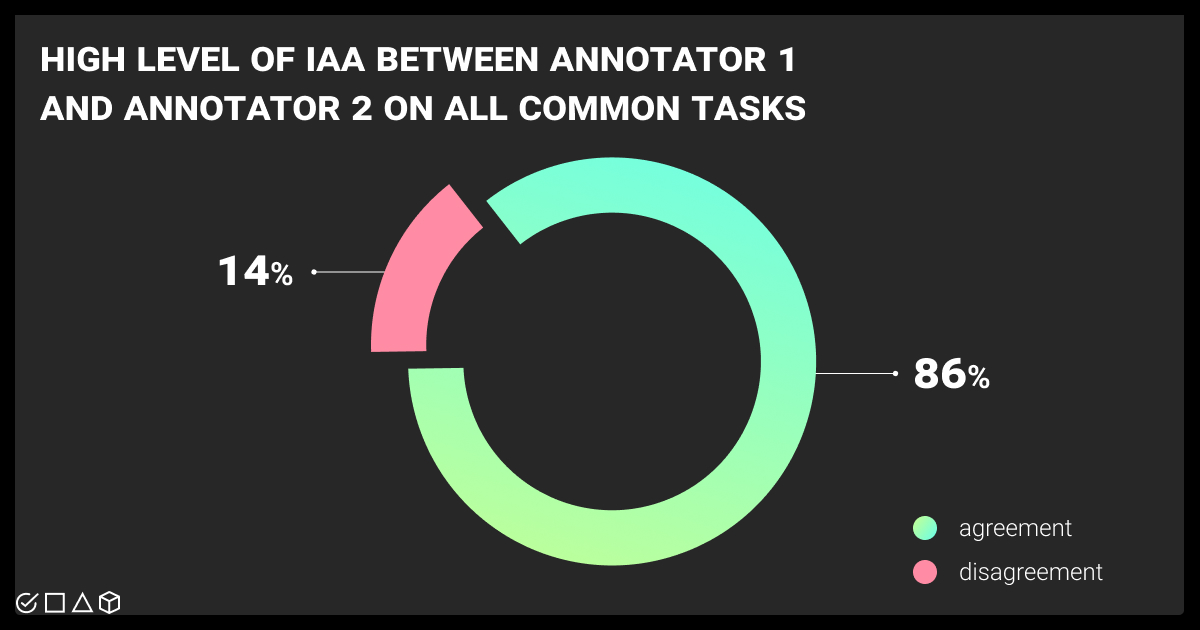
Even though the guidelines are the same for every task, we cannot avoid some level of subjectivity in measuring the final result. To ensure that the approach of every annotator is consistent across all categories of the dataset, we refer to Inter-Annotator Agreement (IAA) metrics. They can apply for the entire dataset, between annotators, between labels, or per task.
The most commonly used metrics include:
Cohen’s Kappa. This is a statistical coefficient to measure the agreement between two annotators on qualitative categories. In defining how to measure quality of data, reviewers give value 1 for complete agreement, -1 for disagreement, and leave space for chance-level agreement, marking the label with a 0.
Krippendorff’s Alpha. This metric assesses the reliability of agreement between annotators, whatever their number. It is applicable for various data types, including ordinal, ratio, and nominal. Krippendorff’s Alpha shows a specific level of disagreement for each pair of labels.
Fleiss’ Kappa. Similar to Cohen’s Kappa, Fleiss’ Kappa allows defining agreement with categorical ratings. However, this metric involves three and more annotators.
F1 Score. The metric shows the mean between precision and recall, which relate to positive results in predictions and actuals, accordingly. This metric is useful in tasks which have a gold standard, allowing a data labeling quality specialist to assess the quality of labeled data against this standard.
Percent Agreement. This metric is the simplest, which shows in percentage the amount of data that are annotated with the same labels against the total number of data. The downside is that it doesn’t include the chance agreement and may overestimate the actual result.
IAA metrics help to measure how clearly you understand the initial guidelines and how final data are uniform across all annotators who work on the project. It’s a gatekeeper in validation and reliability of annotation outcomes.
Consensus Algorithm
When multiple annotators work on similar tasks related to the same project, sometimes they cannot avoid discrepancy, especially working with data that requires subjective judgment. For instance, a consensus algorithm may come in handy when you need to evaluate data entry quality control.
As the name suggests, the algorithm serves as a consensus between annotators on which label to use for defined datasets. Basically, every annotator provides their labels for the defined data, and the consensus algorithm applies to determine the final label and measure data quality. This method is considered one of the simplest, as annotators can choose the final label even by simple majority voting. The algorithm is spread across scenarios with manual annotation, specifically in sentiment analysis or image classification.
Cronbach’s Alpha Test
Cronbach’s Alpha is another statistical method to assure the final annotation sticks to defined data labeling standards. In data annotation, the adapted test helps to check consistency and reliability of annotation across the dataset. The reliability coefficient is usually marked with 0 for completely unrelated labeling and 1 for high similarity among the final labels. As a result, the more alpha is closer to 1, the more final labels share in common.
Not only is Cronbach’s Alpha test used for data annotation quality control at the final check of labeled data. It also helps to reassess initial guidelines, refining them if something remains unclear for annotators. Besides, the test is used in pilot studies to proactively eliminate all inconsistencies in further data labeling.
We offer a free pilot for your annotation project. Whatever the industry you’re in, we ensure that the annotation is done accurately, consistently, and meets the initial benchmark. Give it a try!
How to Measure Quality of Data Labeling: The Gold Standards We Adhere to at Label Your Data
Imagine you work with a specific niche like the winemaking industry. And need to label a wine review dataset. Or perhaps you’re dealing with large datasets, which all should be labeled uniformly. How do you measure data quality in this case?
At Label Your Data, we believe manual work brings the most accurate results. Thus, we have a manual QA, which takes place several times during the whole annotation process. Even though additional checks can take extra time, we add them on purpose.
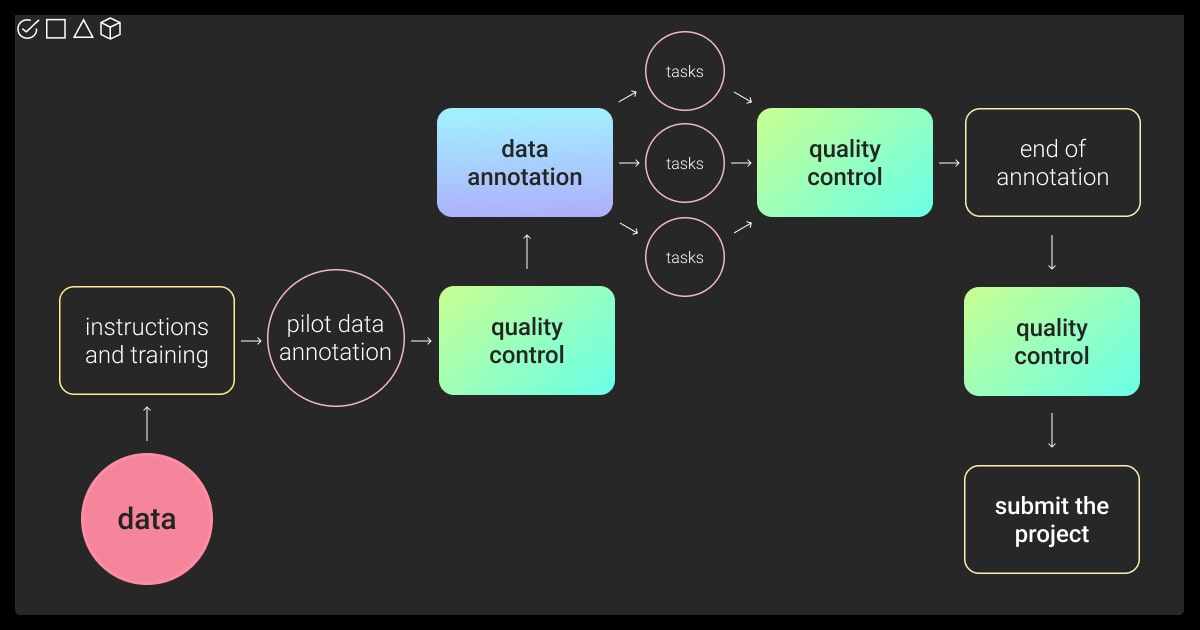
Here are the main stages of our QA process:
Step 1 We gather all the instructions for the data to be annotated. They can contain requirements for further machine learning training, as well as ready examples, which we later use as a benchmark.
Step 2. We organize the training for all annotators who will be involved in the project. Training for data quality is critical at the beginning to ensure that the final labels meet the expectations and require no to minimum changes. At this stage, the annotators receive all the instructions and see in practice how to label that particular dataset.
Step 3. We launch a pilot, which usually consists of a small part of the project. We check its quality and compare it to the initial instructions. If it’s approved on the client’s side and the data quality is high, we continue with the rest of the dataset.
Step 4. If the volume of the dataset is big, we divide it into smaller milestones and tasks. We accomplish data quality control after every task, and not only at the end of the project. This helps us save time on corrections and ensure we all move in the right direction.
Step 5. Finally, when the annotation is done, we end up with the final control and are ready to close the project by delivering the high-quality labeled dataset to the client.
Depending on the initial instructions, the volume of the dataset, and other requirements, we may accomplish additional QA checks as one of our additional services. For ML projects, which include subjective labeling, we use the following approaches:
Cross-reference QA. This method ensures the final labels are consistent by involving multiple experts performing annotations for further comparison and verification. The main result is to reach consensus between all annotators, especially in matters regarding subjectivity. We had cases where two or three annotators were doing the same task. These are usually projects that contain datasets of text and maps.
Random sampling. By randomly selecting multiple labels, we check that the quality corresponds to the project requirements. This approach is more relevant to smaller projects and is used as an extra step to regular quality control checks.
“We treat every project with the utmost care. We ensure that every accomplished annotation task passes through all stages of quality control. With such a meticulous approach, we guarantee +98% of accuracy rate in data annotation to our clients.”
Karyna Naminas,
CEO of Label Your Data
Consequences of Poorly Managed Data Labeling Quality

One thing to remember is that all the labeled dataset is further used in the training and testing of machine learning models. With poor data, incorrectly trained models can lead to adverse consequences, especially in such areas of AI implementation as medicine or finances.
Data annotation trends show that with inconsistent data labeling, the performance of ML models will be less accurate, more biased, will lead to financial losses, and wasted training costs. In addition, the most common consequences of bad data labeling quality include:
Biased models. No matter the area of biased model application in machine learning, it can lead to incorrect, discriminatory outcomes. Biased models also influence poor decision-making and can even meet regulatory penalties.
Incorrect performance metrics. Performance metrics are crucial to assess reliability of the model used for machine learning training. Incorrect metrics influence the overall performance of the AI model, which leads to resource mislocation, loss of trust among stakeholders and users, as well as economic losses.
Inefficiency of model development. ML training happens in sequential steps. If datasets are labeled incorrectly, the model development adds extra steps for checking and modification, which becomes more time-consuming, reducing the effectiveness of development.
Wasted resources. Even if you automate data collection, for example, you still invest in data annotation. And not only money, but also time. If the labeled data is of poor quality, you have wasted and used your overall budget ineffectively.
Constraints of AI adoption. Data labeling influences the overall implementation of the AI model. If the project has constraints or includes biased data, the project will likely meet resistance from users and stakeholders regarding its implementation.
That’s why it is so critical to ensure that the labeled data is of high quality, accurate, and without any discrepancies. Our team can help you with ML projects of different scale, providing expert data tagging services.
How Label Your Data Can Elevate Your Dataset Quality
Our team of professionals can help you with moving your ML dataset to the next level, carefully annotating it. All our services are of high quality and bear ISO/EIC certification.
Most importantly, our manual QA procedures are undertaken by experienced specialists in the field, guaranteeing the highest accuracy. Besides, we work with all types of data, being thus flexible to meet any challenges of your project.
If you need a quality annotation, free of biases and in accordance with your project needs, fill our form for a free pilot!
FAQ
What is quality annotation?
Quality annotation refers to the data that is accurately labeled for further usage by the machine learning model. More specifically, these are meticulously labeled data points used to create a dataset that a machine learning model can learn from effectively. This is one of the most critical steps in the whole ML pipeline, since the quality of labeled data will further influence the model performance.
What data quality measures are used in the annotation project?
Every project starts with the requirements for data annotation. Every labeled data is checked against the benchmark established as a gold standard. These standards usually include accuracy, consistency, relevance, and completeness of the annotation, which are later measured assessing the degree of inter-annotator agreement (IAA).
How is quality measured in data labeling?
The quality of the final labeled dataset is controlled by tools or manually. Different metrics and methods exist for measuring the quality of data labeling, such as percent agreement, inter-annotator agreement (IAA) metrics, or consensus algorithm, among others. In manual QA, the agreement is usually made on the final label, by comparing the annotations made by a labeler with those made by a reviewer.
Table of Contents
![]() Get Notified ⤵
Get Notified ⤵
Receive weekly email each time we publish something new: