
- Key Roles and Skills of Your Data Annotation Team
- A Dedicated Annotation Team: How to Build One?
- The Benefits of Building an In-House Data Annotation Team
- Key Takeaways
- FAQ
In pursuit of innovation and success, businesses need accurate data to make informed decisions that affect their bottom line. Keeping that data accurate and up-to-date is not an easy task, especially for smaller companies without much expertise. That’s where data annotation teams come in to keep models relevant for informed decisions and ensure reliable results.
Yet, the key question remains: how to build a data annotation team that consistently delivers accurate and relevant results?
For over 13 years, we at Label Your Data delivered top-tier, secure data labeling services to clients worldwide. But we’ve often kept our inner workings out of the spotlight. Today, we want to shed light on who data annotators are, their role, and share our key tips on how to establish a data annotation team from scratch.
Key Roles and Skills of Your Data Annotation Team
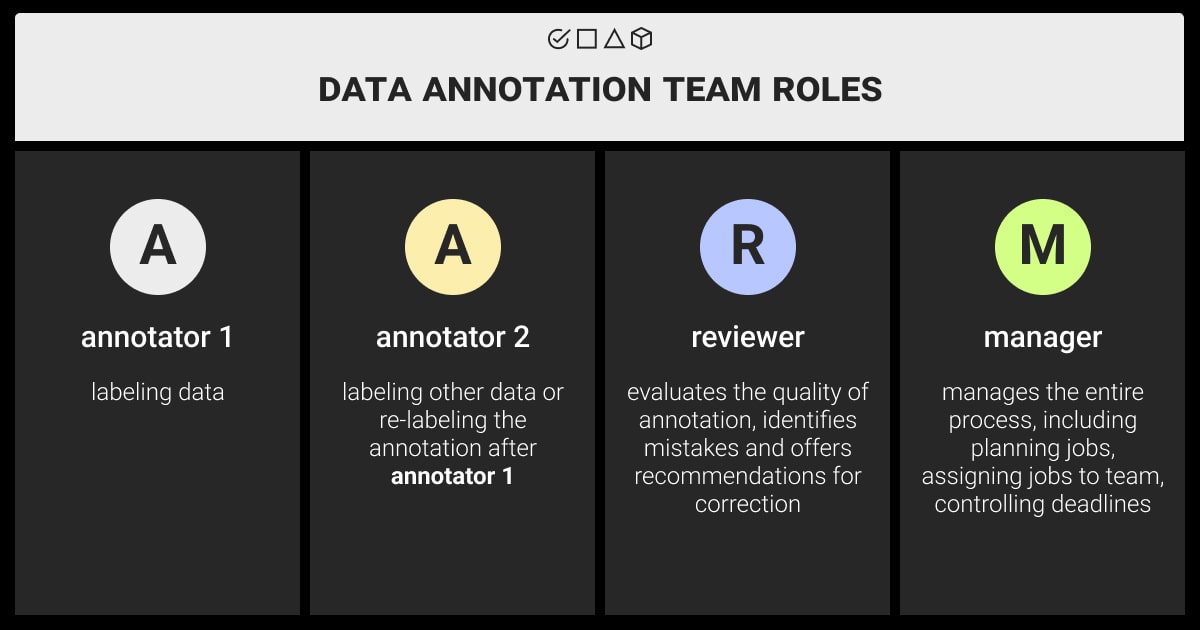
A dedicated annotation team of full-time employees is great for complex ML projects, private data, or when you don’t have a set budget. This is the only option for labeling data with sensitive information or legal restrictions. Yet, such projects still require a thorough training and management, just like any other team.
A data annotation team consists of:
Data annotation specialists who prepare high-quality training data for ML models. They know how to label data for machine learning according to predefined criteria or guidelines to ensure its accuracy and relevance. Their work directly impacts the success of ML projects by guaranteeing the integrity and effectiveness of training data.
Project manager, or a data annotator team manager, who coordinates the annotation process, allocates tasks, and manages timelines to ensure project completion.
QA (Quality Assurance) specialists who verify the accuracy and consistency of annotations, ensuring high-quality labeled datasets.
Subject-matter experts that provide domain-specific knowledge to guide annotators in accurately labeling data relevant to the project.
Data scientists or ML engineers can sometimes be on the team to oversee the annotation process from a technical perspective, ensuring alignment with the requirements of the ML models being developed.
When it comes to the core team members, annotators, their role extends beyond mere data annotation:
Data annotator responsibility | Explanation |
Working with data |
Analyzing data for key features and attributes to guide how it’s labeled. |
Creating labeling rules |
Establishing clear and consistent instructions for data annotators to follow. |
Applying labels to data |
Accurately assigning predefined tags to data to make it machine-readable. |
Checking the quality |
Reviewing and verifying the accuracy and consistency of performed annotations. |
Teaming up with diverse experts |
Collaborating with other team members involved in the project, such as data scientists and engineers. |
Securing the data |
Following strict security protocols to ensure data privacy during annotation. |
Skip the labeling hassle. Get your free pilot from Label Your Data.
A Dedicated Annotation Team: How to Build One?
While automatic data annotation can be quicker and more affordable, it might also be less accurate. Human experts can label data more precisely because of their knowledge and experience, leading to better results, although it might cost more.
Here are some reasons why you might need to build a team to label your data:
To figure out how much data is needed to train ML models accurately.
To give machine learning models enough data to learn from.
To keep checking the data and making sure the results are still accurate and relevant.
To handle large amounts of data that one person couldn’t manage alone.
How to Hire a Data Annotation Team?
Building robust ML models requires high-quality training data, and the accuracy of this data hinges on the people who label it: data annotators. Yet, the study finds error rate in data annotation jumps from 6% for simple tasks to 40% for complex tasks like sentiment analysis, highlighting the importance of the right hiring strategy.
Traditional methods often lead to inconsistencies, impacting the final model’s performance. However, specialized annotation tools are emerging to address this challenge, providing structured training for annotators to deliver consistent labeling. But finding the right data annotation team members remains crucial. So here’s what we suggest:
Leverage your network: Utilize job boards like Indeed, Glassdoor, and LinkedIn, targeting experienced professionals. Engage with relevant AI communities on social media. Encourage employee referrals for qualified candidates.
Look beyond your network: Consider partnering with third-party annotation companies for leveraging their existing pool of pre-trained professionals. Create targeted online ads to attract qualified individuals, focusing on relevant keywords, such as “data labeling expert” or “AI project annotator.”
Prioritize quality over cost: Assess the annotators’ skills, experience, and portfolio to ensure they meet your ML project’s needs. Remember, good data annotation is an investment in your AI’s accuracy.
-
Choose the right hiring approach:
In-house: Offers control and consistency but can be expensive.
Freelancers: Cost-effective with access to specific skills, but managing quality can be challenging.
Outsourcing: Turnkey solution with minimal management, but expensive and less flexible.
Crowdsourcing: Highly cost-effective, but ensuring consistent quality is difficult.
You can also check our blog to find out more about in-house vs. outsourced data annotation to make the right choice.
By employing the right strategies and carefully considering your options, you can create a data annotation team and ensure your ML project thrives on high-quality training data.
How to Train Your Data Annotation Team Members?
Effective image annotation services or any other labeling task require a well-trained team. We suggest these key steps to help you build a well-rounded data annotation team:
-
Define your data annotation process clearly
Document guidelines: Establish clear instructions for labeling conventions, training procedures, and quality control measures. Make them readily accessible and regularly updated to ensure everyone is on the same page.
Training procedures: Streamline onboarding for new members and ensure existing members stay aligned. Encourage real-time questions and provide written feedback during training.
A clearly defined process ensures clarity, consistency, and enhanced efficiency. First, it fosters a collaborative environment where each of the data annotation team members understands roles, expectations, and quality standards. Second, clear procedures minimize confusion and wasted time, leading to faster completion and consistent high-quality data.
-
Establish effective training procedures
An effective training procedure is crucial for building a data annotation team. Here’s how to achieve one:
Clear communication: Establish clear and consistent guidelines to avoid confusion and maintain data annotation quality.
Onboarding and ongoing support: Defined procedures ensure efficient training for new members and continued reference for experienced members.
Consistency in labeling: Consistent application of annotation standards across the team is crucial for reliable data applicable for machine learning models.
The success of training annotators for a project hinges on several factors, including the project’s specific needs, time constraints, and the capabilities of the managing team. When planning your project timeline, consider the duration of the training phrase. It depends on the experience level of the workforce, the project’s complexity, and the chosen method for ensuring data quality.
-
Additional considerations for a data annotation team building
Beyond the core training, consider these additional factors:
Tagging ontology: Design for consistency by considering potential edge cases and using contrasting examples to clarify labeling.
User experience: Design task guidelines with ergonomics and collaboration in mind.
Language and culture: Consider variations when setting up tag sets and data collection guidelines.
Team diversity: Create a data annotation team that is diverse, with relevant language skills, and different backgrounds to reduce bias in data models and ensure fair outcomes.
Performance monitoring: Implement a plan to address consistently low performers to maintain data quality.
User-friendly tools: Choose intuitive and user-friendly data annotation tools for efficient data processing and higher-quality results.
By following these steps, you can build a strong and well-trained data annotation team that delivers consistent, high-quality data for your ML models.
While achieving perfect annotation is unrealistic, it’s crucial to have a system in place for identifying and addressing consistently underperforming annotators. This could involve either providing additional training for annotators or, if necessary, removing them from the project to safeguard the quality of the ML datasets.
Why SMEs Matter in Building a Data Annotation Team?
Subject-matter experts (SMEs) play a crucial role in building a data annotation team for several reasons:
Domain-specific knowledge: SMEs possess deep understanding and expertise in the specific field or domain the data pertains to. For instance, you might need SMEs for data annotation in academia, healthcare, or banking. This allows them to accurately interpret, categorize, and label data points with the necessary context and nuance.
Quality assurance: Their expertise enables them to identify inconsistencies, ambiguities, and potential errors in data annotation. This is especially important for complex tasks like sentiment analysis or medical image recognition, where subtle details can significantly impact results.
Developing guidelines and standards: SMEs are instrumental in establishing clear and consistent annotation guidelines and standards for the team to follow. This minimizes discrepancies in how different annotators perceive and annotate the data.
Training and mentoring: SMEs can effectively train and mentor other annotators, especially those new to the domain. They can provide valuable insights into the specific characteristics and nuances of the data, leading to a more skilled and efficient annotation team.
While not always feasible to have a team solely of SMEs, their involvement is vital for ensuring high-quality, reliable data annotation.
Let experts handle data annotation. Run your free pilot today!
The Benefits of Building an In-House Data Annotation Team

Having a dedicated data annotation team offers several advantages over crowdsourcing or other options. While both approaches involve a large pool of workers, relying on anonymous individuals can lead to inconsistent and lower-quality data compared to a managed team working with the same data.
One of the key benefits of building a data annotation team is annotators’ increasing familiarity with your project. That is, the expertise of the data annotation team in your specific corporate rules, context, and edge cases grows in parallel with their practice. This understanding allows them to ensure high-quality results and efficiently train new members who join the team. Not to mention the fact that in-house teams offer enhanced data security thanks to the implementation of non-disclosure agreements (NDA).
Moreover, a managed annotation team is particularly crucial for ML projects, where data quality and the ability to adapt are critical. Unlike crowdsourced workers, in-house data annotation team members gain a deeper understanding of your model and its context with continued exposure to your data. This ongoing collaboration fosters smoother workflows and ultimately leads to superior training data for your project.
Key Takeaways

To get high-performing ML models, you need to build a data annotation team capable of handling different project complexity and types of data. While it may seem challenging at first, accurate and well-labeled data translates to efficient and accurate models, ultimately saving you time and resources in the long run.
To reap the benefits of building a data annotation team in-house, be sure to follow the steps we’ve outlined in this guide.
You can always skip the team building process and get reliable data annotation delivered by experts. Contact us here!
FAQ
What is the role of a data annotation job?
The role of a data annotator is to accurately label data to train machine learning models and improve their performance. This involves tasks such as categorizing images, transcribing audio, or tagging text to create labeled datasets used for training ML algorithms across various applications such as computer vision and natural language processing (NLP).
Is data annotation an IT job?
The data annotator job can be considered an IT-adjacent task, as it involves labeling and processing data for ML applications, often performed by IT professionals or specialists within data science teams.
Where should I start with building a data annotation team for my ML project?
When assembling a data annotation team for an ML project, consider these key primary steps:
Identify necessary skill sets, such as data labeling expertise and domain knowledge.
Recruit team members with strong attention to detail and ability to work with large datasets.
Establish clear guidelines and processes for annotation tasks to ensure consistency and accuracy.
Table of Contents
![]() Get Notified ⤵
Get Notified ⤵
Receive weekly email each time we publish something new: