How to Label Data for Machine Learning?

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

TL;DR
- Data labeling creates high-quality training datasets for ML models.
- Key steps include data collection, cleaning, labeling, and QA.
- Tasks range from image categorization to text and audio transcription.
- Challenges include cost, time, and consistency, solvable with proper strategies.
- Supports computer vision and NLP for accurate predictions and smart solutions.
Where Data Labeling Fits in the ML Pipeline
Data labeling for machine learning became pivotal for streamlining the way we handle massive data volumes. Yet, companies still struggle to get this process done right for their ML projects.
Those that do know how to label data for machine learning are already in the pace for speeding up the development of intelligent and dependable AI systems. In this guide, we’ll show you how to get the process of data labeling in machine learning right.
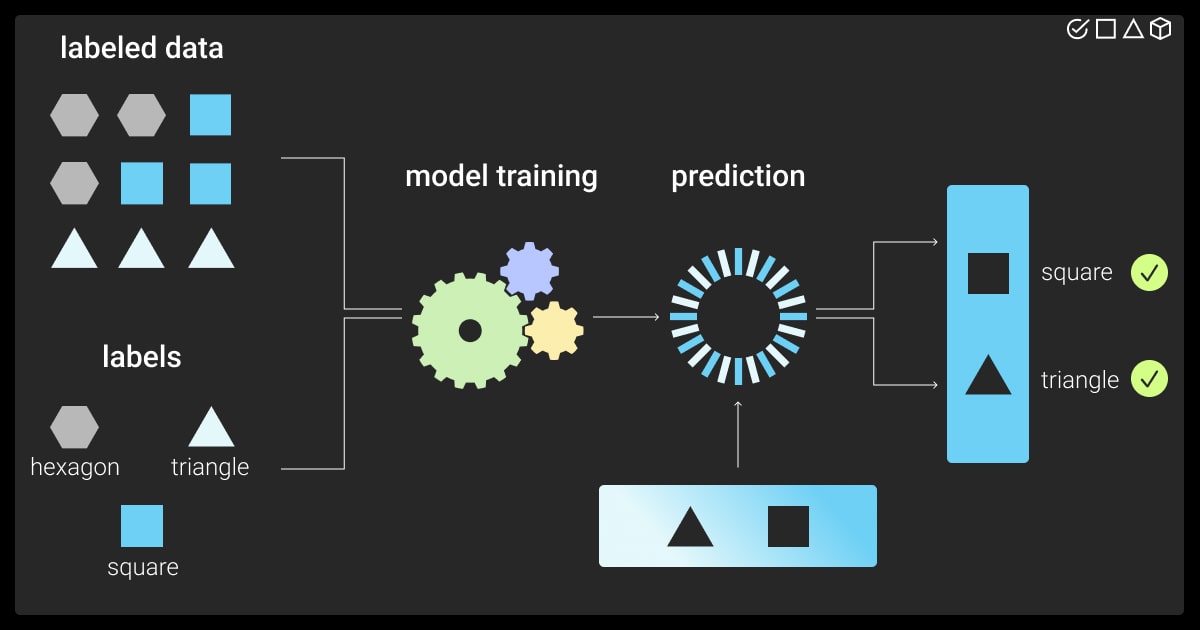
Key Steps in Labeling Data for Machine Learning
Here’s a breakdown of how data labeling fits in the machine learning pipeline:
Data Collection
The pipeline begins by gathering the raw data you want your model to learn from. Data collection implies gathering raw, unstructured data (images, videos, text documents, or audio files) that needs to be labeled. The more data you have, the more precise your model will be.
Here’s where you can find data for your ML project:
- Freelance fieldwork: Hire specialists to collect specific data unavailable online.
- Public datasets: Access free data from sources like Kaggle, UCI, and Data.gov.
- Paid datasets: Invest in specialized or exclusive data for your project.
Data Cleaning
Prepare data for supervised ML by cleaning it. That is, eliminating irrelevant, duplicate, or corrupted files to uphold data quality, as well as identifying and correcting (or deleting) errors, noise, and missing values. Data cleaning is an ongoing process that happens throughout the development and potentially even deployment of your machine learning project.
Data Storage and Management
The next step is to store your collected data correctly and in the right format for efficient management. Choose a storage solution that can scale with your data needs over time. Common options include:
- Data warehouses: Traditional solutions like Oracle Exadata or Teradata, or cloud-based options like Amazon Redshift.
- Data lakes: Cloud-based solutions such as Amazon S3 with AWS Glue or Azure Data Lake Storage with Azure Databricks.
Data Labeling
Data labeling, or data annotation, is the process of adding meaningful labels to raw data, making it usable for machine learning models. This step is essential for supervised learning, where labeled datasets are required to train models to recognize patterns and make accurate predictions. Whether it’s text, images, audio, or other data types, proper data annotation services ensure the model can learn effectively and produce reliable outcomes.
Model Training
Once you’ve labeled data in machine learning and checked the quality and consistency of the performed annotations, it’s time to put the labeled dataset to use. By analyzing the labeled data, the model learns to identify patterns and relationships between the data and the labels.
The dataset can now be split for model training, testing, and validation, following this rule of thumb:
- 60%: Used for model training to identify patterns and relationships.
- 20%: Reserved for validation to fine-tune and prevent overfitting.
- 20%: Set aside for testing to evaluate performance on unseen data.
By analyzing the labeled data, the model learns to identify patterns and relationships between the data and the labels, a process that may include LLM fine-tuning for language models to improve task-specific performance.
Model Evaluation & Deployment
Once trained, the model’s performance is evaluated on a separate dataset. Metrics like accuracy, precision, and recall are used to assess its effectiveness. If successful, the model can then be deployed for real-world use.
How Labeling Data for Machine Learning Works
Most ML models use supervised learning, where an algorithm maps inputs to outputs based on a set of labeled data by humans. The model learns from these labeled examples to decipher patterns in that data during a process called model training. The model can then make predictions on new data.
Labeled data used for training and assessing an ML model is often referred to as “ground truth.” The model’s accuracy relies on the precision of this ground truth, emphasizing the importance of investing time and resources in accurate data labeling.
With high-quality annotations on hand, data scientists can identify the important features within the data. However, common dataset labeling pitfalls can impede this crucial process.
More specifically, public datasets often lack relevance or fail to provide project-specific data, and in-house labeling can be time-consuming and resource-heavy. Automated tools, while helpful, don’t guarantee 100% accuracy or offer all the features you need. And even with automation, human oversight is still a must.
Next, we reveal 6 steps to overcome these challenges when labeling datasets for machine learning.
6 Steps to Overcome Data Labeling Challenges

In the study by Hivemind, a managed annotation workforce demonstrated a 25% higher accuracy rate compared to crowdsourced annotators, who made over 10 times as many errors.
This means that building and managing your own in-house data labeling team can significantly improve the quality of your training data. To help you achieve efficient in-house labeling, we’ve gathered our time-proven steps to help you navigate the main challenges in data labeling:
Building a Solid Data Annotation Strategy
Data annotation projects usually fall under one of the categories: data labeling for initial ML model training, data labeling for ML model fine-tuning, and human-in-the-loop (HITL) and active learning.
Your data annotation process must be scalable, well-organized, and efficient. It’s an iterative step in the entire ML pipeline, involving constant monitoring, feedback, optimization, and testing.
Maintaining High Quality of Labeled Datasets
Regular QA procedures are crucial to verify label accuracy and consistency, ensuring that your machine learning algorithm is trained on high-quality data. This includes reviewing random data samples or employing validation techniques. The labeling process also follows an iterative loop, with initial results reviewed and feedback incorporated for further label refinement.
Keeping ML Datasets Secure
To ensure labeled data security, you should prioritize a multi-layered approach encompassing:
- Physical security: Manned security, access restrictions, surveillance, ID badges, and limited personal items in sensitive areas.
- Employee training & vetting: Training on security risks, phishing, and policies; background checks and NDAs required.
- Technical security: AES-256 encryption, secure software, multifactor authentication, and role-based access control.
- Cybersecurity: Proprietary tools, penetration tests, and external audits.
- Data compliance: GDPR, CCPA, and ISO 27001 compliance with regular updates.
Hiring Data Annotators
Inconsistent data annotations can cripple the model’s performance. To tackle this, you need to hire skilled data labelers. You can build your team by leveraging your network through job boards and social media, or look beyond it by partnering with a data annotation company or targeted online ads. By choosing the right hiring approach, you'll assemble a strong data annotation team to fuel your ML project’s success.
Training Data Annotators
Despite the level of automation we’ve reached so far, data labeling cannot do without human intelligence. Always make sure to have human experts on your team. They bring the context, expertise, experience, and reasoning to streamline the automated workflow.
Training a team of annotators to use a specific labeling tool and follow the project guidelines. When dealing with a specific type of data and edge cases in data labeling, you need to hire subject-matter experts (SMEs) for complex domains, like healthcare, finance, scientific research, or for multilingual tasks in NLP.
Choosing In-house vs. Outsourced Annotation
Choosing between in-house vs. outsourced data labeling depends on your specific needs and priorities. Consider the size and complexity of your dataset, the turnaround time required, and the level of control you need over the labeling process.
In short, outsourcing works for projects involving large datasets with simpler labeling tasks and a focus on faster turnaround times. However, this strategy might pose potential quality issues. A dedicated in-house team, in contrast, is suitable for those looking for a balance between cost, quality, and scalability, especially for projects requiring domain expertise.
You can learn more about this in our article about in-house vs. outsourcing data annotation.
Labeling Data for Computer Vision Models

The process of labeling data for machine learning usually falls under two categories: machine vision tasks and NLP tasks. If you’re building a computer vision system, you deal with visual data, such as images and videos.
Here, you can use more than one type of data labeling tasks to generate a training dataset, including:
Image Categorization
Allows training your ML model to group images into classes, allowing further identification of objects in photos.
Semantic Segmentation
Associates each pixel with an object class, creating a map for machine learning to recognize separate objects in an image.
2D Boxes (Bounding Boxes)
This labeling type implies drawing frames around objects for a model to classify them into predefined categories.
3D Cuboids
Extends 2D boxes by adding a third dimension, providing size, position, rotation, and movement prediction for objects.
Polygonal Annotation
Draws complex outlines around objects, training machines to recognize objects based on their shape.
Keypoint Annotation
Defines main points for natural objects, training ML algorithms for shapes, movement, and versatility in facial recognition, sports tracking, etc.
Object Tracking
This type is often used in video labeling, breaking down frames, and detecting objects to link their positions across different frames.
As such, when labeling data for ML training, keep in mind the specific task you want your ML model to perform. You can use your labeled dataset to build a computer vision model for image recognition, recognizing handwritten text, segmenting medical images, or even predicting anomalies in satellite imagery through geospatial annotation.
Labeling Data for NLP Models

Labeling data for machine learning can get trickier when working with textual or audio data. The reason for this is simple: inherent subjectivity and complexity in language. The key challenge here is the need for linguistic knowledge.
Creating a training dataset for natural language processing techniques involves manually annotating key text segments or applying specific labels. This includes tasks such as determining sentiment, identifying parts of speech, categorizing proper nouns like locations and individuals, and recognizing text within images, PDFs, or other documents.
The main NLP labeling tasks include:
Text Classification
Groups texts based on content using key phrases and words as tags (e.g., automatic email filters categorizing messages).
OCR (Optical Character Recognition)
Converts images of text (typed or handwritten) into machine-readable text, applied in business, license plate scanning, and language translation.
NER (Named Entity Recognition)
Detects and categorizes specific words or phrases in text, automating the extraction of information like names, places, dates, prices, and order numbers.
Intent/Sentiment Analysis
Combines sentiment analysis (classifying tone as positive, neutral, or negative) and intent analysis (identifying hidden intentions) for applications in market research, public opinion monitoring, brand reputation, and customer reviews.
Audio-To-Text Transcription
Teaches ML model to transform audio into text, useful for transcribing messages and integrating with other NLP tasks like intent and sentiment analysis for automatic speech recognition in virtual assistants.
As you can see, data labeling for machine learning is key to developing effective models. Accurate and scalable labeling enables smarter solutions in computer vision and NLP, streamlining the process for better outcomes.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
Does machine learning always need labelled data?
Not necessarily. Machines can leverage both labeled and unlabeled data for model training. However, while labeled data is commonly used in supervised learning, unsupervised and reinforcement learning can operate without labeled data.
How to label data using machine learning?
- Choose annotation tools like Label Studio or Prodigy.
- Define relevant labels for your ML task.
- Assign labels manually or with AI assistance.
- Validate accuracy with QA checks.
What technique involves giving examples and labeling data for learning?
Supervised learning uses labeled examples to train models and help them learn input-output relationships.
Can you use AI to label data?
Yes, AI tools can automate labeling tasks, but human validation ensures accuracy, especially for complex data.
How to add a label in a dataset?
- Load the dataset into an annotation tool.
- Assign predefined labels to each data point.
- Ensure consistency with clear guidelines.
- Export in formats like CSV or JSON.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.