AI is not only a hot trend but a pool of opportunities that every business wants to tap into. That is why we can see the implementation of AI in every industry, from automotive to retail to entertainment. And while the introduction of AI in your business can bring a lot of competitive advantages, we currently face a crisis, which is connected to the big data and its annotation.
AI models are powered by the data, but it's not just any data. First, it should be big: the more you feed into the machine learning model, the more accurate predictions you will have. Second, it must be relevant and complete, match the goals of your project, and also be devoid of biases and blind spots. Finally, it should be labeled properly and undergo the round of quality assurance to check its usability.
Sometimes correspondence to these conditions is a question of the revenue that a company loses when the data is not good enough. In other cases, it's a matter of life and death, for example, for products like self-driving cars. A tiny mistake might cost human lives, so there's no room for errors. Knowing this, we've outlined the most problematic issues that undermine the smooth adoption of AI:
Ignoring any of these issues can potentially lead to unreliable AI software and the risk of starting anew. But being aware of them is already a step in the direction of finding answers and building an effective, successful AI model.
Big and Relevant: Collect the Data According to the Goals of Your Project
Irrelevant Data
People like the concept of artificial intelligence because it promises us automation. We can finally get rid of tiresome, tedious, and mundane work. But before we can do it, we have to teach our machines to work as we would. And for this, we need a lot of data.
Alexandr Wang, the CEO of Scale AI, uncovered the “dirty secret” of AI: if you want a working, reliable software, you will require a large amount of relevant, high-quality data. What this means is that you have to train your ML model by showing it thousands of examples and let it memorize the correlations between your data pieces. The more you feed into it, the more accurate its predictions will be.
However, there are hidden pitfalls here. More data means that your model will need a lot of time to go through it. With increased volume also increases the risk of mistakes and low-quality data pieces. And while the volume of the required data usually grows together with the intricacy of the model, it is harder and more expensive to sustain. Besides, it's highly unlikely you won't need to retrain your model after it goes live, despite how much data you use during initial training.
Make It Manageable: The Availability and Security of Data Governance
Hui Lei, VP of Futurewei Technologies, says that the AI crisis is connected to the systematic and infrastructural faults in AI development rather than the adequacy of ML algorithms. And this is where data governance shines. It is the strategic policy that approaches your AI project as a system and tackles the inefficiency of your data on all stages of the project.
Let's say that you've successfully collected your dataset. Now what? You need to store it. But don't just heap everything in one place; work out a system. This is useful since, next, you'll need to make it available to those who will be working with it. You should also track if the data is consistent and reliable on every stage of your project: when the new data arrives, it should be smoothly integrated into your project.
Data management also means protecting your data. You need to know what data is used, who uses it, how and for what purposes. Ensuring security within your company is crucial, but it is even more important if you decide to outsource your data labeling task. When you do, check if the third party firm knows the appropriate data governance techniques and will provide the security of your datasets.
For example, at Label Your Data, we believe security is no less important than the quality and speed. We are GDPR and CCPA compliant, which means we will go out of our way to make sure your data is handled with extra care and discretion.
Consistency and Expertise of Label Quality
Incorrect or inconsistent labels
Data is the new oil, but you cannot use it in its raw, crude form. Your data needs refinement, which comes in the form of data labeling. And here lies another issue that increases the difficulty of using the data for your AI. Aside from the quality of the data that you collect, you also need to know the value of label quality.
On one hand, a lack of professional expertise is commonly the root cause of poor label quality. You cannot expect a person with no knowledge in jurisprudence to understand all the details of the contract clauses. At the same time, the labeling work of a lawyer will cost more. So the companies often utilize the combination of expert data labeling with freelance, outsourcing, and in-house annotators to ensure the high quality of the labeling process.
On the other hand, labels can be influenced by the annotator's background (language, culture, personality, etc.). The most common issues, in this case, are label consistency and absence of a single correct answer. To avoid these problems, you'll need to create a policy that explains how to create training labels correctly and according to your strategic goal. The policy should have no room for interpretation, otherwise, you're leaving a lot of the data labeling to chance. Also, diversity and inclusion in your data labeling team might help.
Analysis of Labeled Data: Looking for Blind Spots and Biases
Looking for blind spots
After you've annotated the data, the process of data labeling in AI is not finished. If you want to make sure the ML algorithm will make no mistakes, you should analyze the dataset. Ignoring the issue of mistakes (for now), the data labeling of AI training sets is prone to the two types of inaccuracies: blind spots and biases.
A blind spot is a lack of training on certain types of data. For example, it happens when your self-driving car sees an object it cannot recognize, let's say, a garbage can. A bias is favoring a certain variety of data. E.g., your algorithm for autonomous cars was trained mostly on the pictures of one-story buildings and thus doesn't recognize skyscrapers as such. These inaccuracies result in absence of understanding what to do with such types of data, which means they can be completely ignored.
In addition, there are also edge cases, which are rare and unusual situations that do not happen often. You do not often encounter a helicopter that landed in the middle of the street. But if you want to avoid accidents in case this happens, it is necessary to factor in such occurrences.
The analysis of labeled data is especially tricky in semi-supervised ML, as well as deep learning algorithms. They generate pseudo-labeled data, which can be based on inaccurate tags or classes. These models generally lack the flexibility and understanding of the real world that people have. After the primary labeling, human experts are crucial because we, unlike the machines, can use common sense to decide what the necessary action is. For this reason, a lot of AI and data labeling companies practice active learning, the approach where data is added incrementally to achieve the highest accuracy with the least amount of data.
Quality Assurance: Human-in-the-Loop
Label Your Data office – data annotation process
Quality assurance (QA) is a must to ensure the accuracy of the data on all three stages of an AI project:
Collecting and preparing of data
Training of the algorithm
Monitoring the working model
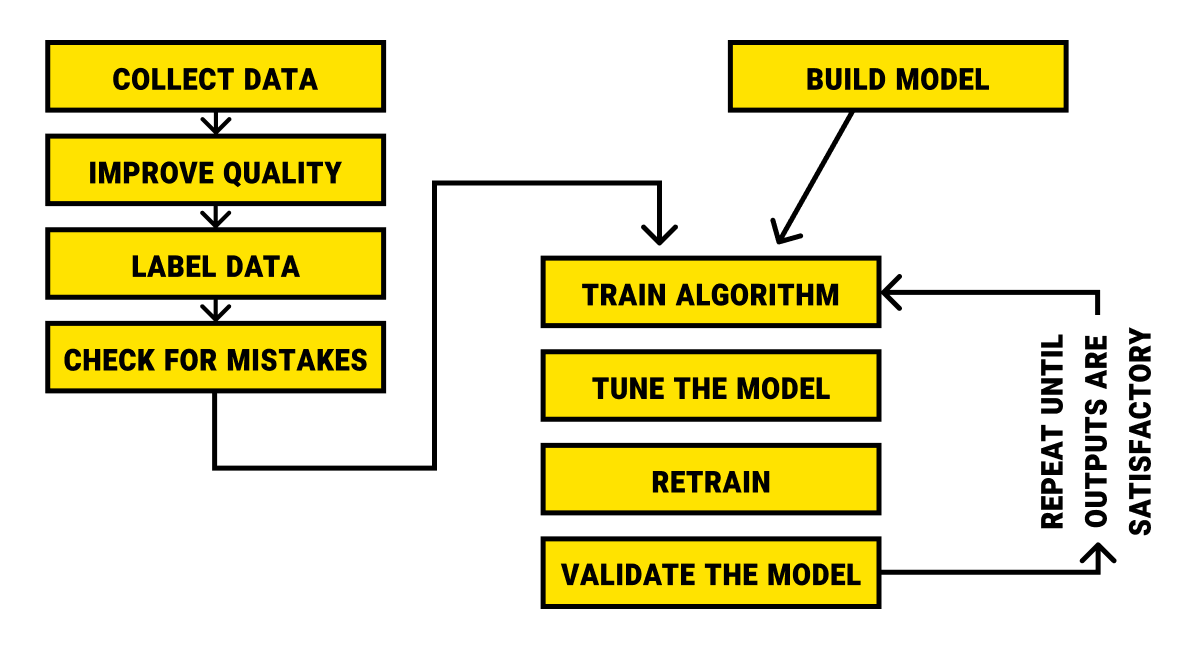
Human-in-the-loop is a popular approach to ensure continuous QA on every stage of the AI project. This approach is based on continuous feedback that the algorithm provides for people to access and adjust (to spot overfitting, eliminate blind spots and bias, teach the model about edge cases, and add new classes and tags). Typically, it goes like this:
For the moment, human-in-the-loop is the preferred approach for AI companies. We at Label Your Data use this approach at all stages of the data labeling process to combine the flexibility and common sense of humans with the reliability and computational power of the machines. Usually, after we label our Clients' training data, there's at least one (and sometimes more) round of QA we perform to make sure there are absolutely no mistakes left. That's because we strive to perfection!
QA is a vast and complicated topic, full of questions and interesting solutions. If you're interested in it, do some further digging. Michael Perlin's series of articles on QA in ML is a good place to start.
How Label Your Data Helps with the Challenge of Big Data Labeling in AI
Label Your Data office – data annotation process
There is no doubt that big data (and, consequentially, data labeling) is an integral part of building an AI model. However, it's not just about the big numbers. The data should also be high-quality and clean unless you want an unreliable algorithm that will fail when faced with the new real-world data. Obviously, the data should also be relevant to your task. And while Label Your Data cannot help you with collecting the data, we can make sure you have the best labeling service available.
We at Label Your Data realized the problem that companies face when training their AI. Our team created the error-proof annotation process to address every issue during the stage of data labeling. We make sure the data is protected and well-managed. Our diverse team of data labeling experts offers expertise in a variety of fields, from self-driving cars and AR to retail and healthcare. We also believe in the importance of QA and will perform as many rounds as necessary to eliminate all potential errors. If you want to be sure of the quality and security of your labeling, request a quote for your AI project.
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.
Read Next
PyTorch vs TensorFlow: Comparing Deep Learning Frameworks

 CEO of Label Your Data
CEO of Label Your Data