Document Digitization with OCR: Complete Guide to Converting Paper to Digital

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

TL;DR
- OCR transforms physical documents into searchable digital files through scanning, text extraction, and accessibility remediation for legal forms, IDs, banking documents, and KYC information.
- Successful digitization requires four-stage quality checking, specialized handling of tables and images, and manual intervention for complex content like formulas or damaged pages.
- Deep learning-enhanced OCR automates data extraction and reduces manual entry errors, though human review remains essential for validation and correcting recognition mistakes.
The Business Case for Going Paperless with OCR
Paperwork is known to be a major productivity bottleneck, which is why more and more companies are putting their efforts into going entirely paperless. Think about it: with 45% of office paper trashed daily, isn’t it time to ditch the hard copy and go digital?
Automating paperwork can be a game-changer for businesses, eliminating the tedium of manual work. More specifically, organizations are learning document digitization (converting physical documents to receive digital output) with the help of different advanced techniques. One of them is Optical Character Recognition.
The reason for such increased interest in document digitization is that it reduces clutter and saves lots of space, all while providing easier accessibility and enhanced security. The OCR technology, in turn, is used to recognize text in the scanned documents using deep learning algorithms, making it an ideal solution for digitizing hard copy documents.
Given that most businesses are on their way to paperless offices, we think the time is ripe for you to learn more about intelligent document processing and how Optical Character Recognition is used to digitize documents.
How OCR Technology Enables Document Digitization

Imagine being able to transform any type of information, whether it’s text, audio, or visual, into a language that computers can understand and process. That’s exactly what digitization of documents is all about.
This cutting-edge process involves converting analog data into a digital format that is made up of binary code, or bits, which computers can easily process. Once in this form, the information can be stored, shared, and accessed in a way that was never before possible.
With digitization, the possibilities for organizing and utilizing information are truly limitless. By converting handwritten or printed text into digital format, OCR enables users to edit, search, and share documents electronically with ease. Besides, the application of OCR technology can greatly accelerate document processing tasks, ultimately leading to cost savings and improved productivity.
What can you turn into digital format? Thanks to OCR technology that uses deep learning, you can now digitize a variety of documents, including:
- Legal forms, such as those used for government procedures and tax filings
- Identification cards, including driver’s licenses and passports
- Banking documents, such as passbooks, account statements, and checks
- KYC (Know Your Customer) information, such as proof of address and ID cards
- License plates in various languages
- Numbers on shipping containers, regardless of their orientation
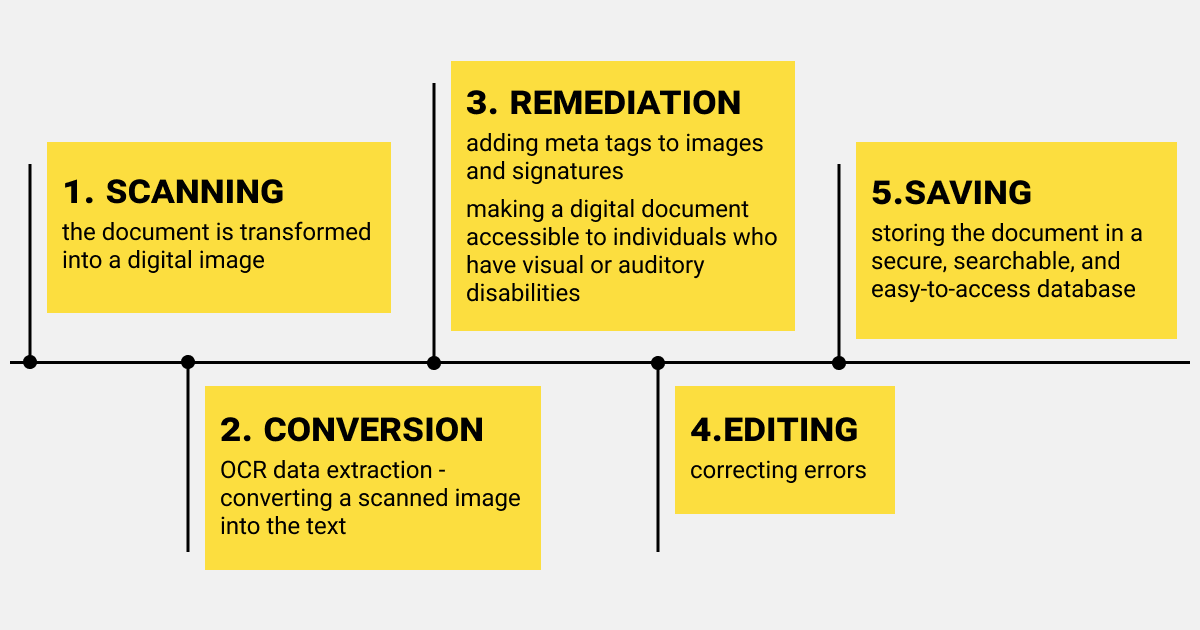
The three stages of OCR document digitization
The digitization of documents can be performed using a scanner and the OCR technology, which involves a number of steps:
Document scanning
When documents are scanned, they are transformed into digital images or electronic copies of the original paper document. However, these images lack any intelligence and cannot be searched or edited by cutting and pasting into other documents.
Document conversion
Document conversion involves more than just basic scanning. It also includes OCR data extraction technology, which converts the scanned image into the text that can be easily searched and edited. OCR also facilitates the data export stages.
Document remediation
Document remediation takes this process to the next level by adding meta tags to images and signatures. It also reorders tables and columns for use with assistive technologies (e.g., screen readers). This process transforms a regular digital document into a resource that is accessible to individuals who have visual or auditory disabilities.
Overcoming Technical Challenges in OCR Digitization
As AI in business continues reinventing how modern industries operate, the integration of OCR technology in data digitization has emerged as a transformational tool, providing a reliable, swift, and accurate alternative to traditional document handling.
The OCR technique for the digitization of documents varies significantly across different software, and mastering each one necessitates a significant investment of effort. But either way, there are four key areas that require specific focus: quality assurance, tabular data, graphical content, and specialized material.
If you want to learn how to digitize documents, here’s a short guide from us:
Step 1: Quality check
In general, four quality checks are conducted for the digitization of files:
- The first one is done during the OCR process, where the built-in spell-checker of the OCR program flags any doubtful letter while displaying the image of the word to facilitate error correction.
- The second one is a comprehensive examination of the text after OCR, which verifies the absence of missing pages, chapters, paragraphs, and tables. It is also essential to review titles and chapter headings.
- The third check involves using an advanced dictionary to perform a spelling check, and adding complex scientific and technical terms to the spell-checker.
- Finally, an independent person needs to review the finished document for any errors, table and image problems, tagging, and overall text appearance before the document can be considered ready for digital dissemination.
Step 2: Dealing with image and tabular data
To optimize image data for clarity and visibility, different image types require specific scanning and saving methods:
- Black-and-white line art must be scanned in line art mode and saved as GIF or PNG files.
- Black-and white photographs should be scanned in grayscale mode and saved as GIF or JPEG files.
- Color photographs must be scanned in color mode and saved as JPEG files, while medium-quality JPEG provides sufficient resolution.
It is essential to optimize images since they use up most of the space on a hard disk or CD-ROM. To save space, irrelevant images can be omitted, and batch-processing programs can be used to resize or enhance all images at once after scanning.
Tables, on the other hand, also pose a challenge to OCR programs due to their complex structure and significant amount of data, making them hard to check for errors.
However, there are three primary ways to handle tables:
- One approach is to scan them as black-and-white images, which is the easiest but consumes more memory and can have low resolution.
- Alternatively, tables can be manually recreated by typing the data, which saves time but may lead to errors, such as merged columns or unrecognized punctuation marks.
- To ensure table accuracy, concentrated effort, intensive proofreading, careful checking, and good quality control are necessary.
Step 3: Specialized material in the digitization of files
Specialized content in documents may include special characters, mathematical formulas, non-native language characters, and challenging pages. OCR programs should be set to the specific language being read to ensure accurate recognition of diacritical marks.
Formulas may require manual recreation, which can be done in a word processor such as Microsoft Word. In some cases, damaged pages or those with complex content may need to be retyped manually when a clear image cannot be obtained through scanning.
How to Digitize Documents with OCR and Deep Learning: A Hands-On Example
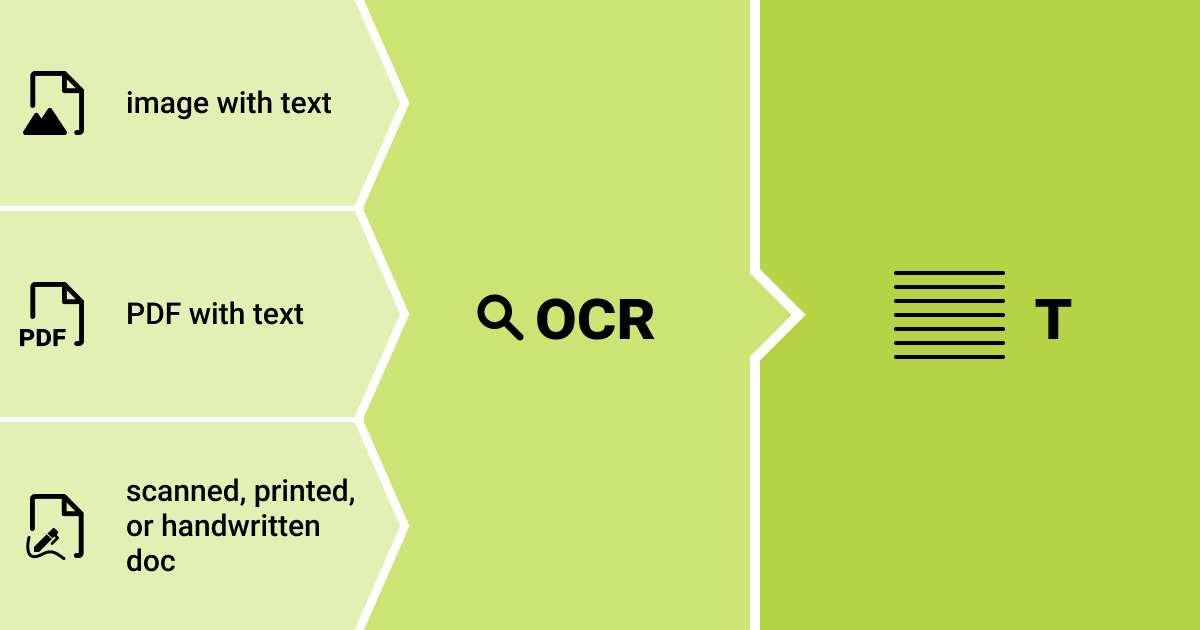
The integration of deep learning and OCR has advanced the process of digitizing documents by extracting both structured and unstructured data from images. Moreover, this technology enables automation of the digitization process, making manual data entry procedures easier with lower error rates, improved storage, and faster response times.
However, one important thing should be noted: OCR alone cannot replace the need for manual data entry as you still have to import, categorize, extract, and validate data from documents.
Now, let’s take a look at an example of document digitization with OCR to see how it works in practice. Say a law firm wants to digitize a document, such as a paper-based client intake form, to improve efficiency and reduce storage costs. They decide to use OCR software to convert the forms into searchable digital files.
Here’s the process they would follow to digitize the document:
- Prep work: The team sorts and organizes the paper intake forms by client and removes any staples, paperclips, or other obstructions that could interfere with the OCR process.
- Scanning: A scanner is used to create high-quality digital images of the intake forms. They save the scanned images as PDF files.
- OCR software: The OCR software helps to convert the scanned images into searchable text. By analyzing the images and recognizing the characters, it converts them into digital text.
- Editing: The OCR software may not recognize every character correctly, especially if the original form was handwritten or had other irregularities. The law firm reviews the digital text and corrects any errors manually.
- Saving and storage: The final digitized files are saved in a secure, searchable database. The files can be accessed quickly and easily, without the need for physical storage.
As you can see, digitizing client intake forms streamlines processes, improves efficiency, reduces storage needs, and increases data security by storing digital files in a secure database.
The possibilities are endless when it comes to the practical applications of the digitization of files, and this is just a glimpse into the great potential of OCR technology.
The Future of Document Management with OCR
It's becoming clear that OCR and deep learning have opened up exciting new possibilities for digitization of documents. As the saying goes, time is of the essence, and with document digitization, time is exactly what you’ll gain.
By harnessing the power of these cutting-edge technologies, organizations can transform the way they manage information, unlocking valuable insights that were previously hidden in paper documents. So we say, pushing towards a more digital future and embracing OCR technology will give businesses an edge in today’s fast-paced world.
About Label Your Data
If you choose to delegate OCR data labeling, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What does the process of digitization look like?
Digitization of paper documents implies the act of converting information into a digital format. The required information is grouped into multiple-bit groups called bytes.
What is the best way to digitize documents?
The best way to digitize documents is by using OCR software or specialized scanners that convert physical documents into digital files.
How can the process of document digitization benefit your business?
If the business decides to digitize files, it can capitalize on increased efficiency, cost savings, and improved data accessibility.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.