When thinking of AI, machine learning and smart computers, we tend to imagine something very contemporary, something that has appeared only recently. Many would indeed be surprised to know that machine learning history has started back in the 40s with a very important book on human cognition, and it has been accelerating only recently due to the development of new algorithms and methods but also due to the wide availability of the technology itself. It is impossible to pinpoint when machine learning was invented or who invented it, rather, it is a combination of many individuals' work, who contributed with separate inventions, algorithms or frameworks.
Machine Learning Timeline
1943
Warren McCulloch (left) and Walter Pitts (right) Machine learning history starts with the first mathematical model of neural networks presented in the scientific paper "A logical calculus of the ideas immanent in nervous activity" by Walter Pitts and Warren McCulloch.
1949
'The Organization of Behavior' by Donald Hebb, New York (1949). The book "The Organization of Behavior" by Donald Hebb is published. This book has theories on how behavior relates to neural networks and brain activity and is about to become one of the monumental pillars of machine learning development.
1950s
Arthur Samuel and IBM 700 (February 24, 1956)Arthur Samuel, a pioneer in machine learning, created a program for playing championship-level computer checkers. Instead of researching each and every possible path, the game used alpha-beta pruning that measured chances of winning. Additionally, Samuel utilized a minimax algorithm (which is still widely used for games today) of finding the optimal move, assuming that the opponent is also playing optimally. He also designed mechanisms for his program to continuously improve, for instance, by remembering previous checker moves and comparing them with chances of winning. Arthur Samuel is the first person to come up with and popularize the term "machine learning".
1951
Marvin Minsky (left), Dean Edmonds (right) and the SNARC machine with 40 Hebb synapses. When most computers still used punched cards to run, Marvin Minsky and Dean Edmonds built the first artificial neural network, consisting of 40 interconnected neurons with short- and long-term memory.
1956
Marvin Minsky, Claude Shannon, Ray Solomonoff and other scientists at the Dartmouth Summer Research Project on Artificial Intelligence (1955)The Dartmouth Workshop is sometimes referred to as "the birthplace of artificial intelligence". During a two-month period, a group of prominent scientists in the fields of math, engineering, computer and cognitive sciences have gathered to establish and brainstorm the fields of AI and ML research.
1965
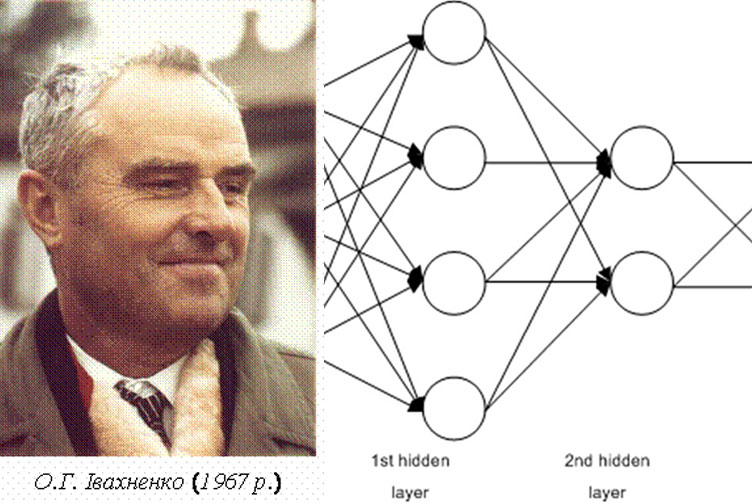
Alexey (Oleksii) Ivakhnenko and first Deep Neural Network (1967) Ukrainian-born soviet scientists Alexey (Oleksii) Ivakhnenko and Valentin Lapa have developed hierarchical representation of neural network that uses polynomial activation function and are trained using Group Method of Data Handling (GMDH). It is considered as the first ever multi-layer perceptron and Ivakhnenko is often considered as the father of deep learning.
1967
First page of the article 'Nearest Neighbor Pattern Classification' by Thomas Cover (bottom) and Peter Hart (top).Thomas Cover and Peter E. Hart from Stanford publish an article in IEEE Transactions on Information Theory (Volume: 13, Issue: 1, January 1967, pages 22-27) about the nearest neighbor algorithm (used for classification and regression in machine learning).
1979
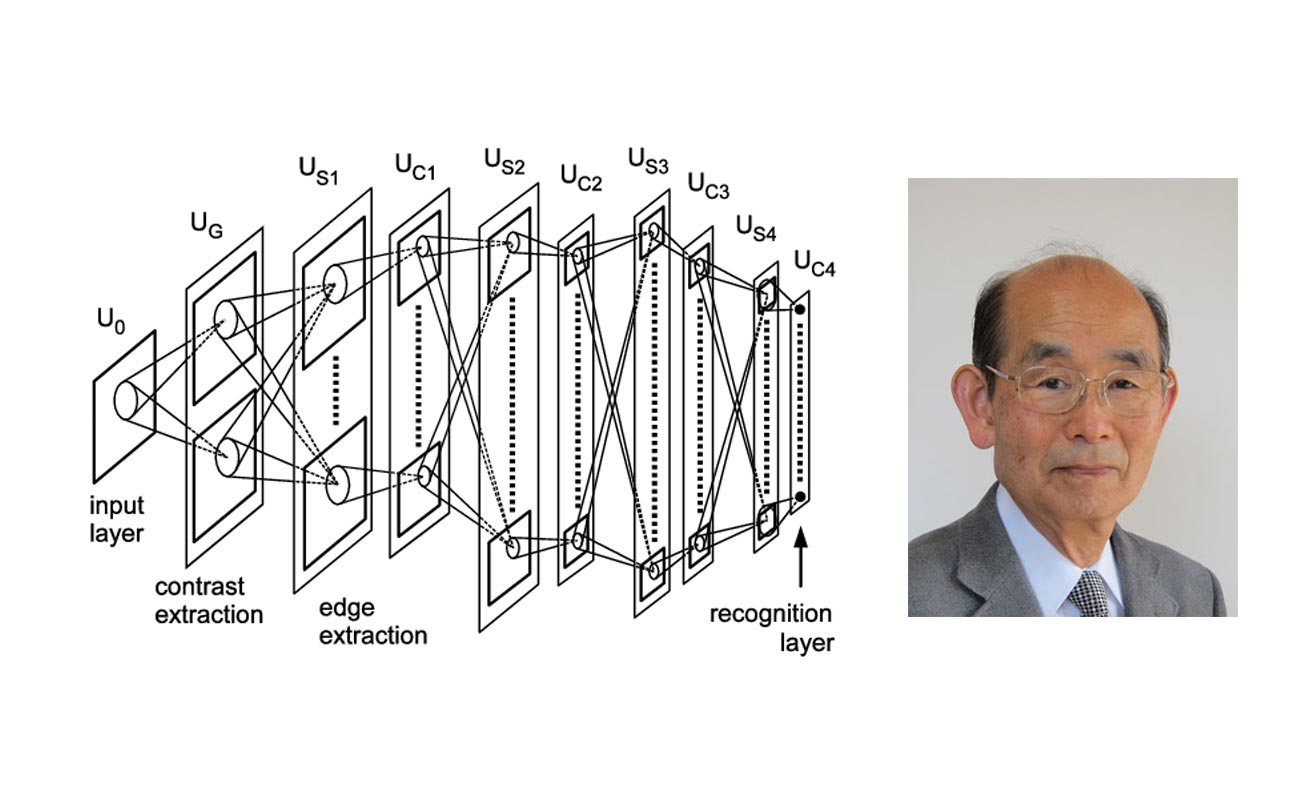
Kunihiko Fukushima and the architecture of the Neocognitron. Japanese computer scientist Kunihiko Fukushima publishes his work on neocognitron, a hierarchical multilayered network which is used to detect patterns and inspires convolutional neural networks — systems used nowadays for analyzing images.
1979
Stanford cart autonomously avoids objects.Stanford cart, a project in development since the 60s, has reached an important milestone. It was a remotely controlled robot, which could move around the space autonomously with 3D mapping and navigation.
1985
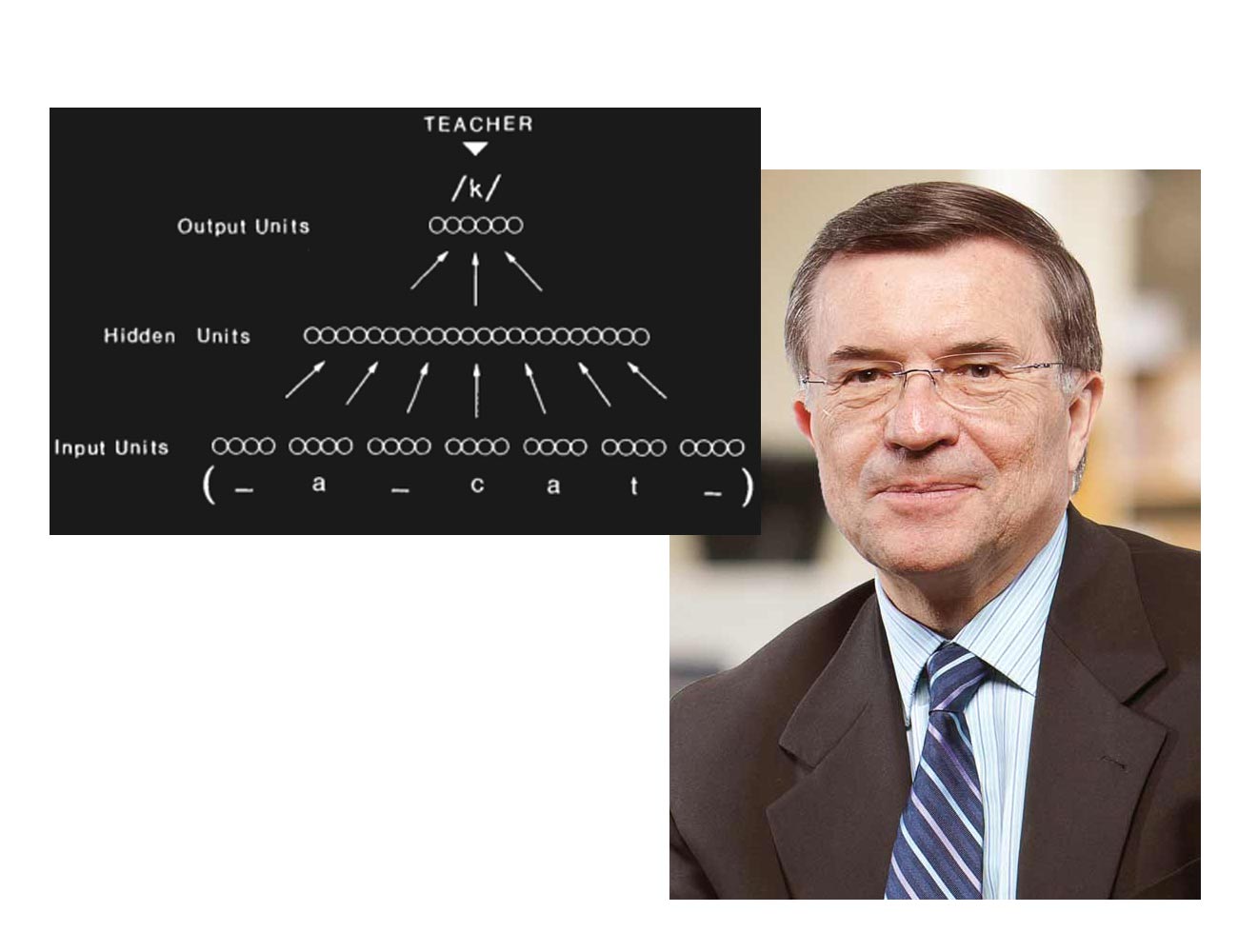
NETtalk network architecture from Sejnowski and RosenbergTerrence Sejnowski, combining his knowledge in biology and neural networks, invents NETtalk, a program with a purpose of breaking down and simplifying models of human cognitive tasks in order for machine to potentially learn how to perform them. His program learns to pronounce English words the same way a baby does.
1986
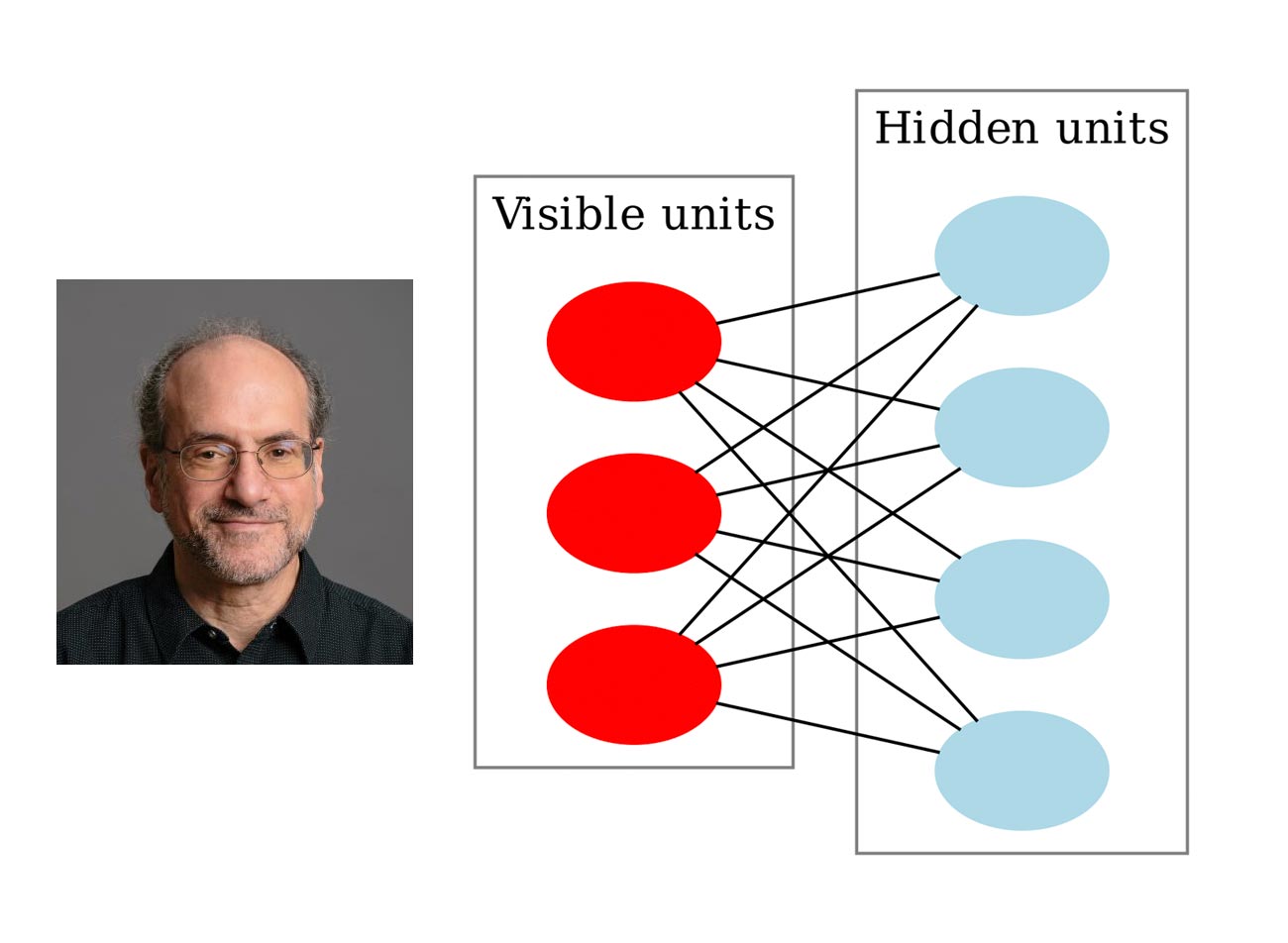
Paul Smolensky and the scheme of the Restricted Boltzmann Machine (RBM) Cognitive scientist Paul Smolensky comes up with a Restricted Boltzmann machine (RBM) which can analyze a set of inputs and learn probability distribution from them. Nowadays, this algorithm is popular for topic modeling (for instance, based on the most popular words in an article, AI determines its possible topics) or for AI-powered recommendations (based on previous purchases, what are you likely to buy next).
1990
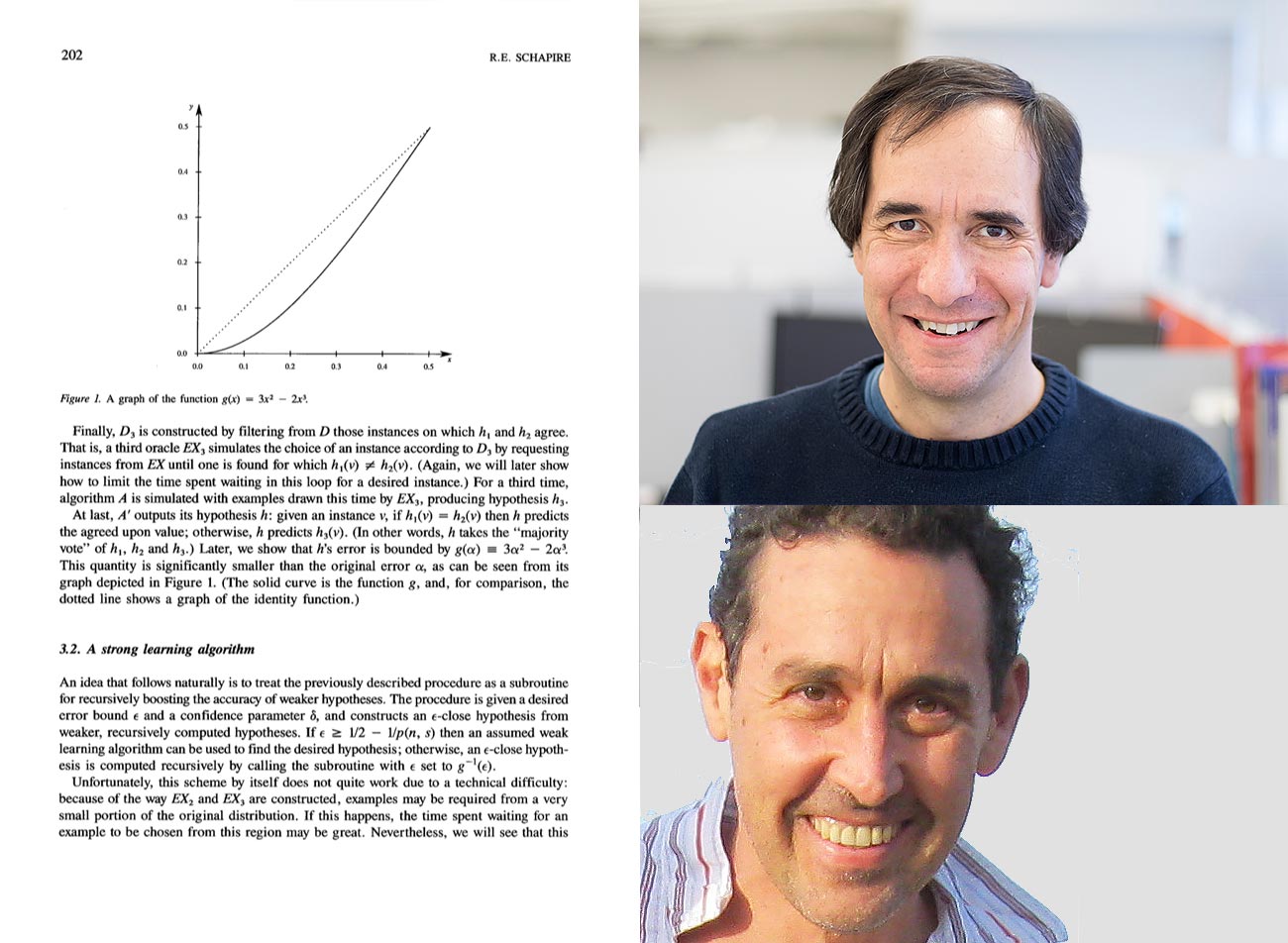
Robert Schapire (top) and Yoav Freund (bottom) Paper “The Strength of Weak Learnability” by Robert Schapire and Yoav Freund introduce boosting for machine learning. Boosting is an algorithm which aims to enhance predicting power of an AI model. Instead of using a single strong model, it generates many weak models and converts them into strong ones by combining their predictions (usually, using averages or voting).
1995
Tin Kam Ho, Random decision forests (1995)Random decision forests are introduced in a paper published by Tin Kam Ho. This algorithm creates and merges multiple AI decisions into a "forest". When relying on multiple different decision trees, the model significantly improves in its accuracy and decision-making.
1997
Video Rewrite presentation by Bregler, Covell and Slaney Video Rewrite program — first "deepfake" software is developed by Christoph Bregler, Michele Covell and Malcolm Slaney.
1997
Garry Kasparov (left) and IBM Deep Blue with operator (right) IBM chess computer, Deep Blue, beats world champion Garry Kasparov in chess. At the time this achievement was seen as a proof of machines catching up to human intelligence.
2000
Igor Aizenberg, 'Multi-Valued and Universal Binary Neurons' Book Cover (2000) First mention of the term "deep learning" by a Ukrainian-born neural networks researcher Igor Aizenberg in the context of Boolean threshold neurons.
2009
Fei-Fei Li, creator of ImageNet A massive visual database of labeled imagesImageNet is launched by Fei-Fei Li. Li wanted to expand on the data available for training algorithms, since she believed that AI and ML must have good training data that reflects the real world in order to be truly practical and useful. The Economist described the creation of this database as an exceptional event for popularizing AI throughout the whole tech community, marking the new era of deep learning history.
2011
Google Brain learns to identify cats on photos (Right: Andrew Ng, Head of Google Brain, 2011-2012) Having an extensive machine learning background, Google’s X Lab team has developed an artificial intelligence algorithm Google Brain, which later in 2012 became famously good at image processing, being able to identify cats in pictures.
2014
Goodfellow, Pouget-Abadie, Mirza, Xu, Warde-Farley, Ozair, Courville, Bengio A group of prominent scientists (Goodfellow, Pouget-Abadie, Mirza, Xu, Warde-Farley, Ozair, Courville, Bengio) develop Generative adversarial networks (GAN) frameworks that teach AI how to generate new data based on the training set.
2014
DeepFace working scheme (by Facebook)Facebook research team develops DeepFace, a deep leaning facial recognition system — nine-layer neural network trained on 4 million images of Facebook users. This AI is able to spot human faces in images with the same accuracy as humans do (approximately 97.35%).
2014
Google Sibyl LogoGoogle introduces Sibyl, a large scale machine learning system, to the public. Many novel algorithms are presented together with the system itself. For instance, parallel boosting, column-oriented data and stats in RAM — all for performance improvement. Sibyl is largely used for Google's prediction models, specifically ranking products and pages, measuring user behavior and for advertising.
2014
Eugene Goostman user interfaceEugene Goostman is the first chatbot that some regard as having passed the Turing test. It was developed by three friends-programmers, Vladimir Veselov, Eugene Demchenko and Sergey Ulasen. Eugene Goostman was portrayed as being a 13-year-old boy from Odessa, Ukraine, who has a pet guinea pig and a father who is a gynecologist. On 7 June 2014, in a Turing test competition at the Royal Society, Goostman won after 33% of the judges were convinced that the bot was human.
A conversation between Scott Aaronson and Eugene Goostman ran as follows:
Scott: Which is bigger, a shoebox or Mount Everest? Eugene: I can’t make a choice right now. I should think it out later. And I forgot to ask you where you are from… Scott: How many legs does a camel have? Eugene: Something between 2 and 4. Maybe, three? :-))) By the way, I still don’t know your specialty – or, possibly, I’ve missed it? Scott: How many legs does a millipede have? Eugene: Just two, but Chernobyl mutants may have up two five. I know you are supposed to trick me. Scott: No, I need to know that you're not a chatbot. Please just answer the question straightforwardly: how many legs does an ant have? Eugene: Something between 2 and 4. Maybe three? :-))) Oh, what a fruitful conversation ;-)
2015
DeepMind's AlphaGoAlphaGo program is the first AI to beat a professional Go player. Go is one of the oldest and hardest abstract strategy games, which was previously thought to be a near-impossible game to teach a computer.
2016
comparison of Face2Face and SenseTime A group of scientists presents Face2Face during the Conference on Computer Vision and Pattern Recognition. Its logic and algorithms are the basis of majority of today's "deepfake" software.
2017
Waymo launches commercial service in Phoenix (2017)Waymo starts testing autonomous cars in the US with backup drivers only at the back of the car. Later the same year they introduce completely autonomous taxis in the city of Phoenix.
Evolution of Machine Learning: Data labeling
We tried to provide some of the most important inventions and achievements in evolution of machine learning, though, this is still far from a comprehensive list, which would potentially include tens, if not hundreds of other scientists. At Label Your Data, we see the importance of knowing when did machine learning start and the history of AI in general as a guideline to understand the vector of the industry development and foresee the new trends. Since the availability of big data, data annotators have also left their footprint in machine learning history too. Labeling large datasets for science and businesses or even having these datasets publicly available has been assisting researchers for years in eliminating the long and bothersome, but nonetheless crucial process of data annotation.
For our partners and clients, data labeling quality and secure labeling solutions have been among the priorities for choosing us, so we continue developing and improving our services in these angles.
Become a part of ML and DL history — deploy your project faster by outsourcing data annotation: Get your quote now →
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.
Read Next
When Definition and Context Matter the Most: Addressing Specific Data Labeling Requests

 CEO of Label Your Data
CEO of Label Your Data