Annotating Data: What Does It Mean and How Is It Done?

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

Despite having quite a history under its belt, artificial intelligence seems to just start its journey to popularity in the public mindset. On the other hand, there’s literally no industry today that has no way to benefit from utilizing the possibilities of AI and machine learning.
And that’s no wonder. Both AI and ML offer automation of business processes and predictive analytics, along with a whole bunch of other solutions that are crucial for modern businesses.
However, even though business owners strive to adopt some sort of artificial intelligence and machine learning, there’s rarely a thorough understanding of the process and its essential steps. Instead, businesses with core goals focused on a sphere different from data science have a general desire to benefit from adopting an AI mindset.
But how is it being done? What are the main things to think about when planning an AI project? Where to find the right people? Can you outsource parts of the project to expert partners?
And what, in the name of AI, is that data annotation everyone’s talking about?
Well, worry no more. We’ve put a comprehensive guide for you to understand what data annotation means, why you need it, and how it is being done. Let’s dig in, shall we?
Data Annotation: Meaning and Importance
So let’s say you’ve started to plan your AI project. You’ve mapped out the major steps (from collecting the data to algorithm design to implementing it with your business platforms). You’ve allocated the necessary resources and even gathered a team of engineers to build the algorithm and data scientists to collect, analyze, and process the data. So why do you also need data annotation?
Well, because, if you want great results, you have to properly train your algorithm. You can just feed some data into it, unlabeled as it is, and even get certain benefits. However, your opportunities will be quite limited by what a machine learning algorithm can do.
This is because machines do not think as humans do. We possess the natural flexibility of the mind to understand interdependent connections and the ability to grasp the differences in data when we see them. A machine needs to be taught how to see those differences and make connections. It needs to be trained to think like a human being.
For this, you need labels.
Data Labeling vs Annotation: Is There a Difference?
What’s labeling, you ask? We were just talking about annotation, and now there’s a new concept to understand.
Don’t worry! In reality, there’s no real difference between these two terms. Both data labeling and data annotation are used to refer to the same thing: it’s a process of adding meaningful labels (also known as tags or sometimes classes) to a specific set of data in order to explain to a machine learning algorithm what that data is.
And there are quite a few annotation tasks that are used to explain how to interpret different types of data to a machine. We at Label Your Data specialize in a variety of labeling tasks, starting with semantic segmentation and 2D boxes for computer vision (CV) and ending with optical character recognition for NLP (an abbreviation for Natural Language Processing).
But let’s take this slow and first how data annotation helps in training an ML algorithm to think as a human does.
How Is Data Annotation for AI Done?
Before you start working with your data, you obviously need to collect it. The format depends on the type of task you want your data to perform. If building an image recognition system, you’ll need to collect several thousand pictures with objects that your system will be trained to detect. If you need an automation tool that turns the pages of handwritten text into text files that you share and edit, you’re looking for an OCR algorithm that needs to look through tens of thousands of pages of text data.
Actually, here’s a good question no one knows a real answer to: how much data do you need?
The general consensus is this: the more data you have, the better. This is called big data, which means that you use AI to see the hidden patterns in a vast amount of data. A good example would be a retail online store forming a flexible and ever-updating recommendation system. Such a system uses AI to predict items that users prefer to buy together, and offer these items to other users with a similar background, gender, and age.
There is the possibility of overfitting (or overtraining) your model. However, in modern realities, getting your hands on good data is quite an expensive and long process, so it’s unlikely it’ll be your foremost problem. It’s better to concentrate instead on getting the best data possible because, as the saying goes, garbage in – garbage out.
The Labeling Challenge: Hired Professionals vs. Data Annotation Companies

When your data is collected and you’ve made sure it’s clean and perfect and ready to be labeled, you have to make a decision. Data annotation is a very long and tedious process.
In fact, it’s so laborious that, at the current moment, nearly 80% of all work related to an AI project is being done to process and annotate the data. This creates a narrow bottleneck that requires developers to wait until the data is ready before they can proceed with training the algorithm and implementing it in practical settings.
For this reason, a lot of businesses opt to outsource this part of an AI project to an annotation partner. This allows focusing on the core processes and building an algorithm while the data is being annotated. It’s beneficial in terms of saving costs, time, and expert effort.
However, if you plan to do it yourself, we have a more comprehensive guide on how exactly a data annotator’s work is being done. This guide covers the major steps of the labeling process in different fields of AI (computer vision and NLP), as well as discusses the advantages and disadvantages of human annotators.
Types of Data Annotation: CV & NLP
Now, what are these fields and types of data annotation we’ve been mentioning now and again? Well, there are different types of data, and they should be treated differently. You cannot add the same labels to a piece of text and a photograph (even if it’s a photo of that piece of text).
There are two fields of AI that cover the majority of data annotation tasks:
- Computer vision. As the name suggests, this field works with visual formats of data such as images, photos, and videos. Within the computer vision field, you’ll find tasks such as facial recognition, movement detection, autonomous driving, etc.
- NLP. This field deals primarily with textual and audio data, although there are exceptions like OCR that works with images of text. The tasks of natural language programming aim to teach the machines to understand how people talk in our natural languages.
There are also a few freestanding data annotation tasks that use alternative types of data. For example, LiDAR uses lasers and RADAR uses waves to measure distances. They create a 3D cloud of data points later used by an algorithm to “see” the surrounding environment.
Let’s go through a few of the most popular types of data annotation for both CV and NLP.
Data Annotation Types in Computer Vision
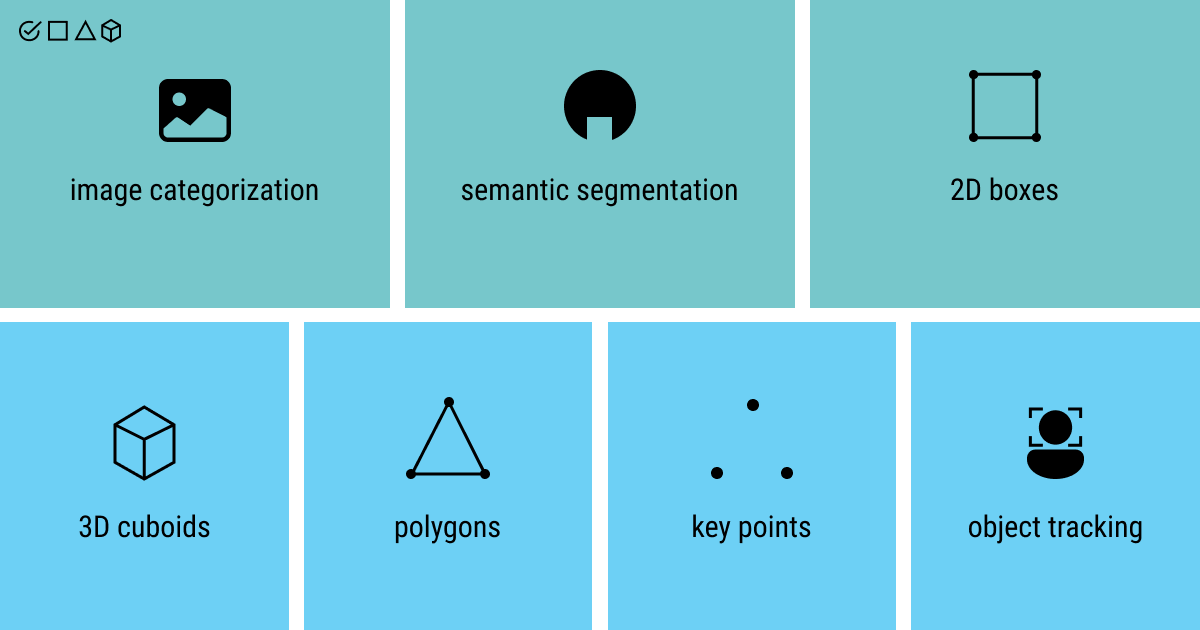
Computer vision is among the hottest AI projects at the moment. You can find it in organizational and manufacturing settings (development of autonomous driving models), on your phone (things like facial recognition or automated classification of images), and in public spheres (emotion recognition for remote education).
Let’s see what types of data annotation tasks enable such a popular swing of computer vision algorithms.
Image Categorization
Also known as image classification, this is one of the most widely pursued types of tasks in machine learning. Categorization allows training an ML algorithm to group images into predefined classes. After training, a machine learning model will be able to identify which object is detected on the photo based on these classes.
For example, if you train your model to recognize different styles of furniture, it might be able to tell the differences between a Georgian and a rococo armchair.
Semantic Segmentation
A human can see the objects in the image as separate entities. To train a machine to do the same, semantic segmentation associates each pixel of an image with a certain object class (e.g., tree, vehicle, human, building, highway, sky). Then the ML model clusters together same-class pixels.
As a result, it creates a map with clusters of different object classes that allows the machine to train to “see” the separate objects on the picture.
2D boxes
The alternative name to this popular type of data annotation is bounding boxes. And the name says it all: 2D boxes annotation is about drawing frames around the objects on an image. These can be cars (relevant for autonomous driving projects), people (often found in smart CV cameras with movement detection, household objects )essential in architecture algorithms), etc.
The machine then learns to classify the objects with similar parameters into predefined categories (cars, people, household objects, and so on).
3D Cuboids
Similar to 2D boxes, 3D cuboids add an additional dimension to the initial frame around an object. This data annotation type is used in AI projects to add an in-depth perspective to a two-dimensional image.
With the third dimension added, you get not only the size and position of the object in the space on an image but also rotation, relative position, and even the prediction of movement.
Polygonal Annotation
Frames are commonly not enough to train an ML algorithm as it doesn’t allow for the quick capturing of an object’s shape. As an alternative, polygonal annotation is used to draw complex outlines around objects with complicated (think curvy) or varying numbers of sides.
Polygons train the machines to recognize the objects and their position in space based on their shape. Thus, you can explain to your model what is a lamp and what’s a vase in the interior design project, or what types of those objects they are.
Keypoint annotation
While man made objects are simpler to explain to an algorithm than natural objects, there is a type of annotation that is aimed directly at that. By defining the main (key) points for a natural object, keypoint (aka landmark) annotation trains an ML algorithm to predict the shapes and movement of said objects.
Keypoint annotation is commonly used for facial and emotion recognition, tracking the movement of people (such as sports players or in exercise apps) and animals, etc. Interestingly, due to its versatility, this type of data annotation can also be used to track the position of manmade objects.
Object Tracking
Object tracking is the type of data annotation primarily used in video labeling tasks. Annotating a video is quite similar to annotating an image but it takes more time and effort.
First of all, it is required to break up a video into separate frames. Then each of the frames is treated as a separate image. Object detection is essential as it allows creating links between different frames, explaining to the algorithm, which objects appear in different positions on different frames. This is achieved by separating an object (usually moving) and contrasting it against the background (usually static) on every frame.
Data Annotation Types in NLP

While computer vision is all the rage now, NLP has been around for a while and has a lot of uses that the regular public doesn’t really think about. However, NLP surrounds us: voice recognition assistants, cameras that scan QR codes, CRM systems that fill up customer profiles after a single call; all of these and many more require NLP data annotation tasks.
Text Classification
Arguably the biggest NLP task is text classification that allows the grouping of texts based on their content. For this, the key phrases and words are used as tags to explain an ML algorithm what to look for in a text to classify it.
E.g., automatic filters in your email are a good example of text classification: based on the cues inside an email, certain messages can be marked as “spam”, “promotions”, “updates”, etc.
OCR
Business today still thrives on paper. However, more and more people recognize the value of automation brought by electronic workflows. Switching between the two is a cumbersome task and a perfect case for the OCR data annotation task. It allows deciphering images of text (both typed and free, such as handwritten) into text readable by a machine.
Not only in business, but OCR is also big in a lot of other AI projects. For example, CV cameras along the roads use it to scan license plates. You can use OCR to translate a phrase written in a different language into your own. The possibilities are limitless – actually, we have a thorough guide on OCR in our blog, read to learn more.
NER
Another case of automation, named entity recognition shortened to NER, is based on the detection and categorization of “entities” or, simply put, specific words or phrases in a text. These can be anything from names and places to dates, prices, and order numbers.
While it may seem a little too straightforward at first glance, imagine having to deal with large volumes of text. Without the help of a machine trained with NER data annotation, you’d spend multiple hours looking for specific information. NER automates this task for you to focus on the activities that matter most.
Intent/Sentiment Analysis
This one is actually two types of data annotation rolled into one. First, sentiment analysis is the analysis of a text and its classification based on the tone of the messages. The most common example is dividing the tone between positive, neutral, and negative (although there can be a wide variety of tones including friendly or angry). This type of data annotation is commonly used in market research to understand customer satisfaction, for the monitoring of public opinions, and for building and monitoring brand reputation.
The second part of this data annotation task, Intent analysis is used to identify the intention hidden in a text. These can be quite varied, as well: from making a purchase to looking for help to placing a complaint, etc. Overall, this data annotation task helps to automate the process of collection of customer reviews. It also allows building the hierarchy of prioritization for complex systems (such as CRM systems).
Audio-To-Text Transcription
Not only text but also audio, this annotation task aims to combine the two formats. It’s used to teach an ML algorithm to transform audio into text.
It’s quite useful both on its own (to transcribe messages from speech to text), as well as in the combination with other NLP data annotation tasks (for example, together with intent & sentiment analysis for building a voice recognition model in virtual assistants like Alexa or Siri).
TL;DR: Data Annotation Advantages and Short Process Summary

So what is data annotation, in the end? To put it shortly, it’s a crucial step in building and training a flexible and high-performing ML algorithm. It can be skipped when only a limited function of the algorithm is needed. But, in the era of big data and high competitiveness, data annotation becomes quintessential as it teaches the machines how to see, hear, and write the way humans do.
Aside from its advantages, data annotation can be a tedious and laborious task. It takes a lot of time and manual work, which is why a lot of businesses look for data annotation partners instead of doing it themselves. If you’re looking for such a partner for your AI project, contact Label Your Data now – we’ll tell you everything you need to know about data annotation, its major types, and what we can do to make your ML algorithm work for you!
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.