How to Build a Solid Data Annotation Strategy

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

Machine learning, deep learning, data analysis, and NLP help 48% of businesses to get the most out of their large datasets. However, without a sound data annotation strategy in place, these advanced technologies may fall short in delivering optimal results.
For machine learning projects, a well-thought-of annotation strategy guarantees effective model performance. We decided to explore the essentials of developing such a strategy, covering key considerations, methodologies, and our best practices.
From selecting appropriate annotation types to mitigating biases, this guide will equip you with the insights necessary for building a data labeling strategy and creating a dataset tailored to your specific ML project needs.
Top 5 Data Annotation Tactics in Machine Learning
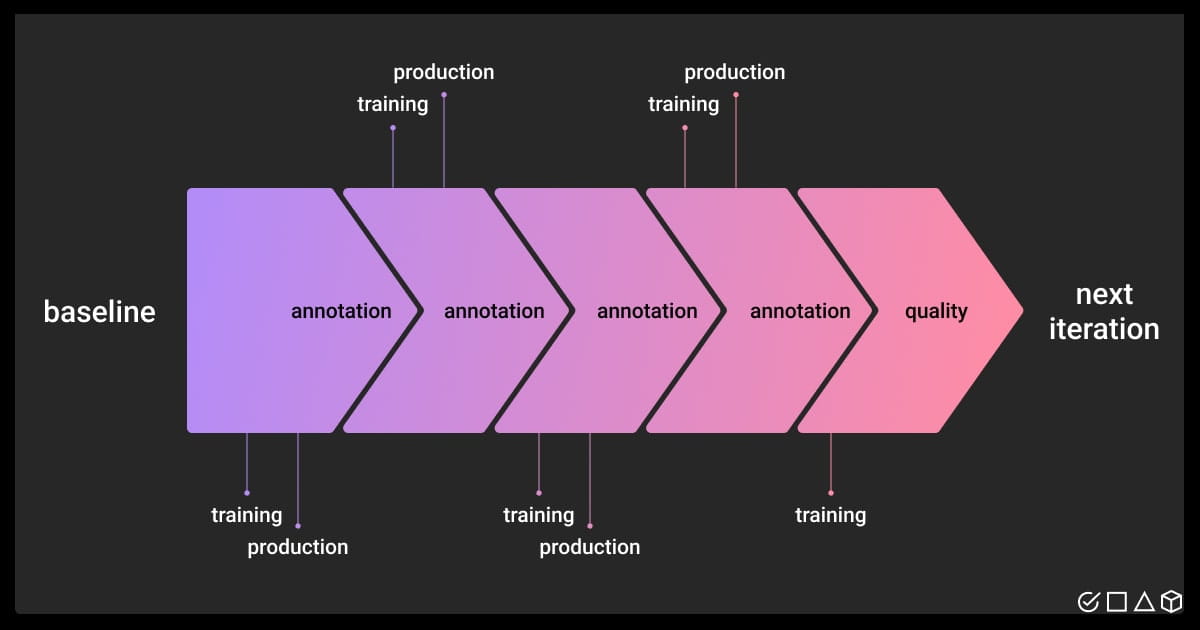
Building a robust data annotation strategy is crucial for the success of your ML project. This strategy essentially defines a set of tactics that determine how you’ll label your data. Selecting the right tactics depends on various factors specific to your project.
Here’s a breakdown of the key data labeling tactics to help you decide which ones work best for your project:
1. Manual Labeling vs. Automated Labeling
Manual labeling. This involves human annotators identifying and assigning labels to specific elements within your data points.
- Pros: Ensures high accuracy, allows for complex labeling tasks, and provides greater control over quality.
- Cons: Time-consuming, expensive (especially for large datasets), and prone to human error.
Automated labeling. This tactic utilizes ML algorithms to label your data points, reducing the need for manual human intervention. Automatic annotation greatly assists when dealing with large datasets. For instance, AI models like Grounding-DINO and Segment Anything Model (SAM), when combined, can be a powerful tool for object detection and segmentation in images. For text data, you can opt for AI models like BERT, Longformer, Flair, and CRFs that offer functionalities more tailored to the labeling tasks.
- Pros: Saves time and cost for vast datasets, reduces human error for simpler tasks.
- Cons: Accuracy can be lower than manual labeling, might not be suitable for complex tasks, requires high-quality training data for the automation tool itself.
Pro tip:
Choose manual labeling for small datasets, critical tasks requiring high accuracy, or projects with complex labeling needs. However, when you have large datasets but simpler tasks, it’s better to use automated labeling. This tactic can also be used as a pre-labeling step to improve efficiency in manual labeling workflows.

 CEO of Label Your Data
CEO of Label Your Data
2. In-House Labeling vs. External Labeling
In-house labeling involves building and managing your own team of annotators within your organization. In external labeling, there are two main approaches to external labeling: crowdsourcing and a dedicated labeling service. For a more in-depth comparison of in-house and external labeling, as well as tips on choosing the best approach for your needs, see the final chapter of this guide.
3. Open-Source vs. Commercial Labeling Tools
Open-source tools. Freely available software with the underlying code accessible to the public. Anyone can contribute to their development and improvement.
- Pros: Free to use and modify, allows for customization to specific needs.
- Cons: They can’t cover specific use cases, lack bulk data import/export via API, and require relying on community forums for help instead of dedicated support. Additionally, their functionality might be limited by the size of your dataset, and any customization often requires developer assistance.
Commercial tools. They are developed and offered by private companies and typically require a subscription or license fee for use. Some popular options include Labelbox, SuperAnnotate, and Amazon SageMaker Ground Truth data labeling tools.
- Pros: Wide range of features for various labeling tasks, user-friendly interfaces, often include data security and quality control measures, provide technical support.
- Cons: Can be expensive, might have limitations on customization.
Pro tip:
If you have the technical expertise and a small project with specific needs, open-source tools can be a good option. For most projects, especially those involving large datasets, complex labeling tasks, or requiring user-friendliness and support, commercial data labeling tools are a better choice.
 Integration Specialist at Label Your Data
Integration Specialist at Label Your Data
4. Public Datasets vs. Custom Datasets
Public datasets. These are pre-labeled datasets readily available online from various sources like research institutions or government agencies. There’s a wealth of free data available online, with a few top resources to explore, such as Kaggle, UCI Machine Learning Repository, and Data.gov. They can be a valuable resource for getting started with ML projects.
- Pros: Readily available, free to use, can be a good starting point for initial training.
- Cons: Might not perfectly match your project’s use case, may have quality or bias issues, might not be suitable for all tasks (e.g., privacy-sensitive data).
Custom datasets. A custom dataset is a collection of data specifically curated and prepared for a particular task or project. Unlike public datasets that are readily available online, custom datasets are tailored to address the unique needs of your model.
- Pros: Tailored to your specific project requirements, higher quality and relevance to your task.
- Cons: Require time and resources to collect and label data.
Pro tip:
Leverage public datasets to get started quickly, test your models, or for tasks where a perfect fit isn’t crucial. Invest in building a custom dataset when public datasets can’t cover your use case.
CEO of Label Your Data
5. Cloud Data Storage vs. On-Premise Storage
Cloud storage. This tactic implies storing your data on remote servers managed by a cloud service provider (CSP) like Google Cloud Platform, Amazon Web Services (AWS), or Microsoft Azure. These providers offer scalable and readily accessible storage solutions, accessible from anywhere with an internet connection.
- Pros: Scalable storage capacity, easy access from anywhere, eliminates hardware management needs, often has built-in security features.
- Cons: Relies on internet connectivity, potential security concerns depending on the provider, can be more expensive for very large datasets over time.
On-premise storage. This involves storing your data on physical servers located within your organization’s infrastructure. You have complete control over the hardware and its maintenance.
- Pros: Provides greater control over data security, eliminates reliance on external providers, potentially lower ongoing costs for massive datasets.
- Cons: Limited scalability, requires in-house hardware management and maintenance, can be less accessible for remote collaboration.
Pro tip:
Choose cloud storage when your project requires scalability, easy collaboration, or limited in-house infrastructure. Be mindful of internet connectivity needs and ongoing costs for massive data volumes. Pick on-premise storage if your project involves highly sensitive data, strict security requirements, or predictable and large storage needs where cloud costs might outweigh benefits.
Integration Specialist at Label Your Data
Additional Tips
- Ask questions before taking actionsBefore you start the project, grasp the specific issues it’s trying to solve:
- What does your ML project aim to achieve?
- How much and what type of data is needed?
- What sources will you use to gather data?
- How much time do you need to finish the project?
- What results do you expect?
- Is the budget sufficient for the results you want?
- Plan, document, and secure your workflowsTo enhance the scalability of data operations, document annotation workflows to establish standard operating procedures (SOPs). This not only protects datasets from theft and cyber threats but also ensures a transparent and compliant data pipeline according to data labeling and data privacy guidelines.Before project commencement, make sure to:
- Establish clear processes,
- Obtain necessary labeling tools,
- Set a comprehensive budget covering tool expenses, human resources, and QA,
- Gain expert support,
- Secure resources, including operating procedures.
- Treat data annotation as an iterative processTo establish an effective strategy for data labeling ops, start with a small-scale approach. By doing so, you can learn from any minor setbacks that may arise, make necessary improvements, and then gradually expand the process. Starting small allows you to invest less time initially compared to starting with a larger dataset.Regularly monitor annotation progress and be prepared to adapt the strategy based on feedback, challenges, and evolving project needs. Once you’ve achieved a smooth operation, including the integration of appropriate labeling tools, you can move forward with scaling up the entire operation.
- Communication and consistency are your cornerstones“Data annotators are more effective when they understand the purpose behind their tasks. Summarize the guidelines by providing examples of a “gold standard” to assist in understanding complex tasks. Highlight edge cases and errors to minimize initial mistakes. Clearly communicate the evaluation criteria to annotators, preventing potential issues during reviews. Implement version control for guidelines to adapt to the ML project lifecycle.”Karyna Naminas,CEO of Label Your Data
How to Measure the Scope of the Dataset Volume to Label
To optimize annotation workflows, AI engineers and operations managers require precise dataset calculations and monthly new data generation rates. This information helps the annotation team:
- Plan for the initial annotation cycle: Knowing the total dataset volume allows for efficient resource allocation and task scheduling.
- Identify bottlenecks and staffing needs: High monthly data generation rates might necessitate streamlining the annotation process or hiring additional personnel.
We suggest taking these steps:
- Count the number of instancesDetermine the total number of data points or instances in your dataset. This could be the number of rows in a table, documents in a corpus, images in a collection, etc.
- Evaluate data complexityAssess the complexity of the data. Consider the variety and types of data and the diversity of labels or categories needed.
- Examine feature spaceIf your dataset has multiple features, assess the dimensionality of the feature space. The number and types of features can impact the annotation effort.
- Consider annotation granularityUnderstand the level of detail required for annotation. Finer granularity may require more effort (i.e., annotating each word in a document versus annotating the document as a whole).
- Understand the difficulty of the labeling taskAnnotation tasks vary in complexity. Labeling images, for instance, can include object detection, segmentation, or classification, each with differing levels of difficulty. Assess the complexity of annotating each instance, as some may be straightforward (like those in data entry services) while others demand more nuanced judgment.
- Analyze time requirementsEstimate the time required to label each data point. This can depend on the task and the expertise needed for accurate annotation.
- Account for iterative annotationIf data annotation is an iterative process, consider that some annotated data may be used to improve ML models and guide subsequent labeling efforts.
- Use sampling techniquesIf the dataset is large, you might consider sampling a subset to estimate the annotation effort required. Ensure that the sampled subset is representative of the overall dataset.
- Consult domain expertsSeek input from domain experts to understand the context and intricacies of the data. They can provide valuable insights into the annotation process.With that said, these key steps provide a foundational framework for measuring the scope of dataset volume and enhancing the effectiveness of your data labeling strategy.
Build Better Data Annotation Strategies with Label Your Data
For machine learning and AI projects, achieving a well-organized, consistent data annotation workflow depends greatly on the chosen strategy and how your manpower and data are managed.
You can continue learning about data annotating strategies and how to implement them into your ML project. Or, you can make a smart move and let experts do their job. We at Label Your Data can take care of all your data annotation needs.
FAQ
What is labeling of data in ML?
Data labeling in machine learning is the process of identifying raw data and turning it into structured information by assigning predefined tags to input examples. This enables a machine learning model to learn and make predictions based on those annotated examples.
What are the methods of annotation?
The key methods of data annotation include:
- manual annotation by human annotators,
- automated annotation using tools or algorithms,
- semi-automated approach that combines human and machine intelligence.
What is the labeling data strategy?
The labeling data strategy involves developing a systematic approach for the meticulous tagging or marking of datasets with relevant labels. The training data you get ensures the effectiveness of ML models.
Why are data annotation strategies important for an ML project?
A strategic approach in data annotation tackles domain-specific challenges, edge cases, and transforms data into a meaningful asset for model training. Data annotating strategies can greatly improve the accuracy of the model by delivering more informed predictions.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.