Supervised vs. Unsupervised Learning: Key Differences

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- Where Supervised vs Unsupervised Learning Shows Up in Practice
- Difference Between Supervised vs. Unsupervised Learning
- What Is Supervised Learning & Why It Needs Data Annotation
- What Is Unsupervised Learning & Where to Apply Unlabeled Data
- How to Choose Between Supervised vs. Unsupervised Learning
- About Label Your Data
- FAQ

TL;DR
- Supervised learning trains on labeled data and fits tasks like classification and regression.
- Unsupervised learning works with unlabeled data to find hidden patterns or groupings.
- The difference between supervised vs unsupervised learning lies in whether the data is annotated or not.
- Supervised is better for prediction; unsupervised is suited for exploration.
- Semi-supervised methods combine both when labeled data is limited.
Where Supervised vs Unsupervised Learning Shows Up in Practice
Supervised vs unsupervised learning reflects one of the earliest splits in the history of machine learning. The difference—labeled data or not—remains central to how we design pipelines, pick models, and evaluate performance. You’ll see it everywhere: from heuristics in clustering to fine-grained classification tasks across applied ML systems.
In practice, both methods drive progress in computer vision, natural language processing, and generative AI. LLMs, for example, combine pretraining on unlabeled text with supervised fine-tuning.
None of this works without data annotation—even unsupervised methods often rely on labeled validation sets. Choosing the right approach isn’t theoretical; it’s a matter of task, data access, and how much control you need over outputs.
Difference Between Supervised vs. Unsupervised Learning
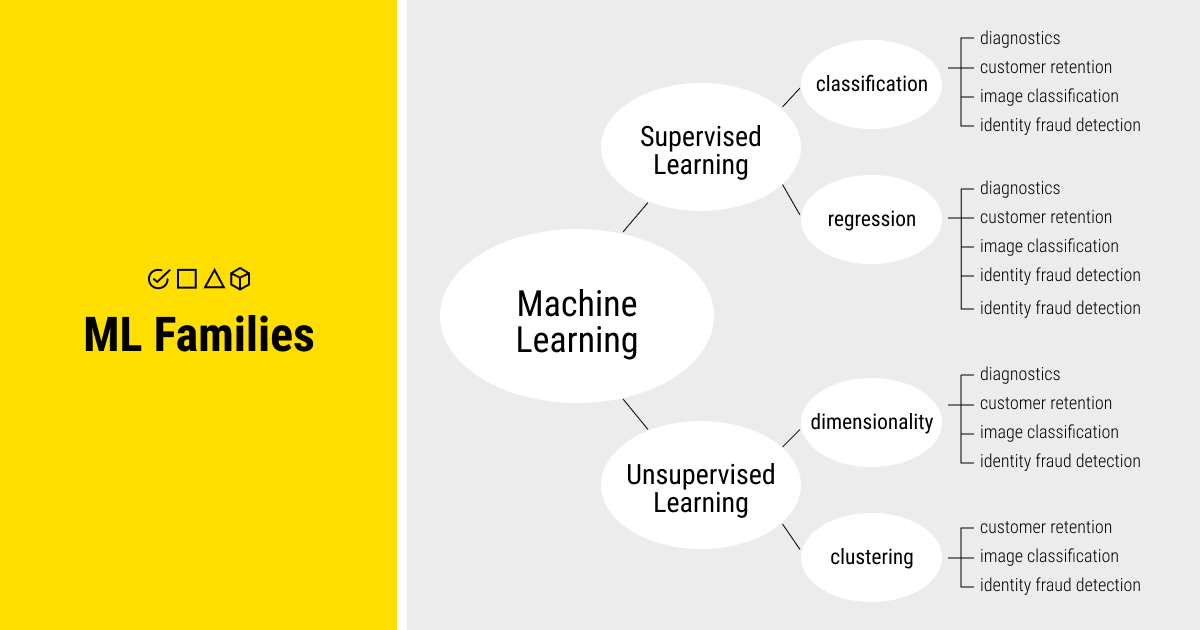
Artificial intelligence can solve a variety of problems, even those that are beyond our control. We know how machine learning can be useful for optimizing the finance or insurance industries, enhancing personalized approaches to customers, or even choosing a good wine for true connoisseurs.
So it makes sense to group different models and approaches in ML, depending on the challenge it’s tasked to address. This is why there are families of ML methods, like supervised learning and unsupervised learning, where training data has a different role for each. And the main difference between these approaches to ML is data, namely labeled data.
Before we begin exploring supervised learning vs unsupervised learning, let’s first recall how machine learning works: ML algorithms are integrated into machines and data streams to extract valuable information and knowledge, which are fed into a system to generate the desired output. For example, it can include prediction or recommendation tasks. These algorithms can be either supervised or unsupervised, or sometimes they fall under the category of reinforcement learning. The latter are the algorithms that learn from data and identify patterns in order to react to an environment. Yet, it’s much more common to distinguish between supervised and unsupervised machine learning.
| Aspect | Supervised Learning | Unsupervised Learning |
| Data Requirement | Requires labeled datasets | Works with unlabeled datasets |
| Goal | Predict outcomes for new data | Discover hidden patterns or groupings |
| Common Algorithms | Linear Regression, SVM, Decision Trees | K-Means, Hierarchical Clustering, PCA |
| Use Cases | Spam detection, sentiment analysis | Customer segmentation, anomaly detection |
| Complexity | Generally less complex, but requires labeling | More complex due to lack of labels |
Supervised vs Unsupervised Learning: Core Algorithm Types
In essence, the primary difference between these two methods of ML lies in the presence/absence of labels in the training data subset. More specifically, supervised algorithms require the training data to perform analytical tasks before they build contingent functions to map fresh instances of the attribute. The classification and regression algorithms are the two main types of supervised ML.
Unsupervised algorithms, on the other hand, don’t require an annotated training dataset. Instead, this method is based on pattern recognition, with no need for a target attribute. This means that all the variables are used as inputs, which is best suited for clustering and association mining techniques in ML. Unsupervised algorithms can identify inherent groupings within the unlabeled data and then apply labels to each data point.
| Type of ML | Algorithms |
| Supervised Learning | - Linear Regression - Support Vector Machines (SVM) - Decision Trees - Random Forest - Naïve Bayes |
| Unsupervised Learning | - K-Means Clustering - Hierarchical Clustering - Principal Component Analysis (PCA) - Autoencoders - DBSCAN |
Supervised vs. Unsupervised Classification
Supervised classification models learn by example how to answer a predefined question about each data point. In contrast, unsupervised models are, by nature, exploratory and there’s no right or wrong output. Supervised learning relies on labeled data and learns from it. The example that the supervised model learns from is the unique cognitive capacity of humans to extract meaning from context, which machines still lack to develop. A training model is used in supervised classification to cluster new inputs into predetermined categories that are applicable during training.
This distinction is a key part of understanding how supervised vs unsupervised machine learning applies across real-world classification tasks.
Conversely, there’s no annotated data (aka labels) in an unsupervised classification method. When using this method, you must examine the input to identify the structure of the data, and then classify or cluster it based on the structure. Inputs are fed into the model, but the category of each output is not specified. The training inputs are clustered into groups with similar characteristics.
Therefore, the goal of supervised learning is to predict new data outputs. The type of results is known upfront. In unsupervised learning, however, the purpose is to extract knowledge from huge amounts of data because, in this method, the algorithm identifies the unusual or interesting attributes in the dataset on its own.
What Is Supervised Learning & Why It Needs Data Annotation

Judging by the name of this ML method, there’s obviously something that is being supervised. That is, a machine learning model that is supervised by a data expert. Simply put, you inform the system of the appropriate output for a given input in supervised learning.
Supervised learning relies on the expertise of a data scientist, who trains a machine learning algorithm with labeled inputs of data to get the desired output. For instance, in image recognition, an image of an animal might be labeled as “dog,” so the goal is to train the algorithm so that it can eventually predict the right label for all the images containing a dog. In this case, the algorithm learns from the training dataset to generate accurate predictions iteratively. Yet, even though supervised models are considered more accurate than unsupervised ones, they still require human involvement to annotate the data for the model training.
When comparing unsupervised vs supervised learning, this method stands out for its accuracy—but also for its reliance on high-quality labeled data and human input.
You can always send your data to our team of annotation pros to make it easier to cope with supervised learning. Contact our data annotation company to ensure your ML model is fed with secure and accurately labeled data! If you’re unsure where to start, check our data annotation pricing to estimate your project budget.
Examples of Supervised ML
Some of the most common applications of supervised learning include sentiment analysis, text categorization, weather forecasting, price prediction, and spam detection. Face recognition is one of the many supervised learning use cases that benefit from video annotation services, especially in security and behavior analysis.
It’s quite a simple method in machine learning, which is often computed using languages like R or Python. However, the process of training such models may be time-consuming, and it requires robust data annotation expertise to provide the right labels for input and output variables.
Supervised learning is a much more common and more accurate ML method that can tackle complex and tedious tasks. It’s an ideal approach for:
- Binary classification: Trains a model using only two class labels to predict a discrete or categorical target variable.
- Multi-class classification: Applies a large number of different class labels to the object or the data.
- Regression modeling: Tackles the issue of predicting a continuous response variable.
- Ensembling: Uses a variety of models to predict an outcome, including different algorithms or training datasets.
What Is Unsupervised Learning & Where to Apply Unlabeled Data
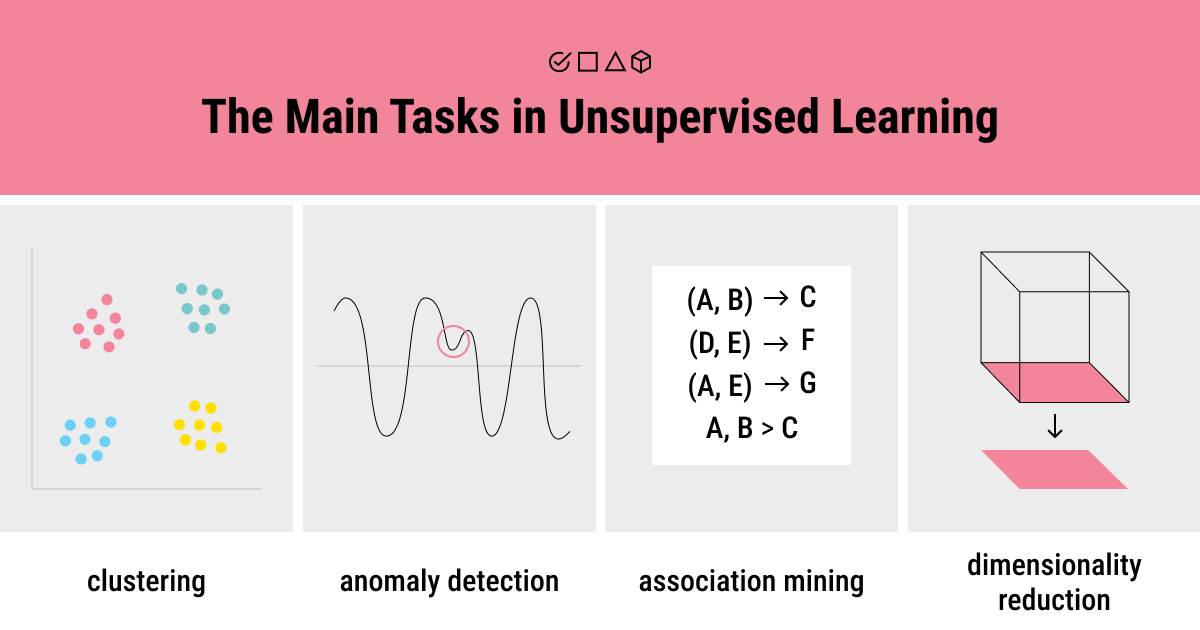
Unsupervised learning, on the other hand, doesn’t require a data scientist to be involved in the process. No labels or corresponding outputs are needed. Instead, unsupervised ML implies that the algorithm is fed with unlabeled data to detect patterns that form the groups of data. The algorithm itself analyzes the underlying structure of the data.
In the context of supervised learning vs unsupervised, this approach trades accuracy for flexibility — letting the model explore patterns on its own without predefined labels.
Thus, unsupervised models function independently, and they can find the inherent structure of unlabeled data on their own. Of course, they still require humans in the loop (HITL) to validate output variables and ensure that the results are satisfactory.
Examples of Unsupervised ML
Unsupervised models also have a broad spectrum of applications in machine learning, including recommendation engines, anomaly detection machine learning, customer segmentation, and medical imaging, to name a few. However, since you have a lot of unclassified data to work with, you need sophisticated tools to handle computationally difficult unsupervised models. Besides, unless human intervention is applied to evaluate the output variables, an unsupervised method might produce radically inaccurate results.
Unsupervised ML is an ideal approach for:
- Clustering: Organizes data into segments (groups) and reveals similar patterns in the dataset.
- Segmentation: Seeks to find and locate semantically relevant categories with no need for labeled data.
- Anomaly detection: Detects data points that deviate from the normal behavior.
- Association mining: Employs a variety of rules to uncover correlations between variables in a dataset.
- Dimensionality reduction: Identifies the characteristics of data values that produce the largest variation between data points.
Unsupervised Data Mining
The basic concept of machine learning solutions is to analyze hidden patterns in data, which is the process called data mining. Before mining patterns, some teams also rely on data collection services to gather the raw datasets. A model then uses these patterns to predict outcomes or classify a given set of data, given the problem posed to the model. In unsupervised data mining, the algorithms have a tendency to discover rules that accurately describe connections between the attributes. This is why unsupervised models are sometimes called descriptive models because they look for unknown patterns in a dataset (unlabeled) with no or minimum human supervision.
In discussions of unsupervised learning vs supervised learning, this pattern-finding approach stands apart by not aiming to predict a known output.
These models focus on the data’s fundamental structure, relations, and interconnections rather than predicting a target value. Unsupervised data mining refers to the method of using ML algorithms where there’s no outcome variable that is predicted or classified, like in supervised data mining techniques. The goal of this type of data mining is to explore and analyze patterns in the given machine learning dataset based only on the relationships between data points. Therefore, unsupervised learning helps identify unknown (hidden) patterns in data using clustering, association, and extraction. However, unsupervised methods are notoriously slow, and they present a number of scalability concerns.
An unsupervised method of data mining is applied when there’s no specific goal of an ML project or when one aims to discover hidden patterns and relationships within the dataset. While unsupervised methods can do without labeled data, data annotation projects remain an essential element in supervised learning.
Semi-Supervised Learning
Semi-supervised learning combines a small amount of labeled data with a large amount of unlabeled data during training. This approach is particularly useful when labeling data is expensive or time-consuming. It leverages the strengths of both supervised and unsupervised learning to improve model accuracy without the full cost of data annotation.
Self-Supervised Learning:
Self-supervised learning involves training models to predict part of the input from other parts, effectively generating its own labels. This method has gained prominence in training large language models (LLMs) and in computer vision tasks, where labeled data is scarce. By utilizing the inherent structure in data, self-supervised learning enables models to learn useful representations without manual labeling.
How to Choose Between Supervised vs. Unsupervised Learning

Machine learning is a viable strategy that makes it easier to navigate and eventually succeed in the modern business environment. The only problem is to evaluate your project’s needs and choose the right approach to machine learning, supervised vs unsupervised learning.
If you’re working on an ML project, you need to know these basics we’ve discussed in order to understand what solution is the best for you. The success of your ML project lies in your ability to evaluate the structure and volume of your input data, set the right goals for the project, and examine your algorithms’ alternatives. If it so happens that supervised learning is your match, you will need expert support from data annotation services.
In supervised learning, classifying large volumes of data might be challenging, but highly accurate and reliable results are well worth the effort. Unsupervised learning, on the other hand, can deal with massive amounts of unlabeled data in real-time. However, if you’ve faced the transparency issue of data clustering or a higher risk of inaccurate output, semi-supervised learning kicks in. But we’ll save this topic for future discussion, so stay tuned!
When training large language models with limited labeled data, LLM data labeling becomes essential for accuracy and task-specific performance. Combining this with LLM fine tuning allows teams to tailor models to domain-specific tasks. Many teams rely on expert LLM fine-tuning services when internal capabilities are limited.
Pros and Cons of Supervised vs Unsupervised Learning
| Supervised Learning | Unsupervised Learning | |
| Pros | - High accuracy for prediction tasks - Clear evaluation metrics (e.g. accuracy) - Easier to troubleshoot and interpret | - Reveals hidden patterns in unlabeled data - No need for labeled datasets - Scales well with large, unstructured data |
| Cons | - Requires large volumes of labeled data - Expensive and time-consuming annotation - Doesn’t generalize well to unknown patterns | - Harder to evaluate model performance - Results may be less interpretable - Can cluster data in meaningless ways |
Your final choice in machine learning supervised vs unsupervised methods depends on how much labeled data you have, what kind of results you need, and how flexible your model should be.
About Label Your Data
If you choose to delegate LLM fine-tuning, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is the main difference between supervised and unsupervised learning?
Supervised learning uses labeled data to train a model. The algorithm learns from examples where the correct answer is already known. Unsupervised learning works with unlabeled data. It finds patterns or groupings without being told what to look for.
Is ChatGPT supervised or unsupervised learning?
ChatGPT was trained using a mix of both methods, which is common across many types of LLMs today. First, it went through unsupervised pretraining on large volumes of text (no labels, just prediction of the next word). Then it was fine-tuned using supervised learning and reinforcement learning with human feedback (RLHF) to follow instructions better.
What is an example of unsupervised learning?
Clustering customer behavior in e-commerce is a classic use case. The algorithm groups users based on what they click, buy, or ignore — without needing labels like “high spender” or “bargain hunter.”
Is a neural network supervised or unsupervised?
A neural network is just the architecture; it can be used for either. If you train it with labeled data, it’s supervised. If it learns from patterns in unlabeled data, it’s unsupervised. It depends on how you use it.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.