Machine Learning Datasets: Types, Sources, and Key Features

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- What Is a Dataset in Machine Learning?
- Types of Machine Learning Datasets
- Top Sources to Find Machine Learning Datasets
- Key Features of High-Quality Machine Learning Datasets
- How to Build Machine Learning Datasets
- Top Use Cases for Machine Learning Datasets
- Common Challenges of Information Sets Used in Machine Learning
- About Label Your Data
- FAQ

TL;DR
- Machine learning datasets are the foundation for training, validating, and testing AI models.
- High-quality datasets must be relevant, balanced, diverse, and well-annotated.
- Building datasets involves data collection, preprocessing, annotation, and splitting into training, validation, and testing subsets.
- Data sources range from open-source repositories like Kaggle and UCI to synthetic data tools and paid services.
- Emerging trends like synthetic data generation, federated learning, and multimodal datasets are shaping the future of dataset development.
What Is a Dataset in Machine Learning?
A machine learning dataset is, quite simply, a collection of data pieces that can be treated by a computer as a single unit for analytic and prediction purposes. This means that the data collected should be made uniform and understandable for a machine that doesn’t see data the same way as humans do.
ML models depend on machine learning datasets to learn and improve. These datasets act as collections of data used to train, test, and validate a machine learning algorithm. Without the right dataset, your model won’t perform well or provide accurate results.
Why Are Datasets Important?
The success of any machine learning model depends on the quality and relevance of the data it learns from. Here's why:
- Training: AI training datasets provide examples that models use to identify patterns.
- Validation: Separate datasets help tune the model's performance.
- Testing: Unseen data evaluates the model's ability to generalize.
Without the right data, even the best-designed algorithm won’t work effectively.
Data Types in Machine Learning
There are two main categories:
| Structured Data | Unstructured Data |
| Organized into tables or rows, such as numerical values or categories. Example: sales data. | Includes text, images, video, or audio. Example: social media posts or medical datasets for machine learning containing X-ray images. |
Choosing the right type depends on your project’s goals. For instance, image recognition models require unstructured data, while forecasting tasks often rely on structured datasets.
Types of Machine Learning Datasets
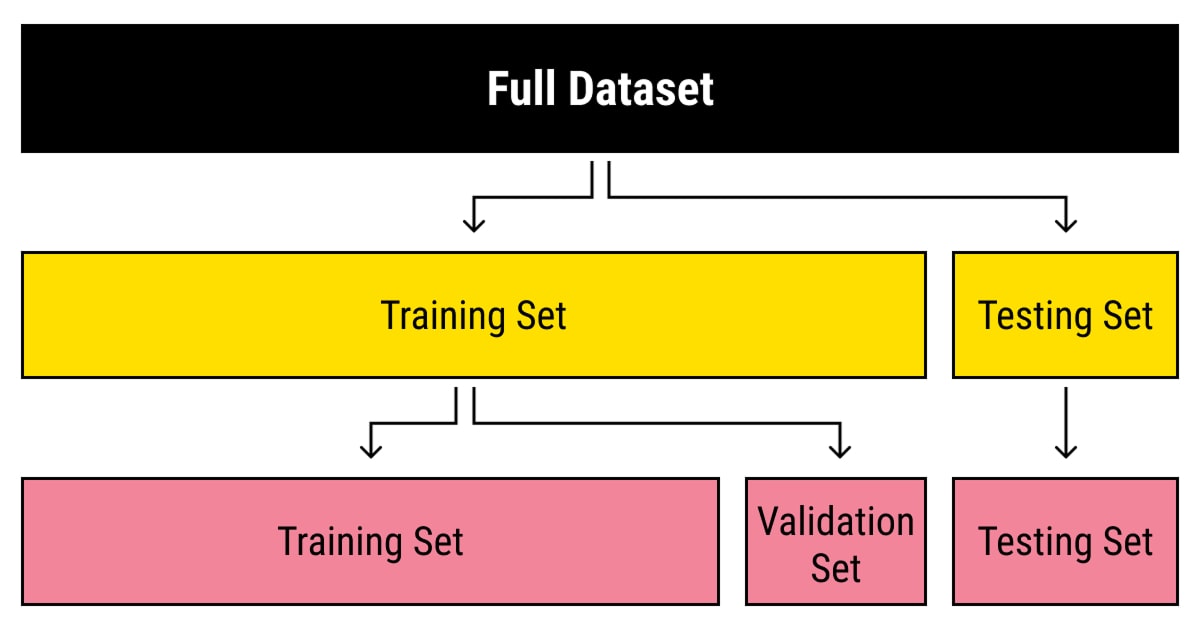
Machine learning models rely on three main types of datasets during development. Each serves a distinct purpose, contributing to a model’s accuracy and reliability.
Training Datasets
Purpose: To teach the model.
The AI training dataset is the largest subset and forms the foundation of model development. The model uses this data to identify patterns, relationships, and trends.
Key Characteristics:
- Large size for better learning opportunities
- Diversity to avoid bias and improve generalization
- Well-labeled for supervised learning tasks
Example: AI training datasets with annotated images train models to recognize objects like cars and animals.
Validation Datasets
Purpose: To fine-tune the model.
Validation datasets evaluate the model during training, helping you adjust parameters like learning rates or weights to prevent overfitting.
Key Characteristics:
- Separate from the training data
- Small but representative of the problem space
- Used iteratively to improve performance
Tip: Validation data ensures your model isn’t simply memorizing the training data but can generalize well.
Testing Datasets
Purpose: To evaluate the model.
The testing dataset provides an unbiased assessment of the model’s performance on unseen data.
Key Characteristics:
- Exclusively used after training and validation
- Mimics real-world scenarios for robust evaluation
- Should remain untouched during the training process
Example: Testing a sentiment analysis model with user reviews it hasn’t seen before.
How to Split Datasets Effectively
Splitting your machine learning datasets into these three subsets is crucial for accurate model evaluation:
- 70% Training
- 15% Validation
- 15% Testing
Keep these subsets diverse and balanced to ensure your model learns and performs well across different scenarios.
Top Sources to Find Machine Learning Datasets

Finding the best datasets for machine learning can be challenging, but knowing where to look makes it easier. Below is a curated list of dataset sources, categorized by type and paired with practical use cases.
When sourcing datasets for machine learning, it’s essential to consider both free (open-source) and paid (proprietary) options. Each category has its advantages depending on your project’s goals, budget, and resource requirements.
Open-Source Machine Learning Datasets
Public datasets for machine learning are freely available and often used for educational or research purposes. They typically require preprocessing and annotation to align with project goals.
Kaggle Datasets
A go-to platform for datasets across diverse fields. Kaggle also offers tools for collaboration and analysis through its cloud-based notebooks. You can search by tags like "finance" or "healthcare" to filter relevant datasets.
When to use: Kaggle datasets are best for exploratory analysis, prototyping, or practicing with clean, ready-to-use data. Suitable for competition-driven or academic projects.
UCI Machine Learning Repository
UC Irvine Machine Learning Repository is a long-standing academic resource offering datasets categorized by machine learning tasks like regression or classification. UCI machine learning datasets are ideal for benchmarking or learning specific algorithms.
When to use: Ideal for academic research, algorithm benchmarking, or learning foundational machine learning techniques.
Google Dataset Search
A search engine for machine learning open datasets, indexing thousands of public repositories. Google Dataset Search unifies diverse dataset sources, from niche research topics to general-purpose collections.
When to use: Datasets for machine learning projects or niche research topics requiring highly specific data that may not be available on standard platforms.
EU Open Data Portal and Data.gov
Government-hosted repositories, like EU open data portal and Data.gov, provide datasets in areas like public policy, climate, and transportation. They are well-documented but limited to specific domains.
When to use: Perfect for policy analysis, environmental modeling, or urban planning projects.
Paid and Proprietary Machine Learning Datasets
Compared to machine learning open datasets, paid datasets are often curated for specific industries, offering higher quality and domain relevance. These are suitable for large-scale or niche applications where free datasets may fall short.
Label Your Data
We offer domain-specific datasets and annotation services for custom machine learning tasks.
When to use: Datasets for machine learning projects requiring high-quality annotations or domain expertise, such as object detection or sentiment analysis in enterprise settings.
Synthetic Data Vault (SDV)
SDV is a tool to create synthetic datasets for controlled experiments when real-world data is unavailable or sensitive.
When to use: Use in projects involving privacy concerns or in scenarios where replicating real-world conditions is crucial.
Unity Perception
Unity is focused on computer vision tasks, it generates synthetic datasets through 3D simulations.
When to use: Ideal for training models in robotics, self-driving cars, or any task needing edge-case scenarios.
Lionbridge AI Datasets
Lionbridge provides industry-specific datasets, often paired with data annotation services for large-scale projects.
When to use: Suitable for enterprise-level applications where curated, domain-specific data is necessary.
Comparing Free and Paid Information Sets Used in Machine Learning
| Dataset Source | Pros | Cons | Example Repositories |
| Public Datasets | - Free to access - Large variety of datasets - Easily available for ML online | - May not align with specific project needs - Often require cleaning and preprocessing | - Kaggle Datasets - UCI Machine Learning Repository - Google Dataset Search |
| Generated Data | - Fully customizable - Ideal for specific and controlled scenarios | - Requires significant computational resources - May lack real-world diversity | - Synthetic Data Vault (SDV) - Unity Perception |
| Paid Data Services | - High-quality, domain-specific datasets - Can include data annotation and cleaning services | - High cost- May require additional customization | - Label Your Data - Appen |
| Government and Open Data | - Reliable and authoritative - Often well-documented | - Limited to specific domains (e.g., census, healthcare) - May lack up-to-date information | - Data.gov - European Data Portal |
| Corporate or Domain-Specific | - Tailored to niche industries- High relevance to specialized ML tasks | - Access restrictions - Licensing can be expensive | - Microsoft Research Open Data - Lionbridge AI |
Key insights:
- Public datasets for machine learning are great for beginners and small projects but often need significant preprocessing.
- Generated data provides full control but requires expertise and resources.
- Paid services ensure quality and relevance but come at a higher cost.
- Government and open data are reliable for specific domains, but may not be comprehensive for advanced tasks.
- Corporate/domain-specific datasets are perfect for niche applications but can be expensive and restricted.
How to Choose the Right Dataset Source
Define Your Requirements
Identify the type of data and the level of annotation required for your model.
Match the Source to Your Needs
For smaller projects, start with open-source repositories. For specialized tasks, consider paid or synthetic data.
Budget Considerations
Free datasets are cost-effective but may require significant cleaning and preprocessing, while paid sources offer higher quality but come at a price.
Key Features of High-Quality Machine Learning Datasets

The quality of your machine learning dataset directly impacts the performance of your model. A poorly constructed dataset can lead to bias in machine learning, as well as inaccurate or unreliable predictions, no matter how advanced your algorithm is.
Here are the essential features to look for when building or selecting machine learning datasets:
Relevance to the Task
Your dataset must align with the problem your model is designed to solve.
- Why it matters: Irrelevant data leads to noisy models and poor performance.
- Example: For autonomous vehicles, datasets with street, vehicle, and pedestrian images are essential; wildlife photos are irrelevant.
Balanced Data Distribution
A balanced dataset ensures all target classes or features are well-represented.
- Why it matters: Imbalanced data can bias the model toward the dominant class, reducing its ability to generalize.
- Example: A sentiment analysis model trained only on positive reviews will struggle to classify negative sentiments accurately.
How to address imbalance:
- Oversample underrepresented classes
- Use techniques like SMOTE (Synthetic Minority Oversampling Technique)
Data Diversity
Diverse machine learning datasets improve a model's ability to generalize across real-world scenarios.
- Why it matters: Limited diversity can lead to overfitting, where the model performs well on AI training datasets but poorly on unseen data.
- Example: A facial recognition model trained only on specific demographics will likely fail on broader populations.
Tips for ensuring diversity:
- Source data from multiple locations or demographics
- Avoid over-representing any single feature
Clean and Accurate Data
Errors in your dataset can introduce noise, misleading the model.
- Why it matters: Duplicates, missing values, and incorrect labels affect the reliability of your model.
- Example: A mislabeled image in a dataset can teach the model to associate the wrong label with similar images.
Steps to clean data:
- Remove duplicates
- Impute or drop missing values
- Validate annotations for accuracy
Sufficient Quantity
Large datasets for machine learning are typically better for training robust models, especially for complex tasks.
- Why it matters: Insufficient data can prevent the model from learning effectively, while larger datasets improve performance and generalization.
- Example: Training deep learning models like GPT-4 requires vast datasets spanning billions of data points.
Proper Annotation
Expert data annotation guides the model’s learning process.
- Why it matters: Inaccurate or incomplete annotations lead to misaligned predictions.
- Example: For object detection tasks, bounding boxes around objects must be precise to help the model identify features accurately.
Annotation options:
- Outsource the task to a data annotation company
- Use automated data annotation for faster labeling
Checklist for Dataset Quality
Before using a dataset, evaluate it with the following:
- Relevance: Does the data align with your model’s goals?
- Completeness: Are all necessary data points present?
- Consistency: Are labels applied uniformly across the dataset?
- Bias: Is there representation for all important features or classes?
- Size: Is the dataset large enough for the complexity of your task?
Quality machine learning datasets, particularly those used in applications like LLM fine-tuning, must be relevant, well-balanced, and annotated to meet the needs of specific ML tasks.
How to Build Machine Learning Datasets
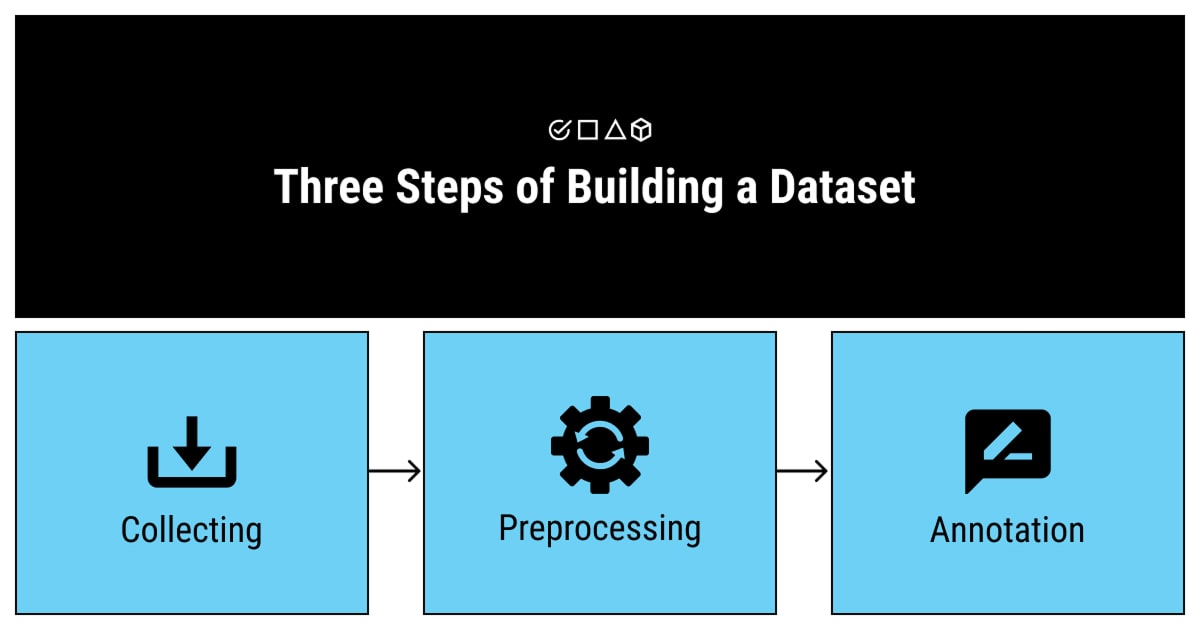
Creating a high-quality dataset is a critical process that involves multiple stages. Each step contributes to ensuring your machine learning model learns effectively and delivers accurate predictions.
Step 1: Define Your Objective
Before collecting any data, identify the specific problem your model is solving. This determines the type, format, and features of your dataset.
Key Questions:
- What is the model’s goal? (e.g., image classification, sentiment analysis)
- What type of data is required? (structured, unstructured, numerical, text, images, etc.)
- Are there specific target outputs (labels) needed?
Step 2: Collect Relevant Data
Choose the most suitable sources for data collection based on your project’s requirements.
Key Questions:
- Open-source datasets: Great for experimentation and academic projects.
- Proprietary data: Ideal for niche applications requiring specific data.
- Synthetic data: Useful for replicating controlled scenarios or addressing privacy concerns.
Tips:
- Use tools like web scrapers or APIs to gather raw data.
- Diversify data sources to improve model generalization.
Step 3: Preprocess and Clean the Data
Raw data is often messy and unsuitable for direct use in machine learning. Preprocessing ensures the dataset is consistent and usable.
Common Steps:
- Remove duplicates and outliers
- Handle missing values by imputing or discarding them
- Normalize or standardize numerical data
- Tokenize and clean text data for NLP tasks
Why it matters: Clean data improves learning efficiency and reduces noise in predictions.
Step 4: Annotate Data
Annotations provide the labels your model learns from. This step is crucial for supervised learning tasks.
Methods:
- Manual Annotation: Involves domain experts or outsourced teams for precise data annotation services.
- Automated Annotation: Use AI-powered tools for large-scale projects.
Examples:
- Bounding boxes for object detection in images
- Sentiment tags for text reviews
- Transcriptions for audio data
Step 5: Split the Dataset
Dividing your dataset into subsets ensures the model is trained and evaluated properly.
Standard Splits:
- Training Set (70-80%): Used to teach the model
- Validation Set (10-15%): Fine-tunes hyperparameters and prevents overfitting
- Testing Set (10-15%): Evaluates performance on unseen data
Step 6: Analyze the Dataset
Before feeding the data into your model, analyze it to uncover potential biases or inconsistencies.
Techniques:
- Use histograms, scatter plots, or box plots to visualize data distribution
- Check for imbalances in class labels or missing features
Step 7: Document the Dataset
Comprehensive documentation ensures transparency and reproducibility.
What to include:
- Data sources and collection methods
- Preprocessing and annotation steps
- Descriptions of features and labels
Step 8: Store and Manage Data
Secure and organized storage ensures scalability and ease of access.
Best Practices:
- Use cloud storage solutions like AWS S3 or Google Cloud Storage
- Implement version control to track dataset changes over time
This step-by-step guide should streamline your dataset creation process, whether you’re working on a small project or building datasets for large-scale AI applications.
Top Use Cases for Machine Learning Datasets
Machine learning datasets serve as the foundation for various applications across industries. The type of dataset often dictates its use case, ranging from enhancing user experiences to solving complex scientific challenges.
Here are some of the most impactful use cases:
Computer Vision
Computer vision tasks rely heavily on labeled video and image datasets for machine learning for accurate predictions.
Applications:
- Object detection and recognition (e.g., autonomous vehicles, security systems)
- Image segmentation for medical diagnostics (e.g., tumor detection in X-rays)
- Scene understanding in robotics and virtual reality, and geospatial annotation
Dataset Examples: COCO, ImageNet, VisualData.
Natural Language Processing (NLP)
NLP tasks require diverse and well-annotated text datasets to train models that understand and generate human language.
Applications:
- Sentiment analysis for customer feedback
- Machine translation for multilingual content
- Chatbots and conversational AI systems
Dataset Examples: IMDb Reviews, SQuAD, Common Crawl.
Time Series Analysis
Time-series datasets are crucial for forecasting and trend analysis.
Applications:
- Predicting stock prices or market trends in finance
- Monitoring sensor data in IoT devices
- Analyzing patient health data for predictive healthcare
Dataset Examples: UCI Gas Sensor, Yahoo Finance Datasets.
Speech and Audio Recognition
Datasets containing speech and audio signals power models for recognizing and processing sound in automatic speech recognition.
Applications:
- Voice assistants like Alexa and Siri
- Speaker diarization in meeting transcription tools
- Acoustic scene analysis for smart environments
Dataset Examples: LibriSpeech, VoxCeleb.
Recommendation Systems
Recommendation systems rely on user behavior data to personalize suggestions.
Applications:
- E-commerce platforms suggesting products.
- Streaming services recommending content (e.g., Netflix, Spotify).
- Personalized learning systems in education.
Dataset Examples: MovieLens, Amazon Product Data.
Common Challenges of Information Sets Used in Machine Learning

Building reliable datasets for machine learning is not without its hurdles. Challenges can range from finding relevant data to ensuring quality and managing costs.
Finding Relevant and Diverse Data
Sourcing data that aligns with your project’s goals and covers all necessary scenarios can be difficult.
Challenge: Limited availability of data in niche domains or specific demographics.
Solution:
- Use open-source platforms like Kaggle or Google Dataset Search for general data
- Leverage domain-specific repositories or APIs for niche projects
- Generate synthetic data to simulate rare or hard-to-obtain scenarios
Data Imbalance
Imbalanced datasets, where one class is overrepresented, can skew model predictions.
Challenge: Poor performance on minority classes, leading to biased outcomes.
Solution:
- Apply resampling techniques like oversampling the minority class or undersampling the majority class
- Use augmentation methods to create additional examples of underrepresented classes
- Incorporate techniques like SMOTE (Synthetic Minority Oversampling Technique)
Data Quality Issues
Raw data often contains errors, inconsistencies, or missing values.
Challenge: Noisy or incomplete data leads to unreliable models.
Solution:
- Conduct rigorous data cleaning to remove duplicates and outliers
- Impute missing values using statistical methods or domain knowledge
- Validate annotations regularly to ensure consistency and accuracy
High Costs of Annotation
Manually labeling large datasets for machine learning can be time-consuming and expensive, especially for complex tasks.
Challenge: Limited resources to label data for tasks like image segmentation or NLP.
Solution:
- Use automated tools or pre-trained models for initial annotation
- Outsource to trusted data annotation companies for large-scale tasks
- Combine manual and machine-assisted labeling through active learning pipelines
Ethical and Privacy Concerns
Handling sensitive data raises questions about privacy and compliance.
Challenge: Accessing and using personal or proprietary data without violating regulations.
Solution:
- Use anonymization techniques to strip personally identifiable information
- Ensure compliance with data protection laws like GDPR or CCPA
- Opt for synthetic data when real-world data usage poses legal risks
Storage and Scalability
Managing and updating large datasets for machine learning can overwhelm infrastructure.
Challenge: Storing massive volumes of data securely while maintaining easy access.
Solution:
- Use cloud storage solutions like AWS S3 or Google Cloud Storage for scalability
- Implement version control to track dataset changes and updates
- Regularly archive outdated or irrelevant data to reduce storage costs
Checklist to Overcome Challenges
- Define clear data requirements before starting your project
- Invest in preprocessing and cleaning steps to ensure data quality
- Balance your dataset to avoid bias and overfitting
- Use efficient annotation methods to save time and costs
- Prioritize ethical and legal compliance when handling sensitive data
If you’re looking for a trusted partner, we’ll gladly help you with dataset collection and annotation for machine learning!
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What are datasets for machine learning?
In machine learning, a dataset is a structured collection of data points that an algorithm can analyze. Each dataset is designed to provide the model with examples it can learn from, typically including features (input variables) and, in some cases, labels (output variables) that guide supervised learning tasks.
Which database is best for ML?
The best database for machine learning depends on your project's needs. For general use, Kaggle and the UCI Machine Learning Repository are popular choices. For domain-specific tasks, consider repositories like Google Dataset Search or proprietary databases from services like Label Your Data for customized, high-quality datasets.
Where can I get free datasets?
You can find machine learning datasets on public repositories like Kaggle datasets, UCI Machine Learning Repository, and Google Dataset Search. Many organizations also provide domain-specific datasets, and some data can be generated synthetically or collected directly based on project needs.
How to create a dataset in ML?
- Decide what the dataset will be used for.
- Gather data from APIs, web scraping, sensors, or existing sources.
- Remove duplicates, handle missing values, and standardize formats.
- Assign categories, annotations, or tags for supervised learning.
- Store it in CSV, JSON, or a database for easy access.
- Divide into training, validation, and test sets.
- Check for errors and balance class distribution if needed.
- Save the dataset securely and document key details.
What are UCI datasets?
UCI datasets come from the UCI Machine Learning Repository, a trusted collection of datasets tailored for machine learning tasks like classification, regression, and clustering. Researchers and students often use these datasets for benchmarking and academic projects due to their accessibility and variety.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.