LLM Fine-Tuning Methods: Standard & Advanced

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

TL;DR
- Fine-tuning customizes LLMs using domain-specific data to improve task performance.
- Feature-based and parameter-based methods vary in complexity and resource needs.
- Effective fine-tuning relies on curated data and techniques to avoid overfitting.
- Applications include healthcare diagnostics, financial analysis, and personalized education.
Fine-Tuning LLM Models: What Is It For?
In most simple cases, you can use a basic large language model. However, if you want your LLM to perform a specific task in a specific domain, you need to fine-tune it.
To give you a better idea of what is LLM fine-tuning, think of it this way. Imagine you’re a talented novelist who writes in English. Now, you’ve been asked to write a technical manual for new software. Although your writing skills are excellent, you need specialized knowledge of the software and industry-specific terminology to complete the task. This specialized training, or ‘fine-tuning,’ ensures your writing meets the specific needs of the technical manual, just as fine-tuning an LLM helps it excel in particular tasks or domains.
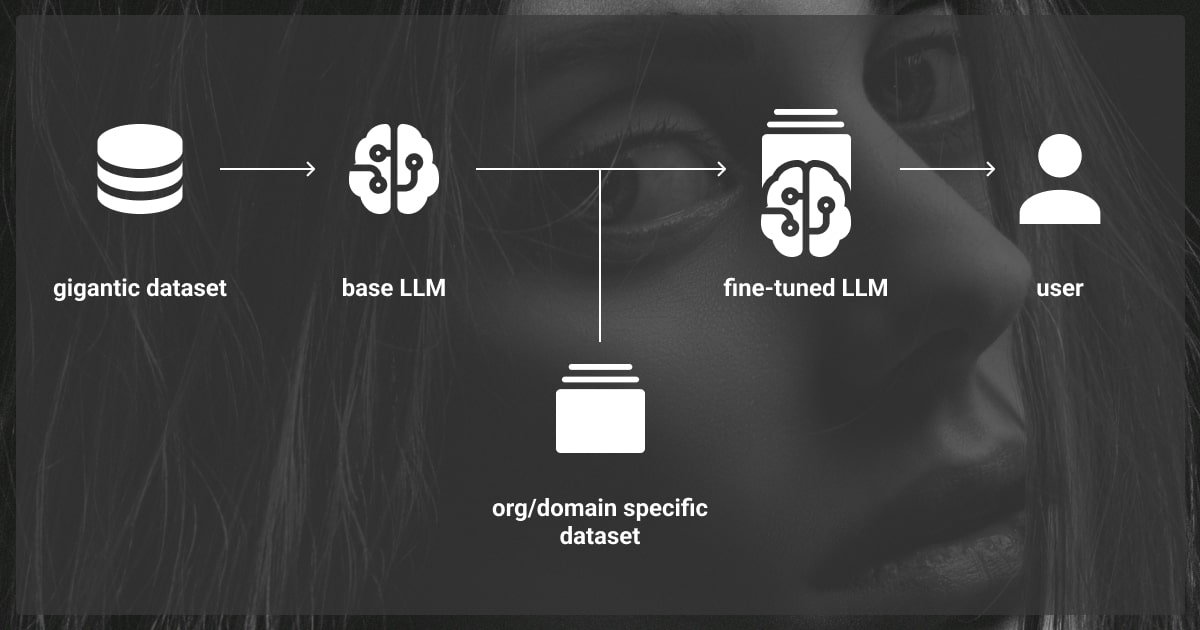
Drawing on our expertise in this field, we at Label Your Data explore the primary LLM fine-tuning methods to help you understand how does LLM fine-tuning work.
Difference Between LLM Pre-Training and LLM Fine-Tuning
Pre-Training
Pre-training involves training a language model on a large corpus of general text data to learn language patterns, grammar, and general knowledge. This process creates a broad, versatile model capable of understanding and generating human-like text.
Fine-Tuning
Fine-tuning LLM adjusts this pre-trained model using specific, domain-related data to improve performance on specialized tasks. This process tailors the model to understand and generate text specific to a particular field or application.
Discover the different families and types of LLMs and their unique capabilities in our recent article.
Standard LLM Fine-Tuning Methods
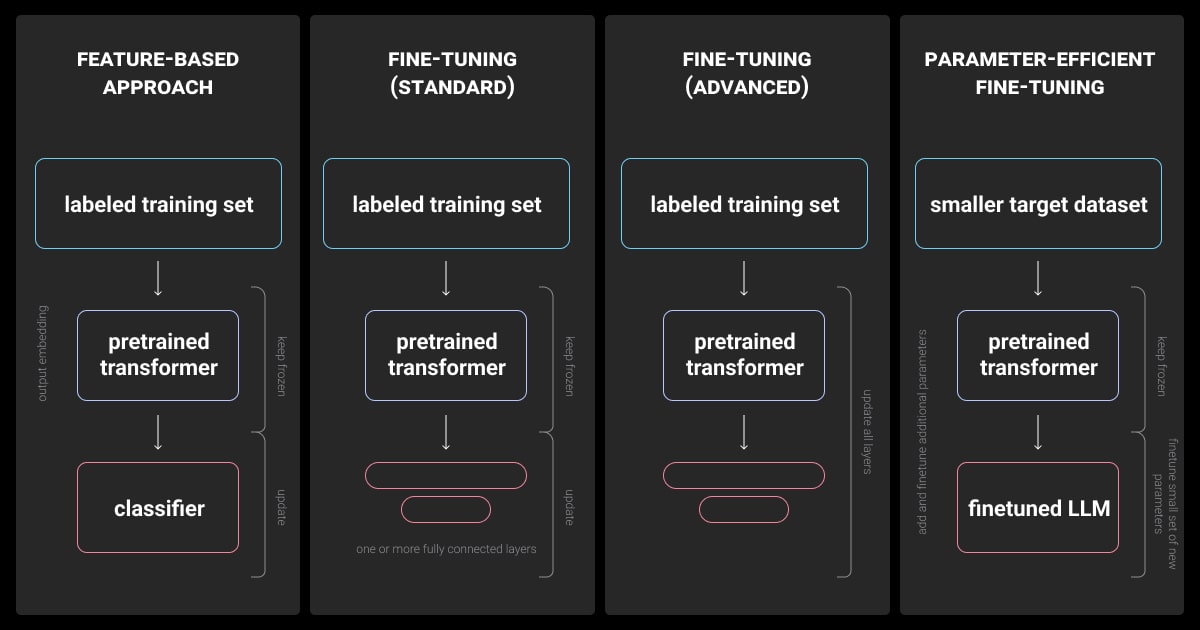
LLM fine-tuning is essential for tasks involving specialized fields, sensitive data, or unique information not covered by general training data. It enables the model to understand and generate text with the depth of knowledge specific to a field, greatly improving the quality of the results.
LLM fine-tuning methods can be broadly classified into two main categories:
Feature-Based LLM Fine-Tuning
Feature-based fine-tuning involves using the pre-trained model’s features as inputs to a new model. This method typically involves freezing the pre-trained layers and adding new layers that are specifically trained for the new task. By keeping the pre-trained layers unchanged, the model retains its learned representations from the vast amount of initial training data.
Pros and Cons:
One of the main advantages of this approach is resource efficiency. Since the pre-trained layers are not updated, the computational cost is lower compared to fully training a model from scratch. However, this method has limited adaptability because it relies heavily on the pre-trained features being relevant to the new task, which might not always be the case.
Use Cases:
Feature-based fine-tuning is commonly used in image classification, where pre-trained convolutional neural networks (CNNs) serve as feature extractors. In text classification, models like BERT or GPT, are used to generate embeddings, which are then fed into simpler models for the specific task.
Parameter-Based LLM Fine-Tuning
Parameter-based fine-tuning involves updating the pre-trained model’s weights to better suit the new task. This can be done either through end-to-end training, where all model parameters are updated, or selective layer training, where only specific layers are adjusted.
Pros and Cons:
This approach offers high adaptability, allowing the model to better fit the specific requirements of the new task. However, it is more resource-intensive, requiring substantial computational power and potentially large amounts of domain-specific data.
Use Cases:
Parameter-based fine-tuning is essential for complex natural language processing (NLP) tasks such as question answering and text generation. It is also used in computer vision tasks, where fine-tuning pre-trained CNNs can significantly improve performance on specialized datasets.
Interested in the next evolution of AI? Read about how Auto-GPT is changing the game with its autonomous capabilities.
Standard Parameter-Based Fine-Tuning
Standard fine-tuning involves several steps: preparing domain-specific data, initializing the pre-trained model, and training the model on the new data with appropriate hyperparameter settings. This process is commonly applied in typical scenarios where moderate customization is needed without extensive modifications.
Pros and Cons:
Standard fine-tuning can achieve high performance with relatively straightforward implementation. However, there is a risk of overfitting, especially if the domain-specific data is limited or not representative of the broader task.
Technical Considerations:
Data requirements for standard fine-tuning include having a sufficiently large and relevant dataset. Hyperparameter tuning, such as adjusting learning rates and batch sizes, is crucial to ensure effective model training.
Advanced Parameter-Based Fine-Tuning
Adapter-Based Fine-Tuning
Adapters are small modules inserted within the layers of the pre-trained model. They allow for efficient fine-tuning by only training a few additional parameters while keeping the rest of the model fixed. This approach is beneficial for scenarios where computational resources are limited.
Parameter-Efficient Fine-Tuning (PEFT)
PEFT focuses on optimizing the number of parameters updated during training. By selectively fine-tuning only a subset of parameters, this method reduces computational costs while maintaining high performance, making it suitable for resource-constrained environments.
Distillation
Model distillation involves training a smaller model to mimic the performance of a larger, pre-trained model. This process reduces the model size and improves efficiency while retaining much of the original model’s performance, which is advantageous for deploying models in production environments with limited resources.
Advanced LLM Fine-Tuning Methods
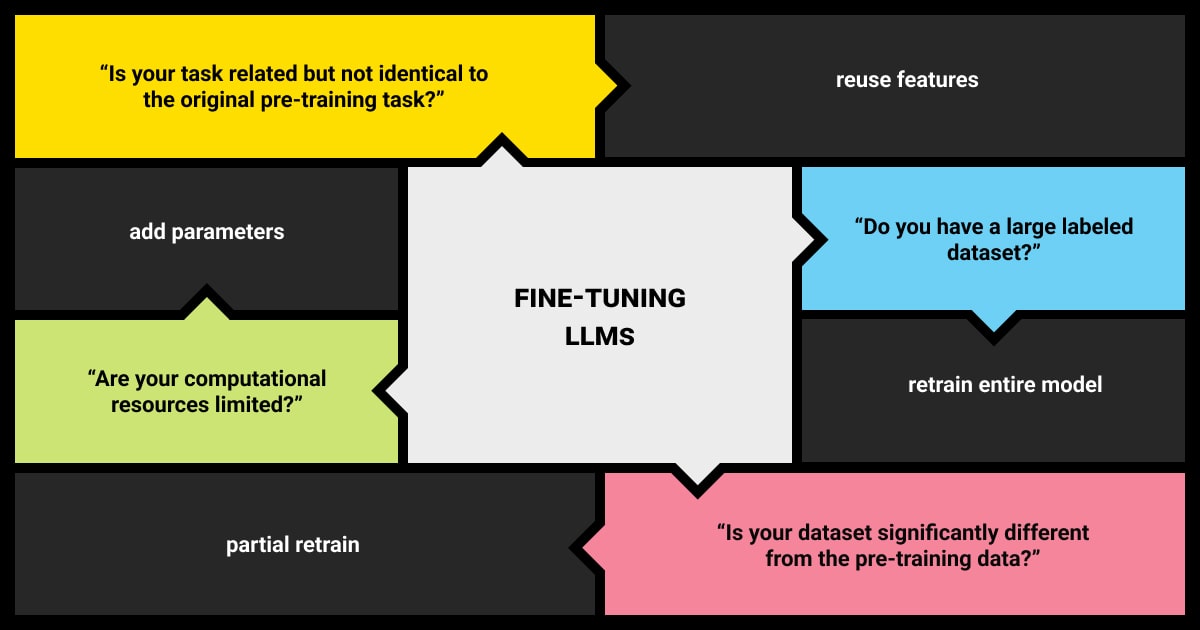
There are also advanced methods for fine-tuning LLM models because they push beyond the traditional requirements and limitations of large labeled datasets and extensive retraining. They optimize the use of pre-existing models and knowledge, making the training process more efficient, adaptable, and capable of handling a wider range of scenarios with limited data.
Transfer Learning
Transfer learning involves using a pre-trained model as a starting point and adapting it to a new but related task. This process leverages the knowledge gained from the initial training to improve performance on the new task, providing significant benefits in terms of training efficiency and model performance.
Few-Shot and Zero-Shot Fine-Tuning
Few-shot fine-tuning uses a small amount of task-specific data to adapt the model, while zero-shot fine-tuning involves no task-specific training data. These methods are beneficial for applications where labeled data is scarce, though they may come with challenges related to model accuracy and reliability.
Prompt-Based Fine-Tuning
This method uses carefully designed prompts to guide the model in generating desired outputs. It is particularly useful when there is limited training data available, as the model leverages its pre-trained knowledge to respond to the prompts effectively.
Cross-Lingual Fine-Tuning
Cross-lingual fine-tuning involves adapting a model trained in one language to perform tasks in another language. This approach faces challenges such as linguistic diversity and the need for multilingual training data, but offers significant potential in applications requiring multilingual support.
| Standard Fine-Tuning | Advanced Fine-Tuning |
| Involves adjusting the model parameters using a moderate amount of domain-specific data. | Involves more extensive parameter modifications, often with a larger dataset and more sophisticated techniques. |
| Suitable for tasks with some complexity where a certain level of customization is necessary. | Ideal for highly specialized tasks requiring a deep understanding of domain-specific nuances and high accuracy. |
| Generally involves fewer computational resources and less data. | Typically requires more computational power and a more significant amount of domain-specific data. |
Effective data annotation is crucial for training advanced models like ChatGPT. Learn how to properly label your data to improve LLM performance in our blog.
When to Apply LLM Fine-Tuning Methods
To help you decide when to fine-tune your LLM, we’ve prepared a short list of questions:
- To start, do you have a specific use case?
- No: Use pre-built models like ChatGPT API
- Yes: Proceed to the next question
- Does your task require domain-specific expertise?
- No: Use pre-built models with document chunking & database approach
- Yes: Proceed to the next question
- Do you have a significant amount of domain-specific data for training?
- No: Collect more data or use pre-built models with documentation
- Yes: Proceed to the next question
- Do you have the resources (time, money, computational power) to fine-tune or train from scratch?
- No: Optimize resources or use pre-built models with documentation
- Yes: Fine-tune your LLM
How to Fine-Tune LLM: A Technical Deep Dive
Fine-tuning LLMs can be complex, even with tools like PyTorch Lightning and HuggingFace. But how does LLM fine-tuning work?
The process involves loading pre-trained model layers into a training library like PyTorch and resuming training. It can either reuse the same language modeling objective with new data or add a new layer for specific tasks like classification or summarization, updating the model’s weights using optimization methods like gradient descent.
Data Preparation for LLM Fine-Tuning
Understanding how to prepare data for LLM fine-tuning is crucial. Proper data preparation ensures the model learns effectively from the new dataset, avoiding issues like overfitting or poor generalization. This involves cleaning and annotating the data, ensuring it is representative of the tasks the model will perform post-fine-tuning.
Advanced Techniques
- Differential Learning Rates: Applying different learning rates to model layers, accounting for gradient differences.
- Layer-Wise Learning Rate Decay: Gradually decreasing learning rates from the final layer to the first, focusing more on fine-tuning the final layers.
Key Tools for LLM Fine-Tuning
- PyTorch: Widely used for training and fine-tuning LLMs, offering robust support and a strong ecosystem.
- HuggingFace Transformers: Provides extensive tools and a large library of pre-trained models and datasets for easy fine-tuning.
Distributed Training
LLMs often exceed single GPU capacity, necessitating multiple GPUs. This can involve splitting datasets (data parallelism) or model weights (model parallelism) across GPUs, improving training efficiency. PyTorch’s DistributedDataParallel supports data parallelism, while HuggingFace Accelerate or Microsoft DeepSpeed handle more complex strategies.
API Services for LLM Fine-Tuning
Services like OpenAI and Databricks simplify fine-tuning proprietary models. The process typically involves uploading training data, the service fine-tunes the model, and then provides API access for evaluation and usage, with charges for subsequent use.
Future Predictions for LLM Fine-Tuning and Development
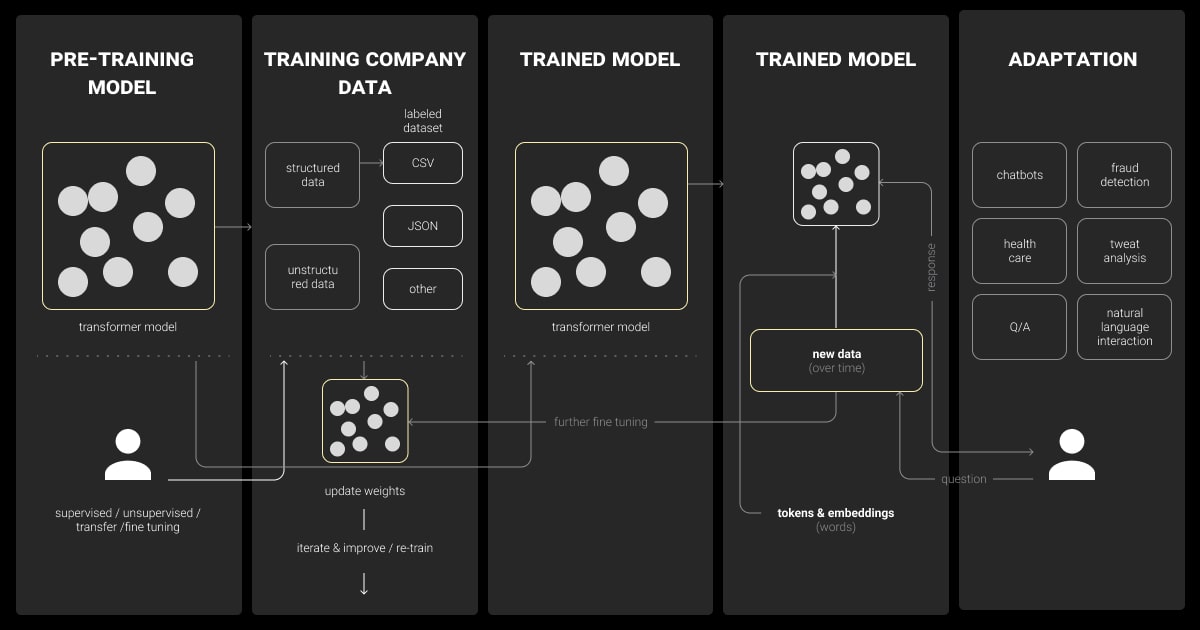
Recent advancements in LLM fine-tuning methods are pushing the boundaries of what these models can achieve. Researchers are exploring novel approaches such as meta-learning, which allows models to adapt quickly to new tasks with minimal data, and continual learning, where models learn continuously from a stream of data without forgetting previous knowledge.
Additionally, techniques like reinforcement learning fine-tuning are being integrated to optimize models based on feedback from specific tasks, enhancing their performance and adaptability. Besides, we can expect the development of more sophisticated adapter modules and parameter-efficient strategies that will further reduce computational costs and training times.
The integration of multi-modal fine-tuning, where models can handle text, image, and audio inputs simultaneously, is also on the horizon. These advancements will make LLMs more versatile and powerful, capable of handling a wider range of applications with greater precision.
Different sectors are already leveraging fine-tuned LLMs to enhance their operations. In healthcare, fine-tuned models assist in diagnosing diseases, personalizing patient care, and analyzing medical records. The finance industry uses these models for fraud detection, risk assessment, and automated customer support. In education, fine-tuned LLMs provide personalized learning experiences, automated grading, and real-time language translation.
How We Can Help with Your LLM Fine-Tuning
At Label Your Data, we offer expert fine-tuning services to optimize your large language models (LLMs) for enhanced performance and accuracy. Whether you need your models to follow specific instructions, adapt to domain-specific tasks, fix generated response errors, or transition to zero-shot learning, we have the expertise to meet your needs.
Our services are designed to reduce costs and improve the efficiency of your models. We use advanced techniques like Reinforcement Learning from Human Feedback (RLHF), instruction fine-tuning LLM, and instant feedback loops to ensure your model is precisely tuned to your requirements.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
Which are LLM fine-tuning methods?
LLM fine-tuning methods include full fine-tuning, where all model parameters are updated using domain-specific data, and parameter-efficient fine-tuning (PEFT), which adjusts only select parameters, such as in LoRA (Low-Rank Adaptation) or adapters. Prompt tuning focuses on optimizing prompts to guide the model’s outputs without modifying its core structure. Few-shot fine-tuning leverages a small number of labeled examples for quick adaptation, while instruction tuning trains the model on task-specific instructions to enhance its performance on similar tasks.
What are the best practices for maintaining the model’s accuracy over time after LLM fine-tuning?
Maintaining LLM model accuracy over time involves regular monitoring and evaluation of the model’s performance on new data. You can incorporate techniques such as incremental learning and periodic re-training with updated datasets.
Also, track the model drift and adapt the model to evolving data patterns. For ongoing support and expert guidance in fine-tuning large language models, consider partnering with Label Your Data.
How can I adapt a pre-trained LLM to a highly specialized domain?
- Collect and curate domain-specific datasets.
- Fine-tune the LLM using the curated dataset.
- Apply transfer learning techniques.
- Evaluate and refine the model on domain-specific tasks.
How do I handle limited labeled data for fine-tuning LLMs effectively?
- Use data augmentation to create synthetic data.
- Leverage transfer learning from related domains.
- Apply few-shot learning methods.
- Incorporate semi-supervised learning with unlabeled data.
- Use active learning to prioritize key samples for labeling.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.