Behind the Scenes of Conversational AI: How Does a Large Language Model Work?

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

It’s been a year since the introduction to ChatGPT has changed the modern digital landscape, showing the exciting possibilities of technologies we build today. After its release in November 2022, the tool became unstoppable, gaining popularity among its 100 millions active monthly users. While individuals continue using it in open access, businesses compete to create their own tools with the same algorithms.
But what is behind such an advanced conversational AI tech? Large Language Models, aka LLMs, are often overlooked, despite being the driving force behind more talked-about technologies such as ChatGPT, Bard, and many others. With sophisticated architecture that continues to evolve, LLMs have gone a long way to an exciting performance they show today.
The Key Architectures for Large Language Models
We are all familiar with ChatGPT that is on everyone’s lips. However, other chatbots and tools, such as Llama, PaLM, and Claude, used in Google Bard and Bing AI, stand the pace. They all use large language models, advanced models of artificial intelligence (AI). They belong to the natural language processing (NLP) field and are designed to analyze enormous amounts of data. Depending on the initial input, they process it, and then translate, or generate new content.
So, how does a large language model work to give such amazing results?
The application of large language models (LLMs) became possible thanks to advancement of conversational AI. To create the models, the great minds used the increased computational opportunities and huge amounts of text data we store today. As part of the generative AI landscape, LLMs are trained to create content based on millions of parameters, or prompts.
To process the request and produce the language, they follow a number of steps. They will differ depending on the architecture used for large scale language models processing. The most widespread is the transformer architecture. It is used in OpenAI’s GPT (Generative Pre-trained Transformer) series models, Google’s BERT (Bidirectional Encoder Representations from Transformers) and its variations, T5 (Text-to-Text Transfer Transformer), and Baidu’s ERNIE (Enhanced Representation through Knowledge Integration).
What about other architectures? Here are some, with their advantages and drawbacks:
- RNNs (recurrent neural networks). This architecture of a large language model is one of the foundational ones. However, it uses sequential processing, which slows down its training time and makes it difficult to process large datasets.
- LSTM (long short-term memory networks). They have better performance than RNNs, capturing longer sequences in the input. With the memory cell, they are effective in sequence modeling. LSTM is applicable in machine translation, speech recognition, text generation, and sentiment analysis.
- CNNs (convolutional neural networks). They are not only used in NLP applications, but also in computer vision, especially image recognition. Successful for hierarchical learning, they contribute to better understanding of the text. CNNs use embedding integration, which helps to understand connections between the words. In simple words, they understand the wider context in addition to the meaning of words.
You’ll choose the architecture based on your needs and the final results you want to get. However, recently, the Transformer architecture proved to be the most successful, and here is why.
Transformer Architecture: The Foundation of LLM (Large Language Model)
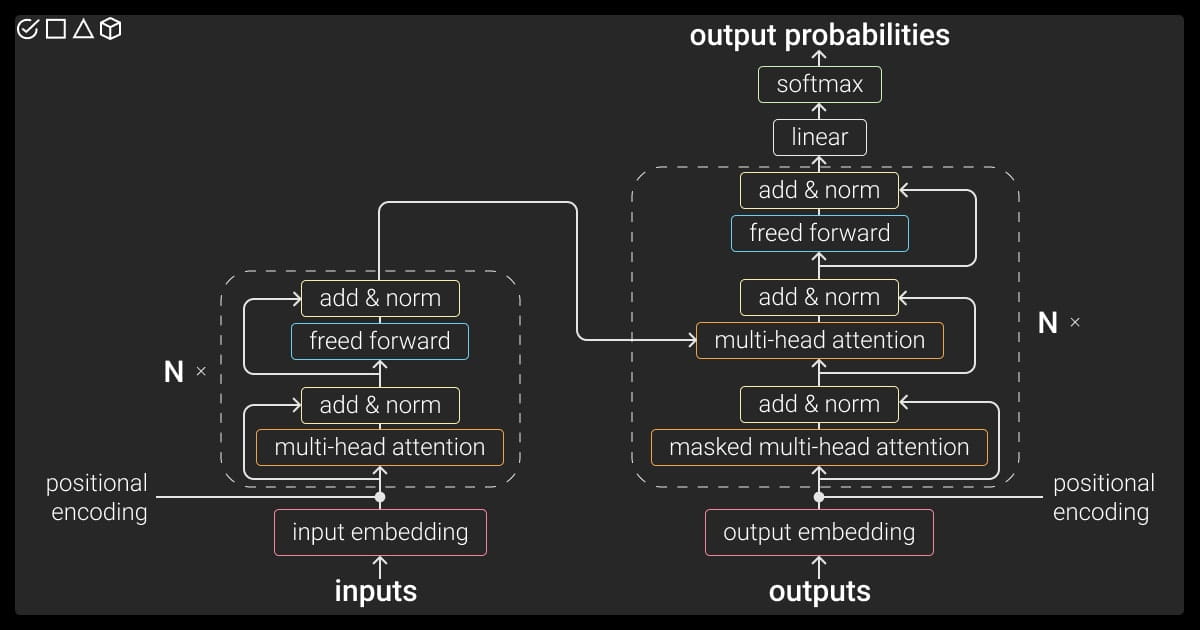
Transformer helps neural networks (NNs) to effectively manipulate the sequential data. It’s not surprising that this architecture is one step ahead. Its innovative self-attention mechanism allows LLMs to identify dependencies regardless of their position in the sequence. Besides, they process the prompts in parallel, which shortens the training time.
The following are the main components of the transformer architecture, which show how large language models work:
- Input. This stage consists of tokens, or prompts, entered by users for training purposes. Before the initial data is transformed into a numerical format, raw language models pass through classification and other NLP annotation services. These inputs assist the model to understand the meaning of words, arranging them in space into compatible phrases.
- Positional Encoding. Used to identify each word’s location, it allows a deep learning algorithm to catch the word order better, contributing to semantically and grammatically correct final outputs.
- Encoder Layers. The tokens of a large language model further pass through multiple encoder layers. They include the self-attention mechanisms and feedforward neural networks, which differentiate a transformer from other architectures. The first captures contextual information and dependencies, while the second processes and clarifies this data.
- Output. The output text is the combination of predicted probability of tokens with their matching vocabulary. The loss function at this stage is the goalkeeper, capturing the discrepancies between the target and the prediction. Thanks to this parameter, the LLM (large language model) has improved accuracy and overall performance.
- Decoder. It’s a very important parameter, creating the alchemy of large language models. It learns to foresee the next word from previous words and inputs during the training.
- Fine-Tuning. This step is optional, but is often used for concrete task training. It uses pre-trained models and adapts them to a specific domain.
Training and Adjustment: How Do Large Language Models Work?
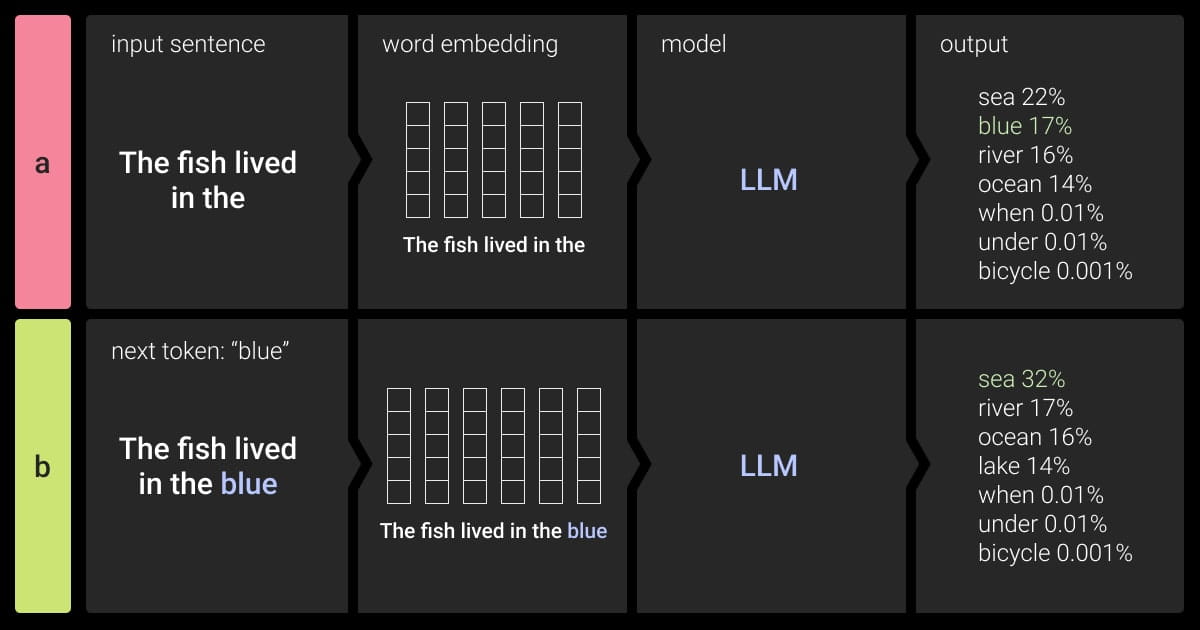
The success of large language models (LLMs), such as ChatGPT, or the enhanced version of ChatGPT called AutoGPT, lies in their training. With the self-attention mechanism, the models’ prediction capabilities moved to the next level. But, the training data is what became a real game changer. We are astonished at ChatGPT’s capability of answering our questions correctly and giving us smart advice. This has become possible thanks to billions of word combinations from books, vocabularies, and databases that have been annotated and used for LLM’s training.
Since we want large language models LLM to serve our different purposes, we choose different methods and mechanisms to train them.
You won’t move further without pre-training. It’s the very first stage of a LLM large language model’s training. It’s at this step that you provide large datasets with information for future correct predictions. However, the more sources, the more time- and cost-consuming the training will be.
Our expert team at Label Your Data makes the training process easy. Send us your request for quality annotation that will fully meet your project requirements!
Even with large initial sources, the pre-trained models can lack accuracy. If we want to enhance the models to follow the instructions and give us answers based on the ground truth, we refer to the fine-tuning training mechanism. It takes a pre-trained model as a basis and makes adjustments to improve its performance.
Another training method is called reinforcement learning from human feedback (RLHF). If the previous two focus on increasing the likelihood of the next words, the RLHF pays attention to the overall quality of the model’s response. It helps to identify whether the response corresponds to the initial goal and assigns scores. The repetitive training adjusts the output to the best possible response. The introduction to ChatGPT shows it is one of the most successful training frameworks.
Now that you have a complete picture of the large language models explained, here are some of the examples of their applications.
What Are the Main Use Cases of Large Language Models?

When you ask yourself, “how do large language models work?,” you immediately refer to the well-known ChatGPT bot, a smart helper, which may even lead a conversation with you. But what were the initial purposes of a large language model, and what can it actually be used for?
This powerful NLP tool has much more to offer than just processing and generating a human language, or answering your questions. The most widespread large language models use cases include:
- Text generation and classification. You provide the needed parameters and the LLM generates you a coherent text. If you have a large dataset, the model will be able to classify it into categories.
- Translation. With the application of a LLM in multiple languages, you may receive a solid piece of machine translation. Its quality is still far from translating books as the humans do, but it can be really helpful in simpler tasks. A famous Google Translator is one of the most popular examples.
- Chatbots and conversational agents. More and more businesses implement chatbots that save you time and help you with quickly answering typical questions regarding your delivery or the price of the product. They are all based on LLMs, allowing them to engage in natural language conversations with you.
- Sentiment Analysis Services. The LLM helps to identify the sentiment expressed in the text. The connotation of the text as neutral, positive, or negative is handy in social media monitoring, gathering customer feedback, and leading market research.
How Do Major Industries Leverage Large Language Models (LLMs)?
We’ve already seen a wide use of artificial intelligence in business management and its application continues to grow. More industries want to be in the race, but some succeed more than others.
- Customer Support: We’ve already mentioned the chatbots and customer service virtual agents that can help you with answering general questions. However, businesses go further and develop bots that will not only perform a “question-answer” function but also place an order for you, answer your mail in multiple languages, and help you solve the issues.
- Healthcare: Currently, the LLMs are used in long patient notes classifications for easier information extraction. They are also helpful in gathering and analyzing patients’ feedback.
- E-commerce: You’ve already experienced suggestions in social media on buying this or that product. LLMs help improve the customer preferences and also gather their feedback.
- Education: With the help of LLMs we already create quizzes, assessments, and texts much quicker. If the assignment consists of a-b-c answers, LLMs save you time by assessing student’s answers and providing feedback.
- Marketing and Advertising: With sentiment analysis you can monitor trends in the market, while some companies already use the bots to create content for their ad campaigns, blogs, and articles, even though the quality can still be compromised.
- Travel and Hospitality: The application in the travel industry similarly lies in feedback analysis and recommendations. However, the improvement of models allows using them as guides. Ask ChatGPT about the landmark or show the image, and you’ll most likely get the general information that is usually present in audio or printed guides.
- Human Resources: One of the most widespread usages of LLM is the resume screening. The HR departments of multiple corporations already use the tools that do the screening in place of human specialists. All you have to do is to set up the needed parameters.
What’s Next for AI: The Sky’s the Limit with LLMs?
The appearance of large language models has shown an unprecedented interaction we have today with artificial intelligence. Spreading into all spheres of our life, they help us save time, automate tasks, and improve the quality of services we provide.
In a relatively short period of time, we’ve started interacting with bots who help us with our working routine and open up to a new world of possibilities. As the AI models progress and improve, their impact on our life will continue to grow. And the new versions and developments can be even more exciting.
Whether you prepare your data for further translation, classification, or sentiment analysis, our skilled team will help you annotate it for further usage by LLMs. Give us a call!
FAQ
Is ChatGPT a large language model?
Yes, ChatGPT is one of the most successful examples of LLMs, or more broadly Large Language AI Models (LLMs). It’s trained on the transformer architecture, which is built in a way to answer requests, or prompts, in a human-like manner.
What is generative AI vs. large language models?
Generative AI is a broader term, which focuses on various types of data to generate new content, including texts, images, videos, etc. Unlike generative AI models, which have broad applications across various creative fields, LLMs are specifically designed for handling language-related tasks. They are trained on text data and, based on billions of parameters, generate new content.
What is the most advanced large language model?
OpenAI’s version of GPT-4 is the latest LLM and the most progressive one. It’s trained on billions of tokens, and it has a higher accuracy of giving answers and providing solutions than its previous versions.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.