RAG LLM: Revolutionizing Data Retrieval

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

TL;DR
- Incorporate RAG for optimizing real-time data retrieval to provide clearer context.
- Generate more relevant responses across industries with the augmented retrieving technique.
- Increase your model's performance with the application of the hybrid technique of sparse and dense retrievals.
- Augment the contextualization of a model's data retrieval.
- Fine-tune the models and optimize parameters for more relevant outputs.
- Apply key metrics to evaluate the final outputs of RAG LLM models.
The Usage of RAG in ML Models
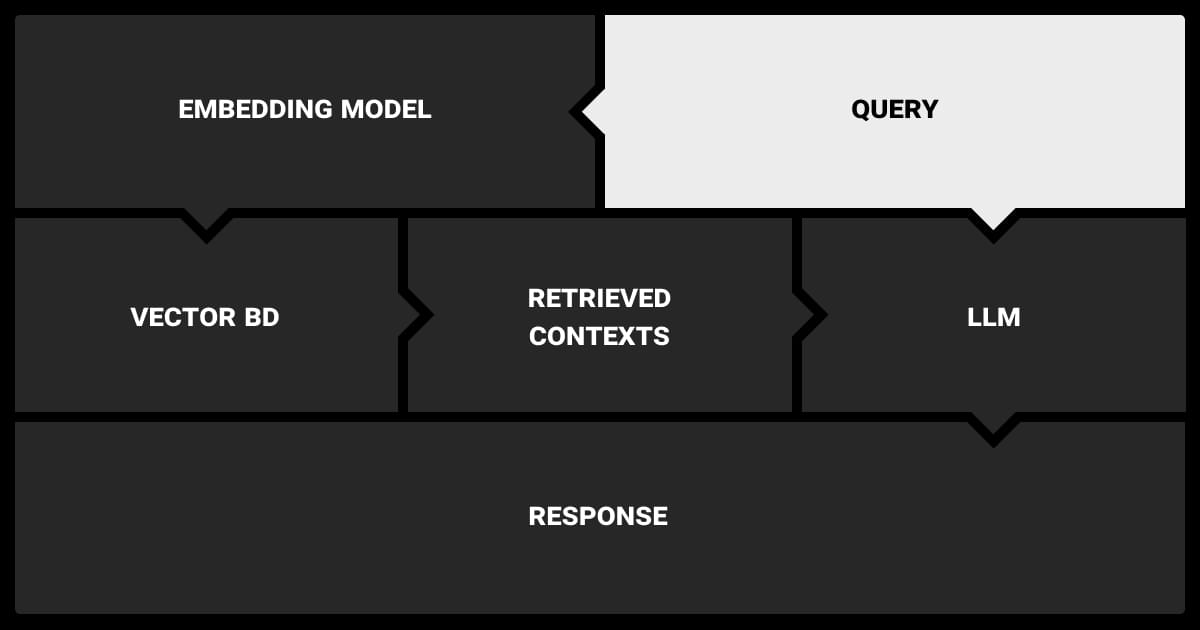
Traditional large language models (LLMs) perform in accordance with data they received during training. As a result, their outputs can be biased and inaccurate, especially when dealing with highly specific or up-to-date information. In this case, Retrieval-Augmented Generation (RAG) comes in handy. RAG enhances the capabilities of LLMs by introducing a retrieval mechanism that actively fetches relevant information from external sources during inference.
Retrieval-Augmented Generation (RAG) is a novel technique. It combines the best of two components: retrieval-based and generation-based models. Essentially, RAG models are crafted to connect the extensive information found in external databases or document collections with the generative power of large language models (LLMs).
The Concept of Retrieval-Augmentation
If we take traditional LLMs, they usually perform based only on the data they were trained on. This can be limiting if the needed information is too specific, outdated, or wasn't included during training. Instead, RAG model LLM overcomes this by adding a retrieval system that pulls relevant documents or data from an external source in real-time. This additional data is then used to guide the LLM, resulting in more accurate and contextually appropriate responses.
Hybrid Nature of RAG LLM Models
The specificity of RAG LLM models is that they use a hybrid approach, which consists of both retrieval and generation parts. The retrieval component locates the most relevant data from a vast database, which the generation component then uses to craft a response. This way, RAG models produce clearer answers based on the latest information. According to this study, the hybrid search helps the model to provide more accurate and relevant responses.
Applications and Advantages
The usage of RAG models is beneficial for open-domain tasks, where queries can be of different nature. The models can deal with unpredictability of request, retrieving and generating relevant responses. This opens doors to them in such areas as customer support, legal research, and even healthcare, where accuracy is a must. By tapping into external knowledge sources, RAG models address the limitations of traditional LLMs.
Advance your RAG models with our data annotation services. Try our free pilot to move forward with your machine learning project!
Technical Architecture of RAG LLM
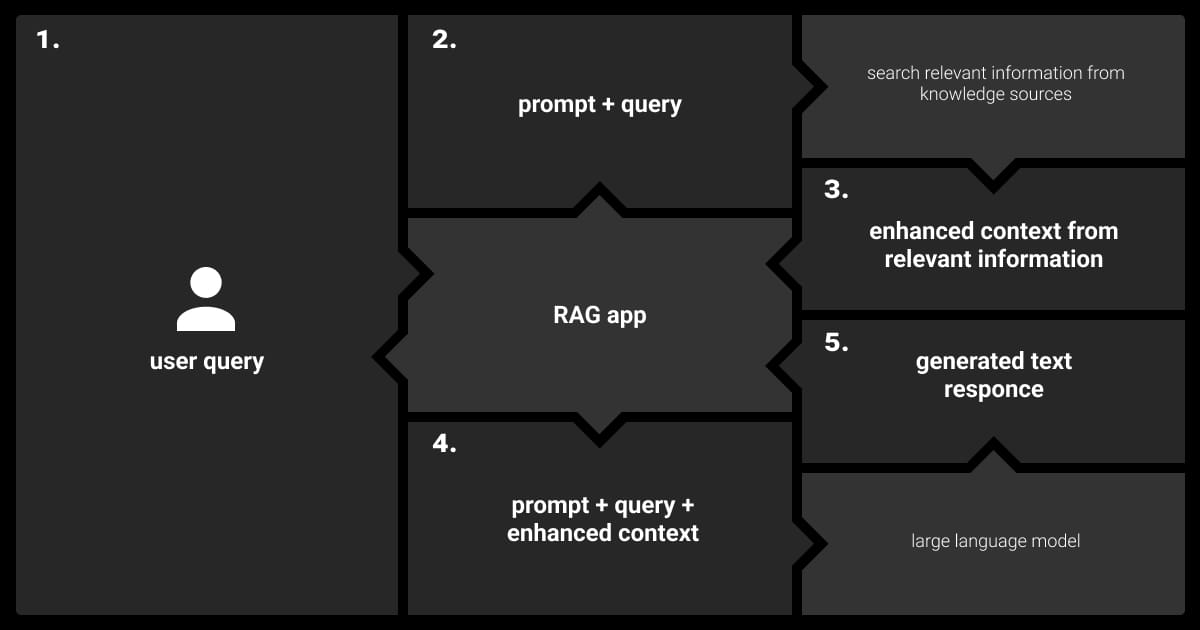
While Retrieval-Augmented Generation proves success as one of the most advanced techniques of AI, let's delve into its technical architecture. Specifically, let's see how the retrieval and generation components work together in LLM RAG architecture to go through pattern recognition in machine learning and generate contextually appropriate outputs.
Retrieval Mechanism
It's thanks to the retrieval system that RAG improves LLM outputs. In comparison to traditional LLMs, RAG retrieves the relevant information from huge datasets. It starts by creating dense vector representations of both the user's query and the documents in the corpus, helping to find the most relevant information.
Dense vs. Sparse Retrieval
| Dense retrieval | Sparse retrieval | |
| Principle | Relies on neural networks to encode queries and documents into dense vectors, semantic search. | Based on keyword matching, word frequency-based. |
| Functioning | Uses dense embeddings for document and query representation. | Uses traditional sparse representations like TF-IDF or BM25 for document and query representation. |
| Usage | For tasks requiring semantic understanding or deep context matching. | For keyword-based search and retrieval where exact word matches are important. |
| Model type | Transformer-based models are typically used for encoding queries and documents. | No neural models needed; relies on statistical methods for representation. |
| Performance | Performs well for semantic or contextual matches, but requires more computational resources. | Performs well for keyword-based retrieval but lack deep contextual understanding. |
Hybrid techniques are also used, combining sparse methods for exact term matches with dense methods for related term expansion.
Re-ranking and Filtering
Once the initial set of documents is retrieved based on their semantic similarity to the query, a re-ranking process is often employed to ensure that the most relevant documents are prioritized. This step is crucial, as the quality of the retrieved documents directly influences the accuracy of the final generated response in a RAG system LLM.
Efficiency and Accuracy
Dense retrieval offers better accuracy but can be resource-intensive, especially with large datasets. To manage this, RAG LLM models optimize the retrieval process by using pre-computed embeddings or approximate nearest neighbor search methods, speeding up retrieval without losing much accuracy. This balance is essential for the best LLM for RAG performance.
Augmenting LLM Prompts

How the final output of the RAG model will perform largely depends on the retrieved documents. After the retrieval mechanism identifies the most relevant documents, they are passed to the generation model, usually an LLM, which uses this data to craft a response and improve the overall output quality. This process ensures that the generated output is both contextually accurate and grounded in the most relevant information available.
Synergy of Retrieved Data and LLM Outputs
In Retrieval-Augmented Generation LLM, the generation model does not merely generate text based on its internal knowledge, but actively incorporates the retrieved documents into its generation process. This fusion ensures that the model’s output is grounded in up-to-date, contextually relevant information, enhancing its accuracy and relevance. This approach allows the model to dynamically adjust to new information, making it particularly effective for tasks requiring the most current and domain-specific data.
Contextualization of Generated Responses
The model uses the enhanced prompt, which blends the original input with added context and its own knowledge base, to generate a response. This process aims to produce a more accurate and helpful answer by incorporating the added context. RAG LLM tailors generative AI for enterprise needs, embedding context-specific details into existing LLMs to create a highly capable digital assistant. This advanced tool can generate specialized responses, such as in the legal field, and has the potential to transform business processes.
RAG LLM and Fine-Tuning
Fine-tuning is essential for optimizing Retrieval-Augmented Generation (RAG) models, helping them adapt to specific tasks and domains. It refines the retrieval and generation components, improving their integration and overall performance. With effective fine-tuning, you can enhance the RAG model's performance even more.
Challenges in Integration
The major challenge in integrating the RAG system LLM is managing latency that appears with the retrieval process. Since retrieval happens during inference, it can slow down response time, which is crucial for real-time applications. A careful design and tuning are needed to achieve smooth interaction between the retrieval and generation components in RAG-based LLM models.
Domain-Specific Fine-Tuning
The fine-tuning of RAG models helps them to perform even better in specific domains. For example, in healthcare, adjusting the model using medical literature and patient data can boost its ability to retrieve and generate relevant information for clinical queries. This fine-tuning process typically includes high-quality, domain-specific data curation and refining of the model to suit the unique needs of that domain.
Parameter Optimization
Optimizing the parameters of a RAG model is key to balancing retrieval precision and generative coherence. For instance, tweaking the retrieval depth (the number of documents retrieved) and the balance between retrieval and generation components can greatly affect performance. Proper tuning ensures the model produces exact responses that correspond to the assigned tasks.
Role of Data Annotation in RAG
Data annotation is a crucial element in the success of RAG models, especially for improving the retrieval component. High-quality annotated data is vital for fine-tuning the model's ability to identify and prioritize relevant documents, which directly impacts the accuracy of retrieval. An example can be data annotation in healthcare, where understanding specific terminology is key.
However, annotating data for RAG models can be challenging, particularly with large and varied datasets. It requires domain-specific knowledge and consistent labeling to ensure the model learns from the best examples. To improve the annotation process, using advanced tools, applying iterative strategies, and leveraging active learning techniques can significantly enhance both the efficiency and effectiveness of the annotations, ultimately leading to better model performance.
Explore data annotation techniques to elevate the accuracy and performance of your RAG models. Contact us for advanced data annotation services!
Evaluating RAG LLM
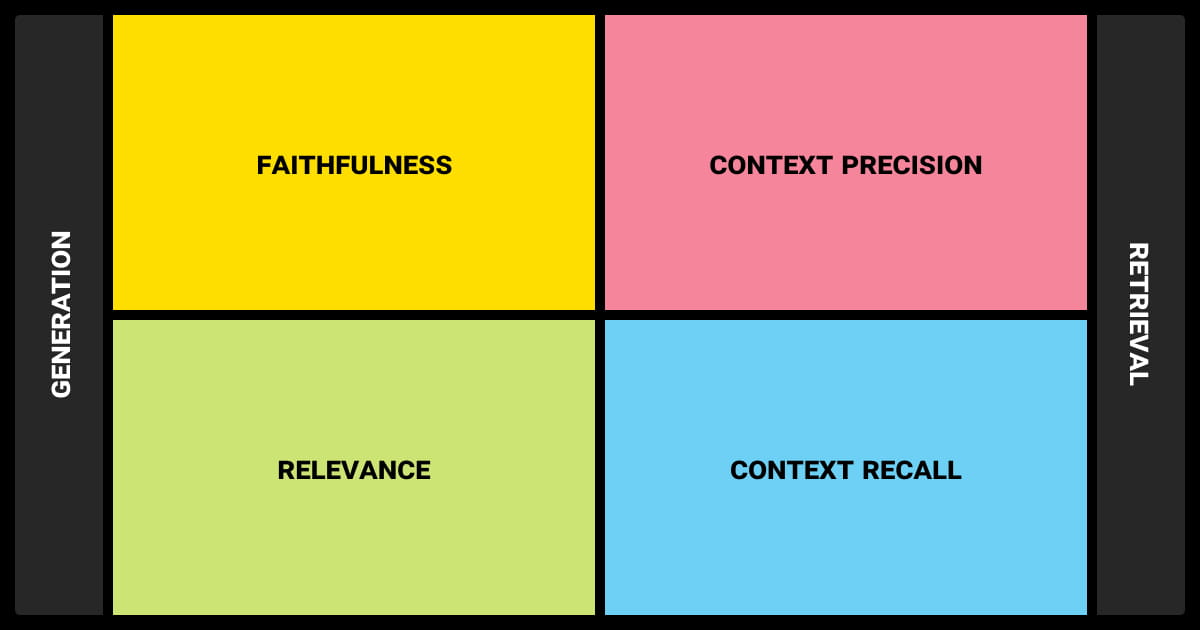
Even with higher accuracy and better performance, RAG models LLM require thorough evaluation. By examining both retrieval and generation components of the model, we can adjust its performance and uncover areas for improvement.
Key Metrics for RAG Evaluation
Evaluating RAG models requires a comprehensive set of metrics that assess both retrieval accuracy and the quality of the generated outputs. Here are the most common ones assessed in RAG models:
| Metric | Feature | Explanation |
| Precision | Measures the proportion of retrieved documents that are relevant out of all retrieved documents. | Higher precision indicates fewer irrelevant documents in the retrieved set, meaning more accurate retrieval. |
| Recall | Measures the proportion of relevant documents that are successfully retrieved from the entire document set. | Higher recall indicates a greater ability to retrieve all relevant documents from the database, ensuring completeness. |
| Exact Match (EM) | Measures the percentage of generated responses that exactly match the ground truth answer. | Exact match checks if the entire generated sequence matches the correct answer, useful in QA systems. |
| ROUGE | Evaluates how well the generated text overlaps with the reference text, focusing on recall of n-grams. | Measures recall-based text overlap, comparing n-grams of generated text to reference text for coverage. |
| BLEU | Measures the overlap between the generated text and reference text, focusing on precision of n-grams. | BLEU measures precision-based text overlap, comparing n-grams to evaluate how well the generated text matches the reference. |
| Holistic Performance Metrics | Provides a unified view of RAG performance, combining both retrieval and generation quality (e.g., success rate, overall accuracy). | Evaluates overall system performance, often combining retrieval accuracy and generation fluency in a holistic metric. |
Precision and Recall in Retrieval
Precision indicates the percentage of retrieved documents that are actually relevant, while recall measures the model's effectiveness in retrieving all relevant documents from the corpus. These metrics are crucial for ensuring that the retrieval mechanism supplies the generation component with the most pertinent information.
Evaluation of Generated Outputs
In addition to evaluating retrieval accuracy, it’s crucial to assess the quality of the generated outputs. Metrics such as BLEU, ROUGE, commonly used in machine translation and summarization tasks, are also applicable to RAG models. These metrics measure how closely the generated text aligns with reference outputs, providing insights into the coherence and relevance of LLM RAG models' responses.
Holistic Performance Metrics
Given that RAG models involve a two-step process (retrieval followed by generation), it’s important to evaluate the entire pipeline holistically. We evaluate the output's overall quality by examining the relevance of the retrieved documents and the coherence of the generated text. These holistic metrics ensure that improvements in one area (e.g., retrieval accuracy) do not negatively impact the overall performance of the model.
Traditional LLMs or RAG?
Comparing traditional LLMs with RAG models highlights RAG's clear advantages in retrieval and response generation. Traditional methods like BM25 and TF-IDF rely on keyword matching, which often fails to capture the nuanced meanings of queries, especially when phrasing differs. In contrast, RAG uses dense retrieval to capture semantic similarities, significantly improving the relevance of retrieved information.
For open-domain tasks, where query diversity is high, RAG models are superior. Traditional systems struggle with context and intent, relying too heavily on exact matches. RAG’s ability to interpret and retrieve semantically relevant documents gives it a decisive edge, making it a more effective solution for complex information retrieval and generation tasks.
| Parameters | Traditional LLMs | RAG (Retrieval-Augmented Generation) |
| Response generation | Generates responses solely based on pre-trained knowledge. | Generates responses based on retrieved external documents. |
| Knowledge source | Relies solely on the internal knowledge encoded during training. | Uses both pre-trained knowledge and real-time retrieval from external databases. |
| Context handling | Limited to fixed context length (e.g., token window). | Can handle dynamic, external context through retrieval. |
| Scalability | Less scalable for dynamic knowledge updates without retraining. | Highly scalable as external knowledge can be updated without retraining. |
| Efficiency | Less efficient for real-time information retrieval or updated knowledge. | More efficient for providing up-to-date, specific information. |
| Use cases | Best suited for tasks that rely on general knowledge and static data. | Ideal for tasks requiring real-time, domain-specific, or rapidly changing knowledge. |
| Output quality | Good for general knowledge, but may lack up-to-date or domain-specific information. | Higher accuracy for domain-specific or factual queries due to real-time retrieval. |
How Label Your Data Can Assist You with RAG
Our annotation services ensure that your models are trained with precisely labeled data, improving the accuracy of both retrieval and generation processes. By providing expertly annotated datasets, we help your models better understand domain-specific terminology and context, leading to more relevant and accurate responses.
What is the difference between RAG and LLM?
Whatever the field and difficulty of your dataset, partner with us to enhance your RAG and LLM models. Ensure your models deliver the precision and context you need for further application.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is the difference between RAG and LLM?
RAG (Retrieval-Augmented Generation) enhances traditional LLMs (Large Language Models) by incorporating a retrieval mechanism that pulls in relevant external data during inference. While LLMs generate responses based solely on pre-trained knowledge, RAG models combine this generative ability with real-time data retrieval, resulting in more accurate and contextually informed outputs.
What is the RAG method for LLM?
The RAG method for LLMs involves combining a large language model with a retrieval system that fetches relevant external data in real-time during the generation process. With this approach, the model can augment its responses and elaborate them with context-specific, up-to-date data. This allows us to get more accurate and relevant outputs than when we solely pre-train models with limited knowledge.
What are the limitations of RAG LLM?
RAG LLMs, though effective, have some limitations. The real-time retrieval process can slow down response times, and the model's performance heavily depends on the quality of external data sources. If irrelevant or low-quality data is retrieved, it can degrade the output. Additionally, fine-tuning and integrating the retrieval and generation components can be complex and resource-intensive.
What is RAG in machine learning?
This is a technique that combines the retrieval of existing knowledge with generative models. With this technique, models perform better and give more contextually relevant responses. It uses relevant documents to retrieve data and accomplish tasks requiring domain-specific updated knowledge.
How to connect RAG to LLM?
You integrate a retrieval mechanism with the language model. First, the retrieval component fetches relevant documents from an external knowledge base, depending on the input query. Then, the LLM processes both the query and the retrieved documents to generate a response, allowing the model to leverage both its pre-trained knowledge and real-time information from the external source for more accurate answers.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.