What Is Data Curation and Where It Stands in the Age of Big Data?

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

One can hardly achieve effective results in the data-driven business without a robust data management strategy in place. If you want to get value from your data, you need to apply analytics and machine learning techniques to make it work for your business.
That might sound simple at first. Yet, modern organizations don’t always know where to get the right data and what to do with it once they have it on hand. The data itself must be thoroughly curated to make it fit your specific business scenario, especially when you’re building an ML model. Otherwise, the entire data pipeline is at risk of failure.
Fortunately, the importance of data curation as an independent discipline is gaining traction in the era of big data. Together with data governance, they establish a well-known term you’ve probably heard of — data-centric AI. In this article, we’ll explore the basics of data curation and explain why it matters in data annotation. Let’s get started!
Explaining the Process of Data Curation in the Context of ML Model Development
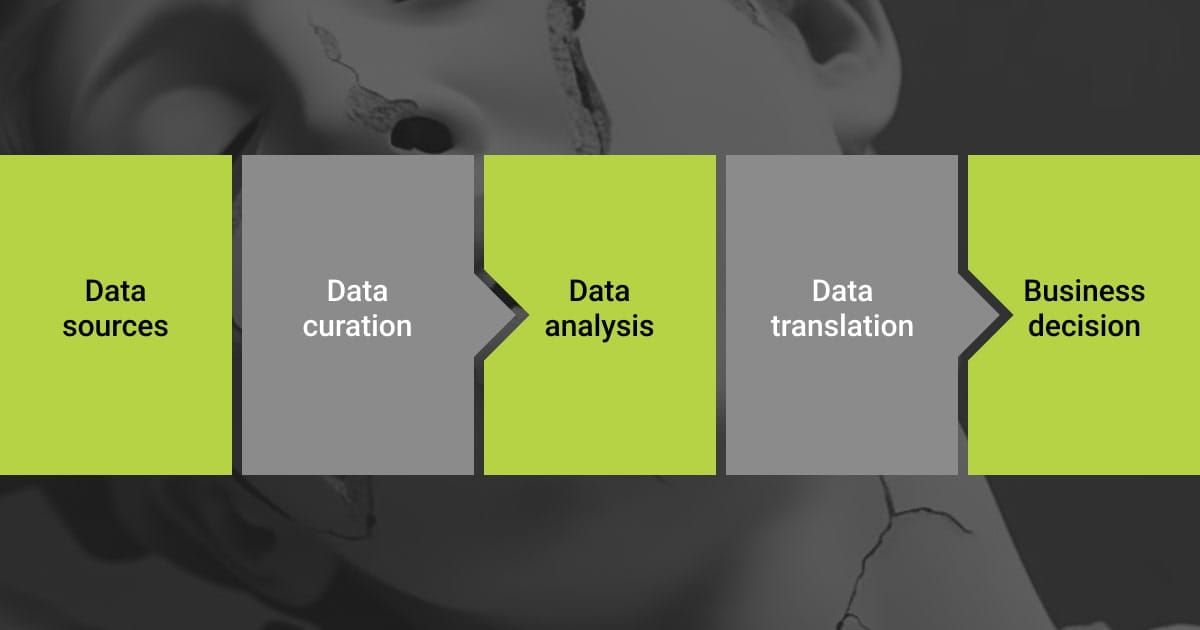
As a data annotation company, Label Your Data has faced all sorts of cases. Sometimes, the data volumes are so large that it can be difficult for our data labelers to decide where to start and which labeling points to choose. Not to mention the fact that data tagging services are also resource-intensive.
In this case, data curation can save the day. This serves as the foundational step for many businesses wishing to organize their data processes. Most importantly, data curation helps them maintain and enhance the quality of data before training, validating, and testing the algorithms. Also, efficient data curation techniques helps businesses to:
- Curate data effectively (of course)
- Save valuable time of ML engineers
- Dedicate more time to an ML model development
- Focus on the model integration into the business workflow
So, in essence, data curation covers data management, data annotation, and data organization. This way, it allows us to ensure that the data we work with is of the highest quality, accessibility, and usability. If this step is ignored, then you risk getting poor model performance because of not properly curated training data.
To give you a better idea of what is data curation, say you’re training an ML model to recognize handwritten digits. You feed the model with thousands of images of digits written in a specific font and style. Despite having precise labels for this dataset, the model might struggle to accurately identify digits written in a different font or style.
To mitigate this, some organizations manually curate the training data by selecting subsets that represent diverse writing styles. However, this manual curation adds complexity to the data preparation process, risking human error and potentially diluting the training dataset with irrelevant examples. The challenges of data curating are particularly pronounced for end-user data scientists, who may lack a robust computer science background.
What Is Data Curation with the Human-in-the-Loop Approach?
Despite the beauty of automation in our days, data curation is not the process to fully automate. Even semi-automated options are not the case because data curation is often tailored to a specific context and, therefore, requires specific data for analysis.
For this reason, the human-in-the-loop, or simply HITL, approach helps to skillfully combine human supervision and automatic data curation tools used for complex tasks. They are:
- Content creation
- Selection
- Classification
- Transformation
- Validation
- Preservation
So, what is data curation with human experts in the loop? HITL systems enable data curators to save time by handling tasks that can be done automatically. However, humans still oversee the entire data curation process to make sure everything is done correctly.
More About the Experts Behind Effective Information Management that Curate Data

The essence of curated data definition is arranging and handling information. The main goal is to make datasets easy to discover, comprehend, and access, which means having clear and detailed descriptions for the datasets.
As you’ve collected a dataset for your project, this data is usually not ready for further analysis and preservation. This is when data curators step into the game. Data curators, which can be anyone working with the data, take the actions for maintaining and further processing raw data throughout the entire ML pipeline for various applications.
In an organization, the data curator, often a data analyst, engineer, or scientist, is accountable for maintaining and redefining data. The team collectively decides who holds this responsibility. The curator determines data relevance, storage, definition, and access, as well as responsible for metadata management.
In fact, various team members contribute to data curation, sharing their knowledge. Crowdsourcing is vital for collaborative data management in self-service analytics. Domain curators, experts in specific data domains (customer, product, etc.), share knowledge, while collaborative curators, numerous but with modest responsibility, participate in data sharing.
Lead curators, usually few in number, play a crucial role in moderating data catalog content. They have high responsibilities for metadata and catalog quality, requiring a substantial time commitment for this process. Let’s now take a look at the key steps for efficient data curation in machine learning!
A Step-by-Step Approach to Curating Data in ML
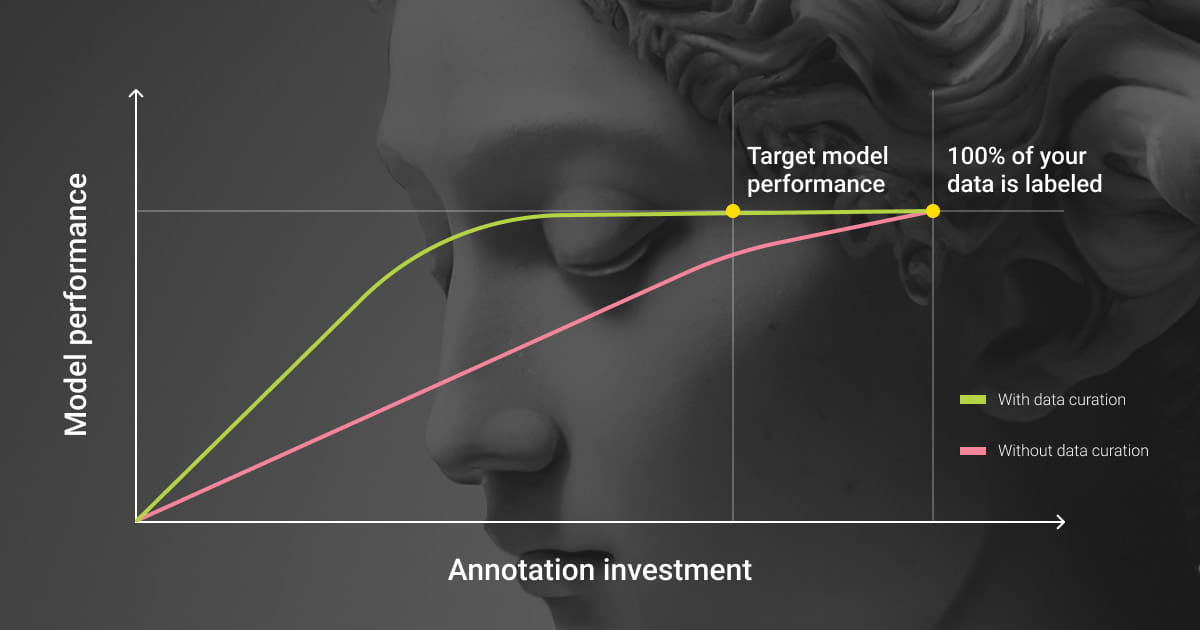
Since a data curator is responsible for organizing and managing a collection of datasets for a specific ML project, there are certain rules to follow along the way. That is, making decisions at each phase of the data lifecycle that will ultimately affect its quality and usability.
The list of steps for curating data may vary. This depends on your project needs, as well as your data needs. Here are the most common practices to curate data assets, achieve their high quality, and make decisions based on that data:
- PlanningWhen it comes to big data accuracy, you can’t do without planning. Having a clear vision and data strategy in place ensures your data aligns with your project goals and the model itself.A data curator must identify the type of data to work with, as well as the tools to automate or semi-automate the process. But don’t forget about the data governance at every step.
- Data CollectionGathering the right data for your project is crucial for generating and ingesting data for the next steps. Data collection depends on the pre-set criteria. The data curator must understand the nature of the data gathered, the sources, and the techniques to use, or trust this process to expert data collection services.Besides, heterogeneous data conditions and the connections between different data types impact the complexity of data structure. Depending on the data type, you must decide how much data management is needed and whether manual or automated data collection is the right choice. Complex data may need more processing later in the life cycle.
- Data IngestionData ingestion involves processing and loading the collected data into a central repository or data warehouse. Due to the extensive diversity of data, there might be a need for large-scale ingestion methods. They could include crowdsourcing, scheduled crawling, or automation.
- Metadata GenerationIn this stage, a curator is crafting detailed metadata — the essential background information that helps us understand the data better. Think of metadata as the data’s ID card: it tells us what the data is and how we measured it. It also tells us where the data came from during processing, giving us a clear picture of its origin.This involves creating, gathering, and maintaining enough metadata. Here, you can use the techniques to automatically grab this key information, such as meta-tag harvesting, content extraction, and analyzing unstructured text in data mining, among others.
- Quality AssuranceData curators must ensure not just the quality of the data but also understand its origin and how it is used to guarantee its reliability, privacy, and security. Evaluating the quality of data is crucial because it directly ties to veracity.Some methods here include:
- Developing an iterative approach through the continuous integration of new and existing data;
- Standardizing Computer Vision or NLP data protocols;
- Using metrics to assess data value.
- Data Storage and PreservationChallenges related to data storage include accessing real-time data and moving it from the processing unit to a storage area for safekeeping. The architecture involves two layers: hardware infrastructure and management infrastructure. Their adoption is crucial due to the varied nature of data (structured, unstructured, and semi-structured). Ultimately, well-designed data storage infrastructures must prioritize both data security and the protection of data ownership.
- Discovery and AccessThe step of discovering and accessing data is crucial in handling curated data. It helps us reuse data and find patterns and insights. This involves using platforms or systems to access the data, making sure there’s standardized information about the data, and using ontologies to improve searching. Platforms, especially in cloud computing, make data easy to get to and control. This step also implies data security measures, such as restricted access to data and specific permissions.
- Maintenance and UpdatesAs the final step in data curation, specialists consistently maintain, update, and refresh data to uphold its accuracy and relevance. Ongoing maintenance activities not only contribute to the overall quality and reliability of the curated data but also protect it against inaccuracies and outdated information. This is also crucial for supporting informed decision-making and sustaining the efficacy of data-driven processes.
How Label Your Data Can Help?

There’s an intricate relationship between data curating and effective data annotation. Our team at Label Your Data goes beyond traditional data labeling, encompassing a suite of additional data services that enhance the overall curation process. With a commitment to accuracy and organization, we ensure that curated datasets meet the highest standards for your ML applications.
By choosing Label Your Data, you’re not just getting collected or annotated datasets. You’re gaining a comprehensive solution for data curation, setting the foundation for reliable and impactful machine learning outcomes.
FAQ
What are the data curation activities?
Data curation activities involve the organization, management, validation, and enhancement of datasets to guarantee their quality, usability, and relevance for analysis or use in various domains.
What are data curation tools?
Data curation implies using relevant tools and filtering techniques to detect what data works and what data doesn’t. These tools are usually software or platforms designed to facilitate the organization, cleaning, validation, and management of data curated, ensuring its quality and accessibility for analysis and use.
What are the 5 C’s of curation?
The 5 C’s of curation are collection, categorization, critiquing, conceptualization, and circulation. They represent key aspects in the process of organizing and managing information.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.