Data Annotation: Your Complete Guide (2026)

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- What Is Data Annotation in Machine Learning
- Data Annotation Types and Tools
- Current Challenges in Data Annotation
- Best Practices for Data Annotation
- How to Outsource Data Annotation Tasks
- Top Data Annotation Vendors in 2025
- Use Cases of Data Annotation
- Industries Leveraging Data Annotation
- Future Trends in Data Annotation
- Our Approach to Data Annotation: Real-World Cases
- About Label Your Data
- FAQ

TL;DR
- Data annotation ensures precise AI model training by labeling datasets.
- Various annotation types, like text and image, serve different AI tasks.
- In-house annotation offers control, while outsourcing saves resources.
- Open-source tools are cost-effective for small projects; commercial tools offer advanced features.
- Combining automation with human review ensures high-quality annotations.
What Is Data Annotation in Machine Learning
Data annotation transforms raw data into labeled datasets that machine learning algorithms can use to learn and make predictions. Without it, ML models can’t produce reliable results.

Annotated datasets help:
- Data scientists streamline supervised learning workflows.
- ML engineers build precise and efficient models.
- AI startups and companies scale projects while managing costs.
- Academic researchers improve the accuracy of their studies.
- Technical decision-makers understand how data quality impacts outcomes.
- C-level executives evaluate strategies to achieve business goals.
Think of a self-driving car learning to navigate. Without labeled data marking pedestrians, road signs, or other vehicles, the driverless algorithm remains blind to its surroundings. Similarly, in text analysis, annotations like names or sentiments give models the context they need to interpret language.
In this guide, we share insights from our experience on keeping annotations accurate, scaling operations effectively, and managing in-house teams. We also review some of the top data annotation tools and vendors to help you make informed decisions.
Data Annotation Types and Tools
Different types of data annotation address the needs of various machine learning tasks. Here’s a breakdown of the main types and the tools designed to handle them effectively.
Text Annotation
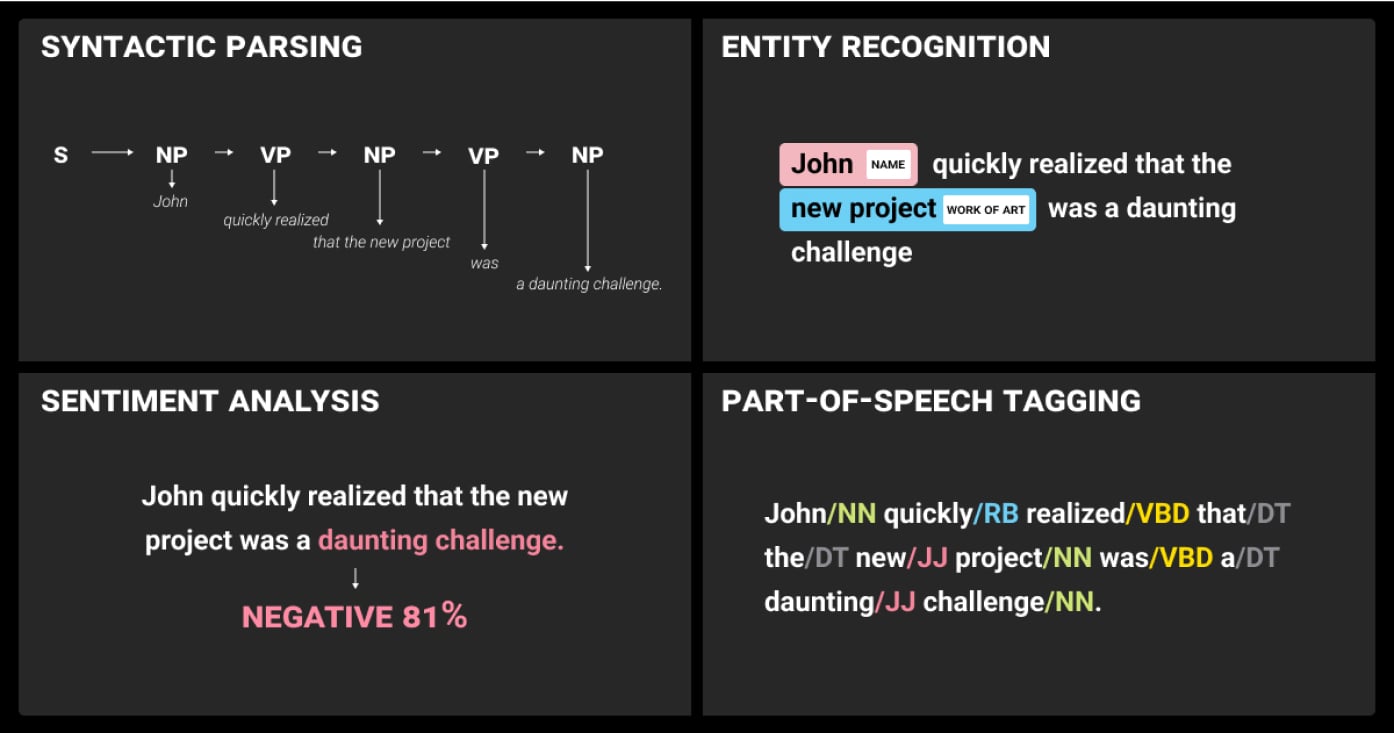
Text annotation involves labeling words, phrases, or sentences to help models understand language. It’s essential for natural language processing services.
Common tasks:
- Syntactic Parsing: Analyzes sentence structure.
- Semantic Parsing: Understands text meaning.
- Dependency Analysis: Examines word relationships.
- Named Entity Recognition (NER): Identifies entities like names and dates.
- Sentiment Analysis: Determines the sentiment expressed in text.
- Contextual Embeddings: Uses embeddings for context-aware annotations.
- Part-of-Speech Tagging: Labels words by their grammatical roles.
Tools to consider:
- Prodigy: Ideal for NER and custom NLP workflows.
- LightTag: Built for team collaboration and large-scale projects.
- Amazon Comprehend: Focused on sentiment and entity recognition.
Image Annotation

Image annotation adds labels to images for computer vision tasks like object detection and classification.
Common tasks:
- Keypoints: Best for motion tracking and identifying specific points on objects.
- Rectangles (Bounding Boxes): Used for object detection by drawing boxes around objects.
- Polygons: Capture precise shapes and boundaries of objects.
- Cuboids (3D Boxes): Annotate objects in three dimensions.
Tools to consider:
- Labelbox: Offers collaboration and automation features.
- SuperAnnotate: Supports complex projects with advanced management tools.
- CVAT (Computer Vision Annotation Tool): Free, open-source, and highly customizable.
Automated image annotation tools and collaborative platforms can facilitate efficient annotation workflows.
Segmentation
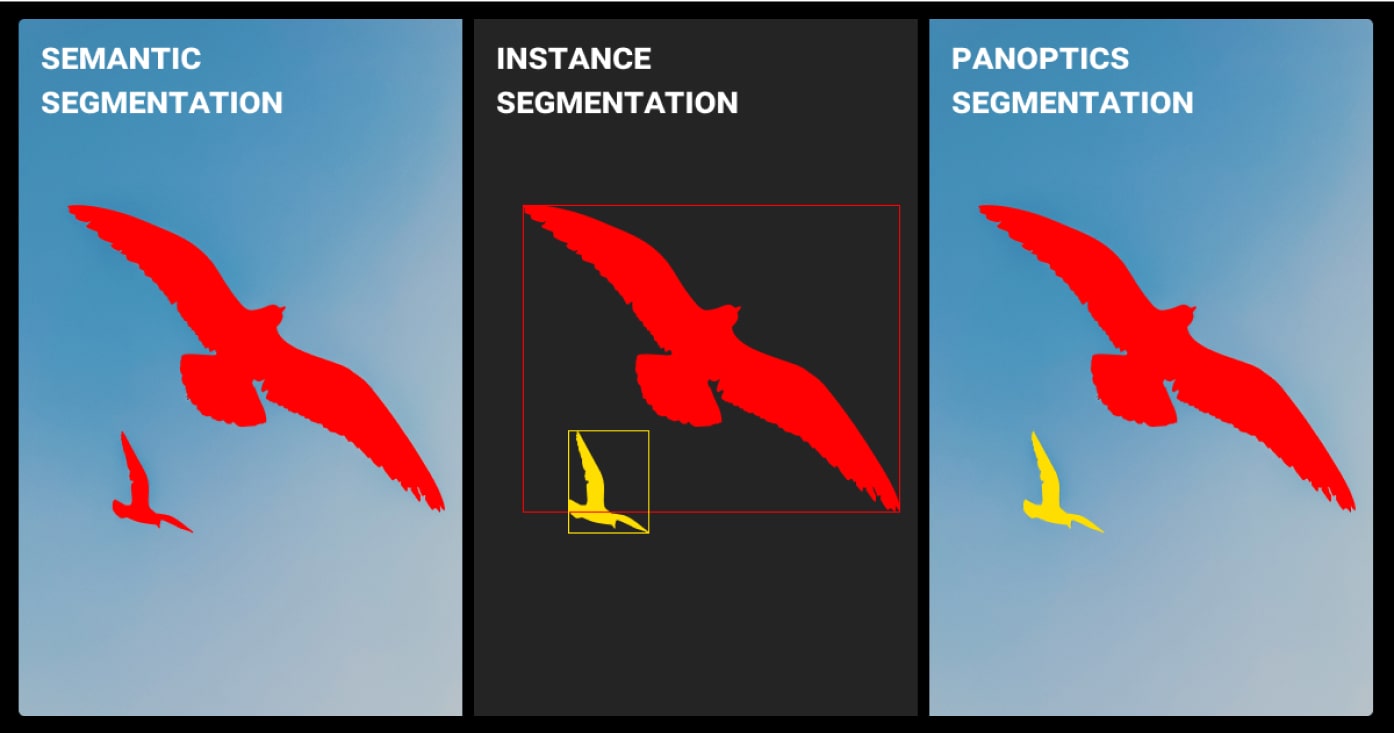
Image segmentation divides images into meaningful regions, enabling ML models to perform detailed object recognition and scene analysis.
Common tasks:
- Semantic Segmentation: Classifies each pixel into a category without differentiating instances.
- Instance Segmentation: Identifies and separates each instance of an object.
- Panoptic Segmentation: Combines semantic and instance segmentation for complete scene understanding.
Tools to consider:
- Labelbox: User-friendly for semantic segmentation.
- SuperAnnotate: Robust for instance segmentation projects.
- Scalabel: Combines semantic and instance segmentation efficiently.
Video Annotation
Video annotation involves labeling moving objects across frames to track motion or identify activities.
Common tasks:
- Object Tracking: Follow objects through frames.
- Activity Recognition: Label specific actions or behaviors.
Tools to consider:
- V7 Darwin: Known for its AI-assisted annotation features.
- Scalabel: Good for collaborative video projects.
- Annotell: Focused on video data for autonomous systems.
Audio Annotation
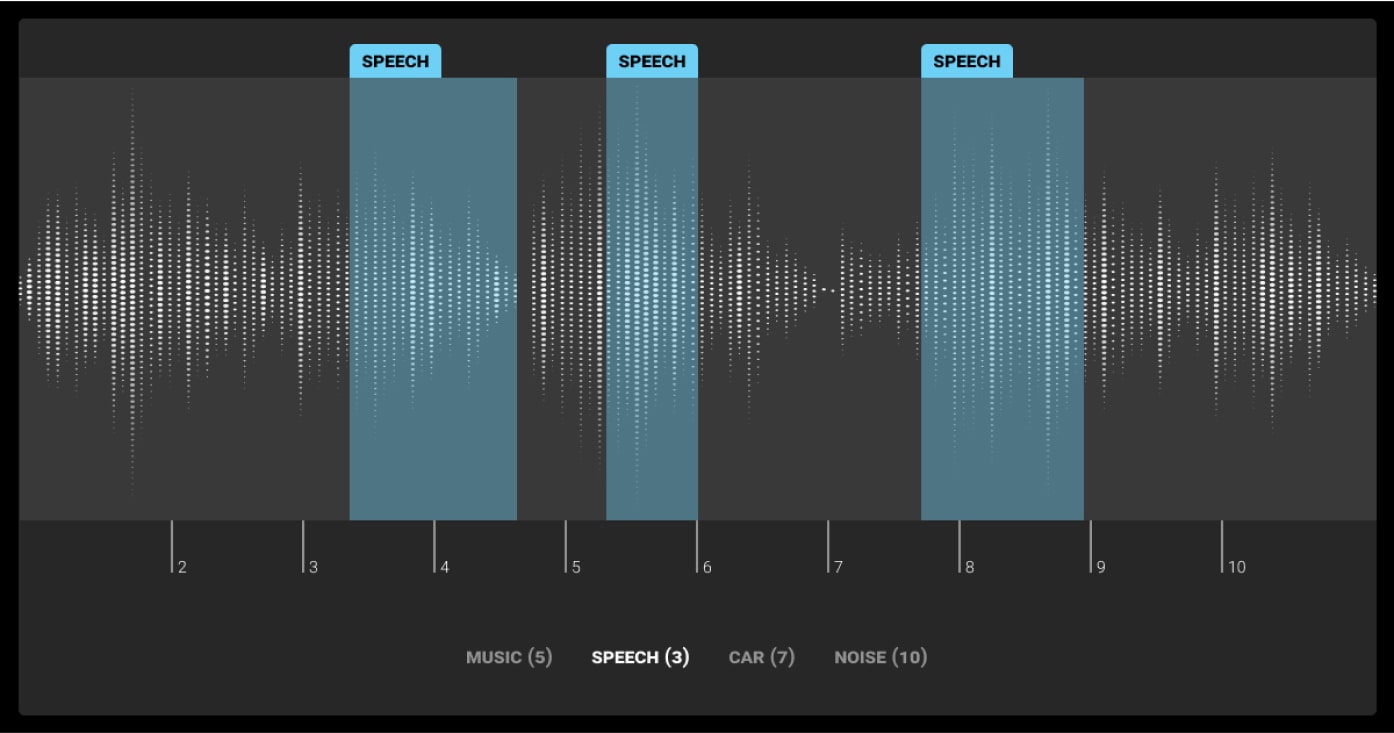
Audio annotation helps train models to recognize speech, emotions, and other audio patterns for tasks like AI sound recognition.
Common tasks:
- Phoneme-Level Transcription: Transcribes at the phoneme level.
- Speaker Identification: Identifies different speakers.
- Acoustic Event Detection: Detects specific sounds or events.
- Word-Level Transcription: Transcribes words for detailed analysis.
- Emotion Detection: Identifies emotions in speech.
- Language Identification: Determines the language spoken.
Tools to consider:
- Sonix: Provides automated transcription with manual editing capabilities.
- Rev: Great for high-accuracy audio transcriptions.
- Otter.ai: Suitable for real-time annotation and meeting transcription.
3D Data Annotation

3D data annotation, like point cloud labeling, is used in tasks involving spatial information, such as robotics and autonomous vehicles.
Common tasks:
- Point Cloud Segmentation: Segments 3D point clouds.
- Object Classification: Classifies objects within 3D data.
- Bounding Box Annotation: Uses 3D boxes to annotate objects.
- Lane Marking: Identifies lane boundaries for autonomous driving.
- Environmental Perception: Enhances navigation in robotics.
- Surface Analysis: Analyzes terrain and surfaces.
Tools to consider:
- Scale AI: Specializes in LiDAR and 3D annotations.
- Pointly: Designed for efficient point cloud annotation.
- SuperAnnotate: Offers robust 3D data annotation capabilities.
- Labelbox: Robust tools for 3D data labeling.
LLM Annotation
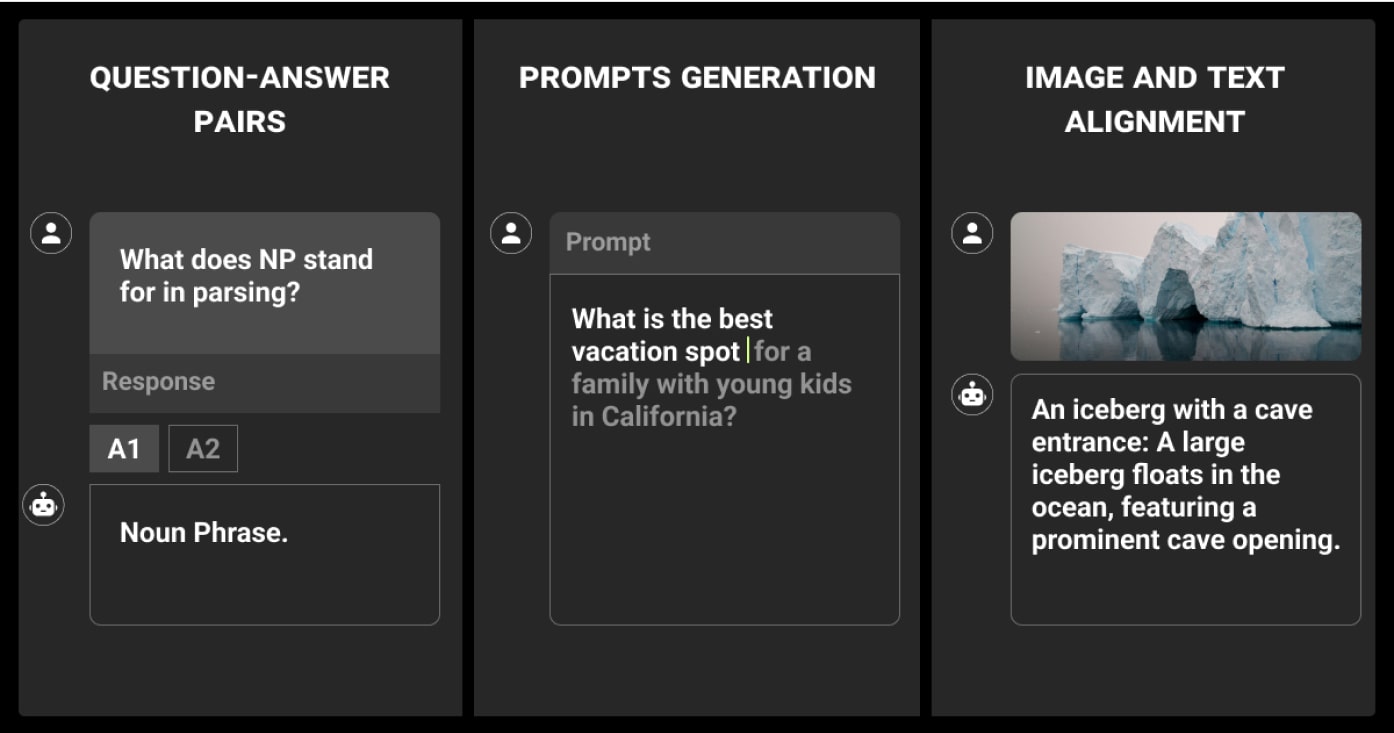
LLM data labeling focuses on preparing datasets for fine-tuning large language models.
Common tasks:
- Text Classification: Labeling text into predefined categories.
- Question-Answer Pairing: Creating datasets for training conversational models.
- Prompt Engineering: Designing prompts to guide model behavior.
- Intent Recognition: Identifying user intent in queries.
- Domain-Specific Fine-Tuning: Preparing data tailored to niche industries or use cases.
Tools to consider:
- Hugging Face: A leading platform for managing and fine-tuning LLMs.
- Snorkel: Helps automate LLM annotation with weak supervision techniques.
- Amazon SageMaker: Supports large-scale LLM annotation and training workflows.
Current Challenges in Data Annotation
Poor data quality is responsible for 80% of AI project failures. As data volumes continue to grow, we’ve seen how challenging it can be to maintain high-quality annotation workflows and tackle data labeling challenges effectively.
The rise of synthetic data and LLM data labeling has only added to the complexity.
Key issues you might face include:
Scaling for Big Projects
Large datasets demand significant effort, and scaling can strain your team and tools.
Balancing Speed and Quality
Automated tools are faster but can miss the nuances that humans catch. Manual work is accurate but slower.
Domain-Specific Knowledge
Some tasks, like labeling medical data or legal documents, require specific expertise, making it harder to find qualified annotators.
Quality Control
Reviewing every label for accuracy isn’t practical at scale, but unchecked errors can harm your ML model.
Cost Management
High-quality annotation isn’t cheap, and finding the right balance between budget and quality is tricky.
Integrating LLMs in Annotation
Incorporating various types of LLMs introduces challenges in consistency, bias management, and scaling.
Best Practices for Data Annotation
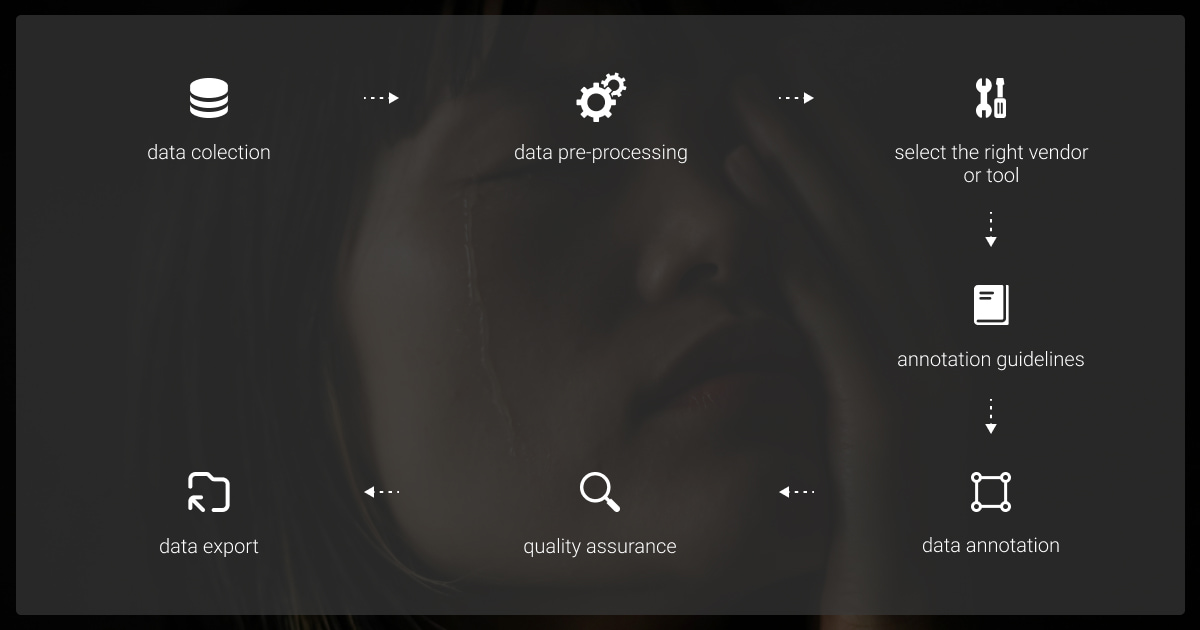
Overcoming data annotation challenges requires a mix of strategic planning, the right tools, and practical workflows.
Here’s how you can approach this critical task efficiently:
Build a Solid Annotation Workflow
A clear process keeps projects organized and reduces errors. Break the workflow into manageable steps:
- Define Objectives: Decide what the model needs to learn and identify the data types involved.
- Measure dataset volume by counting data points, assessing complexity, and consulting experts for planning.
- Set Guidelines: Create detailed instructions for annotators to standardize labeling practices.
- Pilot Projects: Start small with a subset of the data to test workflows and refine the process before scaling.
- Iterate: Regularly update guidelines and processes based on feedback and issues encountered.
Use the Right Tools
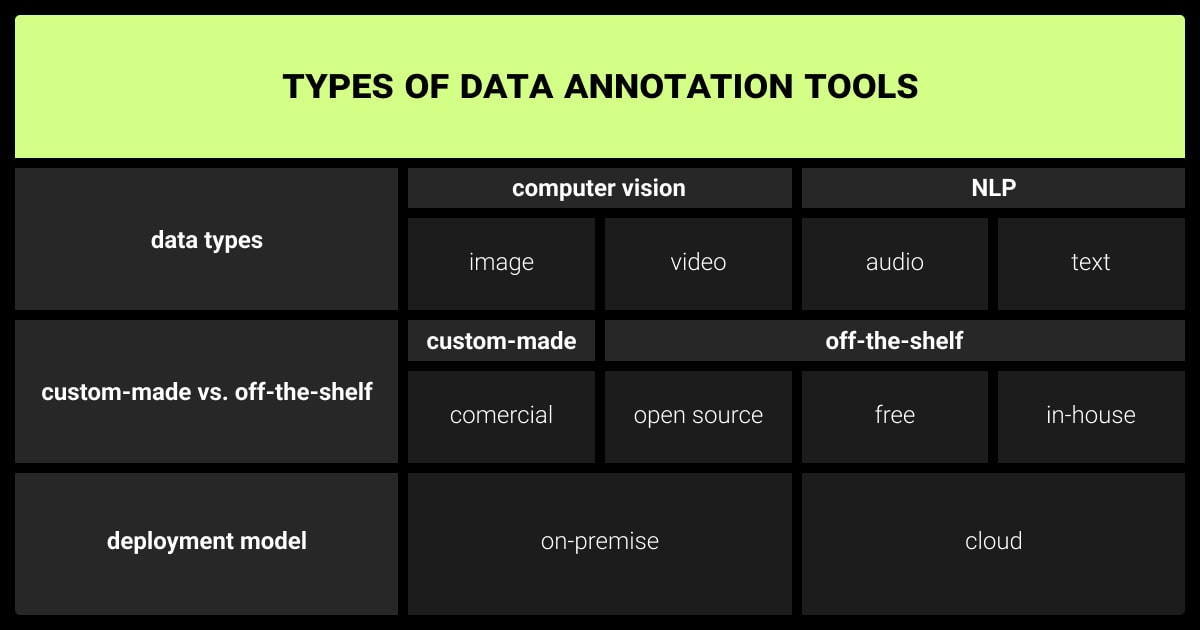
Annotation tools can streamline the process. Choose tools based on your specific needs:
- Text Annotation: Select tools with NLP-specific features like entity recognition and sentiment analysis.
- Image/Video Annotation: Choose platforms with collaborative interfaces for object detection and segmentation.
- 3D Data Annotation: Opt for tools designed for point clouds and spatial data handling.
This comparison can help you decide:
| Tool Name | Type | Best Use Cases | Pros | Cons |
| CVAT | Open-source | Complex computer vision projects | Flexible, robust features | Steep learning curve, limited automation |
| Labellerr | Commercial | Enterprises with large datasets requiring high accuracy | Supports complex data types, ML pipeline integration | Higher costs for large projects |
| Labelbox | Commercial | Flexible annotation for various data types | User-friendly interface, strong API support | Limited free version |
| SuperAnnotate | Commercial | High-volume image and video projects | Excellent for visual data | Limited support for non-visual data |
| Appen | Commercial | NLP and complex datasets for large enterprises | High-quality annotations with human review | Slow setup for small teams |
| V7 | Commercial | Large teams handling image and video data | Advanced tools, seamless integration | Custom pricing may not suit smaller budgets |
| Amazon SageMaker | Commercial | Teams using AWS with large datasets | Strong AWS integration | Requires AWS environment |
| Roboflow | Commercial | Startups or small teams with image data needs | Simple and user-friendly | Limited NLP features |
| Dataloop | Commercial | End-to-end annotation for diverse data types | Flexible and scalable | Higher costs for advanced features |
| Scale AI | Commercial | Enterprise projects needing quality and scalability | Enterprise-grade support | Premium pricing model |
| Keylabs | Commercial | Mid-size teams with visual data projects | Cost-effective and flexible | Limited support for very large datasets |
| Kili | Commercial | Small to mid-size projects needing flexibility | Affordable and versatile | Limited automation |
| Label Studio | Open-source | Research and academic projects | Free and adaptable | Requires technical setup |
| LabelImg | Open-source | Basic computer vision projects | Free and beginner-friendly | Limited to bounding boxes |
| QGIS | Open-source | Environmental, urban planning, and GIS projects | Free, excellent for mapping and analysis | Steep learning curve, minimal automation |
Leverage Automation (with caution)
Automated annotation tools can speed up workflows, especially for large datasets. However, human oversight is necessary to maintain accuracy. Consider using automation for:
- Pre-labeling: Machines handle initial tagging, and humans correct errors.
- Simple Tasks: Use AI tools for repetitive tasks like bounding boxes or keyword tagging.
- Quality Assurance: Automate label reviews to flag potential errors for manual checks.
Establish a Robust Quality Control System
VentureBeat reports that 90% of data science projects don't reach production, with 87% of employees citing data quality issues. Measuring data quality is crucial before completing annotation, as labeled data directly impacts your model performance.
Maintaining accuracy at scale requires proactive measures:
| QA Technique | Description | Best Use Cases |
| Inter-Annotator Agreement (IAA) | Assign tasks to multiple annotators and compare results to identify inconsistencies. | Projects needing high consistency across annotations. |
| Sample Checks | Regularly review a subset of annotations to catch systemic issues early. | Any annotation project as part of routine QA. |
| Consensus Techniques | Use voting systems or averaging methods to finalize labels when disagreements occur. | Tasks with subjective or ambiguous data. |
| Cross-Reference QA | Multiple experts verify annotations for consensus. | Complex projects like text analysis or geospatial mapping. |
| Random Sampling | Review random annotations to ensure overall quality. | Smaller projects or as an additional quality check step. |
| Milestone Reviews | Conduct quality checks after completing project milestones to save time on corrections. | Large-scale datasets or long-term projects. |
A systematic QA process ensures high labeling quality and reduces errors:
- Step 1: Compile clear annotation guidelines and example labels as benchmarks.
- Step 2: Provide detailed training to ensure all annotators meet project expectations.
- Step 3: Start with a small dataset, review quality, and proceed if standards are met.
Poor, low-quality data annotation leads to:
- Biased Models: Training data biases cause unfair outcomes.
- Faulty Metrics: Incorrect labels skew model performance evaluations.
- Inefficient Development: Models require rework due to learning faulty patterns.
- Hindered AI Adoption: Inaccurate labels reduce trust and usability in AI systems.
Poor data labeling leads to biased AI models and flawed outcomes. To counter this, we assemble diverse annotator groups and provide clear guidelines to reduce bias. Using multiple annotators per data item helps average out individual biases, and iterative improvements further reduce bias, helping mitigate the risks of poor data labeling.

 Expert Data Scientist at Limendo GmbH
Expert Data Scientist at Limendo GmbH
Keep ML Datasets Secure
It takes an average of 50 days to discover and report a data breach, risking unauthorized access, financial losses, and reputational damage. Data privacy during labeling requires systems that prevent direct interaction with personal data.
Implement a multi-layered security approach:
- Physical Security: Secure facilities with access restrictions.
- Employee Training & Vetting: Regular training and background checks.
- Technical Security: Strong encryption, secure software, multi-factor authentication.
- Cybersecurity: Proprietary tools, penetration testing, security audits.
- Data Compliance: Follow regulations like GDPR, CCPA, and ISO 27001.
Hire Skilled Data Annotators
The repetitive nature of data labeling can lead to burnout and turnover, disrupting timelines and increasing costs. Effective hiring strategies are essential to build a resilient annotation workforce.
- Write clear job descriptions to attract qualified candidates by outlining tasks, skills, tools, and benefits.
- Post jobs on the right platforms like LinkedIn and Jooble, and set up a referral program for better leads.
- Use structured interviews to test skills, assess cultural fit, and gauge their knowledge of tools.
- Choose candidates carefully by evaluating test results, interest in data annotation, and adaptability.
- Keep annotators engaged by offering task variety, flexibility, and opportunities for career growth.
- Reward employee referrals with bonuses or extra time off to encourage quality recommendations.
Use job boards, social media, and partnerships to hire skilled annotators for consistent, high-quality data annotation.
Comprehensive training on unconscious biases, ensuring diverse annotator teams, and regular audits are key strategies in maintaining high-quality data labeling. This approach helped us achieve more balanced sentiment analysis in our customer-feedback models.
 Founder of Kixely
Founder of Kixely
Train Your Annotators

A well-trained team can dramatically improve annotation quality. Invest in:
- Comprehensive Guidelines: Provide clear examples of correct and incorrect annotations.
- Tool Training: Ensure annotators are proficient in the software they’ll use.
- Domain-Specific Training: For specialized tasks, bring in experts to train your team on complex concepts.
To ensure consistency in data labeling and reduce bias, we implement strict guidelines, conduct regular reviews, and re-train annotators. We also anonymize datasets, limit annotator hours to prevent fatigue, and provide mental health support to our team.
 CEO of Datics AI
CEO of Datics AI
Balance In-House vs. Outsourcing
In your ML project, you’ll need to choose between in-house annotation or outsourcing.
In-house annotation offers control and data security, ideal for long-term projects with large datasets but requires significant resources and may not scale well.
Outsourcing reduces management burdens, offering expert tools, flexible pricing, and scalability, making it effective for projects needing quick, cost-efficient solutions.
The best approach depends on evaluating key criteria:
| Criteria | In-House | Outsource |
| Flexibility | Suitable for simple projects needing internal control | Offers expertise and diverse datasets for complex projects |
| Control | High control over processes and data | Limited control but scalable options |
| Expertise | Requires training and hiring | Access to skilled teams immediately |
| Cost | High upfront investment | Flexible pricing based on scope |
| Pricing | High upfront costs but cost-effective for large volumes | Various pricing plans |
| Management | Requires significant management investment | Frees internal resources but requires vendor management |
| Training | Demands time and money for training | Eliminates training costs but may need additional oversight for consistency |
| Security | Offers higher data security | Requires choosing vendors with robust security measures |
| Time | Slower due to setup and training | Faster due to established infrastructure and skilled teams |
Plan for Scalability
As your projects grow, so will your annotation needs. To scale effectively:
- Use tools with bulk annotation and automation features.
- Hire additional annotators or onboard external teams.
- Build a pipeline for ongoing projects, ensuring that guidelines and workflows remain consistent.
With these strategies, you can tackle annotation challenges, save time, and produce high-quality datasets that improve your machine learning outcomes.
How to Outsource Data Annotation Tasks
Outsourcing data annotation helps manage large data volumes efficiently, providing advanced tools for task review and progress monitoring. It allows you to focus on model development while ensuring high-quality, cost-effective work through expert vendors.
While outsourcing is ideal for scalable and flexible solutions, choose vendors who prioritize data labeling security and privacy. Be prepared for potential setup time and additional oversight to maintain consistency and quality.
Benefits of Data Annotation Outsourcing
- Focus on Core Tasks: Frees data scientists to focus on model building instead of repetitive tasks.
- Guaranteed Quality and Efficiency: Experienced teams ensure high-quality annotations and timely delivery.
- Effortless Scaling: Easily scale annotation efforts without overburdening your in-house team.
Top Data Annotation Vendors in 2025
Copy this table to your notes for quick reference when researching companies:
| Company | Description |
| Label Your Data | A service company offering a free pilot. There’s no monthly commitment to data volume. Pricing calculator is on the website. |
| SuperAnnotate | A product company offering a data annotation platform. Provides a free trial and features a large marketplace of vetted annotation teams. |
| ScaleAI | A service company providing large-scale annotation solutions with flexible commitments. Offers transparent pricing options. |
| Kili Technology | A product company delivering a versatile data labeling platform. Features customizable workflows and powerful collaboration tools, with flexible pricing. |
| Sama | A service company specializing in data annotation with scalable solutions, offering flexible pricing plans and focusing on social impact. |
| Humans in the Loop | A service company providing expert annotation services for various industries. Offers flexible pricing plans and accurate, detailed annotations. |
| iMerit | A service company offering end-to-end data annotation services with a global team. Provides scalable solutions and transparent, tailored pricing. |
| CloudFactory | A service company combining scalable data labeling with flexible pricing. Offers a free pilot to evaluate services before committing. |
| Appen | A service company delivering extensive annotation services with a vast network of contributors. |
How to Choose a Data Annotation Vendor
- Expertise and Experience: Select a vendor with proven experience in your industry and relevant case studies.
- Scalability and Flexibility: Ensure they can scale as your project grows and customize services to your needs.
- Quality Control: Ask about QA processes and consider a pilot project to verify annotation quality.
- Security and Compliance: Choose a vendor with strong data security protocols and compliance with key regulations.
- Transparent Pricing: Opt for vendors with clear, upfront pricing and no hidden fees.
Focusing on these essentials ensures you find a vendor aligned with your project goals.
Use Cases of Data Annotation
Data annotation powers some of the most impactful AI applications today. It enables machine learning models to perform critical tasks across various domains.
Computer Vision

Autonomous Vehicles
Self-driving cars rely on annotated images and LiDAR data to detect pedestrians, vehicles, and road signs. Each label ensures the model can make safe, split-second decisions on the road.
Healthcare Imaging
Medical imaging systems use annotated X-rays, CT scans, and MRIs to identify diseases like cancer or fractures. This supports faster and more accurate diagnostics.
Retail Analytics
In retail, image annotation tracks product placement and shopper behavior. For example, video data from store cameras can identify popular aisles or optimize shelf organization.
Natural Language Processing (NLP)

Chatbots and Virtual Assistants
Text annotation helps train chatbots to understand user intent and provide accurate responses. Speech data annotations further enhance voice assistant capabilities.
Sentiment Analysis
Companies analyze customer feedback by tagging reviews and social media comments with positive, negative, or neutral sentiments.
Search Relevance
Annotated keywords and phrases refine search engine results, improving relevance and user satisfaction.
Audio Processing

Speech Recognition
Training speech-to-text models requires annotated transcripts. These AI sound recognition systems power applications like virtual assistants and dictation software.
Emotion Detection
Annotating tone and mood in audio recordings helps models analyze speaker emotions, aiding customer service or mental health applications through AI in emotion recognition.
Language Translation
Multilingual datasets labeled with audio-to-text transcriptions improve AI-based translation tools.
3D Applications

Robotics
Annotated 3D data enables robots to understand spatial environments, helping them navigate warehouses, hospitals, or factories.
Urban Planning
Geospatial data annotation supports infrastructure development and traffic management, optimizing city layouts and resource allocation.
These use cases demonstrate how data annotation enables AI systems to solve real-world problems.
Industries Leveraging Data Annotation
Data annotation helps organizations implement AI solutions that drive efficiency, innovation, and decision-making. Here’s how different sectors are utilizing annotated data:
Automotive
- Autonomous Vehicles: Models rely on annotated images, videos, and LiDAR data to detect objects, understand traffic signals, and ensure safe navigation.
- Driver Assistance Systems: Data annotation supports advanced features like lane departure warnings and collision detection.
Healthcare
- Medical Imaging: Annotated scans, such as X-rays and MRIs, help detect conditions like tumors or fractures, supporting diagnostic accuracy.
- Predictive Care Models: Labeled datasets aid in identifying patient risks, enabling personalized treatment plans.
Retail and E-Commerce
- Visual Search Engines: Annotating product images allows users to search by photos rather than text.
- Product Categorization: Labeled data ensures accurate sorting and tagging of inventory for better search and recommendations.
- Customer Sentiment Analysis: Annotated reviews and social media data reveal trends and customer preferences.
Finance
- Fraud Detection: Annotating transaction data enables AI systems to identify unusual patterns and flag potential fraud.
- Risk Assessment: Models trained on labeled data can evaluate financial risks for investments or loans.
- Trading Algorithms: Annotated datasets improve predictive models for stock and currency trading.
Agriculture
- Crop Monitoring: Annotated drone images help track crop health and growth.
- Disease Detection: Labeled datasets assist in identifying plant diseases early, preventing large-scale losses.
- Soil Analysis: Annotated geospatial data enables precise irrigation and fertilization planning.
Energy
- Fault Detection: Annotating images or videos from pipelines and equipment helps detect and address potential issues quickly.
- Risk Analysis: Geospatial annotations support better planning for natural disaster mitigation.
- Renewable Energy Optimization: Labeled data enables efficient placement and monitoring of solar panels and wind turbines.
These industries highlight the versatility of data annotation and its role in creating powerful AI solutions tailored to specific challenges.
Future Trends in Data Annotation
The field of data annotation is evolving rapidly. Emerging technologies and practices are reshaping how datasets are prepared for machine learning.
Here are the key trends to watch:
Large Language Models (LLMs) for Automation
LLMs like GPT-4 are now being used to pre-annotate text and generate initial labels for large datasets. While tasks like ChatGPT data annotation speeds up the process, human oversight is still necessary to refine and validate the outputs.
Applications:
- Pre-labeling named entities in text for faster NLP training.
- Suggesting sentiment tags for customer feedback datasets.
- Auto-generating captions for image datasets.
Synthetic Data Generation
Synthetic data is being used to supplement real-world datasets. By creating simulated data, organizations can save time and resources while addressing data scarcity in specific use cases.
Advantages:
- Provides controlled environments for training.
- Eliminates privacy concerns with sensitive datasets.
- Reduces dependency on manual annotation.
Reinforcement Learning with Human Feedback (RLHF)
RLHF combines automated annotations with human guidance to refine model performance. Annotators provide feedback on model-generated labels, improving quality over time.
Use Cases:
- Enhancing conversational AI systems by refining intent recognition.
- Improving recommendation engines with feedback-driven training loops.
Domain-Specific Annotation
Specialized industries like healthcare and legal services are demanding tailored annotation techniques. This trend involves integrating domain expertise directly into the annotation workflow.
Examples:
- Annotators with medical backgrounds labeling complex imaging datasets.
- Legal professionals annotating contracts for AI-based compliance monitoring.
Real-Time Data Annotation
As industries adopt real-time AI systems, on-the-fly annotation is gaining traction. This involves annotating live streams of data, such as video feeds or social media posts, in real time.
Applications:
- Autonomous vehicles updating object detection models in real-world scenarios.
- Social media platforms tagging harmful content instantly.
These trends are making data annotation faster, smarter, and more scalable while addressing emerging challenges in AI development.
Our Approach to Data Annotation: Real-World Cases
We at Label Your Data have helped clients across industries solve complex challenges with precise data annotation services.
Image Annotation for Drone Navigation
A military client needed labeled aerial images to improve drone navigation in difficult terrains. We provided bounding boxes and segmentation annotations to map terrain and identify obstacles. The improved navigation algorithms enhanced the drones’ operational efficiency in critical missions.
Video Annotation for Artillery Precision
To refine artillery fire correction, a defense project required annotated drone video footage. The Label Your Data team labeled frames to track movements and analyze trajectories. This resulted in significantly more accurate targeting, improving operational success.
Audio Annotation for Acoustic Target Detection
An acoustic detection system relied on labeled audio to identify air targets. Label Your Data manually annotated hundreds of hours of audio data, categorizing essential sound patterns. The annotated datasets boosted the detection system’s accuracy and reliability in the field.
Remote Sensing for Environmental Research
PhD students from Yale and Paris needed validated remote sensing models to detect landfills. Our experts conducted cross-referencing and QA to fine-tune these models. The enhanced models contributed to more precise satellite data analysis for global waste management initiatives.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is data annotation?
Data annotation is the process of labeling raw data like text, images, or audio to make it understandable for machine learning models. It’s how AI systems learn to recognize patterns and make predictions.
Can anyone do data annotation?
While anyone can learn data annotation, it requires attention to detail, patience, and sometimes domain-specific knowledge, especially for complex tasks like medical or legal annotations.
What is annotation with example?
Annotation is adding labels or tags to data. For example, in image annotation, a photo of a street might be labeled to identify cars, pedestrians, and traffic signs for a self-driving car project.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.