In-Context Learning: Enhancing Model Performance

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- How to Use In-Context Learning for Seamless Task Shifting in LLMs
- Comparing In-Context Learning with Fine-Tuning and Pre-Training
- Key Applications of In-Context Learning
- Limitations of In-Context Learning
- Techniques to Improve In-Context Learning
- Metrics for Evaluating In-Context Learning
- About Label Your Data
- FAQ

TL;DR
- In-context learning enables real-time task adaptation without changing internal parameters, unlike fine-tuning and pre-training.
- It is ideal for industries requiring immediate task switching, but limited by context size, memory consumption, and generalization challenges.
- Strategies like prompt optimization, tuning, and memory augmentation improve scalability and performance on complex tasks.
- Effectiveness is measured by task-specific accuracy, latency, computational cost, and adaptation speed.
How to Use In-Context Learning for Seamless Task Shifting in LLMs
In-context learning is a powerful method that helps large language models (LLMs) improve their performance on the fly. Unlike traditional methods like fine-tuning or pre-training, in-context learning allows models to adapt to new tasks and data in real time, all without changing their internal parameters.
Key Concept of In-Context Learning
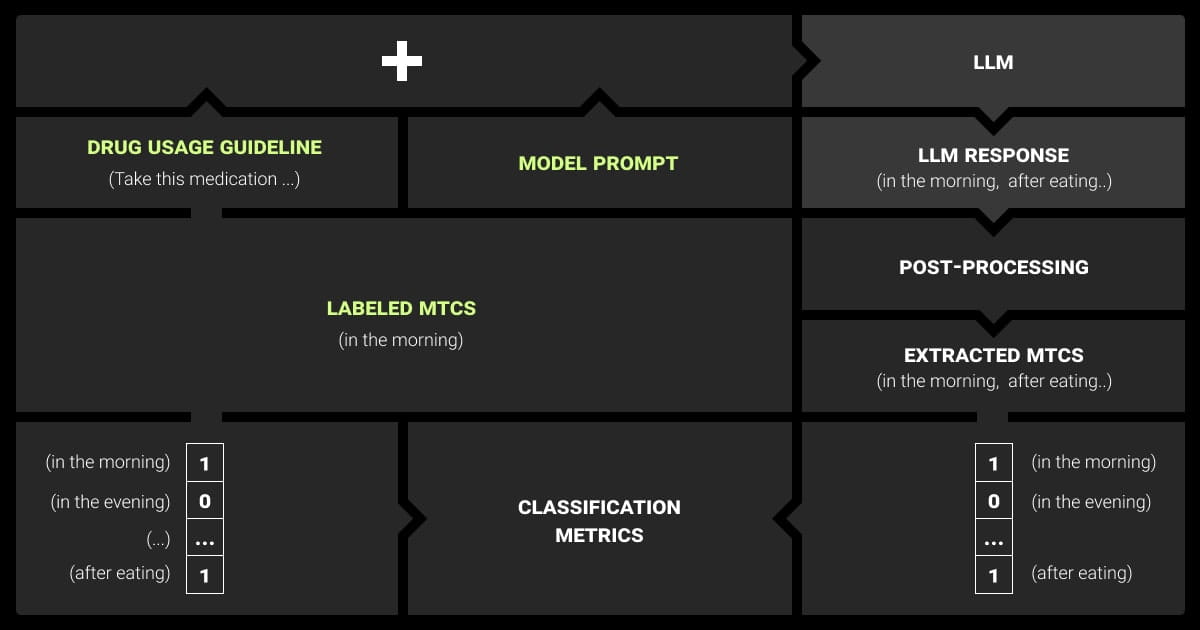
In-context learning enables models to perform tasks using examples provided directly in the input, without updating their internal weights. Instead of adjusting parameters like in fine-tuning, the model remains fixed and learns from the information within the context window. Essentially, the model “learns” from the input in real time, allowing it to switch between tasks without needing retraining.
The Role of Prompt Engineering
Prompt engineering is vital for guiding the model's performance in in-context learning. The quality and structure of the prompt directly affect the model's ability to generate accurate outputs. Well-designed prompts help the model understand and execute tasks effectively.
Providing clear, well-structured examples in the prompt is essential to guiding the model toward relevant results while avoiding ambiguity; prompts should strike a balance between specificity to define the task and generality to allow broader application.
How In-Context Learning Works
In-context learning processes input within a limited context window, where the model temporarily stores recent inputs. Tokenization breaks the inputs into patterns, which the model uses to generate outputs without updating its weights. The quality of the results depends on both the prompt structure and the tokens processed within the context window.
Comparing In-Context Learning with Fine-Tuning and Pre-Training

LLM fine-tuning involves updating model parameters using task-specific data, which requires significant resources and time. Pre-training gives the model a general understanding of language but may still need fine-tuning for specific tasks.
In contrast, contextual learning allows models to adapt in real time using examples in the prompt, without changing model weights. It's quicker and more flexible but limited by the size of the context window and the quality of the prompt. Fine-tuning and pre-training offer more permanent improvements for specific tasks.
Memory-Based vs. Parameter-Based Learning
| Method | Key Characteristics | Advantages | Disadvantages |
| Fine-Tuning | Adjusts model parameters with additional training | High task-specific accuracy | Requires more compute resources and retraining |
| Pre-Training | Initial training on large datasets | Provides general knowledge for many tasks | May not perform well on specific tasks |
| In-Context Learning | Uses examples in the input without changing parameters | Adaptable and lightweight; no retraining needed | Limited by context window size; may struggle with complex tasks |
Scalability and Adaptability
Pre-training requires massive datasets and significant computational resources upfront to create general-purpose models, while fine-tuning is resource-intensive for each specific task, needing additional data and training time. In contrast, in-context learning scales efficiently by adapting to new tasks through input prompts without requiring retraining, which reduces computational demands. Its adaptability allows models to adjust to new tasks in real time, further lowering the need for extensive resources.
Key Applications of In-Context Learning
In-context learning has proven to be highly versatile across various industries and use cases. Its ability to adapt to new tasks without retraining makes it ideal for dynamic environments requiring real-time task switching and rapid updates.
Moreover, data annotation plays a crucial role in the effectiveness of in-context learning. Thus, data annotation in manufacturing or in any other industry is essential for improving model accuracy and performance.
Real-Time Adaptation in Conversational Agents
In customer service, conversational agents need to quickly adapt to user preferences and changing contexts. Traditional models require retraining, which is slow and resource-intensive. In-context learning allows models to adjust instantly based on input prompts, delivering personalized, context-aware responses without retraining.
Dynamic Knowledge Updates in LLMs
LLMs need to handle constantly changing information, such as financial data or breaking news. Traditional models rely on periodic retraining, which is inefficient. In-context learning allows LLMs to update their outputs dynamically using real-time inputs, offering timely responses without retraining.
Multitask Performance Across Domains
Most models struggle with performing diverse tasks in a single session. In-context learning enables seamless switching between tasks, like summarization and sentiment analysis, using different prompts in the same context window. This flexibility extends to areas like object detection and AI image recognition, allowing models to adapt without additional training.
Limitations of In-Context Learning
While in context learning offers significant advantages in flexibility and real-time adaptability, it also has limitations that affect its scalability and performance in complex tasks.
Context Window Size
One major limitation is the size of the context window. This window determines how much information the model can process at once. Small context windows, like 512 tokens, limit the amount of data that can be used for complex tasks or multi-step reasoning. Larger context windows are needed for the model to handle more sophisticated queries and maintain continuity.
Balancing context size is crucial for achieving both accuracy and speed in real-time applications. Instead of increasing the context, a context-prioritization algorithm could help dynamically adjust the context length based on task complexity, optimizing both performance and response time.

 CEO, Swapped
CEO, Swapped
Memory Overhead and Efficiency
In-context learning requires maintaining an internal memory of recent inputs, which can lead to high memory consumption, especially with larger context windows. This increases memory overhead and can slow down performance, particularly when processing long sequences or complex tasks, resulting in higher computational costs and longer processing times.
Generalization
While effective for immediate tasks, in-context learning often struggles with generalizing to broader or more complex tasks. Over-reliance on specific examples can limit adaptability, as the model may fail to apply learned patterns to tasks outside the prompt's range.
Techniques to Improve In-Context Learning

To maximize the effectiveness of in-context learning, several strategies can be applied to fine-tune model behavior. By refining prompts, using templates, and employing memory augmentation techniques, models can better generalize across tasks and perform better in complex environments.
High-quality, annotated datasets can enhance the content of prompts. For example, in sentiment analysis, annotated texts provide reliable guidance for the model, improving its ability to generalize across different inputs.
Prompt Optimization
Optimizing the structure and content of the prompt is essential for improving how models interpret and execute tasks. The arrangement of tokens within a prompt can significantly influence a model's ability to generalize and adapt to new inputs.
- Token structure. Strategic placement of tokens in prompts can guide the model to recognize key task elements, improving its generalization to similar, unseen tasks.
- Diverse examples. Using a variety of representative examples helps the model handle a wider range of tasks, enhancing adaptability.
Prompt Tuning and Template Engineering
Another way to enhance in-context learning is through prompt tuning, where prompts are optimized for consistent performance across different inputs. By refining task-specific templates, you can guide the model step by step, improving reliability for varied or complex tasks.
- Template engineering. Creating templates that include multiple layers of examples enables the model to follow clear steps, especially for complex tasks requiring sequential processing.
- Prompt tuning. Tailored prompts can ensure more consistent and accurate outputs across various tasks by removing ambiguities and highlighting important instructions.
For example, in a summarization task, instead of a generic prompt, a tuned template might specify different summary lengths or focus points, such as the main argument or specific details.
Memory Augmentation
Memory augmentation enhances the model’s ability to handle complex tasks that require large amounts of information. Techniques like chaining prompts and retrieval-augmented generation (RAG) extend the model’s capacity by breaking down tasks or retrieving external data to include in the context window.
- Chaining prompts. Breaking large tasks into smaller, sequential prompts that fit within the model's context window allows the model to process tasks step by step without exceeding memory limits.
- Retrieval-Augmented Generation (RAG): RAG LLM augments in-context learning by retrieving relevant information from external sources, helping the model incorporate data that would otherwise exceed its context window.
For instance, when summarizing a lengthy report, chaining prompts lets the model summarize each section separately and then combine them. RAG can pull in external data to enrich the summary with more context.
Increasing the context size in in-context learning models improves response accuracy by incorporating more information, but it also demands more memory and processing power. This trade-off can result in slower inference times, higher costs, and latency issues, especially in real-time applications. Balancing context size with computational efficiency is crucial to maintaining performance without compromising user experience.
 CEO, Software House
CEO, Software House
Metrics for Evaluating In-Context Learning
Several key metrics evaluate the performance of in-context learning, focusing on task accuracy, efficiency, and adaptability.
- Task-specific accuracy. Measures how well the model performs on individual tasks, including precision, recall, and its ability to switch seamlessly between tasks like classification and sentiment analysis.
- Latency and computational cost. Evaluates the model's response time and resource consumption, comparing the efficiency of in-context learning with traditional fine-tuning methods.
- Adaptation speed. Assesses how quickly the model adjusts to new tasks using prompt examples, with benchmarks to measure performance in unfamiliar scenarios, including few-shot or zero-shot learning.
In-context learning provides a lightweight, adaptable solution for enhancing model performance in real-time tasks. With its ability to handle multiple tasks on the fly, it is becoming a key strategy for AI-driven innovation.
Fine-tuning solutions can greatly improve your LLM's ability to adapt to specific tasks, ensuring higher accuracy and performance.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is an example of in-context learning?
An example of in-context learning is when a language model translates a sentence and then summarizes a text within the same session, based on examples provided in the prompt. The model adapts to each task in real time without needing any retraining or parameter updates.
What is in context learning in GPT?
In-context learning in GPT refers to the model's ability to perform tasks based on examples provided within the input prompt, without updating its internal parameters. It adapts dynamically to new tasks by interpreting the context rather than retraining or fine-tuning.
Is in context learning the same as prompt engineering?
In-context learning and prompt engineering are related but not the same. In-context learning allows the model to adapt to tasks based on examples within the input, while prompt engineering focuses on crafting those prompts to effectively guide the model’s behavior.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.