LLM Fine Tuning: The Guide for ML Teams

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- When to Use LLM Fine-Tuning
- Preparing for LLM Fine-Tuning
- Step-by-Step LLM Fine-Tuning Process
- LLM Fine-Tuning Techniques and Strategies
- Advanced LLM Fine-Tuning: Techniques for Limited Resources and Specialized Tasks
- Monitoring and Evaluating Fine-Tuned Large Language Models
- Current Trends and Future Predictions for LLM Fine-Tuning
- About Label Your Data
- FAQ

TL;DR
- Fine-tune models for domain-specific applications, task-specific performance, custom business solutions, or to optimize resource usage.
- Choose the right LLM model based on size, architecture, and pre-trained data for your task.
- Start with well-prepared data, carefully select a model, and fine-tune it with the correct hyperparameters to maximize performance.
- Implement supervised or self-supervised fine-tuning and use transfer learning to adapt LLMs for domain-specific tasks.
- Use advanced techniques like LoRA and PEFT to fine-tune LLMs with limited resources or for specialized tasks.
- Continuously monitor performance to prevent degradation and ensure scalability.
- Stay up-to-date with emerging techniques like zero-shot learning and AutoML to optimize fine-tuning workflows.
When to Use LLM Fine-Tuning
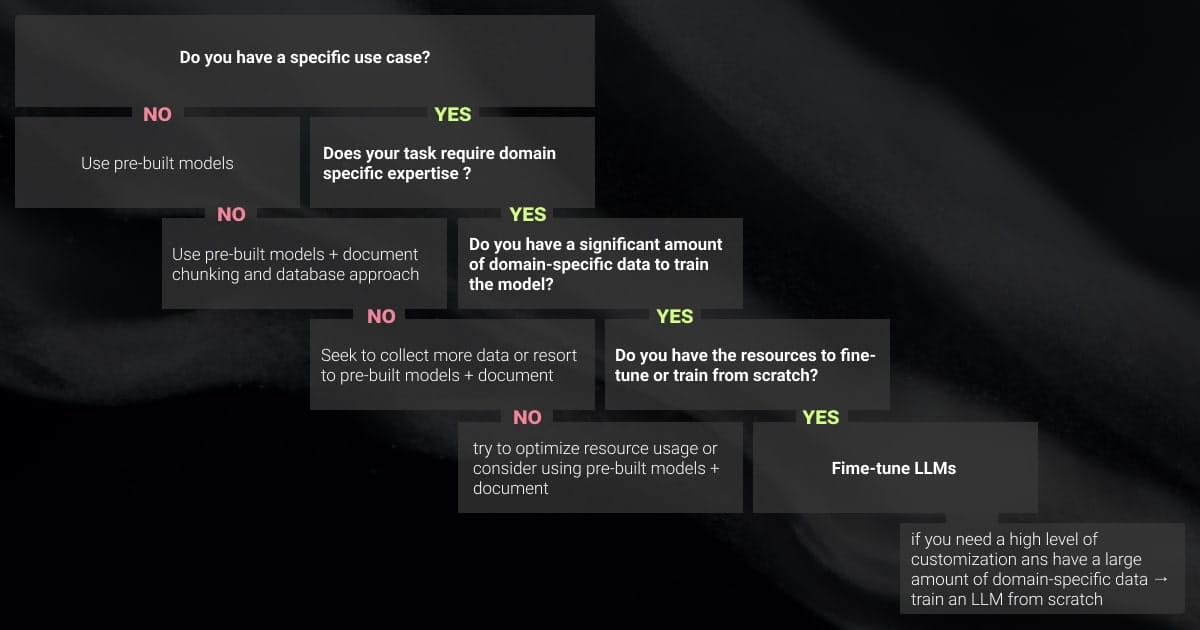
LLM fine-tuning enables ML teams to tailor their models to specific needs. While general-purpose LLMs offer broad capabilities, fine-tuning refines these models for particular domains, tasks, or business requirements, providing enhanced accuracy and relevance.
Understanding when and how to apply LLM fine-tuning is crucial for maximizing the potential of your LLMs. Below, we explore key scenarios where fine-tuning becomes essential.
Domain-Specific Applications
One of the reasons to fine-tune an LLM is when working with specialized fields such as healthcare, legal, or finance. These domains often involve highly specific language, terminology, and contextual nuances that a general-purpose model might not fully capture.
By fine-tuning an LLM on domain-specific data, you can significantly improve the model’s accuracy and relevance. For example, GPT-4 was trained on approximately 45 terabytes of text data, ensuring it captures extensive language details. This process allows the model to better understand and respond to the intricacies of the field, making it a valuable tool for professionals who rely on precise and contextually aware outputs.
Task-Specific Performance Enhancement
For tasks requiring high precision, such as sentiment analysis, entity recognition, or LLM data labeling, fine-tuning is crucial. While general models perform reasonably well across various tasks, they may fall short when higher accuracy is needed for specific applications.
LLM fine-tuning optimizes the model for particular tasks, resulting in better performance. For instance, GPT-4 demonstrated human-level performance in professional exams, outperforming 90% of law students on the bar exam.
Custom Business Solutions
Businesses often have unique operational needs, data, and communication styles that aren’t fully addressed by generic LLMs. Fine-tuning enables companies to align models with their specific business data, tone, and goals. This customization is particularly important for applications like customer service chatbots, automated reporting, or any solution where the model must adhere to a particular brand voice or operational directive.
By fine-tuning an LLM to match the specific requirements of a business, organizations can ensure that their AI-driven interactions are more effective, consistent, and aligned with their brand identity. This tailored approach improves the quality of the LLM’s output and enhances customer satisfaction and operational efficiency.
Resource Optimization
In environments with limited computational resources, fine-tuning allows optimizing LLMs for efficiency without compromising performance. LLMs have grown significantly in size, with GPT-3 reaching 175 billion parameters and costing an estimated $8 million to train. Deploying these large models in resource-constrained environments can be challenging.
Fine-tuning a model to focus on the most relevant data and tasks helps reduce the computational load, enabling the deployment of sophisticated AI in resource-constrained environments. This optimization ensures the model delivers high-quality results while operating within the available hardware or budgetary constraints.
Beyond Prompt Engineering
Prompt engineering is often the first step in optimizing the performance of an LLM. It's quick and can yield immediate improvements for general tasks. However, it can only go so far, especially when dealing with highly specialized tasks or contexts.
Conversely, fine-tuning involves retraining the LLM on a curated dataset that aligns with the desired application. This process not only enhances the model’s understanding of the specific language or terminology used in the task but also improves its ability to perform consistently across different task variations.
The computation used for training LLMs has increased by over 574,000% in the last three years, underscoring the importance of focusing on the most relevant data for efficiency.
Get more accurate, domain-specific outputs with our LLM fine-tuning services.
Preparing for LLM Fine-Tuning
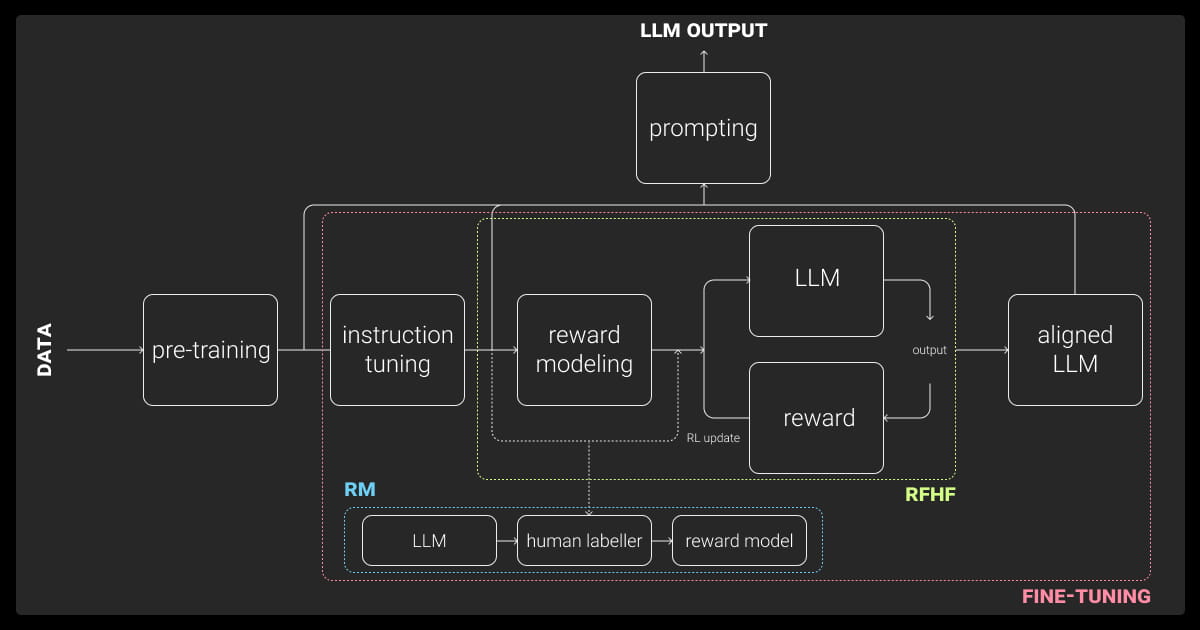
When fine-tuning a large language model, meticulous preparation is crucial for achieving optimal results.
Choosing the Right LLM
Selecting the appropriate LLM for fine-tuning is a critical decision that impacts the effectiveness and efficiency of your project. Here are some factors to consider when selecting between different types of LLMs:
- Model Size. Larger models, such as GPT-4, typically have higher performance capabilities due to their extensive parameters. But they also require more computational resources. Smaller models like LLaMA might be more efficient for specific tasks, especially with limited resources.
- Architecture. Different LLMs come with varying architectures. For instance, models like GPT-4 and PaLM 2 are based on Transformer architectures, which are highly versatile and practical for many tasks. Understanding the underlying architecture can help you choose a model that aligns with your needs.
- Pre-trained Data. The quality and diversity of the data on which the LLM was pre-trained significantly influence its performance. Models trained on more diverse datasets tend to generalize better across different tasks. Reviewing the pre-training data sources can provide insights into the model's strengths and limitations.
Comparing Popular LLMs in 2024
| Model | Developer | Max Tokens | Primary Use Cases | Key Strengths | Weaknesses |
| GPT-4 | OpenAI | 8,000 to 128,000 | Text generation, NLP tasks, code generation, chatbots | Strong reasoning, creativity, few-shot learning | Expensive, requires substantial compute |
| LLaMA 3 | Meta | 65,000 | Research, multilingual applications, text summarization | Open-source, efficient on smaller hardware | Still less powerful than GPT-4 in general tasks |
| Claude 2 | Anthropic | 100,000 | Conversational agents, summarization, code writing | Safety-oriented, large context window | Limited fine-tuning capabilities |
| PaLM 2 | 1,000,000 | Language translation, code generation, knowledge extraction | Scalable, excels in multilingual settings | Fewer open-source options for customization | |
| Mistral | Mistral AI | 128,000 | Open-source NLP tasks, domain-specific fine-tuning | Lightweight, highly optimized for performance | Limited community support compared to larger players |
| Command R | Cohere | 16,000 | NLP tasks, retrieval-augmented generation (RAG) | Retrieval-augmented, optimized for information extraction | Smaller context window than competitors |
Data Collection and Preprocessing
High-quality data is the foundation of successful LLM fine-tuning. Here are best practices to ensure your data is ready for the task:
- Data Collection: Gather diverse and representative datasets that cover the scope of your intended application. The quality of your data directly influences the model’s performance, so prioritize sources that are accurate, up-to-date, and relevant.
- Data Curation: Select the most pertinent examples from your collection. This step reduces noise and focuses the model’s learning on valuable patterns.
- Cleaning and Preprocessing:
- Tokenization: Convert text into tokens, the basic input units for LLMs. Ensure that your tokenization process aligns with the model’s requirements.
- Handling Noisy Data: Identify and remove irrelevant or incorrect data to prevent the model from learning incorrect patterns. Use techniques such as outlier detection and normalization.
- Ethical Considerations:
- Bias: Strive to collect data that is as unbiased as possible to prevent the model from perpetuating harmful stereotypes or inaccuracies.
- Privacy: Ensure that the data you collect complies with privacy regulations and does not contain sensitive information unless adequately anonymized.
Hardware and Infrastructure Considerations
LLM fine-tuning requires significant computational resources, so plan your hardware and infrastructure setup carefully to ensure adequate performance and cost efficiency.
- Computational Resources:
- GPUs vs. TPUs: GPUs are widely used for LLM fine-tuning, but TPUs, designed specifically for TensorFlow, might offer better performance for certain tasks. Evaluate your model’s compatibility with these processors to make an informed decision.
- Cloud vs. On-Premise: Cloud services offer flexibility and scalability, making them ideal for large-scale projects. On-premise setups might be more cost-effective in the long run but require a substantial upfront investment in hardware.
- Budget Considerations: Fine-tuning large models can be expensive. Optimize costs by choosing suitable cloud instance types, using spot instances, and scheduling training during off-peak hours to take advantage of lower rates.
- Environment Setup:
- Software and Libraries: Ensure that your environment includes the necessary software and libraries, such as PyTorch or TensorFlow, depending on the LLM you’re working with.
- Tools: Tools like Docker can help you create a reproducible environment, while MLflow can be useful for tracking experiments and managing models.
By carefully considering these aspects, you can set up a robust and efficient workflow for fine-tuning your chosen LLM.
Step-by-Step LLM Fine-Tuning Process
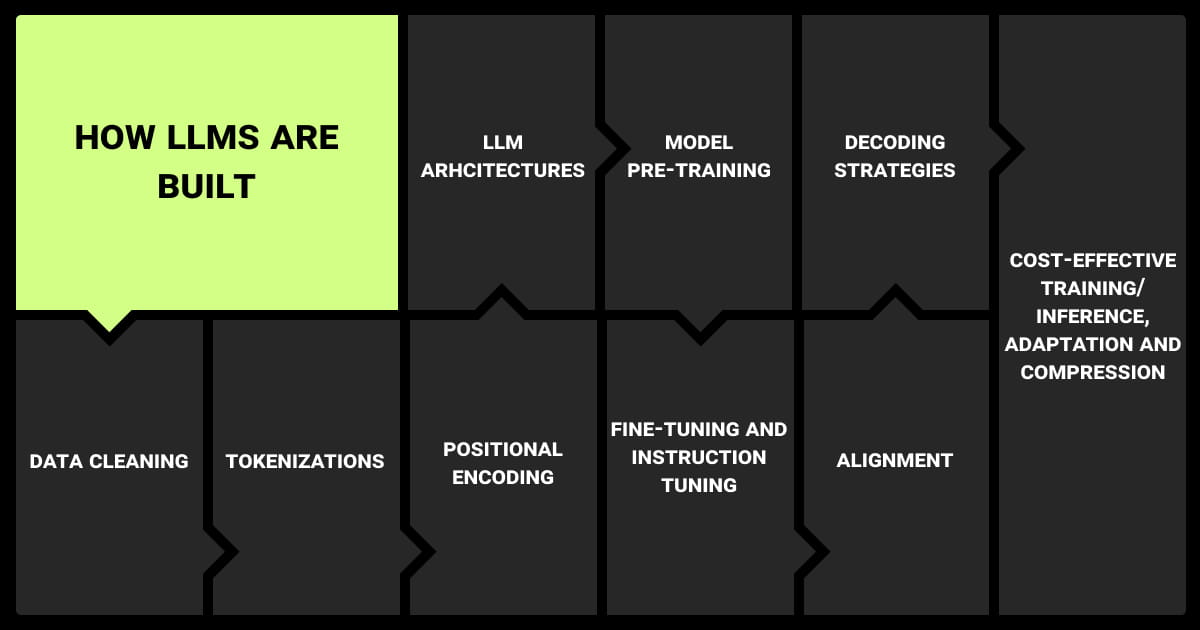
Fine-tuning a pre-trained model to tailor it to a specific task is a critical phase in ML workflows, particularly when working with large language models. Here are the main steps to take using various LLM fine-tuning tools:
1. Data Preparation
Before fine-tuning, curate and preprocess your dataset to ensure it aligns with the task at hand. Data should be tokenized according to the pre-trained model’s tokenizer for consistency in input formatting. Balancing the dataset and augmenting it if necessary can significantly impact the model’s performance.
2. Model Selection and Initialization
Select a base pre-trained model that closely aligns with your target task. For instance, if working with text classification, a model like BERT or RoBERTa might be appropriate. Initialize the model using frameworks such as Hugging Face Transformers or PyTorch Lightning, which offer robust APIs for loading and configuring pre-trained models.
3. Fine-Tuning
Fine-tuning typically involves training the model on your task-specific dataset, adjusting the learning rate, batch size, and other hyperparameters to avoid overfitting while maximizing generalization. Frameworks like Hugging Face Transformers simplify this process with built-in functions for training and evaluation. PyTorch Lightning’s training loop is more customizable, allowing for greater flexibility in handling complex fine-tuning scenarios.
4. Evaluation and Hyperparameter Tuning
After initial training, evaluate the model using appropriate metrics, such as accuracy, F1 score, or perplexity, depending on the task. This step might involve iterative hyperparameter tuning, where you experiment with different settings to improve performance. Automated tools like Optuna can be beneficial for hyperparameter optimization in this context.
5. Deployment
The final step is deployment once fine-tuning is complete and the model meets the desired performance criteria. Export the fine-tuned model for inference using formats like ONNX for cross-platform compatibility. Hugging Face’s Model Hub or TensorFlow Serving are standard deployment options, depending on your infrastructure.
LLM Fine-Tuning Techniques and Strategies
LLM fine-tuning methods are critical for adapting these models to specific tasks or domains. Given their vast number of parameters, fine-tuning requires careful planning and execution to achieve optimal performance without overfitting or degrading the model’s generalization capabilities.
Supervised Fine-Tuning

Supervised fine-tuning involves training the LLM on a labeled dataset with explicitly provided input-output pairs. This process typically requires the following steps:
- Data Preparation: Curate a labeled dataset that aligns closely with the target task. Preprocess the data to ensure it is in a format compatible with the LLM.
- Model Initialization: Start with a pre-trained LLM. This initialization provides a strong baseline, as the model already possesses significant general knowledge.
- Training: Fine-tune the LLM using the labeled dataset. Key considerations during training include selecting an appropriate learning rate, batch size, and training duration. Monitoring training loss and validation metrics is crucial for avoiding overfitting.
- Evaluation: After training, evaluate the fine-tuned model on a held-out validation set to assess its performance. Compare it with a baseline model to ensure that fine-tuning has improved the desired metrics.
Unsupervised and Self-Supervised Fine-Tuning
Unsupervised fine-tuning does not rely on labeled data but instead leverages large amounts of unlabeled text. Self-supervised fine-tuning is a subset of this approach where the model generates labels from the data itself, such as predicting the next word in a sequence (language modeling) or filling in masked tokens.
Use cases for unsupervised and self-supervised methods:
- Domain Adaptation: Fine-tune an LLM on domain-specific corpora (e.g., medical literature) using unsupervised objectives like masked language modeling. This allows the model to better understand the nuances of the target domain.
- Task-Specific Pre-Training: Self-supervised techniques can be used to pre-train models on related tasks before fine-tuning them on the target task. For example, a model pre-trained on a large news corpus using masked language modeling may perform better when later fine-tuned for news headline generation.
Transfer Learning and Domain Adaptation

Transfer learning leverages a model pre-trained on a large, diverse dataset and fine-tunes it on a smaller, domain-specific dataset. This approach is particularly effective when the target domain lacks sufficient labeled data.
Techniques for adapting LLMs to specific domains:
- Domain-Adaptive Pretraining (DAPT): Further pre-train the LLM on a large corpus from the target domain before fine-tuning it on the specific task. This enhances the model’s understanding of domain-specific language.
- Task-Adaptive Pretraining (TAPT): Similar to DAPT, but focuses on the type of tasks the model will perform. For example, pre-training a model on question-answering datasets before fine-tuning it on a specific QA task.
Hyperparameter Optimization
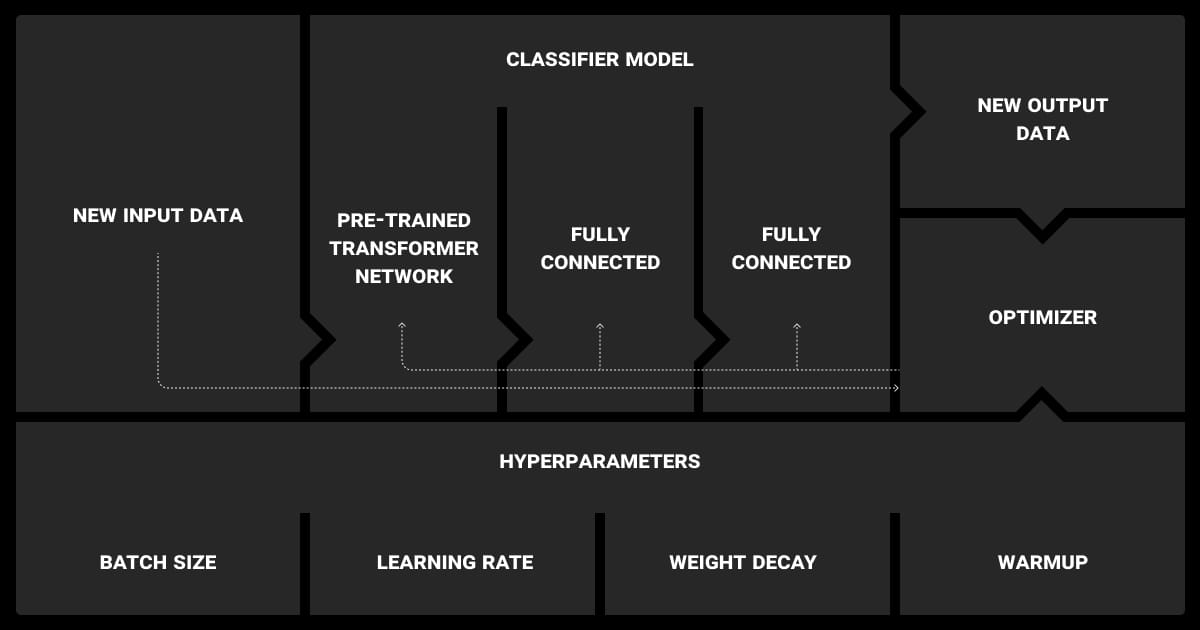
LLM fine-tuning involves tuning various hyperparameters to optimize performance. Key hyperparameters include:
- Learning Rate: The rate at which the model’s parameters are updated. A lower learning rate is generally preferred to avoid catastrophic forgetting of pre-trained knowledge.
- Batch Size: The number of samples processed before the model’s weights are updated. Larger batch sizes can stabilize training but require more memory.
- Epochs: The number of complete passes through the training dataset. More epochs can lead to better performance but increase the risk of overfitting.
Top Tools for Hyperparameter Optimization
| Tool | Optimization Methods | Primary Features | Key Strengths | Limitations |
| Optuna | Bayesian, Tree-structured Parzen Estimator (TPE) | Pruning, distributed optimization, easy integration with ML frameworks | Efficient pruning, highly scalable | Requires tuning for large-scale tasks |
| Ray Tune | Bayesian, Hyperband, ASHA, PBT | Scalable, supports multiple algorithms, cloud-friendly | Scalability, multi-framework support | Can be complex for smaller tasks |
| Hyperopt | Random Search, TPE | Low resource consumption, easy to use | Lightweight, efficient for smaller models | Limited support for complex workflows |
| Weights & Biases (W&B) | Bayesian, Grid, Random | Seamless tracking and visualization of experiments, cloud integration | Excellent UI, collaboration features | Requires external compute resources |
| SigOpt | Bayesian, Random Search | Multi-metric optimization, black-box optimization | Easy integration, robust support | Limited free tier |
| Keras Tuner | Bayesian, Hyperband, Random | Simple API, integrates well with TensorFlow and Keras | User-friendly, built for TensorFlow | Limited outside TensorFlow ecosystem |
| SMAC3 | Sequential Model-based Global Optimization (SMBO) | Flexible configuration space, multi-objective optimization | Strong theoretical foundations | Steeper learning curve for beginners |
| Scikit-Optimize | Bayesian, Random Search | Easy to use with scikit-learn models, simple interface | Lightweight, integrates well with scikit-learn | Not as feature-rich as some competitors |
Regularization Techniques
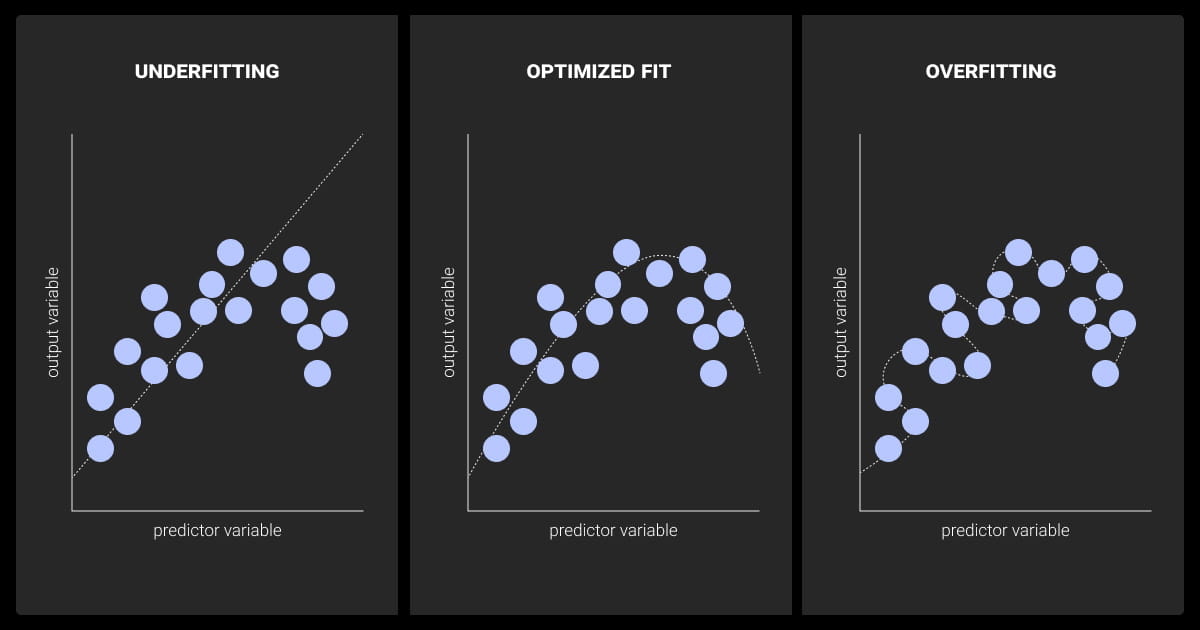
Regularization is essential in LLM fine-tuning to prevent overfitting, especially when working with small datasets. Common techniques include:
- Dropout: Randomly sets a fraction of input units to zero during training, which prevents the model from relying too heavily on specific neurons.
- Weight Decay: Adds a penalty to the loss function based on the magnitude of the model weights, encouraging the model to keep weights small and reducing the risk of overfitting.
When combined with proper hyperparameter tuning, regularization techniques can significantly enhance the robustness and generalization capability of fine-tuned LLMs. This ensures they perform well not just on training data but also on unseen, real-world data.
Accelerate your LLM projects with our top-notch data annotation services.
Advanced LLM Fine-Tuning: Techniques for Limited Resources and Specialized Tasks
As the deployment of LLMs continues to expand across various industries, the need for efficient and specialized fine-tuning methods has become crucial.
Let’s analyze the advanced techniques that allow ML teams to fine-tune LLMs more effectively, even with limited computational resources or for highly specialized tasks.
LLM Fine-Tuning with Low-Rank Adaptation (LoRA)
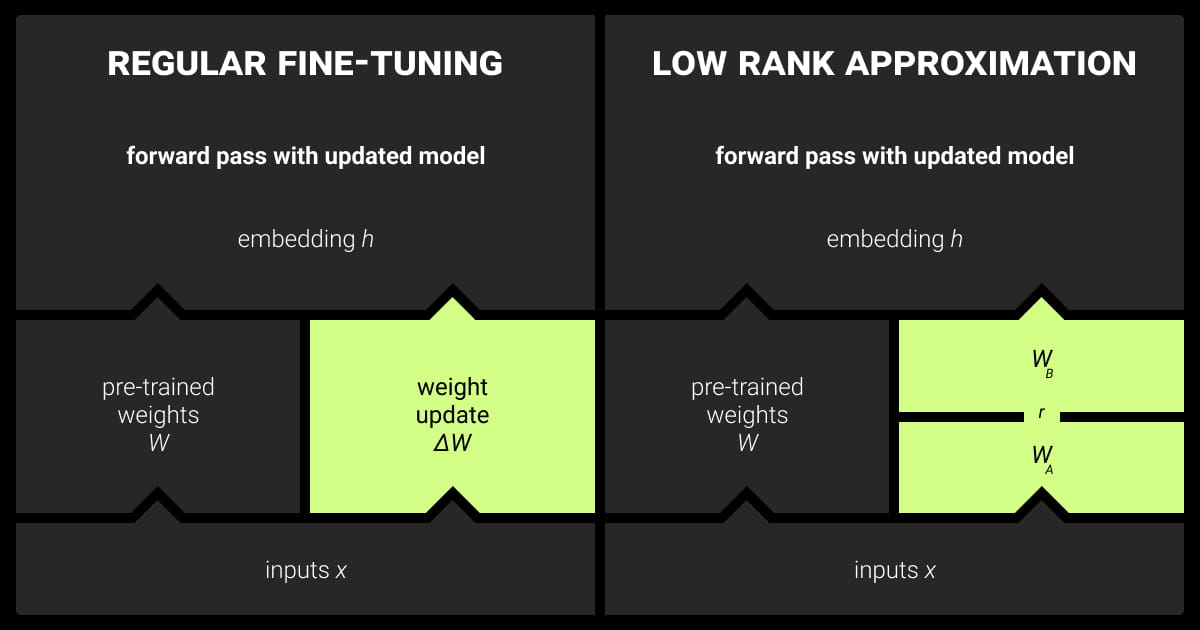
Low-Rank Adaptation (LoRA) is a fine-tuning technique for addressing the high computational and memory costs of adapting LLMs. LoRA works by decomposing the weight matrices of the model into low-rank matrices. This approach significantly reduces the number of trainable parameters, enabling efficient LLM fine-tuning on resource-constrained hardware.
Advantages of LoRA
- Resource Efficiency: By reducing the number of parameters that need to be updated during fine-tuning, LoRA drastically cuts down on the memory and computational requirements. This makes fine-tuning very large models on commodity GPUs or edge devices feasible.
- Scalability: LoRA can be scaled across various model architectures and sizes, making it a versatile solution for fine-tuning different types of LLMs.
- Preservation of Pre-trained Knowledge: Since only a small subset of parameters is adjusted, the original knowledge embedded in the pre-trained model is largely preserved. This leads to faster convergence and improved performance on downstream tasks.
LoRA implementation
When implementing LoRA, carefully select the rank of the low-rank decomposition. A higher rank will capture more information but at the cost of increased resource usage. A lower rank may lead to suboptimal fine-tuning results.
The selection should be guided by the specific task and the available resources. Additionally, regularization techniques can prevent overfitting, and hyperparameter tuning can balance the trade-off between model performance and computational efficiency.
Parameter-Efficient Fine-Tuning (PEFT)
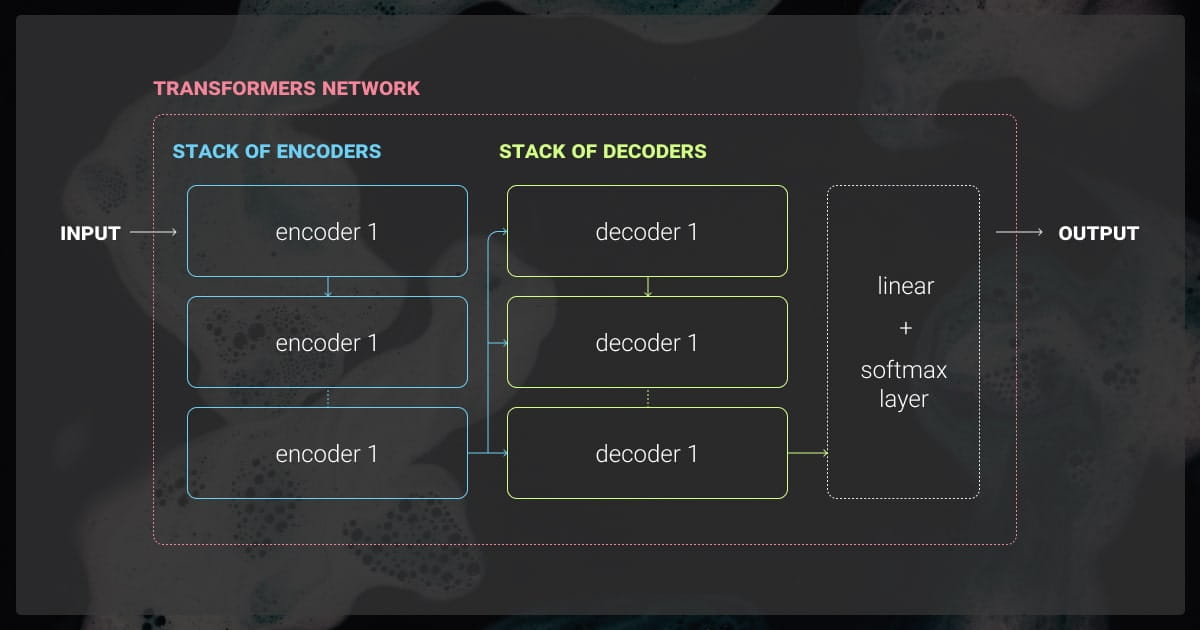
Parameter-Efficient Fine-Tuning (PEFT) encompasses a range of techniques for adapting large models by tuning a minimal number of parameters. Among these, Adapter Layers and Prefix-Tuning have gained significant traction.
Adapter Layers
Adapter layers involve inserting small, trainable layers within each transformer block of an LLM. These layers are lightweight and designed to capture task-specific information without significantly altering the underlying model architecture.
The primary advantage of this method is its modularity. Depending on the task, adapter layers can be added or removed, enabling multi-task learning and domain adaptation without retraining the entire model.
Prefix-Tuning
Prefix-tuning optimizes the model by adjusting only a sequence of “prefix” tokens that are prepended to the input at each transformer layer. Unlike traditional fine-tuning, which updates the entire model’s parameters, prefix-tuning focuses on these prepended tokens, significantly reducing the fine-tuning footprint.
This technique is especially effective when multiple tasks must be addressed concurrently. It allows task-specific prefixes to be learned without interfering with the core model parameters.
Comparing PEFT with Traditional Fine-Tuning
Compared to traditional fine-tuning methods, PEFT techniques substantially improve efficiency and adaptability. Traditional fine-tuning often requires significant computational resources and can lead to catastrophic forgetting, where the model loses previously learned knowledge. PEFT mitigates these issues by minimizing the changes made to the model’s weights, thereby preserving the model’s original capabilities while efficiently adapting to new tasks.
Multi-Task and Multi-Domain Fine-Tuning
Multi-task and Multi-domain fine-tuning involve training LLMs on multiple tasks or domains simultaneously. This strategy can lead to models with broader capabilities and better generalization.
However, the complexity of managing such fine-tuning increases due to potential conflicts in gradient directions from different tasks or domains.
Strategies for Multi-Task and Multi-Domain Fine-Tuning
- Gradient Surgery. One effective strategy for handling conflicting gradients is Gradient Surgery, where conflicting gradient components are projected onto a common subspace. This reduces interference between tasks.
- Task-Specific Modulation. Here, task-specific parameters or layers are introduced to isolate the impact of each task on the shared model parameters.
- Curriculum Learning. This strategy can be employed where tasks are introduced to the model in a sequence that gradually increases in difficulty. It allows the model to build a robust understanding incrementally.
Ensuring Stability in Training
Stability during multi-task fine-tuning can be ensured by implementing techniques such as Gradient Clipping to prevent explosive gradients and Regularization methods like Dropout or Weight Decay to avoid overfitting.
Monitoring the training process closely and using dynamic learning rates can also help maintain stability, especially when the tasks vary widely in complexity or domain.
Monitoring and Evaluating Fine-Tuned Large Language Models
After fine-tuning an LLM, ongoing monitoring is essential to ensure it performs as expected in production. Fine-tuning can introduce changes that require continuous evaluation. It prevents performance degradation or unexpected behaviors.
Advanced Metrics for LLM Evaluation
When fine-tuning LLMs, traditional metrics like accuracy and precision may not fully capture performance nuances. You need advanced evaluation metrics here:
- BLEU and ROUGE work great for text generation tasks, providing insights into how well the model’s output aligns with human-authored references.
- Calibration metrics are used when the model’s confidence in its predictions matters. They assess whether the predicted probabilities reflect the true likelihood of correctness.
- LangEval and F1Py offer advanced capabilities for assessing LLM performance across multiple dimensions, including accuracy, coherence, and response diversity. They are invaluable for ML teams aiming to ensure that their fine-tuned models meet the specific needs of their deployment context.
Real-Time Monitoring and Continuous Evaluation
Once in production, fine-tuned LLMs require vigilant monitoring for sustained performance. Real-time monitoring strategies involve setting up infrastructure that continuously tracks model outputs, latency, and usage patterns. This is critical for the early detection of issues such as latency spikes or unexpected behavior in model predictions.
Prometheus and Grafana are popular choices for establishing real-time dashboards and alerts. These tools can be configured to monitor various model metrics and trigger alerts when performance deviates from expected baselines. Integrating such monitoring systems into your ML pipeline ensures that you can react promptly to any degradation in model performance.
Continuous evaluation, beyond initial deployment, is vital for maintaining model relevance and effectiveness. Techniques such as A/B testing or shadow deployments can be employed to iteratively test improvements without disrupting the production environment. Regular re-evaluation using updated datasets ensures the model adapts to evolving data distributions and user needs.
Handling Model Degradation and Drift
Model degradation and drift are common challenges with fine-tuned LLMs, particularly as the data distribution shifts or the model’s training data becomes outdated. Model drift can manifest as a gradual decline in performance or an increase in bias.
To mitigate these issues, ML teams can implement proactive monitoring strategies, such as drift detection algorithms that trigger retraining processes when significant drift is detected. Additionally, frequent retraining on updated datasets and incorporating feedback loops where human evaluations guide the model’s evolution are effective countermeasures against degradation.
Scaling Fine-Tuning to Larger Datasets and Models
As datasets grow larger and models become more complex, scaling fine-tuning efforts is necessary to maintain performance and efficiency. Distributed training techniques, such as data parallelism and model parallelism, are critical in this context.
Frameworks like PyTorch Lightning and Hugging Face Accelerate provide out-of-the-box support for distributed training across multiple GPUs or nodes, facilitating scaling.
By adhering to these steps, ML teams can fine-tune large models, ensuring optimal performance while managing the complexities inherent in large-scale ML projects.
Trust our model validation services to keep your LLM performing at its best.
Current Trends and Future Predictions for LLM Fine-Tuning
LLM fine-tuning rapidly evolves with new techniques like LoRA, adapter tuning, and few-shot learning. In this section, we’ll cover the latest trends driving more efficient and scalable fine-tuning and future directions.
Emerging Techniques and Research
As we advance through 2024, LLM fine-tuning is evolving with new techniques that make models more adaptable and efficient. Key developments include zero-shot and few-shot learning, which allow models to perform tasks with little to no task-specific data. These techniques enhance model generalization, but challenges like overfitting and the need for robust evaluation frameworks remain.
Zero-Shot and Few-Shot Fine-Tuning
Zero-shot and few-shot fine-tuning enable LLMs to handle tasks with minimal data. While zero-shot learning allows models to perform without prior examples, few-shot learning requires just a handful. Despite their potential, these methods face challenges like overfitting.
Prompt Tuning and Hybrid Approaches
Prompt tuning, which refines the input prompts to improve model responses, is increasingly combined with traditional fine-tuning for enhanced performance. Hybrid approaches, blending prompt tuning with parameter-efficient fine-tuning methods, offer a balance between performance and computational efficiency. Future research will likely focus on integrating these methods with AutoML to create more autonomous, adaptive models.
The Role of AutoML in Fine-Tuning
AutoML is transforming LLM fine-tuning by automating hyperparameter selection and optimization processes. This not only speeds up fine-tuning but also expands its accessibility. Looking ahead, AutoML is expected to enable more adaptive, self-optimizing models, making LLM fine-tuning more efficient and widely applicable.
Ethical and Societal Implications
The growing sophistication of LLM fine-tuning brings significant ethical considerations. Fine-tuning can introduce biases and have broad societal impacts, such as influencing information dissemination and automating complex jobs. ML teams must prioritize transparency, accountability, and ethical guidelines to ensure that LLMs are developed and deployed responsibly.
If your ML team needs a tailored LLM for your project, our fine-tuning experts are ready to help.
About Label Your Data
If you choose to delegate data annotation, run a free pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is the difference between fine-tuning and RAG LLM?
Fine-tuning involves updating the weights of a pre-trained LLM on domain-specific data to optimize its performance for specialized tasks. In contrast, Retrieval-Augmented Generation (RAG) combines LLM generation with a retrieval mechanism that pulls relevant information from external knowledge bases to improve factual accuracy. RAG doesn’t change the model's weights but enhances its outputs by integrating context from an external source, while fine-tuning adjusts the model to internalize domain-specific knowledge.
How to do fine-tuning in transfer learning?
- Begin with a pre-trained LLM (e.g., GPT) and prepare a smaller, domain-specific dataset for continued training.
- Freeze the early layers to retain the model’s generalized knowledge.
- Train the later layers to help the model adjust to the new domain-specific data.
- Adjust hyperparameters, such as learning rate and batch size, to optimize training and reduce the risk of overfitting.
- Allow the model to adapt to new tasks while leveraging its existing language understanding through fine-tuning.
Is transfer learning better than fine-tuning LLM?
Transfer learning is a broad concept where a model trained on one task is reused for another, while fine-tuning is a specialized form of transfer learning. Whether transfer learning is “better” depends on the context.
If your domain is closely related to the pre-trained model’s data, fine-tuning can be highly effective. However, if your task requires completely new knowledge, transfer learning with pre-training from scratch might be a better option.
To fine-tune an LLM for text generation, follow these steps:
- Collect and preprocess data: Ensure it’s well-aligned with your desired text style or domain.
- Set up the environment: Use frameworks like Hugging Face’s Transformers or OpenAI’s API.
- Choose the right LLM: Select a model (e.g., GPT-4) with relevant capabilities for text generation.
- Tune hyperparameters: Adjust parameters like learning rate and batch size for effective training.
- Evaluate and iterate: Monitor performance on text coherence, fluency, and relevance, tweaking as needed.
What are LLM hyperparameters?
LLM hyperparameters are configurations set before training begins and influence how the model learns. Key hyperparameters include:
- Learning rate: Controls how much to adjust model weights per update.
- Batch size: Number of training samples used in one iteration.
- Sequence length: Maximum token length for inputs.
- Number of epochs: Full passes through the training data.
- Dropout rate: Prevents overfitting by randomly dropping neurons during training. Tuning these parameters is critical for optimizing model performance.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.