Convolutional Neural Networks: How to Apply for Computer Vision

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- The Building Blocks of Convolutional Neural Networks
- Recent Advancements in the Architecture of Convolutional Neural Networks
- Advanced Techniques to Use for Convolutional Neural Network Optimization in 2024
- Innovative Applications of CNNs in Computer Vision
- Challenges in Applying Convolutional Neural Networks
- Emerging Tools and Libraries for CNN Development
- About Label Your Data
- FAQ

TL;DR
- Use convolutional, pooling, and activation layers to build strong CNN foundations.
- Incorporate Vision Transformers and hybrid models for cutting-edge applications.
- Fine-tune pre-trained models and optimize training for better performance.
- Apply CNNs to real-time object detection and advanced medical imaging.
- Ensure data quality and tackle model interpretability for reliable results.
- Leverage tools like TensorFlow and PyTorch for efficient CNN deployment.
The Building Blocks of Convolutional Neural Networks
Convolutional Neural Networks (CNNs) have become essential tools in computer vision, enabling precise image analysis and interpretation. Their applications span diverse industries, from improving diagnostics in healthcare to powering the vision systems in autonomous vehicles.
As you work on computer vision projects, CNNs can provide the essential framework for extracting complex features from images. It enables you to develop highly effective models in object detection, image classification, and semantic segmentation tasks.
Before diving into advanced techniques and applications of convolutional neural networks, let’s cover (or, for some of you, recap) the foundational concepts of CNNs.
What Are Convolutional Neural Networks?
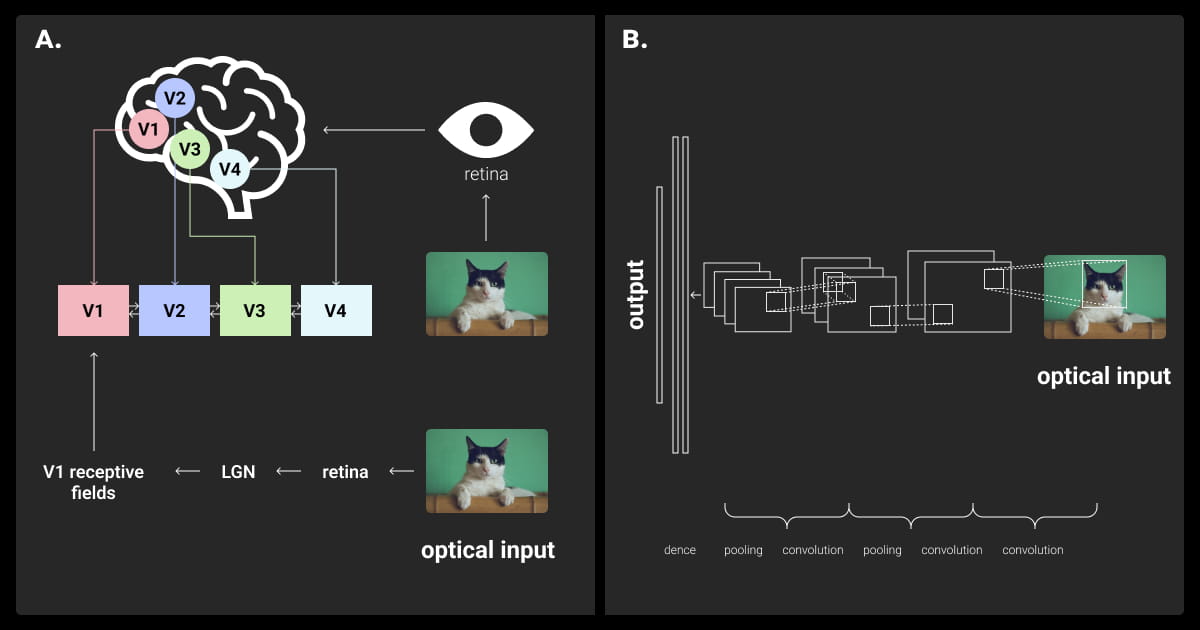
Convolutional Neural Networks are a type of deep neural network specifically designed for visual data analysis. They are inspired by the way the visual cortex in humans processes information. CNNs learn to recognize patterns in images by automatically identifying features at different levels of detail.
Unlike traditional neural networks, where every neuron connects to all neurons in the next layer, CNNs use a more focused approach. Each neuron in a CNN only connects to a small part of the previous layer. This smaller connection area is called the receptive field, allowing CNNs to analyze images efficiently.
Key Components of CNNs
Convolutional Layers
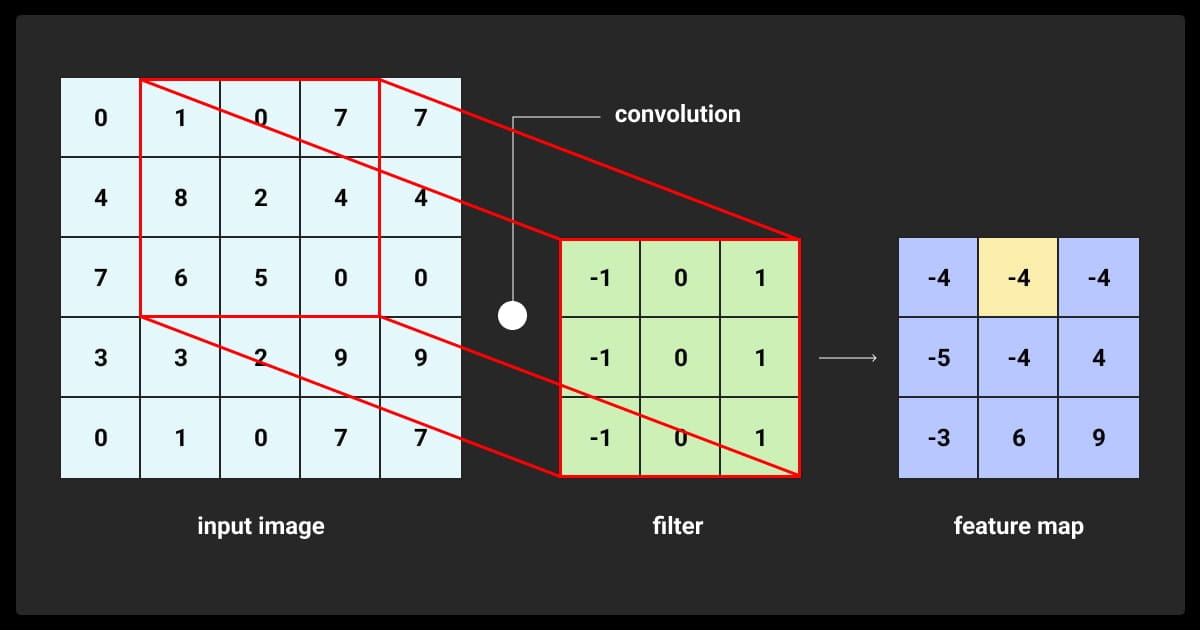
The convolutional layer is the critical component of a CNN. In this layer, filters (also known as kernels) are applied to the input data to create feature maps. These filters move over the image, performing calculations at each position. This process helps the network learn to recognize local patterns, such as edges, textures, or even more complex shapes like objects, as you go deeper into the network.
These filters are small in size, typically 3x3 or 5x5 pixels, but they cover the entire depth of the input image. The outcome of this process is a feature map, which highlights the specific features the filter detects across the image.
Pooling Layers
After the convolution process, the feature maps are usually downsampled using a pooling layer. The two most common types of pooling are max pooling and average pooling. Max pooling picks the highest value from a defined window in the feature map, while average pooling calculates the average value within that window.
Pooling reduces the size of the feature maps, which lowers the computational demands on the network. It also makes the detected features more consistent, even if the input image shifts slightly.
Activation Functions
Activation functions are applied after the convolutional layers to introduce non-linearity into the network. It helps the convolutional neural network learn complex patterns. The most common activation function in CNNs is the Rectified Linear Unit (ReLU), which sets any negative values in the feature maps to zero.
Other activation functions, such as Sigmoid and Tanh, are also used but are less common in modern CNNs. This is because they can cause issues like vanishing gradients, which make it harder for the network to learn effectively.
Fully Connected Layers
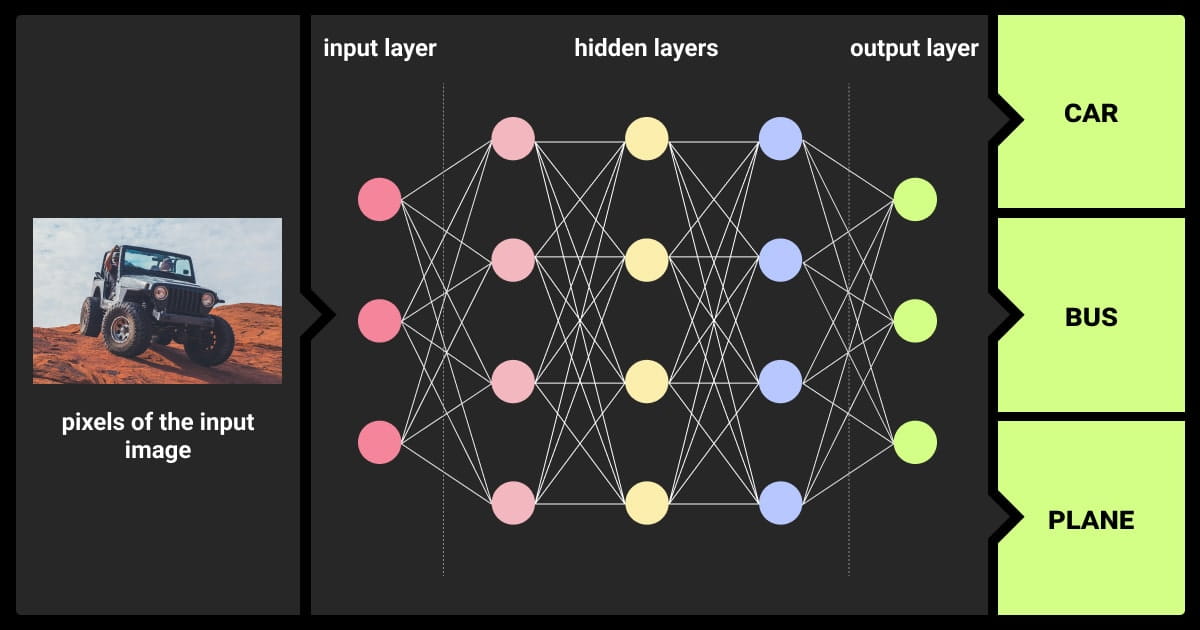
At the end of a CNN, the feature maps are flattened into a single vector after multiple layers of convolution and pooling. This vector is then passed through one or more fully connected layers. These layers function like those in traditional neural networks, combining the features extracted earlier to make the final prediction.
With convolutional neural networks for image classification tasks, the output from the fully connected layers is typically passed through a Softmax activation function. This produces a probability distribution, indicating the likelihood that the input belongs to each possible class.
Normalization and Regularization Techniques
Batch Normalization is used to normalize the output of each layer, which helps stabilize and accelerate the training process. Dropout, on the other hand, is a regularization technique in which neurons are temporarily “dropped” during training. This prevents overfitting by encouraging the network to learn more general and robust features rather than relying too much on specific neurons.
Advantages of Convolutional Neural Networks
Translation Invariance
CNNs can identify patterns no matter where they appear in an image. This ability comes from the convolutional and pooling layers, which consistently detect features across different input locations.
Data Efficiency
Convolutional neural networks (CNNs) can effectively learn and represent features even when trained on relatively small datasets. CNNs are a good choice for scenarios where large, labeled datasets are unavailable.
Hierarchical Feature Learning
The lower layers of a CNN learn to recognize basic features, like edges, while the higher layers identify more complex, abstract concepts, such as entire objects or shapes.
Elevate your computer vision projects with CNNs trained on precisely annotated data. Contact us for expert computer vision annotation services!
Recent Advancements in the Architecture of Convolutional Neural Networks
New architectures are being developed to tackle the growing complexity of computer vision tasks in 2024. A key trend in recent years is the emergence of Vision Transformers (ViTs). They are challenging traditional applications like convolutional neural networks for image classification.
While convolutional neural networks (CNNs) use convolutions to analyze spatial hierarchies in images, ViTs take a different approach. They treat images as sequences of patches and use self-attention mechanisms. Initially used in NLP, this approach has led to a rethinking of CNN design. As a result, we now see hybrid architectures like ConvNeXt, which combines the strengths of both CNNs and transformers, delivering significant improvements in managing complex vision tasks.
Hybrid Models
Hybrid models combine CNNs with other models to expand their applications beyond traditional tasks. For example, when CNNs are integrated with generative models like Generative Adversarial Networks (GANs) or Variational Autoencoders (VAEs), they excel in image synthesis, super-resolution, and style transfer. These hybrids take advantage of the generative power of GANs or VAEs and the feature extraction strengths of CNNs.
Additionally, combining CNNs with reinforcement learning (RL) is widespread in robotics and autonomous systems. In these fields, CNNs process visual input, while RL algorithms decide the best actions to take. This combination reflects a growing trend in AI, where different models work together in modular systems to achieve more effective and specialized outcomes.
Modular and Scalable CNNs
As computer vision tasks become more diverse and complex, there’s a growing need for CNN architectures that are both modular and scalable. Modular CNNs offer flexibility in design, allowing developers to customize models for specific tasks by reusing and combining existing modules. This speeds up development and makes adapting CNNs to new challenges easier without starting from scratch.
Besides, as datasets grow more extensive and more varied, CNNs must be able to scale efficiently to meet the increased demand. Advances in hardware, like more powerful GPUs and specialized AI accelerators, support scalable CNNs. Additionally, neural architecture search (NAS) and automated machine learning (AutoML) help optimize CNN architectures for specific tasks automatically.
Advanced Techniques to Use for Convolutional Neural Network Optimization in 2024
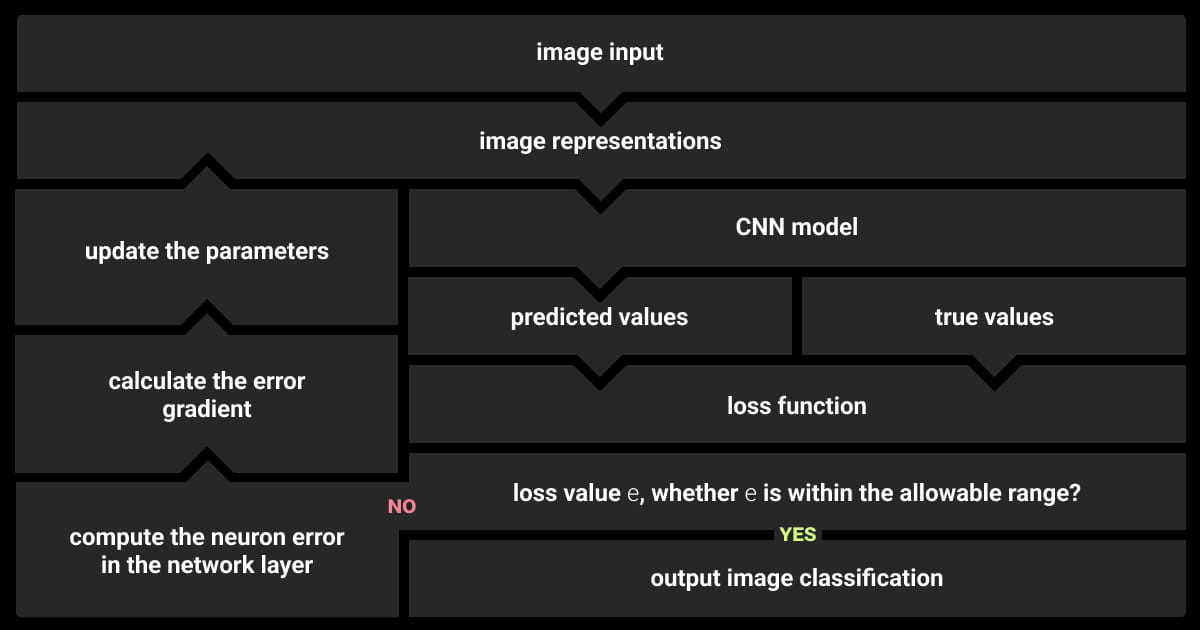
Explore cutting-edge techniques to optimize your CNNs for peak performance in 2024:
Fine-Tuning Strategies
Fine-tuning is essential when applying CNNs to specific tasks, especially when starting with pre-trained models.
Layer-Wise Learning Rate Adjustment
With this strategy, different layers of the CNN are fine-tuned at different rates. This approach offers more precise control over how the model adapts to new data, which is particularly useful when certain features are more critical than others.
Selective Fine-Tuning
When applying this strategy, only specific layers of the CNN are adjusted based on the task’s requirements and how similar the new data is to the original training data.
Domain-Specific Adaptations
They are mainly used in specialized fields like medical imaging or satellite imagery, where data has unique characteristics that need special attention. By integrating domain knowledge into fine-tuning, CNNs can be more effectively optimized for tasks that generic models might not handle well.
Efficient CNN Training
Training CNNs from scratch can be costly and time-consuming, especially as models grow larger and datasets more complex. Several techniques have emerged to improve efficiency without sacrificing performance.
Mixed Precision Training
This technique uses different levels of precision (like 16-bit vs. 32-bit) across the network, reducing computational load and speeding up training.
Model Pruning
Another approach that removes less important parameters, reducing the model’s size and complexity while maintaining accuracy. This makes pruned models faster to train and more efficient during inference, which is ideal for resource-constrained environments.
Quantization
The method further enhances efficiency by lowering the precision of weights and activations. It enables CNNs to run on edge devices with limited processing power, which is crucial for real-time applications like autonomous vehicle object detection.
Transfer Learning and Pretrained Models
Transfer learning is essential in applications of convolutional neural networks when labeled data is limited. Developers can transfer learned features to new tasks using pretrained models, such as those trained on large datasets like ImageNet. It reduces the need for extensive data and resources.
In 2024, the use of pretrained models has grown, with more domain-specific models available for fields like healthcare and agriculture. These specialized models provide a more relevant foundation for fine-tuning on specific tasks.
Additionally, techniques like progressive learning, where models are incrementally refined on increasingly complex tasks, have further enhanced performance by building on previously acquired knowledge.
Enhance your CNNs’ performance in image recognition with our precise image annotation services.
Innovative Applications of CNNs in Computer Vision
Explore the most innovative applications of convolutional neural networks driving advancements in computer vision.
Real-Time Object Detection
Real-time object detection is a crucial application of CNNs, especially in the automotive, robotics, and security industries. In 2024, advances in hardware and software have significantly enhanced CNNs’ ability to detect and classify objects with exceptional speed and accuracy.
Lightweight architectures like MobileNets and EfficientNets, designed for real-time use, balance performance and efficiency, making them ideal for deployment on devices like smartphones and drones. Additionally, integrating CNNs with AI models like recurrent neural networks (RNNs) and transformers has further improved object tracking in complex, dynamic environments.
Medical Imaging Advances
CNNs have made significant strides in medical imaging, particularly in radiology, pathology, and ophthalmology. Today, these networks can automate disease diagnosis and provide predictive insights to guide treatment decisions.
A key development is integrating multimodal data, combining imaging, patient records, and genetic information, to deliver more accurate diagnoses and personalized treatments. CNNs are also advancing precision medicine by identifying biomarkers that predict treatment responses.
Moreover, extending CNNs to analyze 3D medical images like MRIs and CT scans has improved the detection and segmentation of abnormalities.
Beyond Traditional Vision Tasks
Convolutional neural networks (CNNs) are expanding beyond traditional tasks. In 2024, they’re tackling challenges in video understanding, including real-time action recognition and scene reconstruction. They have broad applications in entertainment, surveillance, and autonomous systems.
Another emerging application is 3D object recognition, which is crucial for robotics and augmented reality (AR). By harnessing CNNs, these systems achieve greater spatial awareness, enabling more complex and intuitive interactions with the physical world.
Challenges in Applying Convolutional Neural Networks

Uncover the key challenges in applying convolutional neural networks and how to navigate them effectively.
Data Quality and Annotation
The effectiveness of CNNs hinges on high-quality, accurate data annotation, which is increasingly difficult and expensive to obtain as models become more complex. To overcome this, synthetic data generation and active learning are being used to supplement and refine datasets. Transfer learning also plays a crucial role by leveraging existing data to improve performance when new labeled data is limited.
Model Interpretability and Explainability
Understanding how they make decisions is essential with critical applications of convolutional neural networks like healthcare and autonomous driving. Techniques such as Grad-CAM and saliency maps help visualize essential features, offering insights into the model's decision-making process. Attention-based CNNs enhance interpretability by focusing on crucial image areas, making predictions easier to trust.
Ethical Considerations
The ethical challenges of using convolutional neural networks, such as bias, privacy concerns, and potential misuse, are becoming more prominent. In 2024, there is a stronger emphasis on developing ethical guidelines to ensure responsible AI deployment. This includes creating transparent models, using representative datasets, and implementing safeguards against misuse.
Unlock the full potential of your CNNs in video analysis with expertly annotated video data. Partner with Label Your Data for accurate, frame-by-frame video annotation services.
Emerging Tools and Libraries for CNN Development
Discover the latest tools and libraries advancing convolutional neural network development for more efficient and robust implementations.
Frameworks and Libraries
The evolution of CNNs has significantly been supported by powerful frameworks like TensorFlow, PyTorch, and Keras, which will continue to be enhanced in 2024. These frameworks now include features for:
- Mixed Precision Training: Reducing computational load by using different levels of precision in calculations.
- Neural Architecture Search (NAS): Automatically finding the best CNN architectures.
- Real-Time Inference: Optimizing CNNs for immediate, on-the-fly processing.
New tools like ONNX (Open Neural Network Exchange) are also gaining popularity for standardizing model export and deployment across multiple platforms. AutoML tools have also advanced, providing automated design and optimization of CNN architectures, making it easier for developers to achieve high performance without manual tuning.
AutoML for CNNs
AutoML has revolutionized CNN development by automating critical processes like model design and optimization. In 2024, AutoML tools are even more powerful, offering:
- Neural Architecture Search (NAS): Automatically selecting the most suitable CNN architecture for a task.
- Hyperparameter Tuning: Fine-tuning model parameters for optimal performance.
- Data Augmentation: Enhancing training data to improve model robustness.
- Model Ensembling: Combining multiple models to improve accuracy and reliability.
These capabilities allow developers to rapidly create and refine CNNs tailored to specific tasks, often outperforming manually designed models.
Deployment and Inference Optimization
Deploying convolutional neural networks in production environments requires careful optimization, especially for real-time applications. In 2024, several tools and techniques have emerged to make this easier:
- Edge Computing Solutions: Allowing CNNs to run directly on devices like smartphones, cameras, and drones, reducing latency and enhancing privacy.
- TensorRT and OpenVINO: Frameworks that provide specialized optimizations for inference, enabling efficient operation across various hardware platforms.
- Model Quantization and Pruning: Techniques that reduce the size and complexity of CNNs, making them more suitable for resource-constrained environments without compromising accuracy.
These advancements are crucial for deploying sophisticated CNN models in real-time applications, ensuring they run efficiently and effectively.
Run a free pilot to test high-quality annotations for your computer vision models!
About Label Your Data
If you choose to delegate data labeling, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
Is CNN machine learning or deep learning?
CNNs are a subset of deep learning, a branch of machine learning. Deep learning focuses on training large neural networks with many layers, and CNNs are specifically designed to handle the complexities of visual data within this framework.
How do convolutional neural networks work?
So, here’s how convolutional neural networks work. They apply convolutional layers that filter the input image to extract essential features. These features are then processed through pooling layers to reduce dimensionality and complexity. Finally, fully connected layers analyze the extracted features to make a prediction or classification.
What are CNNs used for?
CNNs are primarily used in computer vision tasks such as image and video recognition, object detection, and segmentation. They are also employed in various fields, including healthcare for medical imaging, autonomous driving for object detection, and social media for content moderation.
What are the limitations of CNNs?
CNNs require large labeled datasets, are computationally intensive, and can struggle with understanding complex spatial hierarchies. They also risk overfitting and can be challenging to interpret in critical applications.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.