What’s the Difference Between Image Classification & Object Detection?

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- Object Detection vs. Image Classification: Key Factors to Consider
- Spotting the Difference: Image Classification vs. Object Detection
- Spotting Similarities: The Connection Between Image Classification and Object Detection
- A Practical Guide to Remembering the Difference Between Image Classification and Object Detection Once and For All
- About Label Your Data
- FAQ
TL;DR
- Image classification assigns a single label to an image, while object detection identifies and locates multiple objects within an image.
- Classification is simpler, focusing on one prominent object; detection is more complex, requiring bounding boxes for precise localization.
- Applications include autonomous driving, retail analytics, and medical image analysis.
- Key architectures include CNNs for classification and models like YOLO and Faster R-CNN for detection.
- Both techniques enhance machine vision, though object detection offers more detailed insights into image content.
Object Detection vs. Image Classification: Key Factors to Consider

Computer vision is a captivating field. From self-driving cars to medical image analysis and virtual reality, these tasks propel the limitless capabilities of computer vision.
Two tasks most commonly used and often mistakenly thought of as somewhat similar: image classification and object detection. For this reason, we’d like to delve into the nuances of image classification vs. object detection and uncover their role in training robust models for machine vision.
Object detection and image classification are crucial tasks commonly used in computer vision, including applications like geospatial annotation. Here, precise object recognition is key to mapping and environmental analysis. Let’s now discuss each task separately to better understand the difference between image classification and object detection.
Understanding Image Classification
Image classification in computer vision is a foundational task for which an annotator attributes a label (or a category) to an entire data piece (i.e., image or video frame). In essence, the model learns to recognize patterns and features within an image that are indicative of a particular class. For instance, a well-trained image classification model can differentiate between various animal species, classify everyday objects, or even diagnose diseases in medical images.
The fundamental challenge of an image classification technique lies in feature extraction. The model must identify distinguishing characteristics within the image that define its class. This often involves using convolutional neural networks (CNNs) that are adept at capturing hierarchical features like edges, textures, and shapes. These features are acquired via supervised learning, which involves training the model using a labeled machine learning dataset.
Understanding Object Detection
While image classification focuses on assigning a single label to an entire image, object detection models go a step beyond by recognizing and pinpointing the positions of numerous objects within an image. In other words, object detection not only categorizes the objects present, but also draws bounding boxes around them to indicate their exact location.
Object detection has gained immense importance due to its wide range of applications. From advanced driver assistance systems (ADAS) that enable cars to perceive their surroundings to retail analytics (take a look at the ZARA case) that track product placement, object detection serves as a versatile tool.
The complexity of object detection stems from its dual requirements of categorization and localization. This has led to the development of architectures like Faster R-CNN, YOLO (You Only Look Once), and SSD (Single Shot MultiBox Detector), each with its unique approach to solving this intricate challenge.
Spotting the Difference: Image Classification vs. Object Detection
To help you better grasp the difference between image classification & object detection, we’ve created a table that highlights the notable differences between these two concepts:
| Aspect | Image Classification | Object Detection |
| Task | Assign a label/category to an entire image. | Recognize and pinpoint multiple objects within an image, associating labels with each individual object. |
| Output | Single class label per image. | Multiple class labels and bounding boxes per image. |
| Goal | Recognize the main subject of the image. | Identify objects and determine where they are located in the image. |
| Use Cases | Basic image tagging, identifying the overall content. | Autonomous driving, surveillance, image understanding tasks where object location matters. |
| Complexity | Generally simpler; focus on the most prominent object. | More complex; involves both classification and localization tasks. |
| Bounding Boxes | Not applicable; doesn't deal with bounding boxes. | Essential; bounding boxes indicate object positions. |
| Network Architectures | Often use standard CNN architectures. | Use architectures like Faster R-CNN, YOLO, SSD, which include both CNNs and region proposal networks. |
| Training Labels | Requires labeled images with class/category. Some open source datasets include CIFAR-10, ImageNet, MNIST, and Caltech-256 | Requires labeled images with class/category and precise bounding box annotations. Object detection datasets encompass COCO, PASCAL VOC, Open Images, KITTI, and Cityscapes. |
| Evaluation Metrics | Accuracy, precision, recall. | Intersection over Union (IoU), mean Average Precision (mAP), precision, recall. |
| Real-time Applications | Faster inference; applicable when only category matters. | Slightly slower due to localization, but useful when object positions are important. |
| Example | Identifying whether an image contains a dog or a cat. | Detecting and labeling pedestrians, cars, and traffic signs in a street scene. |
While this table highlights the key differences between image recognition vs. object detection, there’s often a blurry line between the two. Some object detection tasks might involve classifying objects within bounding boxes, making it a combination of both tasks.
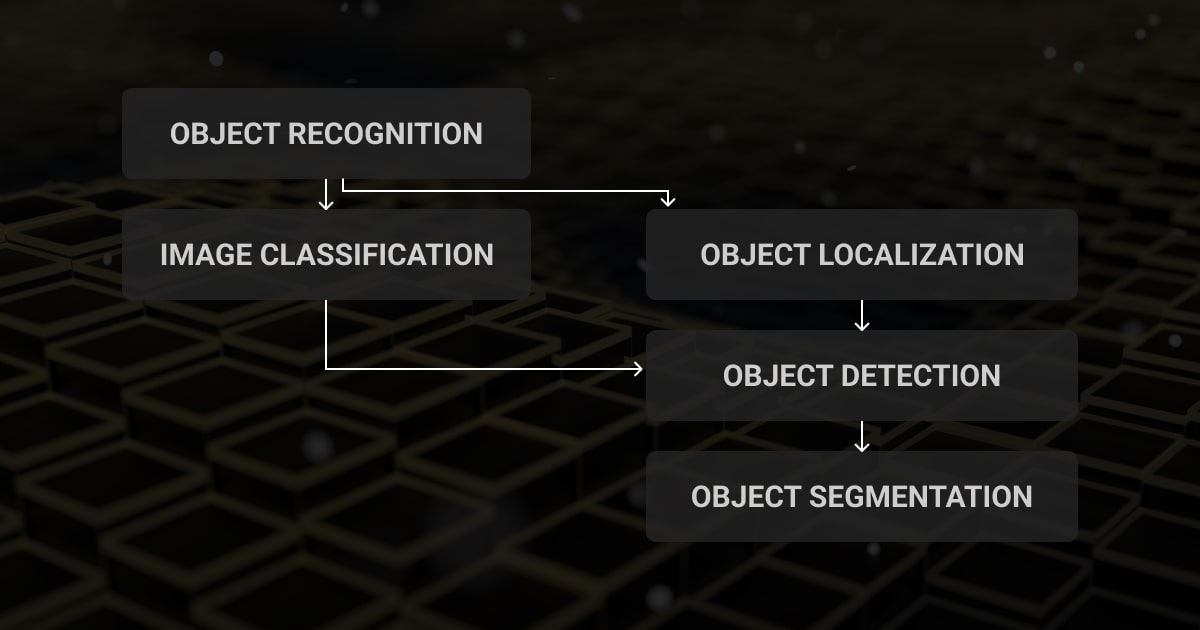
Spotting Similarities: The Connection Between Image Classification and Object Detection
The “object detection vs. image classification” dilemma involves more than just their differences. Let’s explore the common aspects shared by these two concepts. Once more, we’ve prepared a detailed table to illustrate these similarities:
| Aspect | Image Classification | Object Detection |
| Feature Extraction | Both tasks involve extracting high-level features from images to understand their content. | Similar feature extraction process using convolutional neural networks (CNNs). |
| Deep Learning Approach | Benefits from deep learning architectures and techniques for feature learning. | Deep learning methods like CNNs are widely used for both tasks. |
| Dataset Usage | Requires labeled datasets for model training and evaluation. | Labeled datasets containing object annotations are essential for training. |
| Supervised Learning | Both tasks are typically formulated as supervised learning problems. | Both tasks follow a supervised learning paradigm to learn patterns. |
| Image Understanding | Contributes to the understanding of image content. | Image classification is a subset of object detection tasks. |
| Application Diversity | Both tasks find applications in various domains like AI in healthcare, automotive, and entertainment. | Widely used in diverse fields for tasks like autonomous driving and content tagging. |
A Practical Guide to Remembering the Difference Between Image Classification and Object Detection Once and For All

Building upon our prior discussion of image classification vs. object detection, we now delve into the practical significance, offering a comprehensive approach to solidify your basic knowledge about the two most fundamental among various computer vision techniques.
Image Classification
As we already know, image classification refers to the process of assigning a predefined category to a visual data piece. By using a dataset of images labeled with their corresponding categories, an ML model is trained to achieve this outcome. After that, a model can then predict the label or category for new and unseen images.
There are two primary forms of image classification:
- Single label classification that involves assigning a single class label to data. As an example, an object may be categorized as either a bird or a plane, but not both.
- Multi-label classification entails assigning two or more class labels to data. This is useful when identifying multiple attributes within an image. For instance, in ecological research, a multi-label classifier can identify various features like tree species, animal types, water bodies, terrain, and vegetation within a single image or video frame.
Image classification finds various practical applications in digital asset management (AI for efficient content organization), AI content moderation (filtering out harmful content from user-generated content), or even product categorization (i.e., ecommerce products can be accurately categorized).
Object Detection
Significant strides have been made in object detection in the last two decades. Recent advancements in object detection have led to real-time and efficient implementations that can run on resource-constrained devices like smartphones and embedded systems, opening up new possibilities for applications like interactive gaming and industrial automation. Additionally, object detection models have been adapted to handle 3D object detection tasks, enabling applications in robotics, augmented reality (AR), and autonomous navigation in three-dimensional spaces.
Future research will be primarily focused on these object detection problems:
- Lightweight detection: Accelerating detection on low-power edge devices, crucial for AR, autonomous driving, and smart cities. Despite recent efforts, the speed gap with human vision remains, particularly for small or multi-source detection.
- End-to-end detection: Current methods often use separate steps like non-maximum suppression. Focus on efficient end-to-end pipelines maintaining high accuracy is a potential avenue.
- Small object detection: Detecting small objects has applications in population counting and military target identification. Integrating visual attention and designing high-res lightweight networks are future directions.
- 3D object detection: Vital for autonomous driving, research will shift towards 3D detection and utilizing multi-source data like RGB images and LiDAR points.
- Video detection: Real-time object detection in video needs improved spatial-temporal correlation exploration despite computation constraints.
- Cross-modality detection: Leveraging multiple data sources enhances accuracy, but challenges include adapting detectors and fusing information.
- Open-world detection: Emerging topics like out-of-domain generalization and zero-shot detection pose challenges for detecting unknown objects without explicit supervision.
What’s more, advanced scenarios involve combining classification models with object detection. For instance, combining an object detection model with an image classification model enables not only the identification of objects but also their subclassification based on the detected attributes. Also, additional services can be used to enhance image classification or object detection by providing tools for data collection, preprocessing, scaling, monitoring, security, and efficient deployment in the cloud.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
Is object detection an image processing task?
Yes, object detection is a common task used for image processing technology, which entails the identification and localization of objects within an image or video frame.
Is face recognition and object detection the same?
Similar to the “object detection vs. image classification” discussion, face recognition and object detection are not the same. Facial recognition involves recognizing and verifying faces in images or video, while object detection entails determining the location of objects in images or video, which may include faces as one of many possible object classes.
What is another name for object detection?
Another term that can be used for object detection is “object localization and classification.”
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.