What Is Computer Vision in Machine Learning?

 CEO of Label Your Data
CEO of Label Your Data

Humans seem to have no difficulty understanding the three-dimensional nature of the surrounding world. Think of the smartphone or a laptop you are reading this article on, a desk lamp, or maybe a large tree outside your window… It’s easy for us to describe the shape of these objects, their size, volume, as well as color distributions.
For machines, however, vision is a tough nut to crack. The main reason for this is that AI computer vision is an inverse problem. Therefore, modeling a 3D world with its rich complexity is a much more resource-intensive and multistep process that tries to imitate the way human visual perception works.
Computer vision (or simply CV) is one of the most deeply studied and developed areas in artificial intelligence. There was practically not a single article where we didn’t mention computer vision solutions. We talked about image recognition, video recognition, as well as autonomous driving, where both solutions apply. In this article, however, we’ll focus on the term now, define CV, and try to understand what machine vision is all about!
According to the research, the market for computer vision is expected to be worth $41.11 billion by 2030. Computer vision is a branch of AI that aims at teaching machines to extract meaningful knowledge from digital data, such as images, videos, and other visual inputs. Based on this data, CV helps machines take appropriate actions or make decisions (i.e., recommendations, predictions) as per the task at hand. Hence, while the main goal of AI is to teach machines to think and act like humans, computer vision is in charge of endowing machines with visual skills.
In a nutshell, computer vision systems enable machines to see, observe, and comprehend the world around them just like humans. Obviously, human vision and that of machines are two different types of vision, with human sight being around (and evolving) for much longer compared to CV. The benefit of the human eye is that it has had a lifetime to learn how to distinguish between things, determine their distance from the viewer, their movement, and whether something is off about a picture.
However, given the rapid advancement of AI today, is this an issue for machines? We’ll answer this question and examine the complex process of computer vision in artificial intelligence throughout the article, so stay tuned!
The Process Behind Computer Vision Systems

Despite the lack of retinas, optic nerves, and visual cortex, computer vision is still capable of training AI systems to execute similar tasks in much less time. They do so by using cameras, sensors, data, and machine learning algorithms. Energy, utilities, manufacturing, and the automobile industries all employ computer vision AI, and the industry is still expanding.
Yet, how do these sophisticated systems work? What do they need to provide accurate results? The answer is data, of course. CV-based technologies and systems require a considerable amount of data to train machines to recognize patterns in images or videos. Let’s say you have an ongoing project, where you work on creating a self-driving vehicle. The task is to train an autonomous system to recognize pedestrians and other objects a car may encounter on the road. To do this, you need to feed your model with a proper amount of labeled data, meaning images of pedestrians and other objects.
However, this is only a brief overview of how computer vision works. Computer vision AI is based on two key technologies: deep learning, a subfield of machine learning, and convolutional neural networks (CNN). The latter was mentioned in one of our blogs about semantic segmentation if you want to know more on CNNs. With the use of algorithmic models, a computer may learn how to understand the context of visual input using machine learning for computer vision. Instead of being programmed to recognize a picture, algorithms allow the computer to learn on its own.
By dividing up pictures into pixels and assigning labels to each one, a CNN helps a machine learning or a deep learning model to develop the ability to see. The computer uses the labels to perform convolutions, a mathematical procedure that combines two functions to create a third function. It then uses the results to forecast what it sees. Up until the predictions start to come true, the neural network iteratively executes convolutions while assessing the accuracy of its predictions.
Once this happens, the model is able to recognize or perceive visual data similarly to humans. There’s also an RNN, a recurrent neural network, used to train machines to analyze videos (as images that come in a series of frames) and understand how they are connected.
The accuracy rate of computer vision technologies has dramatically increased over the last decade, from 50% to 99%. Moreover, machines have become several times faster than humans to perform tasks that require visual skills. We’ll talk more about these tasks in the next section.
How Is Machine Learning Used in Computer Vision?
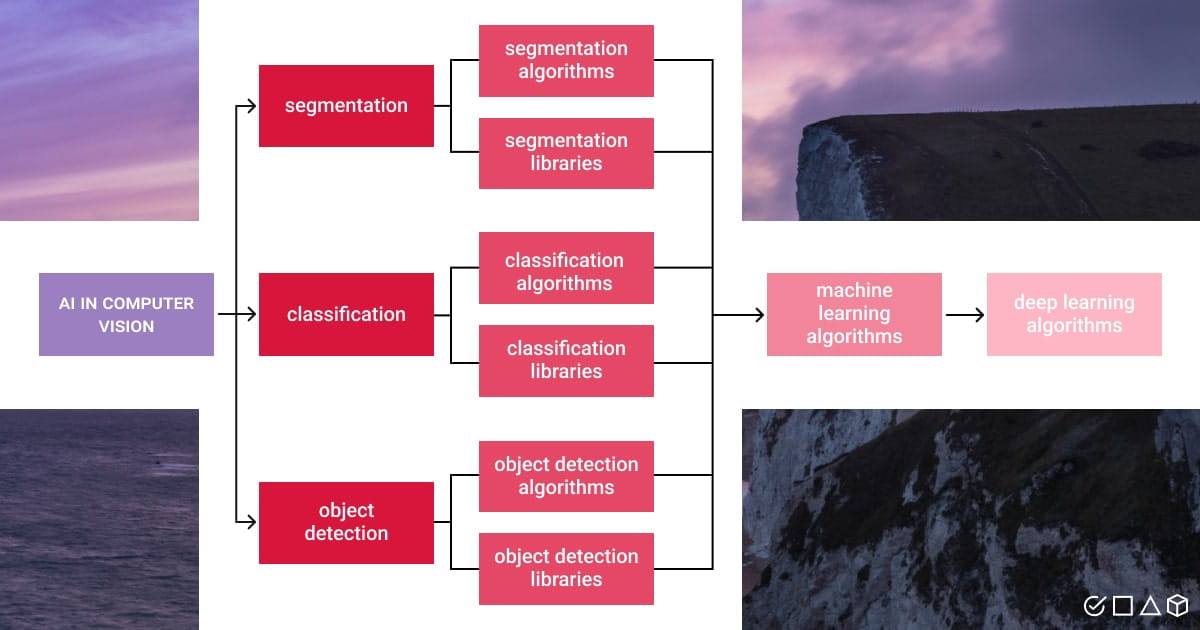
The purpose of computer vision and machine learning is to provide AI systems with the capacity to collect data, comprehend it, and make judgments based on past and present outcomes. The industrial IoT, human cognitive interfaces, and computer vision all depend on one another.
To recognize and follow complicated human activities in multimedia streams, machine learning in computer vision is represented by a number of methods:
- Supervised learningInput data and desired outcomes or variables are combined throughout this learning process. The supervised ML method is applied across many sectors, including healthcare, smart manufacturing, spatial data analysis, and weather prediction. It works with the CV tasks such as classification, regression, and pattern recognition.
- Unsupervised learningIt defines a set of issues where relationships in data must be defined or retrieved using a model. The unsupervised ML methods are used in education, healthcare, market basket analysis, and several industries. These methods deal with clustering, visualization, and projection.
- Semi-supervised learningThis type of learning includes far more unlabeled examples than labeled ones in the training set. Semi-supervised learning can be helpful for image data and audio data tasks, for example, automatic speech recognition. Image classification and segmentation are addressed by this ML method.
- Reinforcement learningA category of issues is represented by this ML technique in which an agent must operate inside a certain environment while learning to do so through feedback. Reinforcement learning is great for machine translation, the movie sector, animated games, as well as self-driving cars. The CV tasks solved by this method are clustering, pattern recognition, and projection.
- Active learningUsing this strategy, the model may query a human user operator to resolve uncertainty during the learning process. Active learning works well for computational biology, object categorization, image classification, image segmentation, and scene classification.
- Transfer learningAn ML technique in which a model is initially trained on one task before being utilized wholly or in part as the basis for another task that is related to it. It’s applied across many industries, such as agriculture, healthcare, geoinformatics, and gaming. The tasks transfer learning solves include image classification, image segmentation, and also video analysis.
We should note that this is not an exhaustive list of machine learning methods and computer vision applications. Some other techniques include:
- Self-supervised learning;
- Multi-instance learning;
- Inductive learning;
- Transductive learning;
- Multi-task learning;
- Ensemble learning;
- Federated learning;
- Zero-shot Learning;
- Meta-learning.
Computer Vision Applications
Today, there is a wide range of practical uses for computer vision in AI. They include:
- OCR (Optical Character Recognition): The process of teaching machines to recognize text data and human handwriting for document analysis, plate or traffic sign recognition, data entry, etc.
- Machine inspection: The stereo vision application area for rapid parts inspection to measure tolerances on auto body parts or aircraft wings, as well as X-ray vision for identification of defects in steel castings.
- Retail: Object recognition is used here for automated checkout lanes and fully-automated stores.
- Warehouse logistics: AI-assisted package delivery, robot manipulators for parts picking, or pallet-carrying drives are enabled by computer vision in warehouse systems.
- Medical imaging: CV helps perform long-term studies of the human brain, as well as registering preoperative and intraoperative medical imagery.
- Self-driving vehicles: A well-developed machine’s ability to drive (and fly) point-to-point and at different distances with no human control.
- 3D model construction: With computer vision capabilities, it’s now possible to build 3D models from aerial and drone imagery in a fully-autonomous manner.
- Match move: Mixing computer-generated imagery with live footage to estimate 3D camera motion and shape of the environment (a popular CV method used in Hollywood).
- Motion capture (mocap): Capturing actors for computer animation with the help of retro-reflective markers viewed from different cameras or other CV-based techniques.
- Surveillance systems: Video data analysis by CV system to track intruders, analyze highways, or even monitor pools for drowning victims.
- Fingerprint recognition and biometrics: In this case, computer vision enables automated access authentication and forensic applications.
Computer Vision Challenges
Let’s discuss the research gaps in computer vision that have been found, as well as the machine learning approaches that may be used to address these problems and bring the discipline of machine vision to the next level.
- Imbalanced data (class imbalance) — Transfer learning, Multi-task learning, and Federated learning;
- Data scarcity — Zero-shot learning, Few-shot learning, and Transfer learning;
- Overfitting/Underfitting of data — Ensemble learning, Meta-Learning, and Active learning;
- Detection and Classification of blur images — Support Vector Machine (SVM);
- Human intervention — Meta-learning and Constructive learning;
- Robustness of ML techniques — Ensemble models;
- High operational costs (model training) — Reinforcement learning, Transfer learning, and Meta-learning;
- Power and storage consumption — Federated learning;
- A large scale of unlabeled images — Self-supervised learning, Few-shot, and Zero-shot learning.
Computer Vision Tasks & Examples
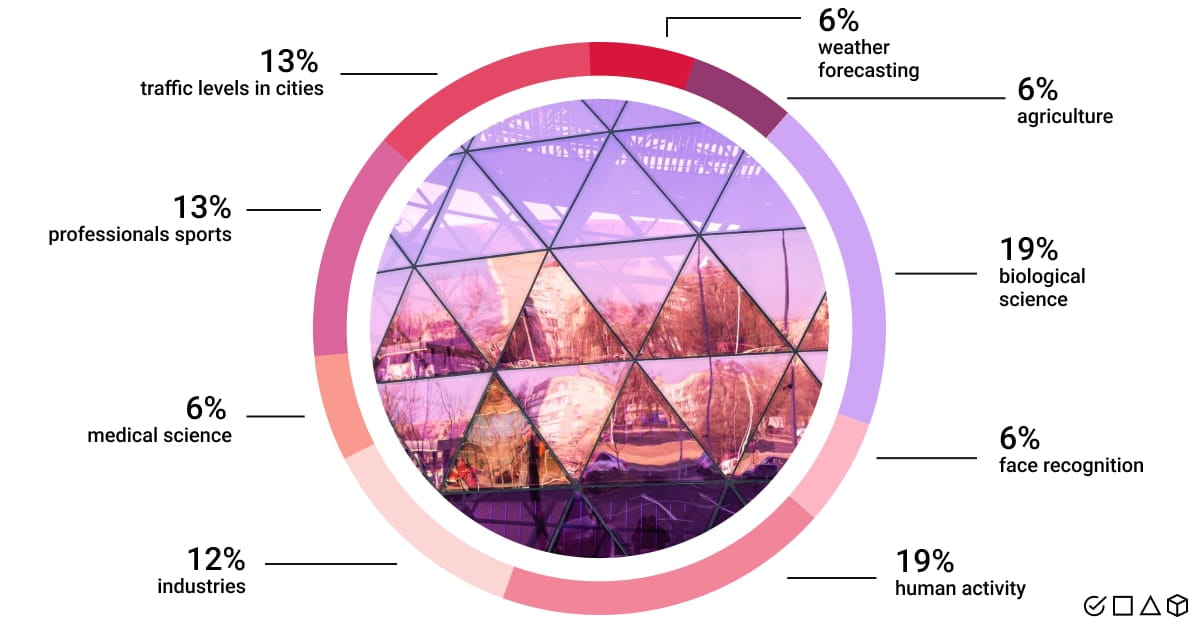
The field of computer vision has been advancing quickly, finding practical applications, and even outpacing humans in some visual task resolution. All of this is a result of recent developments in artificial intelligence, specifically machine learning and deep learning.
Computer vision tasks essentially aim at teaching machines to comprehend both digital pictures and visual information from the outside environment. They comprise techniques for capturing, processing, analyzing, and comprehending images or videos. They also include methods for extracting high-dimensional data from the actual world to create numerical or symbolic information, which we call decisions.
Here are some examples of well-known computer vision tasks:
- Object detection: To identify a certain class of image, object detection can employ image classification. Then, it can find and tabulate objects that fall into that category in an image or video. As an illustration, consider spotting damage on a manufacturing line or locating equipment that needs maintenance.
- Object tracking: This task is frequently carried out using real-time video streams or a series of sequentially collected images. For example, autonomous vehicles must track moving objects such as pedestrians, other vehicles, and road infrastructure. Yet, this task is performed after the objects were detected and classified, to prevent crashes and follow traffic regulations.
- Image classification: Any image may be classified using the image classification task. More specifically, it can correctly guess which class a given image belongs to. Case in point, this task can be used to automatically recognize and sort out offensive photographs shared by users on social media.
- Content-based image retrieval: To explore, search, and retrieve images from huge data repositories based on their content rather than the metadata tags attached to them, content-based image retrieval employs computer vision. Automatic image annotation can be used instead of manual image labeling for this activity. The accuracy of search and retrieval may be improved by using these activities with digital asset management systems.
Data Labeling for Computer Vision Tasks

To tackle the above-mentioned CV tasks, supervised machine learning requires a lot of annotated training data for solving vision problems in AI. Currently, the field of computer vision is undergoing a transformation that gives rise to game-changing new applications.
You’ve already heard of, seen, and maybe even driven a car that can easily navigate autonomously. What about innovations in healthcare that are assisting doctors in finding complex diseases, or intelligent manufacturing plants? All these solutions rely on computer vision systems. For prediction tasks like recognizing, localizing, and segmenting visual objects, ML models can interpret spatial information in raw image data and automatically learn patterns. This is why a lot of labeled data is necessary for training ML models.
Therefore, the fundamental concept behind data annotation for a computer vision system is to create a mapping of visual elements with semantic and spatial labels. This provides us with a clear description of the image’s content.
At least five phases are involved in the image labeling process:
- Collection: Gathering all the relevant data in sufficient quantities and quality, either manually or automatically.
- Labeling: The annotation process itself, where metadata is added to the images or videos to make this data machine-readable.
- Post-processing: The process of improving the quality of annotations by label merging, visual tag refinement, or resizing and rotating the photos to evenly distribute the locations of the objects.
- Quality assessment: It is used to resolve misinterpretations of classes, instances, and similarities that might result in under- or overrepresentation and bias.
- Export: To enable data export, annotations must be stored in a structured format.
Supporting manual labeling with image labeling software and gradually removing a human annotator from the process is a common approach to reducing expenses associated with data annotation. The most popular software for CV tasks are listed below:
- LabelMe
- labelImg
- VIA
- CVAT
- VoTT
- Web Annotation
- ImageTagger
Summary: Computer Vision and Machine Learning — A Great Duo?

Computer vision with machine learning forms a strong alliance, resulting in a wide range of intelligent solutions that have been significantly streamlined by technology advancements in the disciplines of ML and DL.
Even though computer vision systems are still in their infancy, they have a staggering number of practical applications that benefit humanity today. As long as humans and machines learn to better collaborate, processes and technologies that rely on computer vision will be soon fully-automated. In the end, we achieve freed up human labor and more time and resources for higher-value jobs.
However, computer vision models require thorough training for supervised ML models, and huge samples of annotated data still pose a significant barrier. Here, data labeling plays a crucial role in supplying the underlying knowledge base with high-quality, human-verified data.
Does your AI project have something to do with computer vision? Then you definitely need a hand with well-annotated data. Contact our Label Your Data team for a secure and high-quality data labeling service. Together, we can achieve the most outstanding project outcomes!
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.