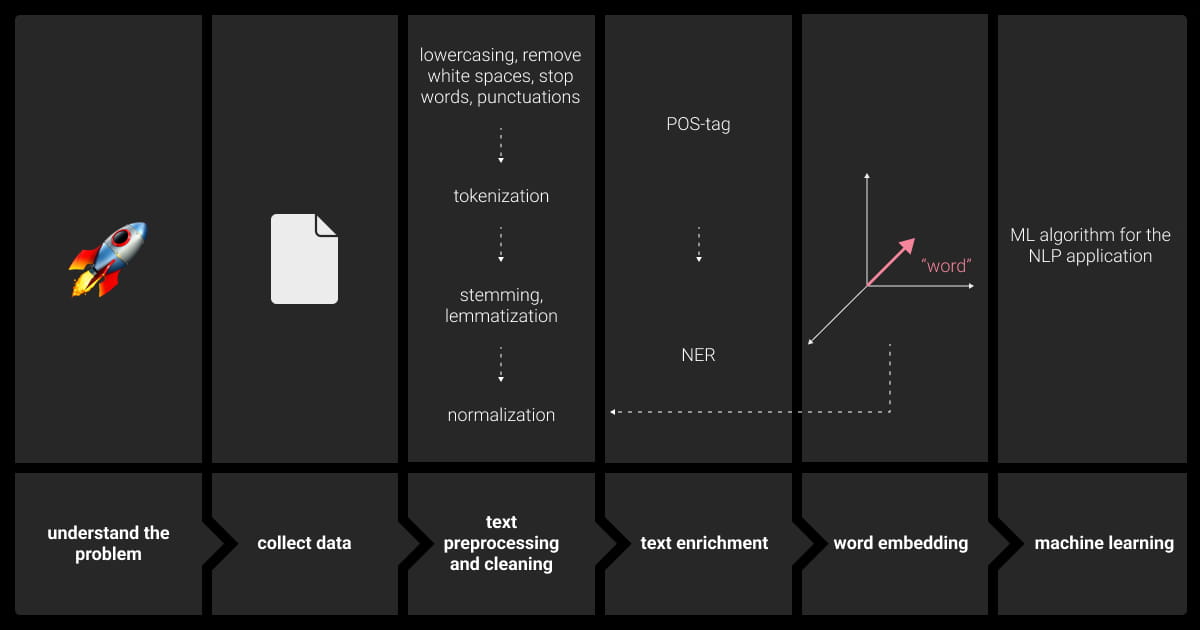
Natural Language Processing Techniques in Machine Learning

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- Feature Extraction Natural Language Processing Techniques
- Text Preprocessing Strategies in NLP
- Text Representation and Data Annotation for NLP Models
- Natural Language Processing Techniques: Model Selection and Fine-Tuning
- Evaluation and Model Validation as Natural Language Processing Techniques
- Which Natural Language Processing Technique to Choose?
- About Label Your Data
- FAQ

TL;DR
- There are 3 feature extraction techniques: use BoW for basic text classification, TF-IDF for a more refined text representation, and N-grams for a more accurate context.
- The top reprocessing strategies are stemming and lemmatization, POS tagging, and NER.
- Use rule-based methods for extracting dates and phone numbers from documents.
- Text classification models like Naive Bayes can be used with feature extraction techniques.
- Use evaluation metrics like the F1-score to test the NLP model against the unseen text data.
Feature Extraction Natural Language Processing Techniques
Feature extraction techniques transform text data into a numerical format that ML models can further process and analyze during supervised learning. With them, we detect the most critical information that relates to such parameters of the text as the significance of the words or their frequency. This approach comes in handy for such tasks as text classification.
Bag of Words (BoW)
The Bag of Words (BoW) model serves as a foundational technique in text processing. This is one of the natural language processing models techniques where the text is seen as a matrix of word counts. BoW method supposes counting the presence of specific words in documents.
BoW technique works when the word order is not important. It is applicable for such text classification tasks as categorization, spam detection, or sentiment analysis. However, it will not be as efficient when you need a model to capture the context or additional word meaning.
For the effectiveness of BoW technique, a couple of preprocessing steps need to be accomplished. They include text normalization, removal of stop words, or elimination of general uninformative sequences.
Term Frequency-Inverse Document Frequency (TF-IDF)
Building upon the BoW model, Term Frequency-Inverse Document Frequency (TF-IDF) provides a more refined approach to text representation. This approach is more intricate and requires greater computational resources. It's suitable for medium and large-size datasets. TF-IDF helps highlight terms that are unique to a document and downweights common terms that are less informative.
While distinguishing between documents and emphasizing distinctive words, TF-IDF helps with the choice for information retrieval and document classification tasks. The natural language processing examples for TF-IDF can be search engines or filtering tasks.
N-grams
N-grams refer to the number of n items in a chosen text. N can refer to words or characters, depending on the task. This is one of the advanced natural language processing techniques that helps to capture local word order and context. Unlike BoW and TF-IDF, which treat words independently, N-grams technique considers the relationship between adjacent words. Such analysis contributes to a richer representation of text.
The choice of n (e.g., bigrams, trigrams) directly impacts the granularity and complexity of the features. While N-grams can capture more context than single words, they also introduce challenges such as increased dimensionality and sparsity. Bigrams and trigrams are usually applicable for capturing meaningful word combinations in tasks like sentiment analysis or phrase detection. The larger combinations however can lead to overfitting, especially if we work with a limited data.
Text Preprocessing Strategies in NLP
Text preprocessing strategies include such methods as tokenization, stopword removal, and stemming, among others. They are crucial for cleaning and standardizing text data before we pass it to a machine learning model training. With these strategies, we can transform the text into a simplified format, preparing the basis for models to learn and perform the given tasks. They are efficient in such tasks as classification and sentiment analysis.
According to Statista, the current trends in NLP include multilingual models development, the increase of predictive analytics, and decision-making. They will lead the boost in market growth, conquering healthcare and e-commerce, customer support and finance industries. This shows the importance of applying one or multiple NLP techniques to reach the needed accuracy.
Stemming and Lemmatization

At the stage of NLP preprocessing, we go through text normalization process. It's one of the crucial steps that uses stemming and lemmatization to shorten words to their initial forms.
- Stemming consists of removing suffixes from words. The example would be removing "ing" in the word "doing", reducing it to its regular form "do". The drawback of this method is its inaccuracy, which can result in providing words that do not exist.
- Lemmatization uses linguistic knowledge to reduce words to their basic, dictionary-guided forms. It helps to differentiate such forms of the word as "good" and "better".
While we usually apply stemming to calculate computational efficiency rather than linguistic accuracy, this method best serves in text mining tasks, where the differences between words are not critical. Lemmatization instead helps us with tasks where we need to preserve the semantic meaning of words. We would rather go for it if we work with legal or medical data, where accuracy is critical.
Part-of-Speech Tagging (POS Tagging)
With part-of-speech (POS) tagging, we label each word in a text with its speech equivalent. For example, you separately label nouns, adjectives, or verbs. This technique helps us to specify the grammatical context. It serves to give a profound meaning of a sentence's structure and meaning.
POS tagging is particularly valuable in tasks that require a deeper understanding of sentence structure, such as syntactic parsing or named entity recognition (NER). Additionally, such tags can be incorporated as features in machine learning models. Enhancing the representation of textual data, they contribute to relationship identification (e.g., subject-verb, noun-adjective), which further influences model predictions. POS tagging can be combined with other techniques, such as N-grams, to provide the best level of syntactic and semantic precision.
Named Entity Recognition (NER)
Named Entity Recognition (NER) is a technique used to identify and categorize key entities within a text. The categories differ from people to locations, groups of people, organizations, NER is needed for such tasks as information extraction, document classification, and question answering.
By identifying and labeling entities, NER enriches the feature set used for training machine learning models, enabling more accurate and context-aware predictions. Existing NER tools and libraries (e.g., SpaCy, NLTK) can be utilized to quickly extract entities from text. With their pre-trained models, the next steps involve fine-tuning and usage out-of-the-box for many applications. The technique increases the overall accuracy.
To ensure the correctness of your training data and improve the performance of your ML model, collaborate with specialists in the field. Try a free NLP annotation pilot with us!
Text Representation and Data Annotation for NLP Models
Text representation and annotation focus on structuring and labeling text data, unlike other techniques that mainly process or analyze text. Methods like rule-based extraction target specific, predictable patterns, and data annotation ensures precise labeling, providing a well-organized foundation for training models. They target tasks where accuracy and structured input are crucial, such as in classification and information extraction.
Rule-Based Methods
With rule-based methods, you can extract structured information from text by applying handcrafted rules or regular expressions. The methods are useful in tasks where patterns are well-defined, such as extracting dates, phone numbers, or specific phrases from documents.
While rule-based approaches lack the flexibility of statistical models, they can be highly effective in scenarios with clear, consistent patterns. Rule-based methods are ideal for tasks involving well-structured text with predictable patterns. Their implementation in small datasets gives higher results.
NLP Data Annotation
High-quality data annotation is a cornerstone of successful supervised learning in natural language processing. Properly labeled data ensures that the model learns from accurate and representative examples, directly impacting its performance.
Data annotation involves assigning labels to text data, such as tagging sentiment or classifying topics, among others. The quality of these annotations depends on consistency, accuracy, and the annotators’ understanding of the task.
While annotation can be manual or automated, it's important to start with the clear guidelines. They serve as a starting point for further consistency across annotations. An accurate annotation is a cornerstone of the following training data. It's important to apply regular quality checks, such as inter-annotator agreement measures. They help assess the consistency and accuracy of the annotations.
If you want to ensure your NLP data is accurate and ready for further ML training, trust this task to professionals. Contact Label Your Data today!
Natural Language Processing Techniques: Model Selection and Fine-Tuning
Model selection and tuning in NLP specifically involve evaluating and comparing different machine learning algorithms to identify which one performs best on a given text-based task.
Tuning techniques, like grid search or cross-validation, are then applied to optimize hyperparameters—such as the regularization strength in logistic regression or the number of trees in a Random Forest—ensuring the model is both accurate and robust for the specific characteristics of the text data.
Text Classification with Traditional ML Algorithms
Once features have been extracted and preprocessed, traditional machine learning algorithms can be applied to build models for text classification. Common algorithms include Naive Bayes, Support Vector Machines (SVMs), and Decision Trees.
These models are well-suited for handling text data, particularly when combined with feature extraction techniques like BoW, TF-IDF, or N-grams. We apply these techniques for text classification tasks where the assumption of feature independence holds reasonably well, such as spam detection in E-commerce industry.
- Naive Bayes is used for high-dimensional text data, since it's computationally efficient.
- SVMs are suitable for tasks where the feature space is large and sparse, as is often the case with TF-IDF or N-gram representations. SVMs excel at finding the optimal hyperplane that separates classes, making them effective for binary and multiclass classification.
- Decision Trees are useful for tasks where interpretability is important, such as in legal or financial document classification. Decision Trees offer a clear visualization of decision paths, which can be valuable for understanding model decisions.
Hyperparameter Tuning
Hyperparameter tuning involves identifying the best set of hyperparameter values for a learning algorithm, optimizing its performance when applied to any dataset. The key hyperparameters include the smoothing parameter in Naive Bayes, the kernel type and regularization parameter in SVMs, and the depth of trees in Decision Trees.
Grid search or random search can be employed to systematically explore the hyperparameter space. This approach helps in identifying the optimal combination of hyperparameters for specific tasks. Hyperparameters that directly impact the handling of text features, such as vector dimensionality or regularization strength, are particularly important to consider as they can significantly affect the model’s ability to generalize from the training data.
Evaluation and Model Validation as Natural Language Processing Techniques
Evaluation and model validation techniques focus on rigorously assessing how well a machine learning model performs on text data by using metrics such as accuracy, precision, recall, and F1-score. Unlike other natural language processing models techniques, these methods include practices like cross-validation and test-train splits to ensure the model's predictions are not only accurate but also consistent and generalizable to new, unseen text data.
Evaluation Metrics for NLP Tasks
It's critical to choose the right evaluation metric so that it increases the performance of a given task. The following metrics offer insights into different aspects of model performance:
- Accuracy indicates the percentage of correct predictions, but it can be deceptive when dealing with imbalanced datasets.
- Precision reflects the ratio of true positive predictions to the total number of positive predictions made, while recall measures the proportion of true positives among all actual positives.
- F1-score combines precision and recall into a single measure, effectively accounting for both false positives and false negatives.
If you work with imbalance data, like sentiment analysis or NER, F1-score technique would suit most. It's also better to use precision and recall together to balance the assessment of false positives and false negatives, especially in tasks where the cost of one type of error is higher than the other. The usage of one of these techniques will help you avoid bias in machine learning algorithms.
Cross-Validation Techniques
Cross-validation is crucial for reliably assessing the performance of NLP models, particularly when dealing with limited data. K-fold cross-validation involves splitting the dataset into a k subsets and training the model a k of times, each time using a different subset as the validation set. In its turn, stratified sampling ensures that each fold maintains the same distribution of classes as the original dataset, which is particularly important in imbalanced datasets.
If K-fold cross-validation is more applicable to smaller and imbalance datasets, stratified sampling proposes a proportional class representation across all dataset.
Error Analysis
With error analysis, we examine the mistakes made by a model to identify patterns and potential areas for improvement. For error analysis, we usually use confusion matrix analysis and manual review of misclassified examples. They show the pitfalls of a model that need further improvement. Such checks are especially needed in critical areas, for example military technology.
Conducting error analysis regularly provides insights into where the model is struggling. Analyzing confusion matrices, for example, helps in identifying which classes are frequently misclassified. The findings from error analysis should guide iterative improvements in feature selection, model parameters, or even the data annotation process. This iterative approach helps in fine-tuning the model for better performance.
Which Natural Language Processing Technique to Choose?
What are natural language processing techniques that would be the most efficient in various ML tasks? All techniques are tailored to enhance performance of ML models. Their application will depend on the task you're currently working on. Thus, tokenization and stopword removal are fundamental for text preprocessing, while TF-IDF and Bag of Words (BoW) would be helpful for feature extraction in text classification.
You may opt for Named Entity Recognition (NER) for extracting proper nouns in information extraction tasks, or classifiers for sentiment analysis. They all serve you to carve your data and make it as accurate as possible for further ML model top-notch performance.
About Label Your Data
If you choose to delegate data annotation for NLP models, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is an example of the NLP technique?
One of the examples of NLP techniques is Named Entity Recognition (NER). It finds and labels names, places, and connections in text. It's often used in tasks like sorting documents or pulling out key details to improve model accuracy.
Is ChatGPT a NLP?
Yes, ChatGPT is an example of an NLP application. It uses natural language processing to understand and generate human-like text, which allows it to lead conversations and answer questions. This technology helps make interactions with computers feel more natural and intuitive.
What type of NLP technique is data annotation, and how does it help with ML model training?
Data annotation is a critical preprocessing technique in NLP that involves labeling text data with relevant tags or categories. It helps with ML model training by providing accurate and consistent examples for the model to learn from, which is essential for building effective and reliable NLP models.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.