Supervised Learning: Best Practices for ML Engineers

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- The Importance of Advanced Supervised Learning Techniques
- Selecting the Right Data Sources in Supervised Learning
- Best Practices in Data Collection and Preprocessing
- Supervised Learning Model Selection and Training
- Handling Overfitting and Model Generalization in Supervised Learning
- Model Evaluation and Interpretation
- Deployment and Monitoring of Supervised Learning Models
- About Label Your Data
- FAQ

TL;DR
- Supervised learning requires advanced techniques to optimize ML pipelines, fine-tune models, and scale effectively.
- Prioritize domain-specific data, balancing open datasets with precise proprietary data.
- Enhance model robustness with rigorous preprocessing, including synthetic data generation and feature engineering.
- Address overfitting using L2 regularization and stratified cross-validation.
- Optimize models with advanced hyperparameter tuning, like Bayesian optimization and AutoML.
- Ensure generalization with transfer learning and domain adaptation, especially for complex datasets.
- Maintain performance post-deployment with drift detection, anomaly detection, and scheduled retraining.
- Tackle scalability with distributed computing, model compression, and optimized inference for real-time use.
The Importance of Advanced Supervised Learning Techniques
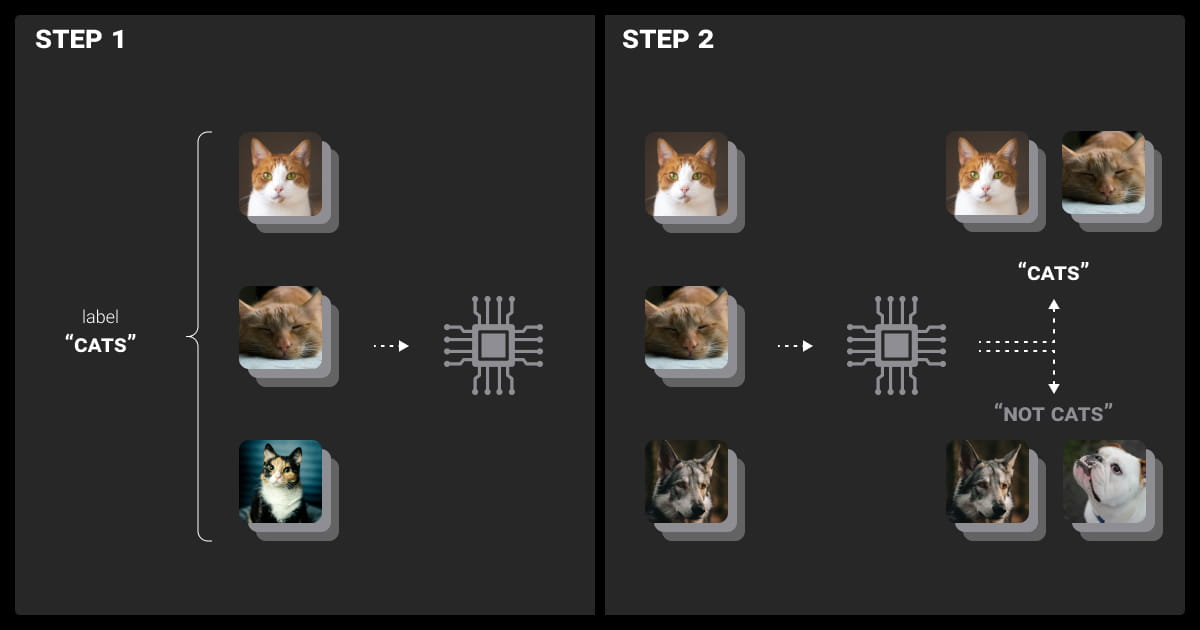
The AI landscape has evolved with larger datasets, synthetic data generation, more sophisticated algorithms, LLMs, and an increasing need for model interpretability. Advanced supervised learning techniques are essential for ML engineers to optimize workflows and keep pace with the latest trends.
Selecting the Right Data Sources in Supervised Learning
Choosing the appropriate data sources is a critical first step in building effective supervised learning models.
Data Relevance
Good data forms the backbone of every successful supervised machine learning model. The first step in building an effective model is selecting the right data sources that align closely with the problem you’re solving.
For ML engineers, this means prioritizing domain-specific datasets that reflect the nuances of the target domain. Whether it’s financial data for predictive analytics or medical records for disease prediction, the relevance of your data sources directly impacts model accuracy and reliability.
Open Datasets vs. Proprietary Data
ML engineers often face the choice between open-source datasets and proprietary data. Open datasets offer accessibility and a wealth of information but may lack the specificity and quality control of proprietary data. Proprietary data, while often more aligned with the specific use case, comes with challenges such as access restrictions, licensing issues, and the need for thorough quality checks.
Balancing these two options requires careful consideration. Open datasets are helpful for initial prototyping and model development, but proprietary data often proves more valuable for production-level models. It’s crucial to evaluate the pros and cons and confirm that the chosen data source fits the project's specific needs.
Here’s a quick summary for you to share with your colleagues and make a decision:
| Criteria | Open Datasets | Proprietary Data |
| Accessibility | Easily accessible, often free, and available to the public. | Restricted access, often requires purchase or licensing. |
| Relevance | General-purpose; may not be tailored to specific use cases or industry needs. | Highly relevant and specific to the use case, aligning closely with business objectives. |
| Quality Control | Variable quality; may contain noise or inconsistencies. | High quality with strict controls, curated to meet specific standards. |
| Cost | Free or low cost, making it ideal for experimentation and prototyping. | Often expensive, reflecting the data’s value and specificity. |
| Legal and Ethical Considerations | Minimal restrictions, but potential issues with outdated or improperly anonymized data. | Stringent legal constraints, including compliance with regulations like GDPR or CCPA. |
| Use Case Suitability | Best suited for initial prototyping and exploratory analysis. | Ideal for production-level models requiring precision and alignment with business goals. |
Data Enrichment
Even the most relevant datasets require enhancement to fully support your model’s objectives. Data enrichment involves augmenting your existing datasets by merging data from multiple sources or integrating external data. It can include economic indicators or geographic information.
This process improves model performance by providing additional context that the model might not otherwise consider. For instance, incorporating weather data could help predict consumer behavior more accurately in a retail analytics model. The key is to identify external data that enhances the predictive power of your model without introducing noise or redundancy.
Best Practices in Data Collection and Preprocessing
To build robust supervised learning models, the quality and preparation of your data are just as important as the algorithms you choose. Data collection and preprocessing ensure that your models are fed with the most accurate and relevant information.
Data Quality
Poor-quality data leads to false predictions, overfitting, and a host of other issues. To mitigate these risks, you need to implement robust data preprocessing techniques.
Data Augmentation
Data augmentation is a powerful method to enhance data quality, mainly when dealing with imbalanced datasets. The following techniques help create a more balanced dataset and improve the model’s ability to generalize across different classes:
- Random sampling
- Oversampling
- Undersampling
Synthetic Data Generation
Synthetic data generation is another effective strategy, especially when data collection is challenging or expensive. ML engineers can supplement their datasets without extensive data collection efforts by generating artificial data that mimics real-world conditions.
Feature Engineering
Feature engineering involves converting raw data into features that more accurately capture the core of the problem. It enhances your model’s predictive accuracy. Advanced feature engineering techniques include:
- Domain-specific feature extraction, where features are derived from expert knowledge in the field
- Automated feature engineering, where tools like Featuretools or TensorFlow’s TF.Transform are used to automatically generate features.
Focus on features that strongly correlate with the target variable while avoiding those that introduce multicollinearity or noise.
Data Annotation
At Label Your Data, we understand that precise and consistent data annotation is the cornerstone of any successful supervised learning model. Accurate labeling ensures that the model learns from the correct examples. It is imperative when dealing with complex or domain-specific datasets.
Don’t let poor data labeling hold your model back. Partner with Label Your Data to ensure precise, consistent annotations that drive better model performance.
Active Learning
Active learning is a method that enhances the data annotation process. By pinpointing the most informative samples for annotation, it minimizes the need for mass labeled data while boosting model accuracy. Additionally, annotation tools that support collaborative workflows and quality assurance mechanisms are vital in maintaining high data quality standards.
Supervised Learning Model Selection and Training
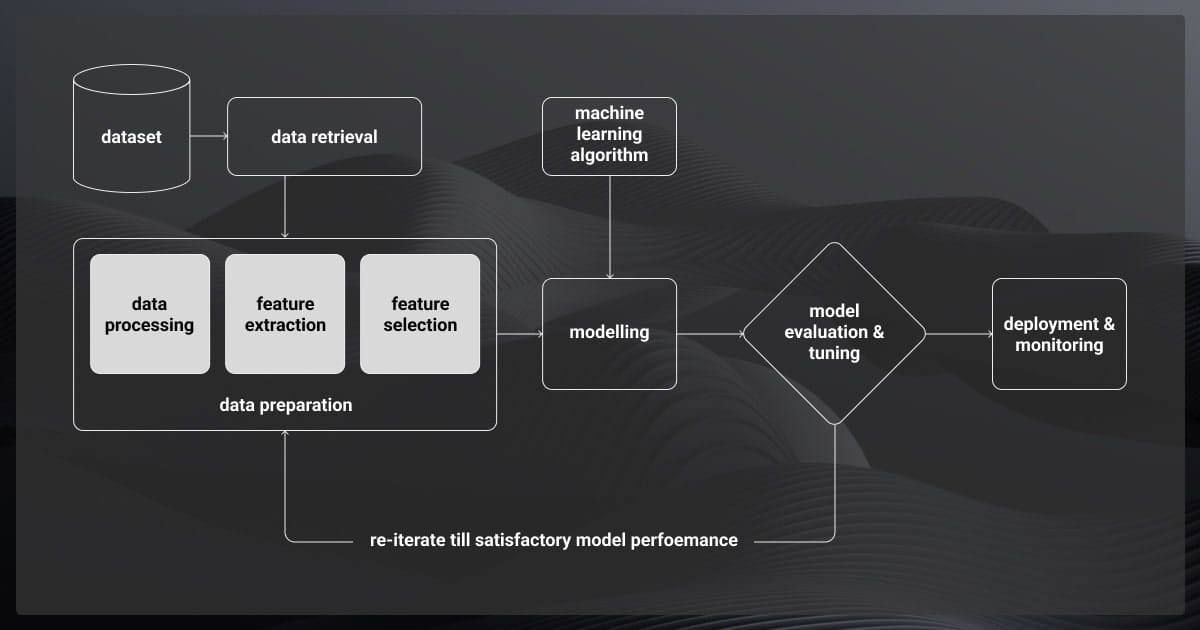
Selecting and training the right supervised model impacts its performance and scalability. Here are the best practices that can help you at this stage:
Algorithm Selection
The algorithm selection process should consider model complexity, interpretability, and scalability factors. While deep learning models like Convolutional Neural Networks (CNNs) are powerful for image classification tasks, they may not be the best choice for projects with limited computational resources or where model interpretability is a priority.
In 2024, the trend is toward hybrid models that combine the strengths of different algorithms, such as blending decision trees with neural networks or incorporating unsupervised learning techniques into a supervised framework. This approach can yield better performance by leveraging multiple methodologies.
Hyperparameter Tuning
Hyperparameter tuning is the process of finding the optimal set of hyperparameters to enhance model performance. Conventional methods like grid search or random search often require significant time and computational resources. In contrast, advanced techniques like Bayesian optimization or automated machine learning (AutoML) platforms offer a more efficient way to explore the hyperparameter space.
AutoML Tools
AutoML tools, such as Google Cloud AutoML or H2O.ai, are handy for ML engineers who need to iterate through different model configurations quickly. These platforms automate the process of model selection, hyperparameter tuning, and feature engineering. This way, engineers can dedicate their time to higher-level strategic decisions.
Training Efficiency
Training large supervised models can be resource-intensive, but there are several strategies to optimize training times:
- Distributed training. The approach where the training process is parallelized across multiple GPUs or TPUs, reducing the time required to train complex models
- Hardware accelerators. TPUs (Tensor Processing Units) can speed up training processes
- Resource-efficient model architectures. They can be found in lightweight neural networks (e.g., MobileNet) and reduce computational overhead without sacrificing performance
Handling Overfitting and Model Generalization in Supervised Learning
Achieving high accuracy on training data is only part of the challenge in supervised learning. You also need to ensure that your model generalizes well to unseen data.
Overfitting is a common issue that ML engineers must address when developing models. This means dealing with a model that performs great on training data but poorly on new data. Here are some techniques to help you address this issue:
Regularization Techniques
Regularization techniques are essential for mitigating overfitting. The key methods here include:
- Dropout: Randomly drops units during training.
- Batch Normalization: Normalizes the inputs of each layer.
- L2 Regularization: Helps prevent the model from becoming too complex and overfitting the training data.
Apply these techniques judiciously, balancing model flexibility with the need for generalization.
Cross-Validation Strategies
Cross-validation is a crucial method for assessing how well a model can generalize to new, unseen data. A commonly used approach is k-fold cross-validation, where the dataset is split into k parts. The model is trained and validated k times, with each part serving as the validation set once.
When dealing with imbalanced datasets, stratified cross-validation is especially useful because it keeps the distribution of the target variable consistent across all folds. For sequential or time-dependent data, time-series cross-validation is the preferred method, as it ensures that the temporal sequence of data is preserved, which is vital for reliable model evaluation.
Ensuring Generalization
To achieve robust generalization across various domains, techniques such as transfer learning and domain adaptation can be highly effective:
- Transfer Learning: This approach utilizes a pre-trained model on a new, but related, task. It significantly reduces the need for extensive data and computational resources during training.
- Domain Adaptation: This method involves refining the model to perform effectively on data from different domains, even when there are differences between the training and target data distributions. It is particularly useful in situations where labeled data in the target domain is limited.
Model Evaluation and Interpretation
After training a supervised learning model, it's crucial to evaluate its performance to gain insights into its behavior. Effective evaluation and interpretation practices are essential for uncovering the model's strengths and addressing any weaknesses.
Advanced Evaluation Metrics
Accuracy alone isn't enough to assess model performance, especially with imbalanced datasets. Metrics like the F1-score, which balances precision and recall, offer a more detailed evaluation. The AUC-ROC curve is also helpful for understanding the trade-off between true and false positives at various thresholds.
Precision-recall curves are particularly valuable when the positive class is critical, as in medical diagnoses or fraud detection. Choosing the right evaluation metrics is key to accurately evaluating your model.
Model Explainability
Supervised machine learning models grow more complex. Hence, the demand for model explainability rises. Tools like SHAP and LIME assist ML engineers in interpreting model predictions, making it easier to spot biases and comprehend the model's decision-making process. Beyond being a technical necessity, explainability is crucial for regulatory compliance, particularly in industries like finance and healthcare, where transparency builds trust with stakeholders.
Ethical Considerations
In 2024, ethical considerations are at the forefront of machine learning. As an ML engineer, you often address issues such as fairness, bias detection, and transparency in supervised learning. This involves using tools to detect and mitigate bias and being proactive in designing models that prioritize ethical considerations from the outset.
Incorporating fairness into model training and evaluation processes ensures that your models are equitable and just, particularly in applications that impact people’s lives.
Ready to elevate your supervised learning models? Our experts provide secure, high-quality training data you need for accurate model predictions. Contact us to learn more!
Deployment and Monitoring of Supervised Learning Models
This critical step ensures the value created during model development translates into real-world impact. Proper deployment practices and robust monitoring and maintenance strategies are essential for sustaining model performance and reliability over time.
Deployment Best Practices
In addition to careful planning and execution, deploying supervised learning models into production requires the following tactics:
- Model Versioning: Track changes in model parameters and architecture to maintain a clear history of model iterations.
- Containerization: Utilize tools like Docker to ensure models are deployed consistently across different environments.
- CI/CD Pipelines: Automate the deployment process with Continuous Integration/Continuous Deployment (CI/CD) pipelines to enable rapid and reliable updates to production models.
- Maintain High Availability: These practices are essential for sustaining high availability and performance in production systems.
Monitoring and Maintenance
After deployment, models need continuous monitoring to ensure they maintain their expected performance. Drift detection is key to spotting changes in data distribution that could affect model accuracy. Retraining schedules should be established based on the frequency and magnitude of detected drift, ensuring the model remains accurate and relevant.
Anomaly detection systems can alert ML engineers to unexpected behavior in the model’s predictions. It allows for prompt investigation and remediation. Regular maintenance is essential for long-term model reliability. It includes updating training data and retraining models.
Scalability Considerations
Scaling supervised learning models to handle large-scale data in real-time applications is challenging. Techniques such as distributed computing, microservices architecture, and horizontal scaling can help manage the increased load. It’s also essential to optimize model inference times. It ensures that predictions can be made quickly and efficiently, even at scale.
In some cases, simplifying the model architecture or using model compression techniques can reduce the computational burden. Scaling the model across multiple servers or cloud instances makes things easier.
Run a free pilot with us to learn how we can support your supervised learning project.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is supervised vs unsupervised learning?
Supervised learning trains models using labeled data, where the correct output is provided, enabling the model to learn the relationship between inputs and outputs. In contrast, unsupervised learning works with unlabeled data, where the model discovers patterns or structures without specific guidance on what the output should be.
What are the two 2 types of supervised learning?
The two main types of supervised learning are classification and regression. Classification tasks involve predicting discrete labels (e.g., spam or not spam), while regression tasks involve predicting continuous values (e.g., house prices).
Is PCA supervised or unsupervised?
Principal Component Analysis (PCA) is an unsupervised learning method used for dimensionality reduction by transforming data into a set of orthogonal components.
What is the role of data annotation in supervised learning?
Data annotation is crucial in supervised learning as it provides the labeled examples needed to train the model. Accurate and consistent annotation directly impacts the model’s ability to generalize from the training data to unseen data.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.