Everything You Need to Know About Bias in Machine Learning

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

As humans, we tend to label and categorize the world around us to make it easier to distinguish things. However, when the same labels or features confound decision-making (either human-driven or suggested by an algorithm), we are faced with stereotypes and biases. They, in turn, inevitably become part of the technologies humans create in many different ways.
What risks does this pose to machine learning? Well, there is no such thing as a perfect machine learning model. And while there are many common issues that ML specialists have to deal with, one of them disrupts the model’s accuracy the most. What’s this biggest concern in ML today? Bias.
Bias is a complex issue in ML, and there’s no universal cure-all. It all starts with humans involved in building the model and the data they use to train it. But, most importantly, it starts with us being aware of the problem and looking for ways to eliminate bias in machine learning. Why? Because technology should work for everyone.
In this article, we’ll take a look at the crux of the problem of biases in ML and see what it takes to prevent the models from perpetuating harmful human bias in machine learning (or not). Keep reading to find out more!
Biased Data or Biased Humans Issue?

This is arguably the most important question to ask while learning about bias in machine learning. We’ll try to address it by exploring all the intricacies of this issue. But first, let’s go through the definition of data bias in machine learning.
Machine learning is based on the idea that systems can learn from data, identify patterns, and make decisions with minimum or no human intervention at all. Usually, we have input data, algorithms that learn from this data, and the actual ML task to perform (e.g., forecasting, recommendation, classification). What can possibly go wrong here?
Say you have a dataset for training a recommendation system for retail. The dataset predominantly includes purchasing patterns from a specific demographic group, forcing the model to unintentionally favor that group. This will result in biased recommendations that overlook the preferences of other customer segments. So, in data annotation in retail, it’s essential to be mindful of potential biases that can emerge.
Machine learning bias, aka algorithm bias or AI bias, is a type of systematic error that happens in ML models as a result of faulty assumptions made throughout the learning process. Technically speaking, it’s an error between the average model prediction and the ground truth. Bias also demonstrates how well an ML model corresponds to the training dataset:
- A high-bias model fits poorly with the training dataset (underfitting)
- A low-bias model closely matches the training dataset (overfitting)
Bias is the phenomenon that compromises the outcome of the algorithm. This means that a particular ML method applied is unable to capture the true relationship between the data and the learning curve of an ML algorithm. That said, if you feed your model with biased data, you’ll get bias in predictions. This leads to incorrect model performance and skewed results.
To avoid such adverse data-related consequences in your AI project, send your data to our team at Label Your Data! Because it all starts with the right data in machine learning.
Bias vs. Variance

Don’t get these two mixed up. Bias and variance are two interrelated (yet, inversely linked) elements that must be considered when developing an accurate and effective ML model. Variance indicates the changes in your ML model when different portions of the training dataset are applied. As a rule, you want to limit bias to a minimum while providing appropriate amounts of variation. This can be achieved by increasing the complexity of a model or a training dataset, allowing for an appropriate ML model.
Tracing Bias at All Stages of Machine Learning Life Cycle
Humans, by nature, are biased. In this sense, the world around us is biased as well, which directly affects the sophisticated systems that we create. Given that the main idea behind a machine learning model is to mimic human observations of this world, it’s no wonder that ML models also absorb our tendency towards bias throughout all stages, starting from data collection and annotation.
Even the subjective nature of human-led data annotation can introduce bias, influencing how models interpret and generalize from labeled data. However, properly trained annotators can deliver expert text, audio or image annotation services, avoiding any inconsistencies in labeling objects for best model performance.
Bias is and must be considered a major problem in machine learning, since it undermines the decisions or predictions that machines make. As a result, we risk trusting the inaccurate results of the model, which might seriously harm one’s business or even life.
How does bias affect each stage of the ML development life cycle?
- Data. Imbalances in data associated with class labels, features, or input structure, can result in unwanted biases.
- Model. The lack of unified uncertainty, interpretability, and performance metrics promotes bias.
- Training and deployment pipeline. Feedback loops reinforce and perpetuate biases in the model.
- Evaluation. The lack of systematic analysis of variance and performance across different demographics and data subgroups.
- Human interpretation. Because humans evaluate the outcomes and the decisions of the model and make judgments, they can inject human error and impose their own biases, distorting the meaning and interpretation of these results.
Machine learning is based on the premise that machines can learn the rules and patterns from examples on their own. These examples are past human decisions and the information about the subject (data) on which they made their judgment. This type of data is known as training data because machines use it to learn and make decisions in the same way that humans do.
The technology picks up on bias from the examples that are shown to it by humans. Thus, it makes sense that an ML model can be often biased, too. When the example that a machine uses contains biased data or the judgments made with it, it’s automatically incorporated by the machine.
The Main Types and Examples of Data Bias in ML
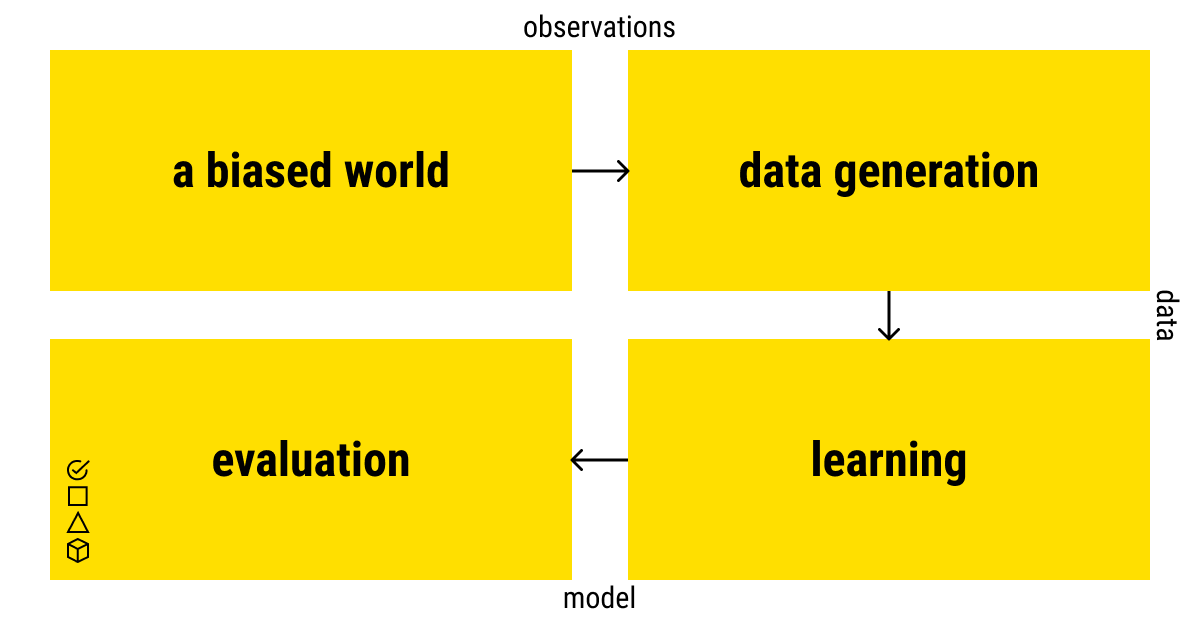
Bias enters an ML model through the data that was used to build it. Yet, data doesn’t collect and feeds itself into the model. It’s here that one can trace the human influence on the development of biased data, and biased ML accordingly.
Now, let’s take a look at the most prevalent biases in ML and their underlying causes! We are getting closer to solving the main mystery of bias in ML: is it the data or the humans?
- Data-Driven
- Selection bias: Data selections don’t reflect randomization (e.g., class imbalance)
- Sampling bias: Particular data instances are more frequently samples (e.g., hair, skin tone)
- Reporting bias: Data available to users doesn’t reflect the real-world likelihood (e.g., news coverage)
- Interpretation-Driven
- Correlation and causation fallacy: Drawing inferences about cause and effect merely based on observations of a relationship between variables
- Overgeneralization: Making more general conclusions from limited testing data
- Automation bias: AI-generated decisions are favored over that of a human
From a more detailed point of view, biases in machine learning are classified as follows:
- Specification biasBias in the choices and specifications, which represent the input and output in a particular ML task. Systems that are based on these choices, unintentionally or purposely biased, will demonstrate inaccurate performance and consistently disfavor protected classes.
- Measurement biasBias that comes from measurement errors. Each error refers to a different type of bias. Instrument error bias occurs due to faulty calibration, inaccurate measuring instruments, contaminated reagents, etc. Observer bias is a systematic disparity between a correct value and the value actually perceived. Bias among study investigators regarding a conclusion, exposure, or outcome, is known as investigator bias.
- Sampling biasBias that arises when there is an underrepresentation or overrepresentation of observations from a segment of the population. Also known as selection bias, or population bias, it might lead to a classifier that performs only for certain demographic groupings or poorly overall. In a dataset, sampling bias can occur for a variety of reasons (e.g., self-selection bias, dataset bias, survivorship bias).
- Annotator biasBias associated with the manual process of data labeling. Human annotators might pass on their own prejudices to the data that they work with, and that is further used to train a model. However, when there’s automated data collection, and the labeling process is automated or semi-automated as well, annotations are read from the real world and might cause historical bias.
- Inherited biasML-enabled tools are frequently used to produce inputs for other machine learning algorithms. If the output is biased, it can be inherited by other systems that use this output as input to train other models (e.g., word embeddings). Despite different bias mitigating methods, it may still remain and continue to affect other models relying on the biased output.
With this list in mind, we hope you can better understand and think of different types of bias in machine learning and what are their main root causes.
However, if you want to save yourself the trouble of learning these details and get started on creating an ML project faster, get professional support. Run your free annotation pilot from Label Your Data!
Bias in Data Analysis
In this case, bias starts with humans, who use unrepresentative datasets and biased reporting and measurements. Bias in the data analysis often remains unnoticed and bears many negative consequences, including bad decisions that influence certain groups of people involved in this process. Underlying all of these problems is a lack of focus on the purpose of the analysis.
- Maintenance of the status quo
- Wrong training goals (model accuracy vs. business impact)
- Underrepresented groups
- Outlier bias
- Cognitive biases
- Analytics bias
- Faulty interpretation
- Confirmation bias
How to Avoid Bias in Machine Learning Algorithms?

Now that we are familiar with the different examples and types of bias in machine learning models, it’s time to learn about bias mitigating strategies to avoid them when building new ML models in the future.
Let’s say you are working on a facial recognition algorithm. Your main goal is to get accurate recognition of human faces of different skin tones and make sure your model performs correctly. To do this, you want to check if your labeled data is biased, and ensure that it can be eliminated once detected. This can be done either independently, or by hiring facial recognition services that provide international teams able to accurately identify individuals with different skin tones or ethnicities. This way, you can easily address the disparities in algorithmic decision-making.
Ignoring biases in your ML model will lead to inaccurate results, which, in turn, could jeopardize your entire AI project. Unwanted bias in ML models can be addressed with the following steps:
- Bring diversity to your dataDiversity is becoming increasingly important in AI. To mitigate bias in data, algorithms, and models, it’s necessary to maintain diverse tech teams in the AI industry and look at the issue from multiple perspectives. This will ensure the cross-cultural approach to creating and deploying ML and help avoid subjectivity.
- Avoid proxiesRemoving protected class labels (e.g., race, sex, skin tone) doesn’t seem like the most reliable method to eliminate bias in ML. There are several ways to deal with bias without removing labels, including technical tools.
- Recognize technical limitationsWith biased data on hand, it becomes obligatory to understand the possible limitations of this data, model, and technical solutions to address bias in ML. Human techniques to mitigate bias, such as human-in-the-loop, prove to be a feasible strategy.
- Use the toolsThe debiasing tools are far from perfect in minimizing machine learning bias, yet they prove to be quite beneficial for improving the model outcomes and providing more accurate and trustworthy predictions. What are these tools?
- AI fairness 360 tool by IBM to help create bias-free ML models
- TensorFlow by Google to detect biases in an ML model
- FATE by Microsoft research group to examine social implications of AI
TL;DR: Let’s Bring Some Diversity to Machine Learning

Biases divide humans and creep into technologies that we create. Biased machine learning poisons the model outcomes and provides us with skewed and even racist predictions. We aim to build the systems to rely on, not to fear. What’s the solution?
While delving into the issue of data bias in machine learning, we see that the need for diversity in AI comes to the fore. For any data endeavor, it’s critical to be aware of the potential biases in machine learning. One might detect it before it becomes a serious concern or respond to it timely by putting the correct processes in place. This will help everyone involved stay on top of data gathering, annotation, and implementation.
ML is an iterative process, and exploring all its issues is a long journey to take. Contact our team of annotators at Label Your Data to get professional support for your journey in AI!
FAQ
What causes data bias?
Data bias emerges when an information set is inaccurate and fails to represent the entire population. This leads to skewed or unrepresentative outcomes in data analysis, making the ML model unreliable. Hence, data bias must be detected and eliminated promptly.
What is an example of bias in ML?
An example of data bias in machine learning is when a facial recognition system can start to be racially discriminatory, or a credit application evaluation system can become gender-biased, illustrating instances where biased training data leads to unfair outcomes.
When an ML model has high bias?
A machine learning model is prone to high bias when it oversimplifies the underlying patterns in the data. When an ML model has high bias, it will not be able to capture the dataset trend, resulting in underfitting and inadequate performance.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.