The Potential of Machine Learning in the Stock Market

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

Ever since the first appearance of artificial intelligence in business, people have understood that its capabilities in predictive analytics are a perfect fit for the most complex areas of human activity, such as the stock market. There’s no surprise that stock trading is done primarily by bots today, and that it relies heavily on the predictions sometimes obtained from machine learning algorithms.
However, the question of the efficiency of such algorithms is still under close regard. Is the theory of random walk true? Do ML models for stock prediction really work? And if they do, how well do they actually perform?
We don’t try to answer these questions definitively, as there is no definitive answer yet. Still, we’ll give an overview of how machine learning in the stock market works and how such algorithms are being built. We’ll also take a crack at the discussion: is it a good idea to use ML for stock trading, and what risks does such an endeavor bear?
Machine Learning and Stock Trading: How Does It Work?
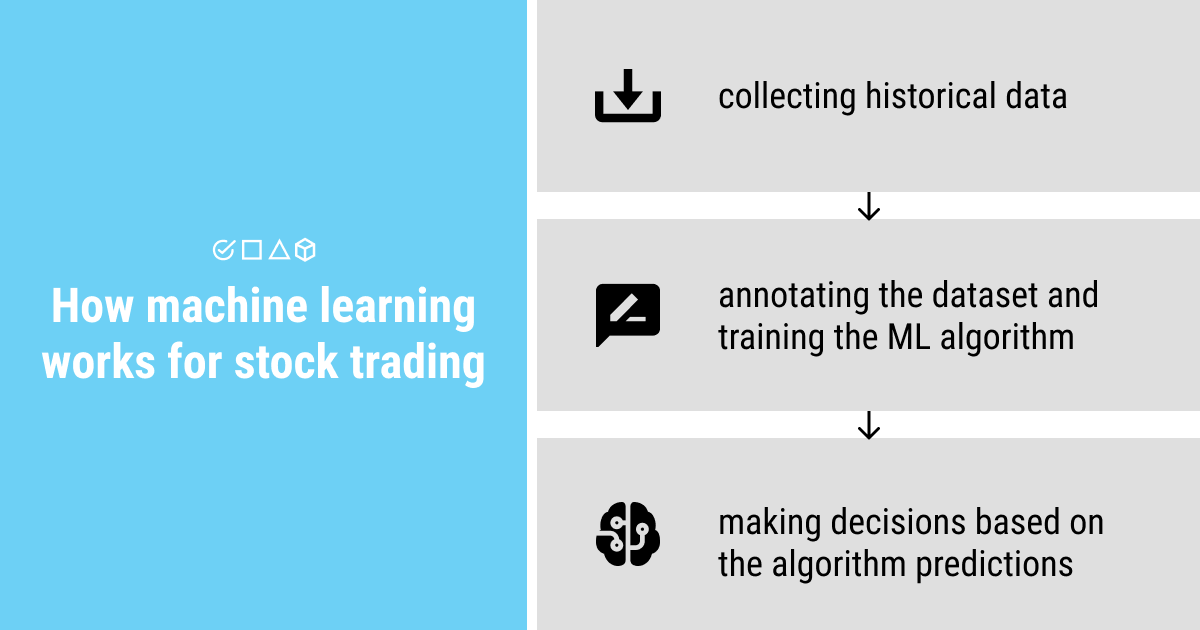
Building machine learning algorithms for trading has been a challenge that a lot of data scientists and ML engineers have pursued over the years. Empirical evidence suggests that such algorithms can be successful for automated stock trading.
This is naturally due to the highly detailed historical data from a variety of companies and stock exchanges. In itself, such data usually represents an already processed and pre-annotated dataset that can be used to train an ML algorithm. As the algorithm learns to see the hidden patterns in the historical data you feed into it, it can analyze them and offer predictions about how the stock prices will change in the near future.
However, there’s still a debate about:
- how successful the ML algorithms for stock trading are, and
- how far into the future these algorithms can predict.
The nature of the debate relies on the foundation of the axiomatic argument that the stock market is inherently unpredictable. The reason behind this is, on the one hand, the multiplicity of variables that contribute to the changing stock prices, starting with the economical, political, and sociological factors and ending with environmental changes and natural disasters. On the other hand, there’s also the irrational behavior of active agents, which makes it virtually impossible to predict the status of the stock market in the long term.
What this means in practice is that modern algorithms used for machine learning in stock trading are never simple. They require a lot of knowledge of how the stock market works and the implementation of more sophisticated, non-linear algorithms. That’s why deep learning models have become the most popular solution for stock trading today.
Deep Learning for Stock Trading
There are quite a few ways to design an ML model for stock trading using linear methods, such as moving average, linear regression, k-nearest neighbors, decision trees, etc.
However, given the complexity and multifactorial dependencies of the problem of stock price prediction, deep learning obviously fits the challenge better. Deep learning models like CNN, RNN, and especially LSTM outperform linear models.
Why? Because of the nature of artificial neural networks. The inspiration for them came from how the human brain works. Neural networks are capable of transferring the analyzed data from one layer to the next one, thus making the training and analytical process much more efficient than in the case of linear ML models.
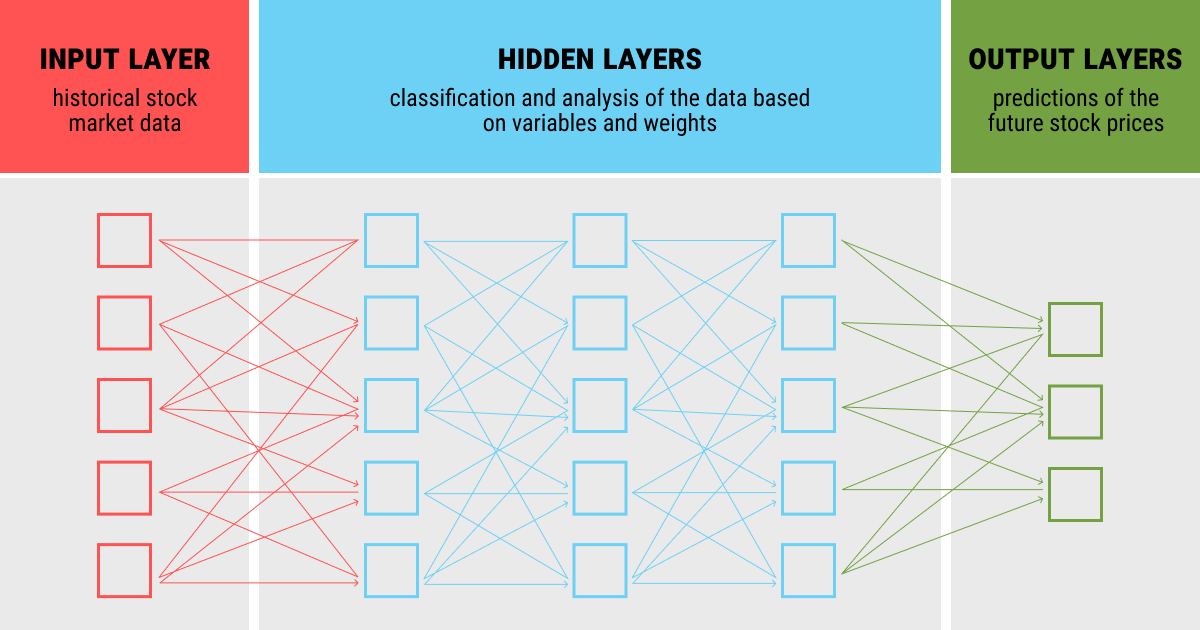
In a nutshell, a neural network consists of multiple layers that analyze and then pass the data from one layer to the other. Any neural network consists of:
- An input layer (in the case of the stock market, historical data about stock prices of certain companies at a specified time period)
- An output layer (prediction of the future stock prices)
- Hidden layers in between (each of which can be considered a single linear algorithm such as linear regression)
As you feed your data into the model (input) and add weights to each piece of data, the first layer analyzes the input based on different variables and weights. Then, as the set threshold of the layer is reached, this data is passed to the next layer, which continues to learn based on the data plus the previously obtained analysis. Such a chain of layers is very efficient and allows making complicated calculations in minutes rather than hours or even days it would take a human expert.
Here are a few types of neural networks that can be successfully used for designing the stock trading algorithms:
- Convolutional Neural Networks (CNNs) are great for pattern recognition and are commonly used in computer vision tasks.
- Recurrent Neural Networks (RNNs) have feedback loops, which makes them a great choice for time series problems. Stock market prices are one such problem, so RNNs have traditionally been used to predict future prices.
- Long Short-Term Memory (LSTM) is a type of RNN that is well-suited for stock market predictions as the important events that have high weights are not regular and there can be lags of uncertain duration between them.
To Use or Not to Use Machine Learning Algorithms for Stock Market Predictions?
There’s an obvious reason why you’d want to use machine learning for stock prices prediction: automated financial gains. As you build a sophisticated ML model and train it on the historical data of certain companies, your goal is to get consistently accurate predictions on stock prices.
Choosing the right machine learning algorithm and tools obviously offers a great solution for this kind of task. The stock market is notoriously volatile. The number of mutual dependencies with other areas of human life is huge. Taking all of these into account is virtually impossible for a human being. On the other hand, ML-based tools have revolutionized the way traders approach the stock market, enabling them to make data-driven decisions with greater accuracy and speed.
More specifically, natural language processing (NLP) models offer potential benefits in the stock market. By performing tasks like sentiment analysis, news analysis, and prediction modeling, they can help investors make more informed investment decisions and better manage risk. A great example of a language model is ChatGPT.
Although a trained AI model, ChatGPT, lacks access to real-time market data and internet browsing capabilities, it can still be utilized in unique ways. For example, you can prompt ChatGPT to generate code for forecasting stock prices. However, achieving the highest level of accuracy in its output requires addressing various nuances. Caution is advised, as a rogue version of ChatGPT once produced a false prediction of a stock market crash, highlighting a significant issue with the technology.
Despite the shortcomings, a machine doesn’t have to sleep or rest. It can work on a vast amount of data and analyze it much faster than any human being could. What a machine cannot do is make decisions based on the analysis without the specific input from humans. To deliver accuracy, ML algorithms need to be properly trained to understand what kind of patterns you’re looking for. The problem is, there may be too much randomness that interferes with patterns and throws off any analysis.
Problems and Risks of Machine Learning Stock Trading: Are the Stock Prices Unpredictable?

Stock Market Volatility
The stock trading experts are well acquainted with the random walk theory that defines the stock market as uncertain at its core. It’s not stationary but changes all the time. And while there are variables that can be predicted and taken into consideration, there are also factors that cannot be taken into account before they happen, such as natural disasters.
Even more importantly, the agents making decisions based on the machines’ analysis are people and thus prone to irrational behavior and/or making mistakes. Such irrationality by definition cannot be part of the ML analysis.
Decreasing Accuracy
It’s worth noting that ML in the stock market is quite capable of delivering accurate predictions for the changes in stock prices. However, in the forecast horizon, the bias increases: the further in the future you want to predict, the less accurate results you’ll probably get.
The models on average offer more optimistic results for the more distant events. So the analysts need to update them (usually by downgrading to more pessimistic predictions) as these events are near.
High Competition
In practice, this means that the unpredictability of the stock prices can be somewhat negated in the comparatively short term. However, it’s worth remembering that the stock market is an area of high competition.
Other agents build other machine learning models that quickly adapt to the changing market conditions. Any change that your model might have that adds a competitive edge to it will soon be replicated by other models.
This is due to the fact that only the new news can be exploited for a competitive edge. As the news becomes better known, other models take them into consideration for their predictions, thus leveling the discrepancy that initially allowed gaining a competitive edge.
Training Data Density
Furthermore, it’s important to consider the density of training data. While there seems to be more than enough historical data available for ML algorithm training, the fact is that it’s insufficient as its density increases slowly.
This is due to the flexibility and mobility of the stock market historical data. Predictions at scale come at the price of the decreased accuracy of the machines’ analysis and the high risk of unfounded decision-making.
Summary: Unleashing the Power of Predictive Algorithms

The automation of stock market predictions has always been an enticing and challenging idea. Ever since artificial intelligence appeared, it became obvious that it’s well-suited for such complex predictions.
Today, most trading is done via bots and is based on calculations from machine learning algorithms. Deep learning neural networks such as CNN, RNN, and LSTM are commonly used for stock trading models as they have increased capacity and efficiency compared to linear algorithms.
However, there’s still a question of whether such algorithms are truly effective. As the stock market is notoriously volatile, a considerable amount of effort is required to design a working ML algorithm. There are a few things to keep in mind when using machine learning for stock trading:
- Follow the scientific method. Make sure your process is based on a thorough understanding of the random nature of the stock market and that it takes into consideration the range of performance outcomes. The high-frequency models commonly tend to disagree on the future stock prices.
- Mind the high competition when planning the competitive edge. While there is a possibility to gain the upper hand by exploiting the information no one else knows about, you should not rely on it entirely. Other models will catch up and adapt sooner than you think.
- Don’t look too far into the future. Increasing the capacity of the machine learning model leads to a drop in performance. The further you want to predict the future stock prices, the less accurate your predictions will get.
Following these tips will not automatically solve all problems connected to building effective stock market ML models. There’s also the issue of high-quality data and high-quality annotation. Feeding your model with subpar data will lead you nowhere, even if you follow all the above tips and design the top-performing algorithm.
FAQ
Can we use AI to predict the stock market?
With the incredible capabilities of modern technology, we can harness the power of AI to predict the stock market through complex technical analysis. By analyzing stock movements and patterns to predict their future performance, one can attain an exceptional level of accuracy.
Which machine learning algorithm is best for stock prediction?
There is no single “best” machine learning algorithm for stock prediction, as the performance of different algorithms can vary depending on the specific problem and data.
Will AI replace stock traders?
In the near future, the trader will not become obsolete. Nevertheless, as machine learning models improve at generating precise predictions based on data, their functions are expected to become more focused.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.