Zero-Shot Image Classification: A Must When Data Is Limited

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

Computer vision is a life-changing technology. But the problem is that computer vision (CV) models are only as good as the annotated data used for their training. They can understand the visual world based on this data, yet they struggle to generalize beyond it.
Say you want to build a model performing image classification of rare species in wildlife. Unless you’re leveraging expert image classification services, getting extensive labeled datasets for regular training is particularly tricky. The main issues arise when the model faces new classes or images outside their training domain. This begs the question: what to do when the access to labeled datasets is limited?
There’s a better option out there — zero-shot image classification. It’s more flexible and usually doesn’t require a lot of retraining, making it a more versatile solution for computer vision. Interested in learning more about zero-shot learning (ZSL) and how it can be used in image classification? Then keep reading this piece.
What Is Zero-Shot Learning and How to Use It in Image Classification?
What’s an ideal computer vision model? Having provided expert computer vision services for over a decade now, we think it’s the one that goes beyond merely recognizing basic labels in images. Case in point, you have an image of a child holding a balloon. The ideal AI image recognition model should not only identify the child in this photo but also comprehend additional details. They might include surrounding trees, birds, the time of day, and, of course, the balloon itself.
However, the usual training for image classification focuses on assigning images to specific categories (or a specific set of labels). This means traditional image classification overlooks the broader contextual information in the visual data. Some can say that retraining the model is a viable option. But how about significant time and financial resources it requires for the dataset collection and model training?
Well, we’re getting closer to revealing what is zero shot learning in image classification. You can also read our article where we compare image classification vs. object detection to explore other computer vision techniques. Now back to the main topic.
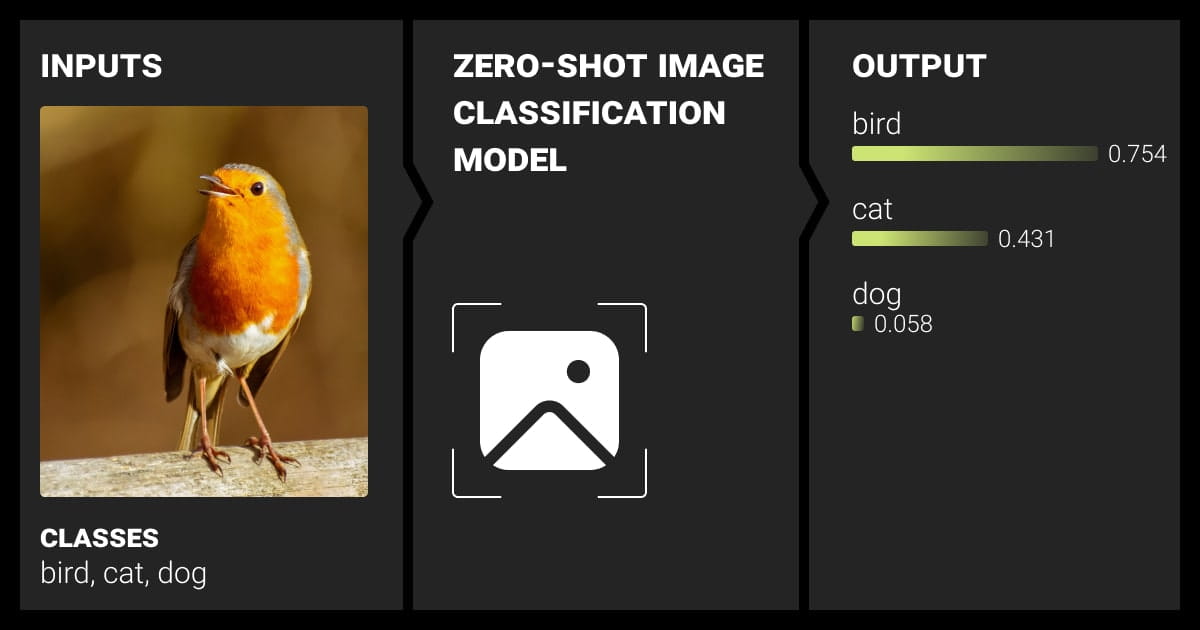
To put it simply, zero shot image classification means figuring out what’s in an image without being explicitly taught about certain things in that picture. It’s like the machine looks at lots of images and their descriptions to learn how to understand them, even if it hasn’t seen those exact pictures before.
Breaking Down the Zero-Shot Learning Image Classification Pipeline
Now that we know what zero-shot learning is, it’s time to explore how it works, the required data, and the key approaches to building these types of image classification models.
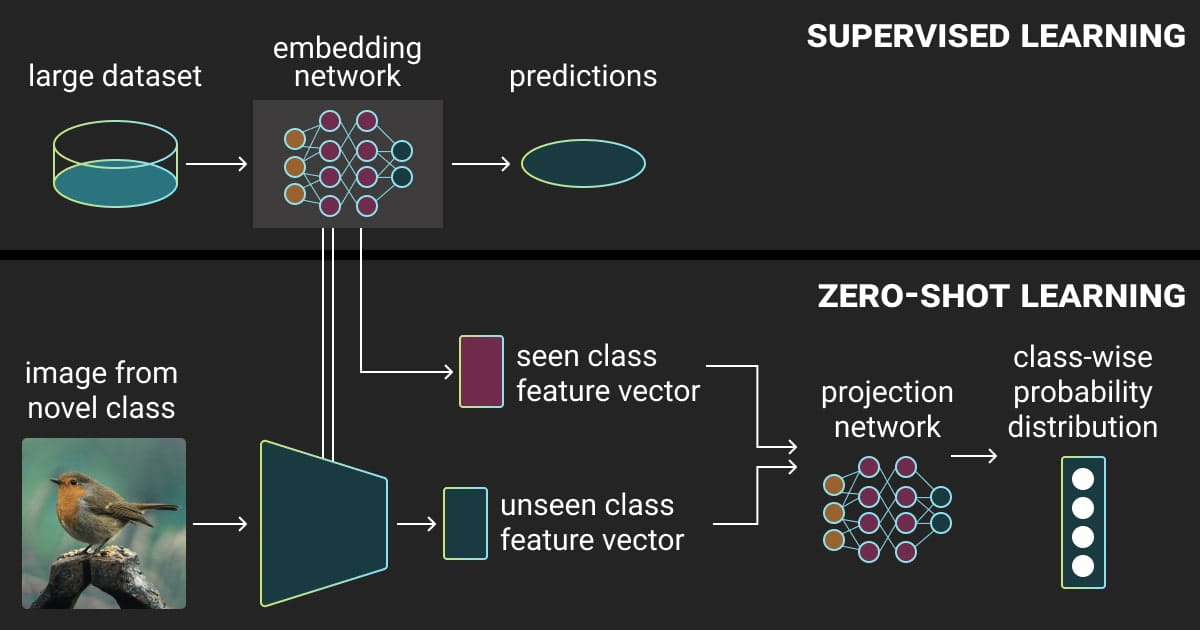
Zero-shot image classification is more flexible because it lets CV models understand and sort categories they haven’t seen before. Plus, it doesn’t require any additional training data. With zero-shot learning in image classification, the model is taught to recognize and categorize objects or scenes it hasn’t encountered while learning.
Unlike a regular model that can only classify specific things it was trained on, the zero-shot model learns how to deal with new categories by figuring out connections between categories it knows and ones it doesn’t. This typically includes connecting meaning or information about the categories, like using text descriptions or characteristics. When the model faces a new category in its predictions, it can use what it learned from these connections.
Data for Zero-Shot Learning (ZSL) in Image Classification
Considering the diverse classifiers in ZSL, including a binary, a general, and a multi-class zero-shot classifier, it’s essential to discuss the nature of the data used. This includes scenarios where classifiers need to generalize to new and unseen classes during image classification tasks.
In zero-shot learning, the data is typically split into three categories:
- Seen DataThis includes data classes used for training the CV model, consisting of images and their respective labels.
- Unseen DataThese are classes that the model must classify even though there was no specific training on them. This includes only labels, without images.
- Auxiliary InformationThis is extra data given to the model during training, establishing a connection between the seen and unseen data. This additional information, presented as textual descriptions, semantic information, or word embeddings, includes details about all the unseen classes. It is crucial for solving the zero-shot classification problem, since there are no labeled examples available for the unseen classes.
Our computer vision services at Label Your Data range from semantic segmentation, 3D cuboids, and key points, to OCR annotation services and even LiDAR data annotation. Get in touch with us to find the service you need for your computer vision project!
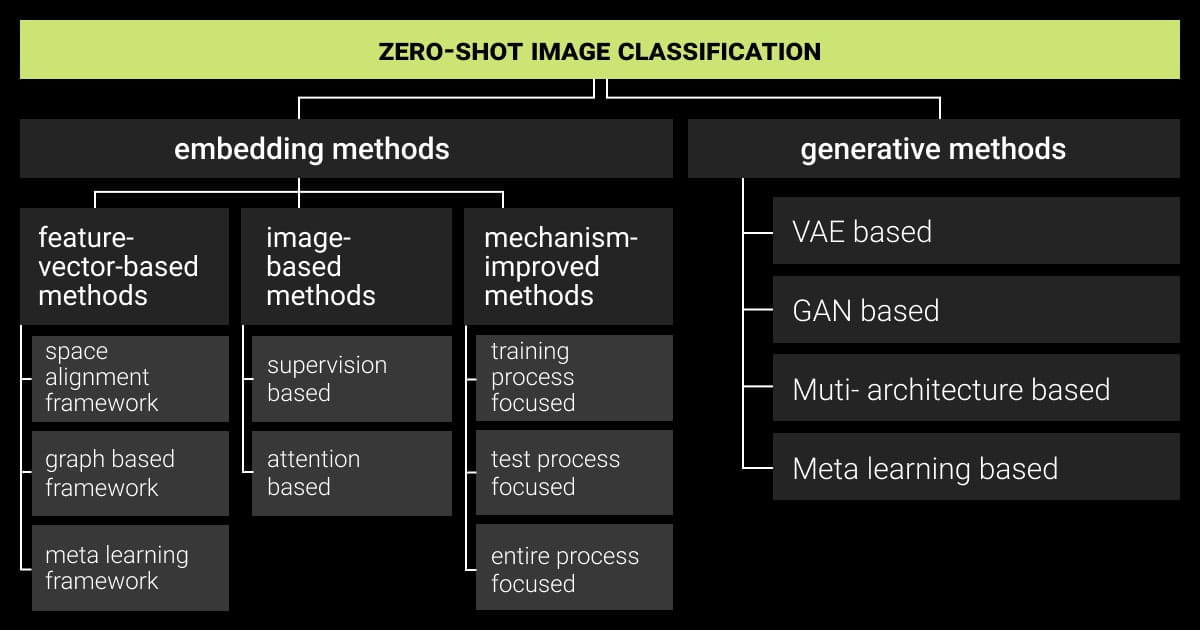
Key Methods for Zero-Shot Image Classification
Now, let’s delve into the specifics of two prevalent methods employed to address the challenge of zero-shot image classification:
Embedding-Based Methods
Embedding-based methods aim to establish a common embedding space through a projection function learned through deep networks. This space may represent visual features, semantic attributes, or an intermediary dimension. One common method uses the semantic space as this shared space. During training, it learns how to map visual features (i.e., what's in an image) to semantic space (i.e., word meanings) using data from known classes.
Neural networks, serving as function approximators, are employed to formulate this projection function. During testing, unseen class image features are inputted into the trained network, generating semantic embeddings. Classification involves a nearest neighbor search in the semantic attribute space, determining the closest match to the network’s output and predicting the label associated with that semantic embedding.
However, embedding-based methods can be biased and shift domains. The problem stems from learning the projection function solely from known classes during training. This impedes the model from correctly categorizing objects. Such a limitation becomes evident during testing, where accurate mapping of features from unseen classes to the correct semantic space is uncertain.
Generative Model-Based Methods
To address the limitation of the previous method, a zero-shot classifier must be trained on both known and unknown class images during training. In this case, generative model-based methods offer a solution by aiming to generate image features for unseen classes using semantic attributes. Generally, this process involves a conditional generative adversarial network (cGAN). It helps create image features by considering the semantic attributes associated with a specific class.
Much like the embedding-based strategy, the generative model takes the attribute vector as input. It generates an N-dimensional output vector based on the attribute vector. The model undergoes training to ensure that the resulting feature vector closely mimics the original feature vector. After training, the generator’s weights are fixed, and it is used to generate image features for unseen classes based on their attributes. With both known and generated unseen class features, a simple classifier can be trained to associate image features with their corresponding labels.
The Process of Zero-Shot Learning in Image Classification
Zero-shot classification involves two main stages: training and inference, particularly in the context of image classification.
- During the training stage, you can use Contrastive Language-Image Pretraining (CLIP) by OpenAI (a classification model requiring zero retraining). Instead of relying on labeled data, auxiliary information is used as a form of supervision to assist the model in learning. As the model encounters various image-text pairings, it gains the ability to distinguish and comprehend phrases, establishing a knowledge base through contrastive learning.
- In the inference stage, after completing the training, the model can make predictions based on its learned knowledge. To set up the classification task, a list of potential labels is created. For instance, in the classification of rare species in wildlife we’ve talked about in the beginning, a list of all species is generated. The encoding of each label is accomplished with a pretrained text encoder. Subsequently, images are fed into a pre-trained deep learning model, and the similarity between the image encoding and each text label encoding is gauged using cosine similarity. The image is classified based on the label with the highest similarity.
We hope this brief overview has demonstrated how zero-shot learning image classification is achieved through these two main stages.
But if you work with supervised learning, there’s no chance to build a high-performing model without well-annotated training data. Get an expert annotation team for your AI project today!
Final Thoughts on Recognizing Unseen Concepts with Zero-Shot Learning

In the beginning of this article, one question remained unanswered: how to deal with the limited access to labeled data when building an image classification model? We hope now you know the answer to this question by learning what is zero-shot classification.
Zero-shot image classification turns out to be a valuable solution to the challenges of scarce and labor-intensive training data. As the demand for extensive, labeled datasets in computer vision continues to grow across diverse domains, zero-shot learning will become indispensable.
FAQ
What is the difference between zero-shot and one shot classification?
In zero-shot classification, a model makes predictions on classes that were not seen during training. Zero-shot learning can be deployed in scenarios where the model has to learn new tasks without re-learning previously learned ones. Meanwhile, one-shot classification involves training a model with just one example of each class it needs to predict.
What are the advantages of zero-shot classification?
Zero-shot classification offers flexibility by predicting on unseen classes during training, and scalability by accommodating a growing number of classes without retraining the model.
What is a zero-shot language model?
In NLP, zero-shot prompting involves presenting a prompt that is not part of the training data to the model, but the model can generate a result that you desire. This technique enhances the applications of large language models across various tasks.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.