GPT Fine Tuning: ML Approaches Across Different Model Versions

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- What Is GPT Fine Tuning?
- Key ML Approaches for Fine-Tuning GPT Models
- How to Select the Right ML Approach for GPT Fine Tuning
- Tools and Platforms for GPT Fine Tuning
- Step-by-Step Guide to GPT Fine Tuning using OpenAI API
- Common Use Cases for GPT Fine Tuning
- Why Consider Outsourcing GPT Fine-Tuning
- About Label Your Data
- FAQ

TL;DR
- Fine-tuning GPT models customizes them for specific tasks, boosting relevance and accuracy.
- Key ML approaches include supervised learning, reinforcement learning, and transfer learning.
- Popular tools for fine-tuning are OpenAI API, Hugging Face, Azure AI, and AWS SageMaker.
- Fine-tuning enhances reliability and adaptability, making GPT suitable for specialized industry needs.
- Common use cases include customer support, handling complex prompts, and task-specific applications
What Is GPT Fine Tuning?
GPT fine-tuning is a process that tailors pre-trained language models, like OpenAI’s GPT models, to meet specific needs.
Think of it like teaching a model to specialize in certain tasks or topics. Instead of training from scratch, you take an existing GPT model and adjust it to perform better in a particular area. For instance, OpenAI reports that GPT 3 fine tuning can increase correct outputs from 83% to 95%, demonstrating significant improvements in task-specific accuracy. Additionally, fine tuning GPT 3.5 Turbo allows for handling up to 4,000 tokens, doubling the capacity of previous fine-tuned models and enabling more complex interactions.
Fine-tuning GPT models makes them more useful in specific industries.
For example, a fine-tuned customer service bot can respond more accurately with company-specific language, while in healthcare, models can be adjusted to understand medical terms. GPT models can also support automatic speech recognition by generating text responses to transcribed audio, and assist in image recognition applications by providing descriptive text for visual data.
Yet, LLM fine tuning has its challenges. You need large datasets for accuracy, which can be costly and time-consuming to create. It also requires strong computational resources, and without them, fine-tuning may take much longer. Sometimes, fine tuning GPT can lead to overfitting, where the model becomes too focused on specific data and loses its ability to generalize.
To address these challenges and get the best results, different machine learning approaches are used in fine-tuning to make GPT models more efficient and tailored to specific tasks.
Key ML Approaches for Fine-Tuning GPT Models
Did you know that training cutting-edge AI models like GPT-4 can cost up to $100 million? Fine-tuning these models to perform specialized tasks is essential for businesses wanting the best AI performance without such extreme costs.
Here are five key methods for fine tuning GPT models effectively:
Supervised Learning Fine-Tuning
Supervised learning fine-tunes GPT models with labeled datasets, helping the model learn to produce accurate outputs based on specific examples. This approach relies on data annotation to provide clear, labeled data, making it ideal when precise and controlled responses are needed. Many businesses use data annotation services to prepare their datasets efficiently.
- Uses: Effective for customer support, educational tools, and regulated industries.
- Advantages: High accuracy and control over responses.
- Best Practice: Use high-quality, relevant examples to avoid overfitting and ensure model reliability.
Reinforcement Learning (RL)
Reinforcement learning (RL) improves models by rewarding desired behaviors, making it useful for fine-tuning tasks where the model benefits from feedback-based improvement.
- Uses: Ideal for interactive applications like chatbots (e.g., fine tuning chatGPT) and conversational agents.
- Advantages: Enables continuous learning and adaptability.
- Best Practice: Regularly review and adjust reward settings for consistent improvement.
Reinforcement Learning with Human Feedback is a core strategy for achieving dynamic, relatable, and client-specific AI outputs that resonate. By continually adjusting the model based on real user interactions, we ensure that responses are not only accurate but also personalized and engaging, directly boosting user satisfaction and engagement.

 Partnerships Manager, Digital Web Solutions
Partnerships Manager, Digital Web Solutions
Transfer Learning
Transfer learning leverages pre-trained knowledge from existing models, making fine-tuning faster and more resource-efficient by building on what the model already knows.
- Uses: Suitable for domain-specific applications where general knowledge needs fine-tuning.
- Advantages: Saves time and computational costs.
- Best Practice: Ensure the model retains a balance between general and specialized knowledge.
Active Learning
Active learning targets challenging data points for fine-tuning, making the process more efficient by focusing on areas where the model needs improvement.
- Uses: Useful in data-scarce scenarios where labeled data is limited.
- Advantages: Reduces labeling costs by targeting only necessary data.
- Best Practice: Apply smart sampling techniques to maximize impact with minimal data.
Few-Shot and Zero-Shot Learning
Few-shot and zero-shot learning enable the model to adapt with minimal or no labeled examples, making it flexible for new tasks without extensive training data.
- Uses: Quick adaptations to new languages, tasks, or topics.
- Advantages: Saves time and resources, especially for rare tasks.
- Best Practice: Use for simpler tasks or when labeled data is unavailable.
Few-shot learning has revolutionized our approach to fine-tuning GPT models. This targeted approach allows for efficient model adaptation, producing impressive results without the need for extensive training data.
 Founder & SEO Strategist, Click Intelligence
Founder & SEO Strategist, Click Intelligence
How to Select the Right ML Approach for GPT Fine Tuning
Choosing the right ML approach for fine tuning GPT depends on several factors. Each project has different data needs, complexity levels, and resource constraints, so understanding these helps ensure the model is optimized effectively.
Here’s a table summarizing the factors to consider when selecting an ML approach for GPT fine-tuning:
| Factor | Consideration | Recommended Approach |
| Data Availability | Plenty of labeled data available | Supervised Learning |
| Limited labeled data | Active Learning or Few-Shot Learning | |
| No labeled data | Zero-Shot Learning | |
| Task Complexity | Simple tasks (e.g., FAQ responses) | Few-Shot or Supervised Learning |
| Complex tasks (e.g., interactive chatbots, chatGPT fine tuning) | Reinforcement Learning or Transfer Learning | |
| Budget Constraints | Low budget for computational resources | Transfer Learning or Active Learning |
| Higher budget, aiming for high customization | Supervised Learning or Reinforcement Learning | |
| Performance Goals | High accuracy and control | Supervised Learning |
| Flexibility and continuous learning | Reinforcement Learning | |
| Timeline | Fast adaptation needed | Few-Shot or Zero-Shot Learning |
| Longer timeline allows for in-depth training | Supervised Learning |
Tools and Platforms for GPT Fine Tuning
Several platforms and tools make it easier to fine-tune GPT models, each with unique features and capabilities. Choosing the right one depends on budget, technical requirements, and scalability needs.
OpenAI API
Provides a straightforward interface for fine-tuning GPT models with your data. Ideal for users seeking high-quality results and direct integration with OpenAI’s resources.
Hugging Face
A popular platform with extensive model libraries and community support. Offers flexible tools called transformers for customizing models and a user-friendly interface for developers.
Azure AI
Microsoft’s Azure AI services include support for OpenAI models, making it suitable for organizations using Azure cloud infrastructure. Good for scalability and enterprise integration.
AWS SageMaker
AWS offers tools like SageMaker for fine-tuning and deploying GPT models, especially useful for companies already working within the AWS ecosystem.
Here’s a quick overview of the top platforms:
| Tool | Description | Best For |
| OpenAI API | Provides direct fine-tuning for OpenAI’s GPT models, offering high-quality results with minimal setup. | Users who want a straightforward, reliable solution with direct OpenAI support. |
| Hugging Face | Open-source platform with a large model library, ideal for flexible customization. Includes tools like Transformers and an active community. | Developers who need customization options and access to multiple model types. |
| Azure AI | Microsoft’s cloud service with seamless integration for fine-tuning OpenAI models, suitable for large-scale deployment within Azure. | Enterprises using Azure infrastructure that require scalable, secure, cloud-based solutions. |
| AWS SageMaker | Comprehensive platform on AWS for fine-tuning, deploying, and managing GPT models with high scalability. | Organizations in the AWS ecosystem needing robust infrastructure and scalability for ML models. |
Pro tip: When selecting a tool, consider factors such as cost, ease of use, and support. For rapid prototyping, Hugging Face may be best. For robust enterprise solutions, Azure or AWS can provide the needed scalability and integration options.
Step-by-Step Guide to GPT Fine Tuning using OpenAI API
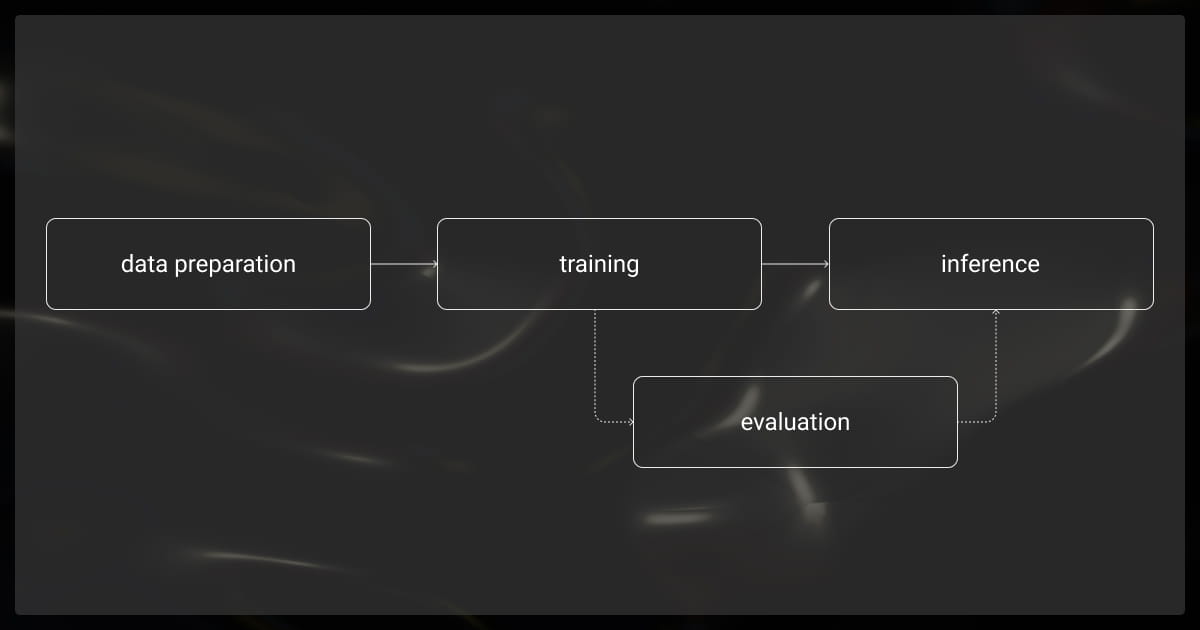
Fine tuning GPT models involves a series of steps to ensure data is prepared, the model is trained correctly, and results are evaluated. You can fine-tune the following GPT models:
- GPT-3: Cost-efficient for applications like customer service and content generation.
- GPT-3.5-Turbo: Balances cost and accuracy for complex tasks.
- GPT-4: Suited for advanced applications requiring nuanced language and reasoning, with higher resource needs.
The OpenAI API simplifies the fine-tuning process with these key steps (you can also check out the detailed instructions from OpenAI here):
Step 1: Data Preparation
Format your data in JSONL files as prompt-completion pairs to teach the model specific patterns and responses.
Ensure the data is high quality and well-annotated to avoid biased or inaccurate outputs. For example, if you want a model to respond in a specific tone, your examples should reflect this style consistently.
Step 2: Uploading Data to OpenAI
Use the files.create endpoint in the OpenAI API to upload your JSONL dataset. Each file should meet OpenAI’s format and size requirements for successful training.
Once uploaded, the file is stored in your OpenAI account for use in training and retraining sessions.
Step 3: Configuring the Fine-Tuning Job
Initiate the fine-tuning job with parameters like model type, batch size, and learning rate. Use the fine_tunes.create endpoint to specify these settings.
OpenAI recommends experimenting with batch sizes and learning rates depending on the dataset size and complexity to optimize performance without overfitting.
Step 4: Monitoring Training Progress
Track the fine-tuning process via the fine_tunes.get endpoint, which provides real-time updates on metrics like training loss and completion progress.
Monitoring allows you to assess if adjustments are needed mid-training, helping avoid issues like overfitting.
Step 5: Deploying and Testing Your Fine-Tuned Model
Once training completes, your fine-tuned model is ready for deployment via the OpenAI API. Use it by referencing the fine-tuned model’s unique ID.
Test the model with real-world inputs to ensure it meets your application’s requirements. For continued improvements, you can iterate on the fine-tuning process by updating datasets or adjusting parameters.
Additional Features for GPT Fine-Tuning
The OpenAI API also provides options to automate and refine fine-tuning workflows, such as using webhooks for completion notifications or the ability to retrain with updated datasets as your needs evolve.
With the OpenAI API, fine-tuning GPT models becomes a manageable process that allows you to tailor language models precisely to your requirements. This helps you enhance accuracy, tone, and reliability for specific ML tasks.
The best way to refine GPT models is to train them while pursuing task-oriented prompting. This enables the model to become sensitive to expected user questions and the subtlety with which users demand answers.
 Co-Founder and Chief Marketing Officer, Cohort XIII LLC
Co-Founder and Chief Marketing Officer, Cohort XIII LLC
Common Use Cases for GPT Fine Tuning
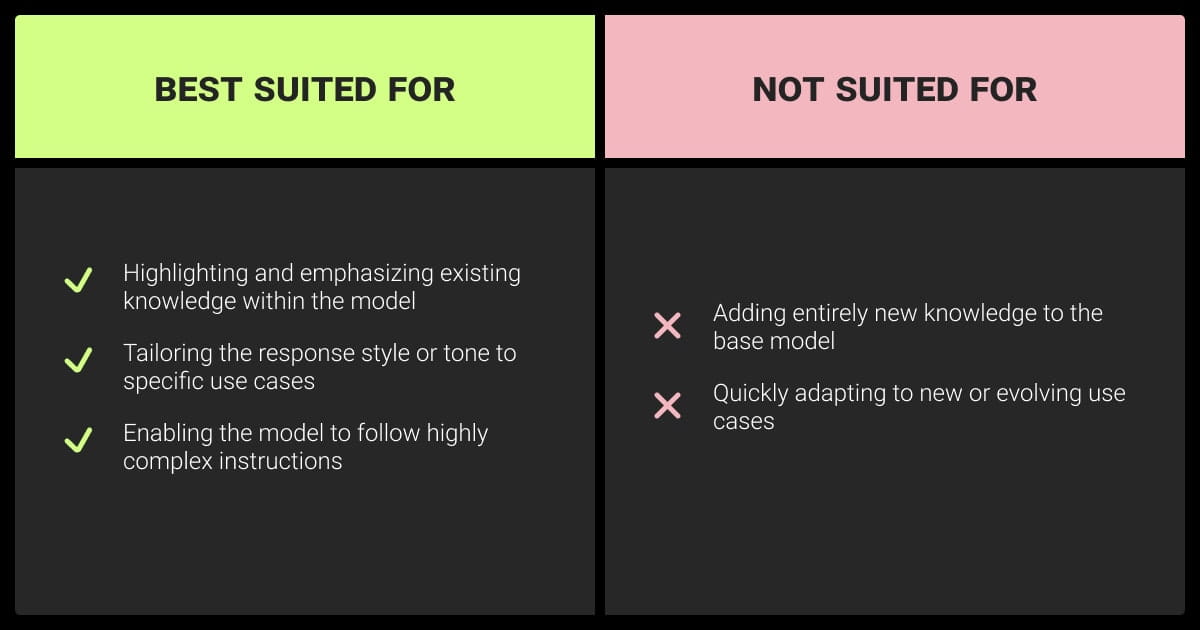
Fine-tuning enhances GPT models for specific needs, making them highly versatile across different applications:
| Use Case | Description | Ideal Applications |
| Customizing Style and Tone | Tailor responses to match a specific voice or format. | Brand-specific customer interactions, content creation |
| Ensuring Consistency | Increase reliability in fields where stable, repeatable outputs are required. | Customer support, legal document drafting |
| Interpreting Complex Prompts | Enable the model to follow detailed instructions effectively. | Technical support, programming assistance |
| Addressing Edge Cases | Define responses for unique or sensitive situations, enhancing precision in specific contexts. | Medical and regulatory environments |
| Adapting to New Skills | Train the model for specialized tasks that go beyond general capabilities. | Niche fields like scientific research, geospatial annotation, domain-specific tasks |
Why Consider Outsourcing GPT Fine-Tuning
If in-house fine-tuning feels complex or resource-intensive, consider outsourcing to specialized LLM fine-tuning service providers, like Label Your Data. At our data annotation company, we handle everything from data preparation to training and deployment, offering expertise that can save time and ensure higher-quality results.
Here’s why partnering with a provider like Label Your Data can help:
- Expertise Across the Process: Providers handle data annotation, training, and deployment end-to-end.
- Time and Resource Savings: Focus on core tasks while experts manage fine-tuning.
- Access to Industry Knowledge: Providers bring domain expertise for compliance and accuracy.
- Scalability: Easily adjust project size without straining internal resources.
- Continuous Support: Get ongoing optimization and support for evolving needs.
Outsourcing offers faster, higher-quality results with industry-specific expertise, making fine-tuning simpler and more effective.
About Label Your Data
If you choose to delegate LLM fine-tuning, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is GPT fine-tuning?
GPT fine-tuning is the process of customizing a pre-trained GPT model to perform better in specific tasks. By training the model on tailored datasets, you can make it more accurate and relevant for particular applications, such as understanding industry-specific language or responding in a desired tone.
Does GPT-4 allow fine-tuning?
Yes, certain versions of GPT-4 support fine-tuning, including GPT 4o fine tuning. This allows users to adapt GPT-4 for specialized tasks, improving its performance in complex or niche applications that benefit from customized responses.
How much does it cost to fine-tune GPT-4?
The cost of GPT 4 fine tuning varies depending on factors like the amount of data, the number of training steps, and the platform. Generally, fine tuning GPT 4 can be resource-intensive, so costs may range from a few hundred to several thousand dollars.
How much data do you need to fine-tune GPT?
The amount of data needed to fine-tune GPT depends on the complexity of the task. For simpler tasks, a few thousand well-annotated examples might be enough, while more complex applications may require tens of thousands of examples to achieve optimal results.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.