Automatic Speech Recognition: Best Practices & Data Sources

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

TL;DR
- Automatic Speech Recognition (ASR) converts human speech to text.
- Best practices include high-quality audio, diverse speaker profiles, and advanced deep learning models.
- Top data sources for ASR include open-source datasets like LibriSpeech and custom audio collection services.
- Challenges in ASR development involve handling accents, linguistic diversity, and background noise.
- Custom data collection can improve accuracy for specific automatic speech recognition AI use cases.
Making Sense of Automatic Speech Recognition: What Is It and How It Works?
As you scroll through stories on Instagram and encounter real-time captions, have you ever wondered how this feature works? Or have you tried obtaining an auto-generated transcript of a song or podcast on Spotify? There’s no doubt that advanced NLP services stand behind this magic, but what exactly is automatic speech recognition technology?
Automatic Speech Recognition (ASR) is an AI-driven technology that can convert human speech into text. This is why it’s commonly named as Speech-to-Text.
The rapid adoption of ASR into real-world applications is due to these three reasons:
- ASR enhances communication with real-time transcription.
- Automatic speech recognition technology automates tasks, leading to increased productivity.
- ASR ensures accessibility by converting spoken content into written form, significantly aiding those with hearing impairments.
Basic automatic speech recognition systems could respond to a limited set of sounds. Today, we can witness advanced AI sound recognition solutions able to understand and respond fluently to natural human language.
What Is Automatic Speech Recognition?
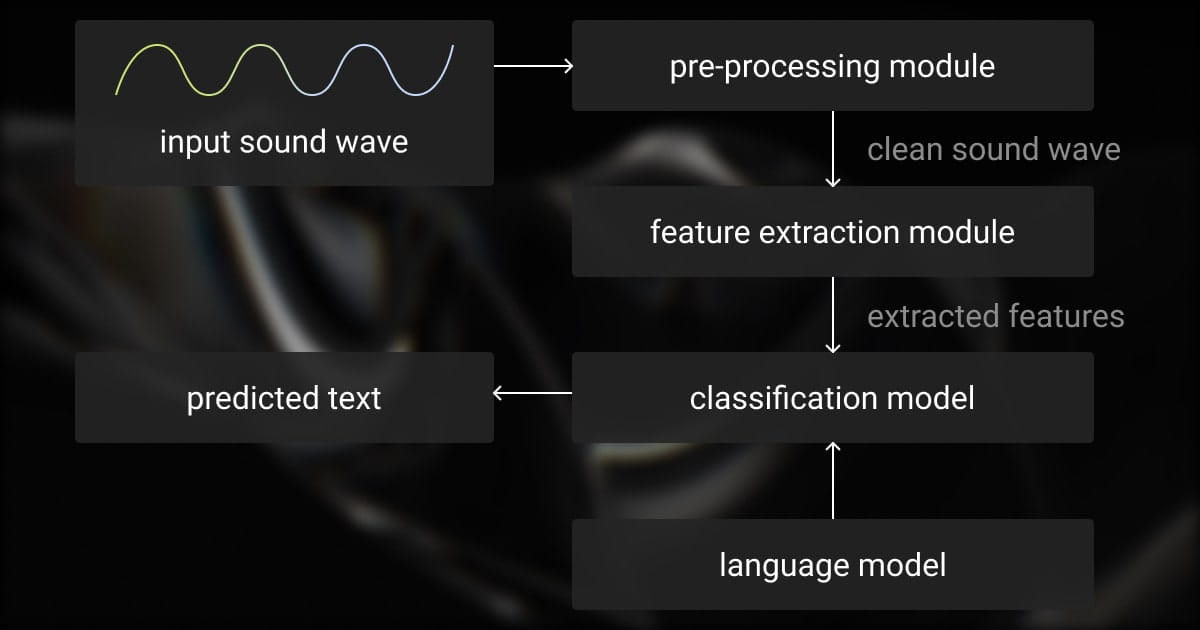
ASR (automatic speech recognition) is the method of converting spoken words into written text by analyzing the speech wave’s structure. Speech recognition is challenging due to the various signals in spoken language. Regardless, this field is gaining traction, as smart cities, healthcare, education, and other sectors can benefit from automatic speech recognition technology for automated voice processing.
ASR aims to provide a solid foundation for deeper semantic learning using:
- Computer technology
- Digital signal processing
- Acoustics
- Artificial intelligence
- Linguistics
- Statistics
- and more.
How Does ASR Work?
Nowadays, ASR is commonly used in various applications like weather updates, handling phone calls automatically, providing stock information, and inquiry systems. Automatic speech recognition technology uses different methods to turn sound information into text through deep learning.
The process involves matching the detected speech signal with text. Modern models like DNN, CNN, RNN, and end-to-end models achieve higher accuracy in recognition compared to older hybrid models.
Most popular automatic speech recognition systems use different models:
- Gaussian Mixture Models (GMMs)
- Hidden Markov Models (HMMs)
- Deep Neural Networks (DNNs)
DNNs are crucial in building automatic speech recognition systems because they involve special neural network models and improved training and classification methods.
Currently, many ASR-based voice assistants, like Google’s Assistant and Apple’s Siri, can understand how people talk in real-time conversations. They use automatic techniques based on what they hear to recognize human speech patterns. For instance, Google’s Assistant can speak more than 40 languages, and Siri can handle 35.
If you already have a specific audio annotation request, don’t hesitate to reach out to our team and get a custom estimate for your project.
Best Practices for Automatic Speech Recognition (ASR) Development

Developing a robust automatic speech recognition system requires a strategic approach to data, model selection, and training processes.
Below are essential best practices to consider:
High-Quality Audio Data
Begin with clean, well-recorded speech samples. Pre-processing steps, like noise reduction and volume normalization, are crucial to ensure the system captures clear audio signals. This reduces potential errors during transcription and improves the overall accuracy of your model.
Diverse Speaker Profiles
To ensure your ASR model performs well in real-world scenarios, it must be exposed to a wide range of speakers. Gather data from individuals of different ages, genders, accents, and dialects. This diversity will prepare your automatic speech recognition system for varied speaking styles, improving its adaptability to new inputs and reducing prediction bias.
Multi-modal annotation, where the audio is labeled alongside contextual data like speaker demographics, emotion, and background noise levels, enhances the ASR model’s ability to adapt to real-world conditions.

Balanced Training Data
Ensure that your training data represents the complexity of language, including variations in speech speed, pauses, and sentence structure. Balancing this data with enough examples of both formal and conversational speech allows the automatic speech recognition system to function well in multiple environments, from customer service to casual conversations.
High-quality annotations ensure that the model learns from properly labeled, contextually rich datasets, improving its performance in recognizing speech across different languages.

 CEO, Software House
CEO, Software House
Use of Advanced Deep Learning Models
Employ deep learning models such as Deep Neural Networks (DNNs), Convolutional Neural Networks (CNNs), and Recurrent Neural Networks (RNNs). These models are excellent at capturing patterns in speech data, offering superior accuracy. CNNs are particularly good for extracting features from raw audio, while RNNs and Long Short-Term Memory (LSTM) networks excel at handling temporal data like speech.
Data Augmentation
Use data augmentation techniques like adding background noise or modifying the pitch and speed of speech. This increases the robustness of the ASR model by preparing it to handle real-world variability, such as background chatter or different speech speeds.
Regular Model Tuning and Updates
Automatic speech recognition systems need ongoing tuning and updates to maintain their effectiveness. Regularly updating your model with new data, including out-of-domain speech, helps prevent overfitting and ensures the system remains accurate in diverse conditions.
Hybrid Annotation Approaches
Balancing manual and automated data annotation processes is key. While automated tools can speed up annotation, manual annotation ensures higher accuracy, especially for complex tasks such as transcribing multi-speaker audio or difficult accents. A hybrid approach allows for the efficiency of automation while maintaining the precision of human oversight.
Annotating data by marking specific sounds, accents, and languages helps the ASR system differentiate between background noise and the main audio. With well-labeled data, the system becomes smarter at recognizing speech across varying environments, leading to more accurate transcriptions and a better user experience.
 Partnerships Manager, Digital Web Solutions
Partnerships Manager, Digital Web Solutions
By following these best practices, you can build an automatic speech recognition system that is accurate, adaptable, and capable of performing effectively in various real-world applications. Yet, keep in mind that ASR systems need a lot of labeled training data to prevent overfitting and guarantee accuracy. This is particularly challenging when there isn’t much data available for automated speech recognition tasks.
So, the first and crucial step is to collect the appropriate data before training your ASR model.
Discover how Label Your Data enhanced missile detection in real-time through advanced audio annotation. Read the full case study.
Data Collection for Automatic Speech Recognition: Essential Factors and Data Sources
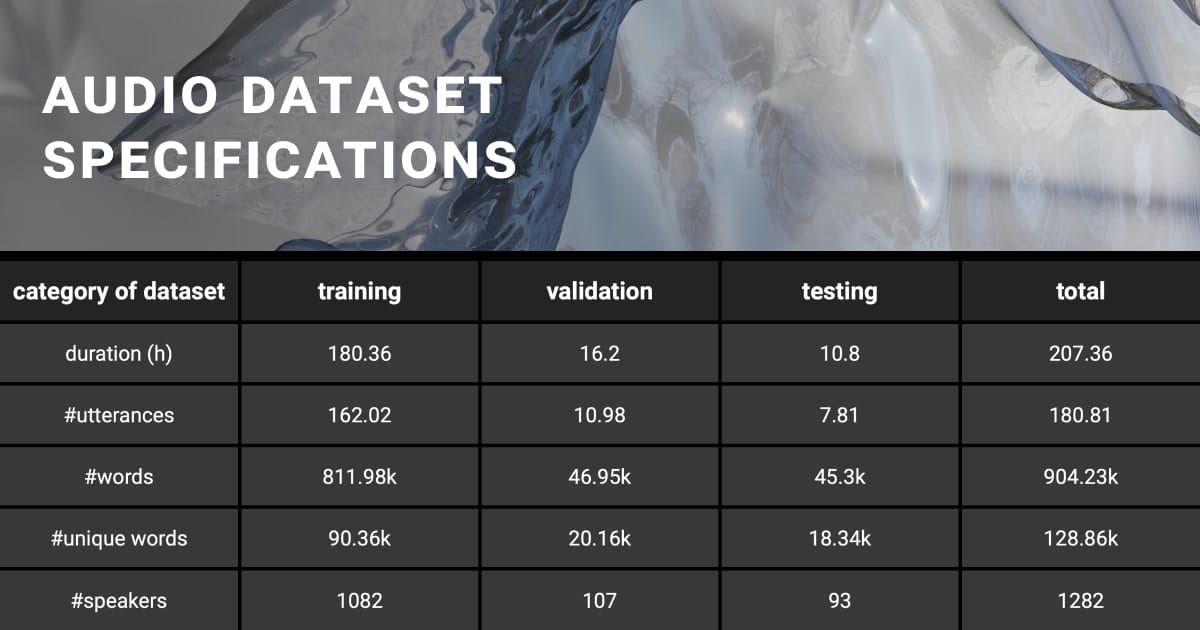
ASR relies primarily on audio data as its core input to transcribe spoken language into written text. The acoustic features within audio signals, such as pitch, intensity, and spectral content, are essential for accurately interpreting spoken words.
To build an automatic speech recognition (ASR) model, you need a lot of training and testing data. If the collected audio data for speech recognition isn’t good, it can affect the performance of voice assistants or conversational AI systems.
Key Factors to Consider in Data Collection for ASR
Several factors impact your data collection efforts for building an AI automatic speech recognition system:
Diversity of Speakers
Effective training requires a substantial dataset encompassing speech from a wide range of users.
Articulation in Speech
Optimal recognition occurs in isolated systems when users articulate words distinctly with pauses between them.
Vocabulary Coverage
The capability of automatic speech recognition systems varies depending on the extent of words they can accurately recognize.
Spectral Bandwidth
The quality of spectral bandwidth directly impacts the performance of a trained automatic speech recognition system. Decreased bandwidth leads to suboptimal performance, while increased bandwidth enhances performance.
Preparing audio data for ASR involves not only accurate transcriptions but also detailed linguistic annotation services to enhance the understanding of language nuances. This process goes hand in hand with text data annotation services, contributing to a comprehensive and accurate dataset.
To ensure a high-performing model, trust data collection to industry experts. Send your quote request and get secure audio collection services.
Top Data Sources for Automatic Speech Recognition
Luckily, there are enough sources to choose from when collecting human audio and speech for an ASR model:
1. Open-Source Audio Datasets
Open-source speech datasets are a great starting point for obtaining audio data for automatic speech recognition (ASR). They are cost-effective, versatile for diverse languages, and well-documented. These public datasets, available online, include notable ones like:
- Google’s Audioset: with over 2 million YouTube videos, offers labeled audio clips categorized into 632 sound types;
- CommonVoice by Mozilla: comprises 9,000+ hours in 60 languages and is continuously expanding through global volunteer contributions;
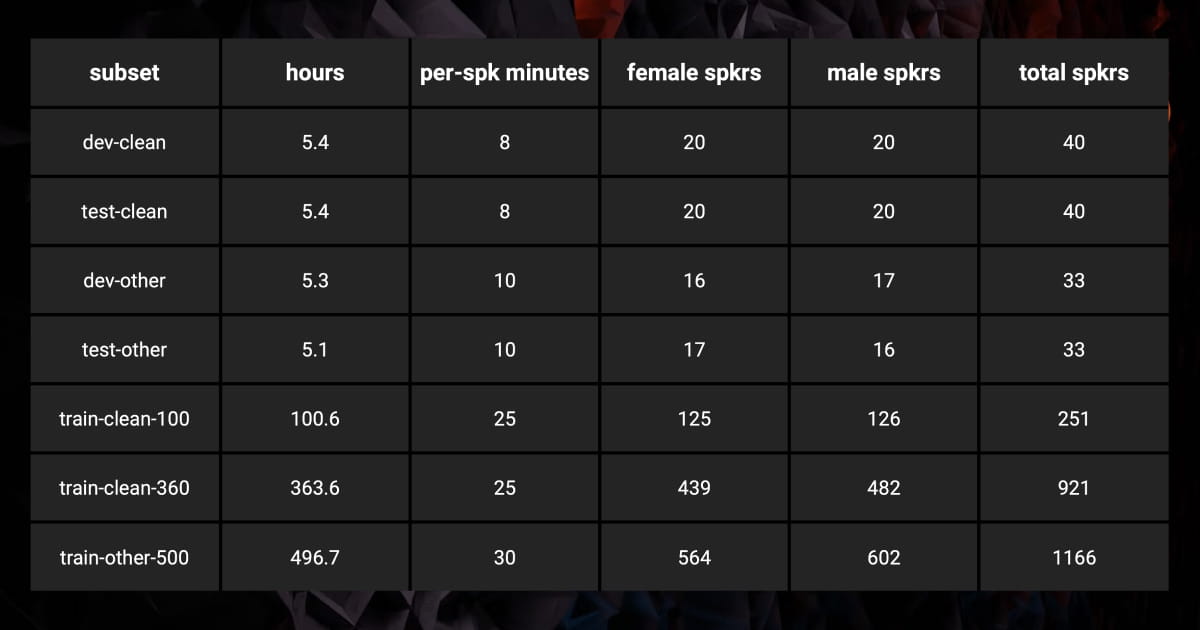
- LibriSpeech: with 1,000+ hours from audiobooks, the dataset is suitable for North American English but may not cover various accents;
- VoxForge: with over 100 hours, is a smaller but useful volunteer-created option.
For beginners, publicly available data is a suitable choice. However, quality variability, limited diversity, and varying dataset sizes challenge ASR model development.
2. Pre-packaged or Ready-to-Deploy Speech Datasets
These datasets are existing collections of audio recordings and labels used for training automatic speech recognition systems. They are obtained by vendors or agencies through crowdsourcing and vary in how they’re collected and processed.
Ready-to-deploy speech datasets save time and cost, with convenient availability and potential discounts on specific data categories. Yet, they offer limited customization, as well as lack ownership benefits, cultural diversity, and technical specifications.
Some companies specialize in selling speech data collected through methods like controlled recordings or transcription ASR software. These datasets, often termed off-the-shelf (OTS), are available for purchase.
3. Custom Audio Collection Services
Say you need a scripted speech collection for your model training. For such a specific request, you may consider creating a custom speech dataset. This involves collecting and labeling speech data tailored to your ASR model.
Customized solutions have several advantages. First, they are generally more affordable than an in-house collection and can scale based on your needs. They are precise due to the expert team tackling the task. A company with multilingual support can collect audio data from specific regions or dialects and customize the dataset for specific scenarios. The main drawback here is finding the right partner that can meet all your ASR project objectives.
4. In-Person Speech Data Collection
Gathering spoken information directly from individuals in a particular environment is called in-person or field-collected speech datasets. This method works best for (ASR) audio speech recognition tailored to a particular population or environment. Here, one needs to define research questions, create a protocol, select participants, obtain consent, and record speech data with specific equipment.
Such audio data collection captures more natural and real-life speech situations. This, in turn, enhances the accuracy and reliability of your ASR algorithm. However, it may be time-consuming and costly, involve ethical and legal considerations, and have a smaller sample size. This potentially limits your model’s generalizability.
5. Proprietary Data for Automatic Speech Recognition
The option of using proprietary or owned data involves collecting audio recordings from your own users. This brings a significant benefit of customization for unique populations. As a result, you get a more accurate representation of your users’ language and context.
Plus, ownership and exclusive rights grant flexibility and control over data use and sharing. However, collecting and annotating data can be time-consuming and expensive, especially for diverse or hard-to-reach populations. This method also poses a challenge with privacy compliance and inherent model bias if data is collected from a limited group.
Challenges in ASR Data Collection

Linguistic Diversity
The right audio and speech collection can make the automatic speech recognition system perform better. The main challenge here is to get multiple variations of text and speeches for training and testing. Currently, we only have enough training data for popular languages out of the around 7000 languages spoken globally.
Accents, Dialects, and Speech Styles
People have different accents and varied voices, making it challenging to build an ASR system that understands everyone. It’s even more challenging for those who speak multiple languages because their accents are more diverse. Not to mention things like social habits, gender, dialects, and how fast people talk while trying to get enough resources to teach the ASR model.
Background Noise and Real-World Conditions
Background noise significantly impacts ASR accuracy, requiring clear, high-quality audio data. Collecting real-world data under these conditions is essential for robust models.
Custom vs. Generic Data
Creating a robust automatic speech recognition system requires collecting diverse audio data that captures accents, pronunciation variations, and speech styles. The dataset, including corresponding transcriptions, must also account for background noise to ensure clarity and accuracy. While generic datasets are available online, specific automatic speech recognition systems may require custom data collection tailored to their unique needs.
Fortunately, there are enough methods for collecting AI automatic speech recognition data, depending on the algorithm and system used. Now that you know these sources, you can choose one based on your ASR model training goals.
Label Your Data provides a global team of data collection experts from diverse backgrounds. Our services are backed by a robust QA. Contact us if you need custom speech data tailored to your ASR project.
About Label Your Data
If you need accurate, consistent ground truth data, run a free pilot with Label Your Data. Our specialist annotation teams have helped many companies scale their ML projects. Here's why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is ASR and how does it work?
Automatic speech recognition technology converts spoken language into text. It works by analyzing audio signals, identifying speech patterns, and using machine learning models like DNNs or RNNs. If you’re looking to build or optimize your ASR system, Label Your Data offers high-quality speech data collection and annotation services to ensure accurate transcription.
What is the difference between ASR and NLP?
ASR converts speech to text, while NLP (Natural Language Processing) analyzes and processes this text to understand meaning, context, and intent for tasks like translation, sentiment analysis, or generating responses.
Is ASR the same as speech-to-text?
Yes, ASR is commonly referred to as speech-to-text, as its primary function is to transcribe spoken words into written text. To enhance the performance of your ASR model, consider Label Your Data's expert audio annotation services.
What is the task of automatic speech recognition?
The task of ASR is to transcribe spoken language into text accurately. This involves recognizing speech patterns, handling different accents, and managing background noise to ensure precise transcription in real-time or recorded settings. For reliable data annotation to support this task, Label Your Data can help collect and label high-quality audio datasets tailored to your ASR model.
What is an example of Automatic Speech Recognition ASR?
Some notable automatic speech recognition examples include voice-activated smart devices like Google Home, Amazon Echo, Siri, and Cortana.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.