LLM Model Size: Comparison Chart & Performance Guide

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- What LLM Model Size Parameters Tell You About Its Performance
- How to Calculate LLM Model Size in GB
- LLM Model Size Comparison Chart (2025)
- LLM Size vs Performance: Finding the Balance
- Choosing the Right LLM Model Size for Your Use Case
- What Else Affects LLM Performance Beyond Model Size
- About Label Your Data
- FAQ

TL;DR
- LLM model size represents the number of parameters that determine a model’s capacity and memory footprint.
- Model size in GB depends on both parameter count and precision: a 7B model is about 14 GB (FP16) or 7 GB (INT8).
- Larger models offer higher reasoning accuracy but slower speed and higher cost.
- 7B-13B models provide the best balance for most use cases.
What LLM Model Size Parameters Tell You About Its Performance
LLM model size is the total number of parameters a model uses to process and generate language.
LLM model size is defined by the number of parameters a model uses to process and generate language. Each parameter is a numerical weight adjusted during LLM training to represent learned linguistic patterns. The total number of parameters determines how much information the model can store and how effectively it can understand context or perform reasoning tasks.
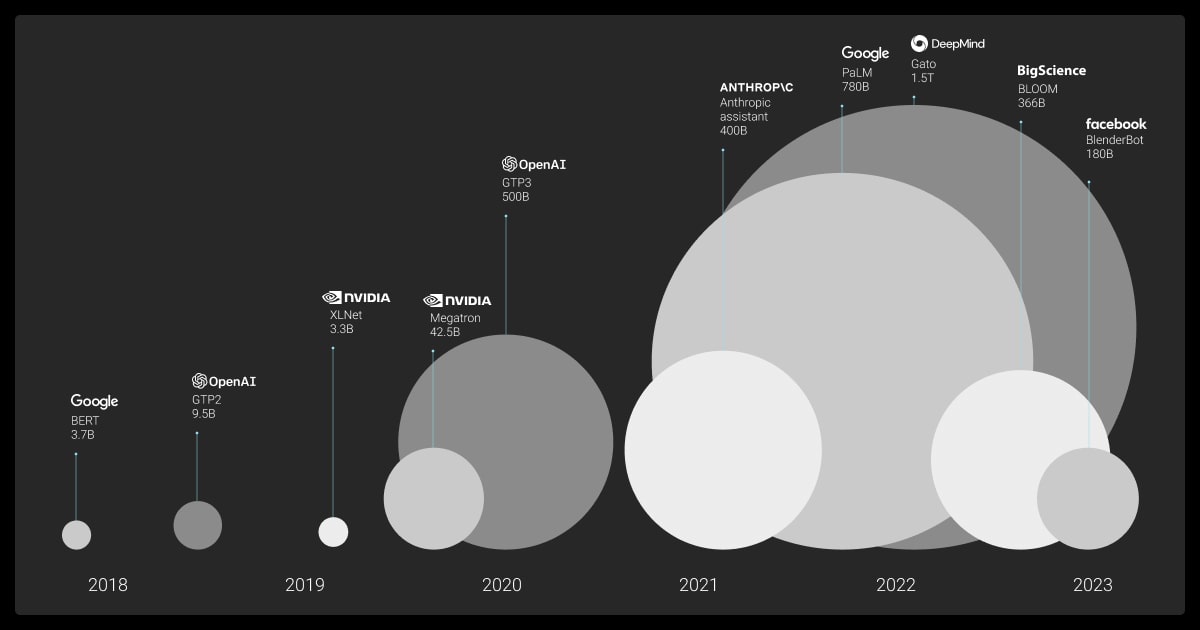
Model size has expanded at an exponential rate. The original Transformer architecture in 2017 contained about 65 million parameters. GPT-3 introduced 175 billion, and models such as PaLM and GPT-4 now reach into the hundreds of billions or even over one trillion parameters. This rapid scaling is directly tied to improvements in reasoning and generalization.
However, larger parameter counts increase computational and memory demands. A 1-billion-parameter model needs around 1.86 GB at 16-bit precision, while a 70-billion-parameter model can exceed 140 GB.
For most applications, models in the 7B-13B range balance reasoning quality with practical performance, especially when quantized or fine-tuned for specific tasks. Here, continuous LLM model comparison across sizes supports better planning for cost, performance, and hardware constraints.
How to Calculate LLM Model Size in GB

LLM model size in gigabytes (GB) shows how much memory a model needs to store its parameters. One gigabyte equals roughly one billion bytes of data.
Since each parameter is a number represented in bytes, the total model size depends on how many parameters it has and the precision used to store them.
You can use a simple LLM model size calculator to estimate this value:
Model size (bytes) = Number of parameters × Bytes per parameterAt 32-bit precision (FP32), each parameter takes 4 bytes. At 16-bit (FP16), it takes 2 bytes. Lower-precision or quantized formats such as INT8 (1 byte) or INT4 (0.5 byte) reduce storage significantly with minimal accuracy loss.
For example, a 7-billion-parameter model occupies about 28 GB at FP32, 14 GB at FP16, 7 GB at INT8, and 3.5 GB at INT4. Similarly, a 70-billion-parameter model requires roughly 280 GB at FP32 or 70 GB at INT8. These values show how precision settings directly affect deployability and hardware cost.
Quantization allows engineers to fit larger, more capable models within limited memory. Running a 9B model at 4-bit precision can often outperform a smaller 2B model at full precision, offering greater reasoning capacity while keeping memory use within typical GPU limits.
Measuring latency requirements and average query complexity is crucial. For example, our e-commerce chatbot worked fine with a 7B model, but our content generation system needed at least 13B for acceptable quality.

 CIO and Founder, Local Data Exchange
CIO and Founder, Local Data Exchange
LLM Model Size Comparison Chart (2025)
Comparing LLM model sizes highlights how parameter count and memory footprint scale across architectures. The following table shows approximate sizes for popular models in both FP16 and INT8 precision formats.
These estimates are based on publicly available data and common quantization levels used for deployment.
Comparing LLM sizes shows how parameter count and memory footprint scale across model architectures. The LLM model size chart below summarizes commonly used models and their approximate storage needs under FP16 and INT8 precision. These values are based on public data and standard quantization methods used in deployment.
| Model | Parameters (B) | Size (FP16, GB) | Size (INT8, GB) | Typical Use Case |
| BERT Base | 0.11 | 0.4 | 0.2 | Text classification, embeddings |
| Mistral 7B | 7.3 | 14 | 7 | General NLP tasks, chat, summarization |
| Gemma 2 9B | 9 | 18 | 9 | Balanced reasoning and efficiency |
| LLaMA 3 70B | 70 | 140 | 70 | Complex reasoning, multilingual tasks |
| Mixtral 8×7B | 46 (active 12.9) | 26 | 13 | Mixture-of-experts performance with lower cost |
| GPT-3 | 175 | 350 | 175 | Broad NLP, text generation |
| Claude 2 | ~100 | 200 | 100 | Document analysis, enterprise tasks |
| PaLM 2 | 540 | 1080 | 540 | Multimodal and multilingual applications |
| GPT-4 (est.) | >1,000 | >2,000 | >1,000 | Advanced reasoning, multimodal AI |
An updated LLM size chart helps engineers quickly estimate which model can fit into their GPU memory before training or deployment.
In practice, models between 7B and 13B parameters represent the most efficient middle ground for local and enterprise-level fine-tuning. Larger architectures such as 70B and above are mainly used in cloud-based inference or research environments where high-capacity GPUs are available.
LLM Size vs Performance: Finding the Balance
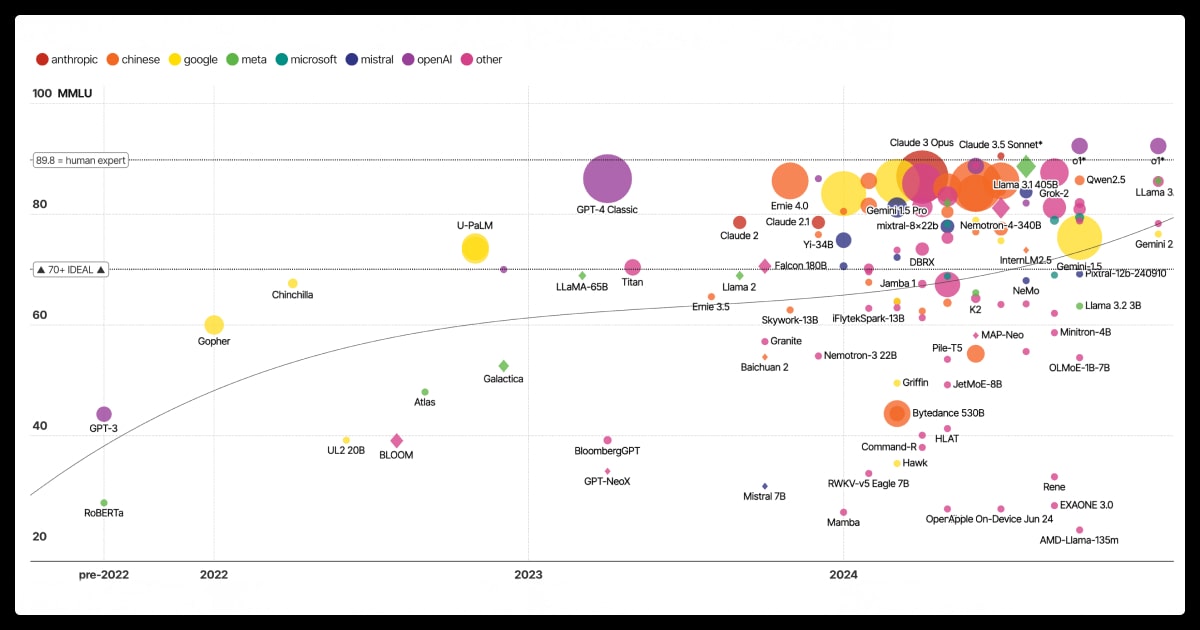
LLM performance scales with size, but the relationship is not linear. Increasing parameter count improves reasoning, comprehension, and generalization up to a point, after which performance gains diminish while computational and energy costs rise sharply.
Smaller models, such as those under 3 billion LLM parameters, handle basic text classification and sentiment analysis but often fail on multistep reasoning tasks. Models between 7B and 13B parameters deliver a strong balance of speed, accuracy, and cost efficiency. Beyond 70B parameters, performance improvements become incremental compared to the steep rise in compute and latency.
| Model Size Range | Typical Tasks | Performance | Trade-Offs |
| 1–3B | Simple NLP, embeddings, mobile inference | Fast, limited reasoning | Shallow context understanding |
| 7–13B | General chat, summarization, QA | Strong balance | Moderate compute cost |
| 30–70B | Advanced reasoning, multilingual, code generation | High accuracy | Requires enterprise GPUs |
| 100B+ | Multimodal, research-scale models | Peak performance | Very high cost and latency |
Performance also depends on architecture and quantization. A quantized 9B model running at 4-bit precision can outperform a smaller 2B model at full precision while remaining within desktop GPU limits.
For practical deployments, evaluating both model size and precision provides a clearer indicator of real-world efficiency than parameter count alone.
Start with a smaller model and gradually scale up based on performance metrics. Find that sweet spot between performance and resource usage.

Choosing the Right LLM Model Size for Your Use Case
Larger models provide higher reasoning accuracy and language fluency but require significantly more memory, power, and processing time. Smaller or quantized models are faster, more affordable, and easier to deploy.
| Model Type | Parameters | Typical Hardware | Best For | Key Advantage |
| Small | <3B | Laptops, edge devices | Classification, sentiment, embeddings | Low latency and power use |
| Medium | 7–13B | Consumer GPUs (8–24 GB) | Chatbots, summarization, RAG pipelines | Balanced accuracy and cost |
| Large | 30–70B | Multi-GPU or cloud | Complex reasoning, multilingual QA | Higher contextual accuracy |
| Very Large | 100B+ | Enterprise clusters | Multimodal or research models | Advanced reasoning and creativity |
Fine-tuning allows teams to improve task-specific accuracy without moving to a larger model.
Many organizations use fine-tuned 7B or 13B models to achieve domain-level precision comparable to general-purpose 70B models. Label Your Data supports this approach by preparing domain-relevant annotated datasets optimized for fine-tuning and evaluation workflows.
Use cases matter: FAQs work with smaller models, while real-time chatbots need larger LLMs. Edge devices require lighter models, but the cloud can handle bigger ones. Start small, analyze, and scale as needed.
 Co-Founder, WebSpero Solutions
Co-Founder, WebSpero Solutions
Once the right model scale is selected, LLM fine tuning becomes a key step to adapt the model to domain-specific tasks. Label Your Data supports this process through LLM fine-tuning services built on verified datasets and scalable QA frameworks for enterprise models and comparative research such as Gemini vs ChatGPT evaluation.
What Else Affects LLM Performance Beyond Model Size
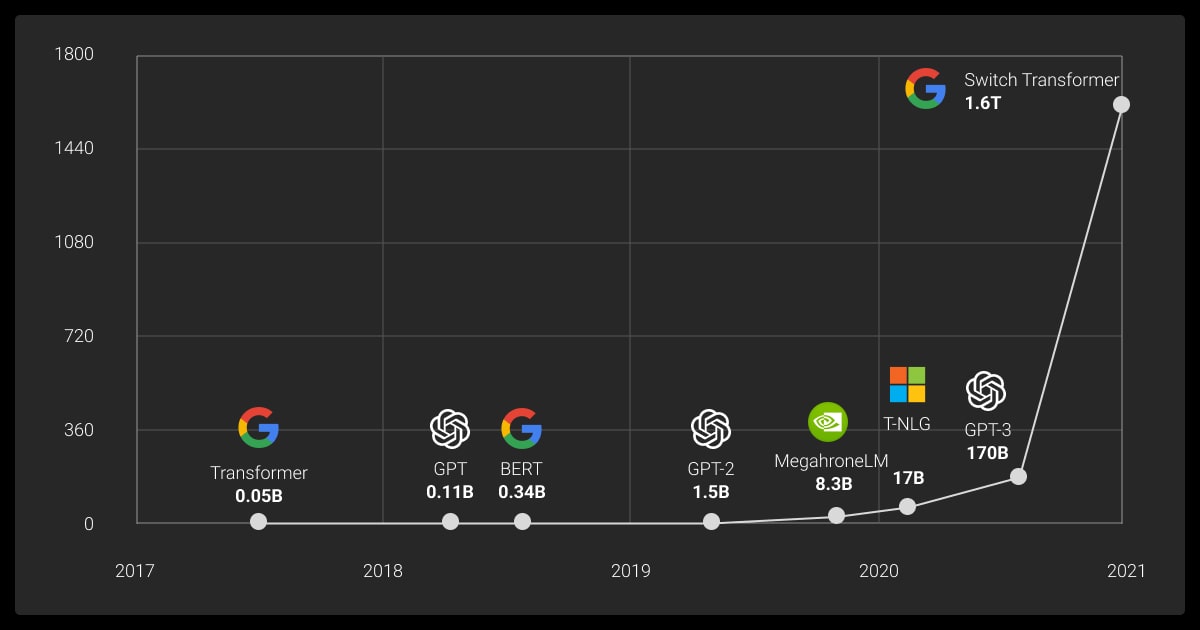
Model size is a major factor in language model capability, but it is not the only one. Performance also depends on the quality of training data, architecture design, and available computational resources.
These factors determine how efficiently a model learns and how well it performs on real-world tasks.
Training data quality
High-quality, diverse, and well-annotated datasets are essential for reliable performance. Even a large model will underperform if trained on noisy or biased ML datasets. Working with a specialized data annotation company like Label Your Data ensures that the training corpus is accurate, diverse, and task-specific. A trusted data annotation platform can also support model fine-tuning, QA, and benchmarking for different types of LLMs.
Models designed for multimodal input require even more extensive annotation pipelines and higher data annotation pricing due to task complexity.
Model architecture
Architectural choices define how effectively a model uses its parameters. Transformer-based designs, sparse attention mechanisms, and mixture-of-experts (MoE) frameworks allow larger models to scale efficiently without linear growth in computation. For instance, Mixtral 8×7B activates only a subset of experts during inference, achieving performance similar to 70B-parameter models at lower cost.
The choice of architecture interacts closely with the quality of the input data. Even advanced transformer or mixture-of-experts architectures rely on professional data annotation workflows.
Computational resources
Hardware capability affects both training and inference speed. GPUs, TPUs, and dedicated AI accelerators improve efficiency, while limited VRAM restricts model size and context window length. Quantization and distributed inference help reduce these hardware constraints, enabling larger models to run on mid-range systems.
Overall, model performance reflects the interaction between size, data quality, architecture, and compute resources. Balancing these elements is key to achieving consistent accuracy and efficiency across different deployment environments.
About Label Your Data
If you choose to delegate LLM fine-tuning, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is the size of an LLM model?
The size of an LLM model is determined by the total number of parameters it contains. Each parameter is a learned weight that helps the model understand and generate language. Together, these parameters define both the model’s capability and the amount of memory required to store it.
What is LLM parameter size?
Parameter size refers to the total number of tunable weights in the model. It's a core measure of model capacity. Common LLM model sizes include 7B (e.g., Mistral), 70B (e.g., LLaMA 3), and 175B+ (e.g., GPT-3/4). Parameter count influences accuracy, memory footprint, and training duration. The LLM parameter size comparison helps identify which model scale suits your hardware and performance needs.
How many GB is an LLM model?
The size in GB depends on the number of parameters and the level of precision. For example, a 70B parameter model takes about 280 GB at 32-bit precision. With 8-bit quantization, that drops to around 70–90 GB. Very large models like GPT-4 or Claude 3.5 may exceed 1 TB if uncompressed.
How big is a 7B LLM model?
A 7-billion-parameter (7B) model requires about 28 GB at 32-bit precision (FP32), 14 GB at 16-bit (FP16), and roughly 7 GB at 8-bit (INT8). When quantised to 4-bit precision (INT4), it can run in about 3.5 GB of memory, making it suitable for consumer-grade GPUs.
Why are LLM models so large?
LLMs are large because they contain billions of parameters trained on extensive text datasets. Each parameter increases the model’s capacity to capture linguistic structure, context, and reasoning. As a result, performance scales with size; but so do compute, energy, and storage requirements.
Large models require vast annotated datasets prepared through systematic data annotation services. These datasets feed billions of text or image recognition examples into the machine learning algorithm during training.
What does 32B mean in LLM?
“32B” stands for 32 billion parameters. The “B” indicates billions, which is a standard way of describing model scale. A 32B model sits between mid-size (7B–13B) and large-scale (70B+) architectures, requiring roughly 64 GB at FP16 or 32 GB at INT8 precision.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.