RAG vs Fine Tuning: Which Method to Choose

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- Understanding RAG and LLM Fine Tuning
- Core Technical Differences Between RAG vs Fine Tuning
- Performance in High-Scale Environments
- Cost and Resource Optimization
- Adaptability to New Data: RAG vs Fine Tuning
- Technical Implementation Challenges in RAG vs Fine Tuning
- Security and Privacy Concerns: RAG vs Fine Tuning
- RAG vs Fine Tuning: Choosing the Right Method in 2024
- About Label Your Data
- FAQ

TL;DR
- RAG: Best for real-time, dynamic tasks requiring frequent updates from external sources.
- Fine-Tuning: Ideal for static, high-precision tasks that require deep domain expertise.
- Performance: Fine-tuning offers faster inference at the cost of memory, while RAG introduces latency due to retrieval steps.
- Costs: RAG saves on retraining but incurs runtime costs; fine-tuning has higher upfront costs but can be more efficient for fixed domains.
- Adaptability: RAG handles evolving data with ease; fine-tuning requires retraining but offers more accuracy for domain-specific tasks.
Understanding RAG and LLM Fine Tuning
The debate between Retrieval-Augmented Generation (RAG) and LLM fine-tuning is crucial for technical teams. They need to make the right choice when tackling specialized, real-time, or evolving ML tasks.
Both methods offer distinct advantages, but the choice depends on several factors. They include:
- Nature of the data
- Project requirements
- Scalability
- Cost considerations
In this article, we explore the technical differences, performance characteristics, cost implications, and other critical factors to help you decide between RAG vs fine tuning.
Core Technical Differences Between RAG vs Fine Tuning
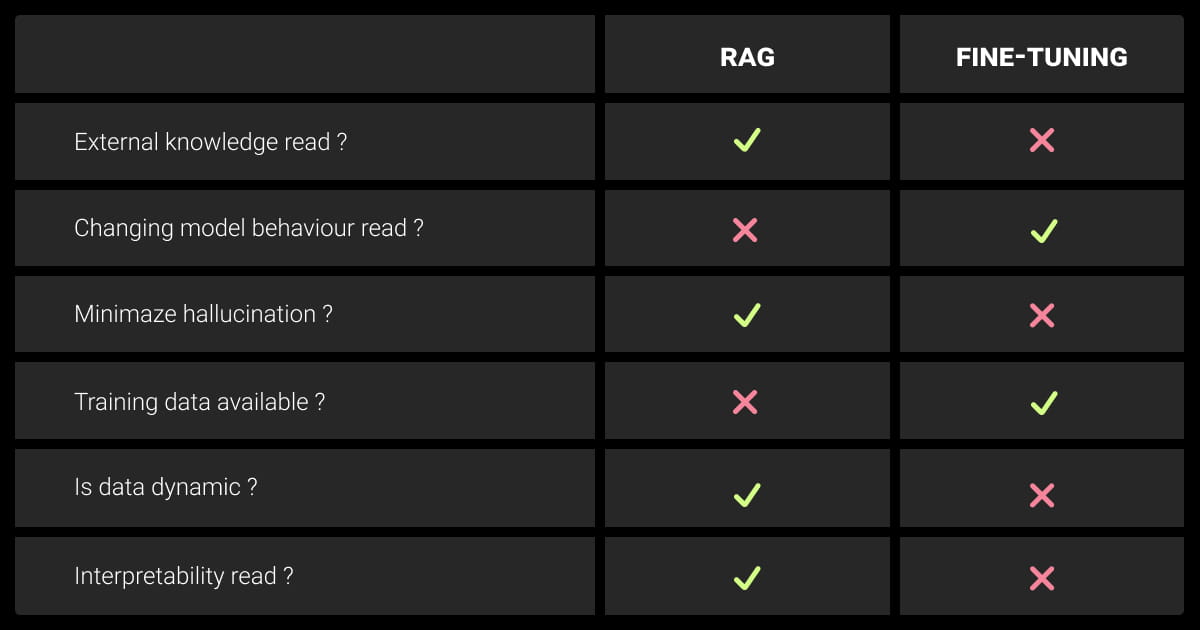
RAG has gained popularity due to its ability to retrieve external data dynamically. It is suitable for real-time, high-scale applications where data is constantly changing.
In contrast, fine-tuning modifies the internal parameters of a large language model (LLM), optimizing it for domain-specific tasks. This often leads to more accurate outcomes but requires retraining as new data emerges.
| Characteristic | RAG | Fine-Tuning |
| Knowledge Source | External databases | Internal, model-embedded knowledge |
| Data Requirements | Large external datasets | Domain-specific annotated datasets |
| Real-time Adaptability | High | Low |
| Use Case | Dynamic, real-time tasks | Static, domain-specific tasks |
| Memory Footprint | Lower, dependent on retrieval | Higher, model size increases with data |
RAG (Retrieval-Augmented Generation)
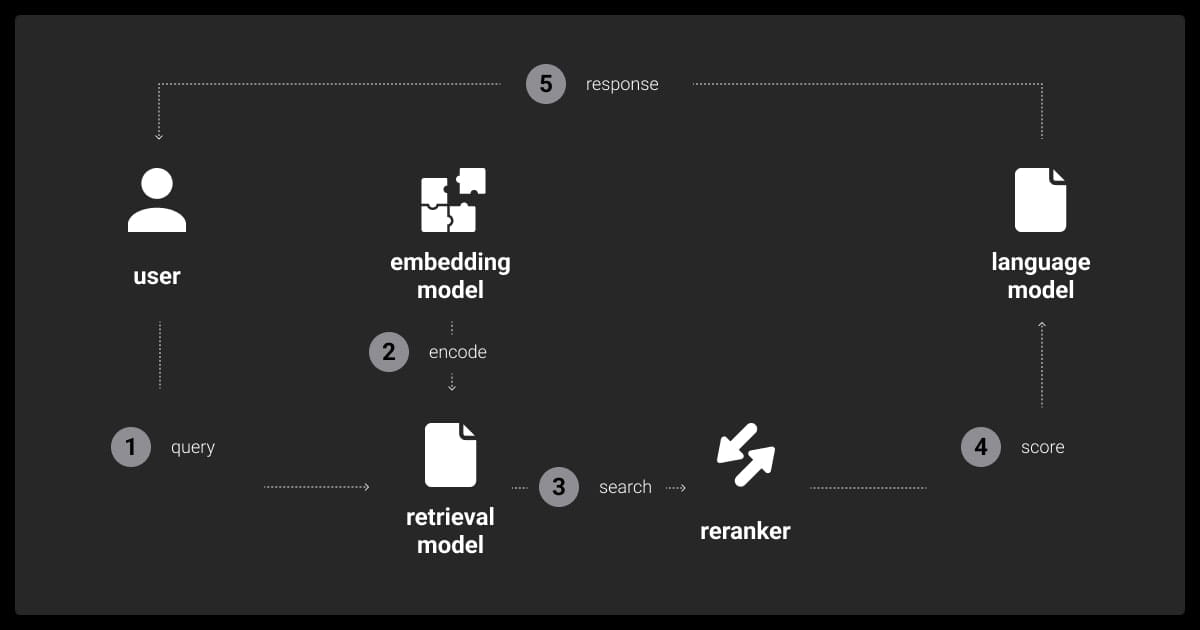
RAG is a hybrid approach that combines traditional retrieval techniques with generative models. It uses an external knowledge base to fetch information on demand so that the model remains lightweight while benefiting from dynamically updated data. This is especially useful in fields such as real-time customer support, dynamic document generation, or any task where the information is constantly evolving.
RAG operates by:
- Retrieving relevant information from external datasets (e.g., databases or APIs).
- Feeding the retrieved data into a generative model to produce context-aware outputs.
Strengths of RAG
- Real-time adaptability: Data can be updated in real-time without retraining the model.
- Memory efficiency: Since knowledge is retrieved externally, the base model can remain small.
Challenges of RAG
- Latency issues: Retrieval introduces delays, especially when large-scale datasets are used.
- Dependency on data quality: The system is only as good as the knowledge base it retrieves from. Poor indexing or irrelevant data can hinder performance.
Fine-Tuning

Fine-tuning involves modifying a pre-trained model’s parameters to optimize it for a specific task or domain. The process requires substantial computational resources as the model is retrained on a new, domain-specific dataset, effectively embedding this knowledge into the model itself.
Strengths of Fine-Tuning
- High precision: By integrating domain-specific knowledge, fine-tuned models often outperform retrieval-based approaches in accuracy.
- Low inference latency: Since the knowledge is embedded in the model, no additional steps are required during inference.
Challenges of Fine-Tuning
- Costly retraining: Fine-tuning demands significant resources, especially as the data or task evolves.
- Model drift: If the model is not retrained periodically, it may become outdated as data changes.
Ready to enhance your LLM’s performance? Explore our fine-tuning services and unlock precise, domain-specific accuracy. Run a free pilot!
Performance in High-Scale Environments
| Factor | RAG | Fine-Tuning |
| Inference Speed | Slower due to external retrieval | Faster, limited by model size |
| Throughput | Dependent on retrieval optimizations | Higher, can be scaled with multiple instances |
| Data Flow | Flexible, handles large external sets | Encapsulates knowledge, but uses more memory |
Latency and Throughput
For RAG, inference time is a concern because it involves an extra retrieval step, adding latency. Optimizations such as FAISS (Facebook AI Similarity Search) can reduce retrieval time, but even then, RAG's inference is typically slower than a fine-tuned model.
Fine-tuning, on the other hand, eliminates this retrieval step, leading to faster responses. However, fine-tuned models consume more memory because they internalize all the knowledge within the model’s architecture, making them harder to deploy on low-resource devices.
Data Flow
RAG’s flexible data flow allows it to manage vast external datasets without increasing the model’s size. This is beneficial in scenarios where the model needs to access constantly changing information, but it introduces the challenge of managing these external datasets effectively.
Fine-tuned models encapsulate all the knowledge within the model itself. While this speeds up inference, it also means that the model will need to be re-trained when new data becomes available, increasing both memory usage and maintenance costs.
Cost and Resource Optimization
| Cost Factor | RAG | Fine-Tuning |
| Inference Costs | Higher due to dynamic retrieval | Lower, but requires upfront retraining costs |
| Resource Usage | Lower model size but external resources | Higher memory footprint |
| Long-term Efficiency | More flexible, but incurs ongoing costs | Cost-efficient for fixed, repetitive tasks |
Inference Costs
The costs associated with RAG primarily stem from the need to query external databases or APIs for information during inference. While this avoids the need for frequent retraining, it increases the operational cost, especially in high-traffic systems where retrieval needs to happen constantly.
Fine-tuning, on the other hand, involves significant upfront costs. Training large models, especially with GPUs or TPUs, can be expensive. However, for fixed domains where repeated tasks are common, LLM fine-tuning methods can be more cost-effective in the long run as it avoids recurring retrieval costs.
Scalability Considerations
Scaling fine-tuned models is relatively straightforward, as they can be deployed across multiple instances with ease. In contrast, scaling RAG requires careful management of external retrieval systems, which may introduce additional challenges and bottlenecks, especially when dealing with multiple, large-scale datasets.
Adaptability to New Data: RAG vs Fine Tuning
| Adaptability | RAG | Fine-Tuning |
| Flexibility | Highly flexible, updates data dynamically | Requires retraining as new data arrives |
| Precision | Depends on retrieval accuracy | Stronger control over accuracy and relevance |
RAG’s Immediate Adaptability
One of the primary advantages of RAG is its ability to adapt to new data instantly. Since the model pulls from external sources, updates to the knowledge base can be reflected in real-time outputs. This makes it the superior choice for dynamic applications such as news generation, where information changes frequently.
Fine-Tuning for Domain-Specific Accuracy
Fine-tuning offers superior control over accuracy within specific domains but lacks the flexibility of RAG. As new data becomes available, the model must be retrained to reflect these changes. While this ensures higher accuracy for fixed tasks, it introduces delays and costs whenever data evolves.
Technical Implementation Challenges in RAG vs Fine Tuning
| Challenge | RAG | Fine-Tuning |
| Complexity | Managing external databases and retrieval | Efficient model updates and retraining |
| Optimization | Indexing, caching strategies | Reducing overfitting, optimizing training |
RAG Implementation Challenges
Implementing RAG involves managing large-scale, up-to-date knowledge bases and ensuring that retrieval is both fast and relevant. This requires sophisticated indexing, caching, and ranking strategies to optimize retrieval speed and minimize latency.
Fine-Tuning Challenges
Fine-tuning presents its own set of challenges, particularly when it comes to efficiently updating models without overfitting. Techniques like LoRA (Low-Rank Adaptation) and adapters can help mitigate resource usage, making it more feasible for teams without extensive hardware.
Security and Privacy Concerns: RAG vs Fine Tuning
| Concern | RAG | Fine-Tuning |
| Privacy | External data introduces higher risks | Internal data ensures stronger privacy control |
| Compliance | GDPR, HIPAA risks with external retrieval | Better compliance with in-house data |
RAG
RAG relies on external data sources to provide up-to-date information, which inherently introduces security risks. When pulling data from external databases or APIs, there is the potential to inadvertently expose sensitive information. Furthermore, this retrieval process can raise compliance concerns under privacy regulations like GDPR or HIPAA, where managing and auditing external data usage becomes increasingly complex.
To mitigate this, companies need to employ robust encryption and strict access control protocols. However, this adds another layer of complexity to RAG implementations, especially in industries with strict regulatory oversight such as healthcare and finance.
Fine-Tuning
Fine-tuning keeps all data processing in-house, offering far greater control over privacy and security. This method is advantageous for organizations handling sensitive, domain-specific information that cannot be risked in external databases. Fine-tuned models also have lower exposure to external threats since they don't need to access external systems in real time.
While fine-tuning ensures better compliance, the need to constantly update the model when new data emerges can still present operational challenges, especially in industries where regulatory scrutiny is high.
Still unsure if fine tuning vs RAG is the best fit for your project? Let our team help you choose the optimal approach for your LLM needs!
RAG vs Fine Tuning: Choosing the Right Method in 2024
Let’s summarize the main points discussed to help you understand which method, RAG vs fine tuning, works best for you.
Project-Specific Recommendations
RAG shines in real-time applications where new data is constantly emerging. For example, in dynamic environments like news aggregators or real-time customer service, RAG allows models to pull the most relevant and current information. This makes it particularly useful in industries that rely on the most up-to-date insights, such as finance, health, or content generation.
Fine-tuning, on the other hand, is the go-to method for tasks that demand high precision and where data is relatively static. For example, in legal document generation, medical research, or tasks requiring domain-specific expertise, fine-tuning ensures that the model can perform highly accurate and detailed tasks without the need for continuous data retrieval.
Decision Matrix
Below is a concise decision matrix to help you evaluate which method—RAG or fine-tuning—best suits your needs:
| Criteria | RAG | Fine-Tuning |
| Inference Speed | Slower, due to external retrieval | Faster, no retrieval required |
| Cost | Higher ongoing costs for external retrieval | Higher upfront training costs |
| Scalability | Dependent on external systems | Easy to scale with internal systems |
| Real-Time Adaptability | Immediate adaptation to new data | Requires retraining for new data |
| Domain-Specific Accuracy | Lower precision, dependent on retrieval | High precision within specific domains |
Use this matrix as a quick reference for deciding which method is better suited to your project.
Hybrid Method
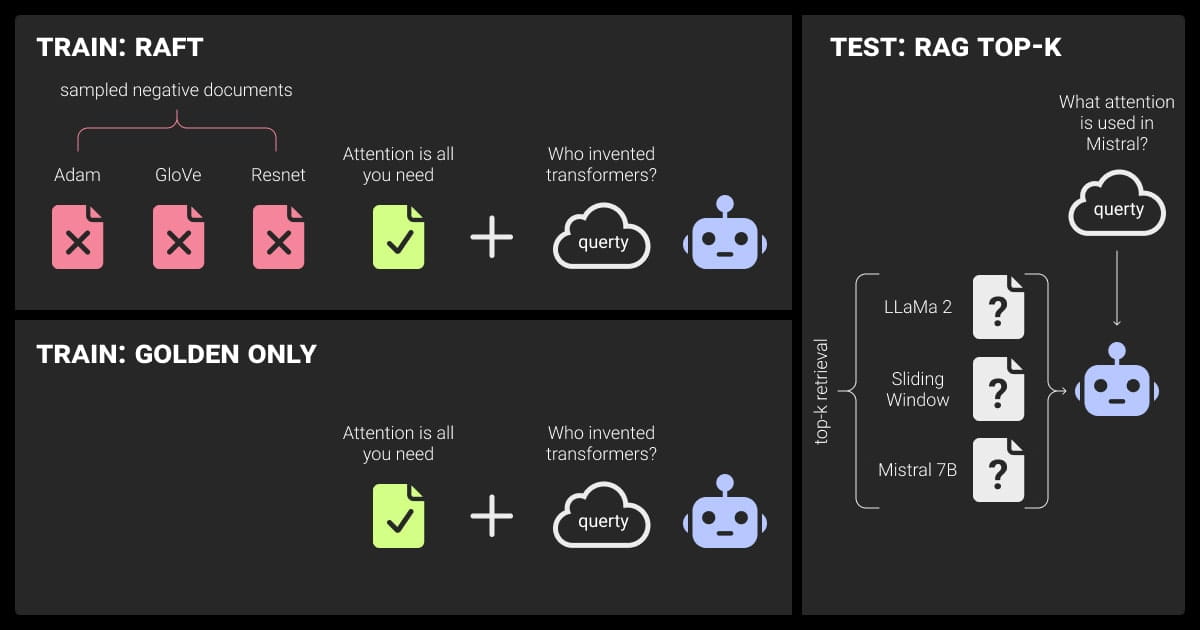
For complex use cases that require real-time adaptability and high precision, a hybrid approach combining RAG and fine-tuning can offer the best of both worlds.
How the hybrid approach works:
- Fine-tuning the LLM ensures high accuracy for static, domain-specific tasks, such as legal document generation or medical diagnoses, where deep, pre-trained knowledge is essential.
- RAG complements this by retrieving dynamic information from external sources, allowing the model to handle evolving or real-time data, such as customer support queries or financial market updates.
Benefits of the hybrid method:
- Real-time adaptability with precision: You get the accuracy of fine-tuned models along with the flexibility of RAG to handle real-time data.
- Reduced retraining: The model can rely on RAG for up-to-date information, reducing the need for frequent fine-tuning thus lowering operational costs.
- Enhanced performance: The model can provide more comprehensive and contextually relevant responses by leveraging internal knowledge (fine-tuned) and external retrieval (RAG).
This hybrid strategy is particularly effective in healthcare, finance, and customer service, where static expertise and real-time adaptability are crucial.
Integration and Ecosystem Support
Both RAG and fine-tuning benefit from extensive ecosystem support, but the choice of tools and platforms may influence your decision:
- RAG Tools and Frameworks: Popular frameworks like Haystack, Hugging Face, and K2View offer support for implementing RAG pipelines. These frameworks integrate well with external databases and are particularly useful for teams looking to deploy real-time LLMs.
- LLM Fine-Tuning Tools: PEFT (Parameter-Efficient Fine-Tuning) and OpenAI’s Fine-Tuning API streamline the fine-tuning process for specific use cases. Fine-tuning has also become easier with modern LLM infrastructure, allowing for more efficient deployment across large-scale environments.
Ease of integration with different types of LLMs like GPT-4, PaLM, and similar models has made both approaches viable for enterprise-scale tasks. However, the right choice will depend on your infrastructure and the technical expertise available within your team.
If you’re still unsure which approach is best for your project, contact us for a free consultation on how to get the most out of your LLM models!
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
Is RAG the same as fine-tuning?
No, RAG retrieves external information during inference, while fine-tuning modifies a model’s internal parameters for specific tasks.
What are the advantages of RAG vs fine tuning?
RAG is more adaptable to real-time data, has a smaller memory footprint, and doesn't require retraining when new information becomes available.
What's the difference between RAG and LLM?
RAG combines a language model with external data retrieval, while LLMs, like GPT-4, use only pre-trained internal knowledge.
What is the difference between pretraining and RAG?
Pretraining is when the model is trained on a large dataset to learn general patterns, while RAG enhances a pre-trained model with real-time external data during inference.
What is the difference between RAG and fine-tuning research?
RAG research focuses on optimizing retrieval and integration of external data, while fine-tuning research explores improving internal model adjustments for specific tasks.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.