Data Augmentation: Techniques That Work in Real-World Models

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- When Data Augmentation Actually Moves the Needle in ML
- Core Data Augmentation Techniques by Data Type
- Mix-Based and Generative Methods That Outperform Standards
- Data Augmentation in Multimodal Pipelines
- Evaluating the Effectiveness of Data Augmentation
- Troubleshooting and Pitfalls
- Scaling Augmentation for Production Workflows
- Tips for ML Teams Using Data Augmentation
- About Label Your Data
- FAQ

TL;DR
- Not all augmentation helps. Use it when you're low on data, facing class imbalance, or need better generalization on edge cases.
- The best methods are tailored to data type: MixUp and GANs work well for images, back-translation for text, and jittering or bootstrapping for time series.
- In multimodal setups, mixing augmentation strategies is tricky; what works for image/text may fail for video/sensor data.
- To measure impact, run ablation tests and watch for real gains in AUC, F1, or task-specific metrics.
- Tools like Albumentations, nlpaug, and modAL help scale augmentation inside ML pipelines without wasting resources.
When Data Augmentation Actually Moves the Needle in ML
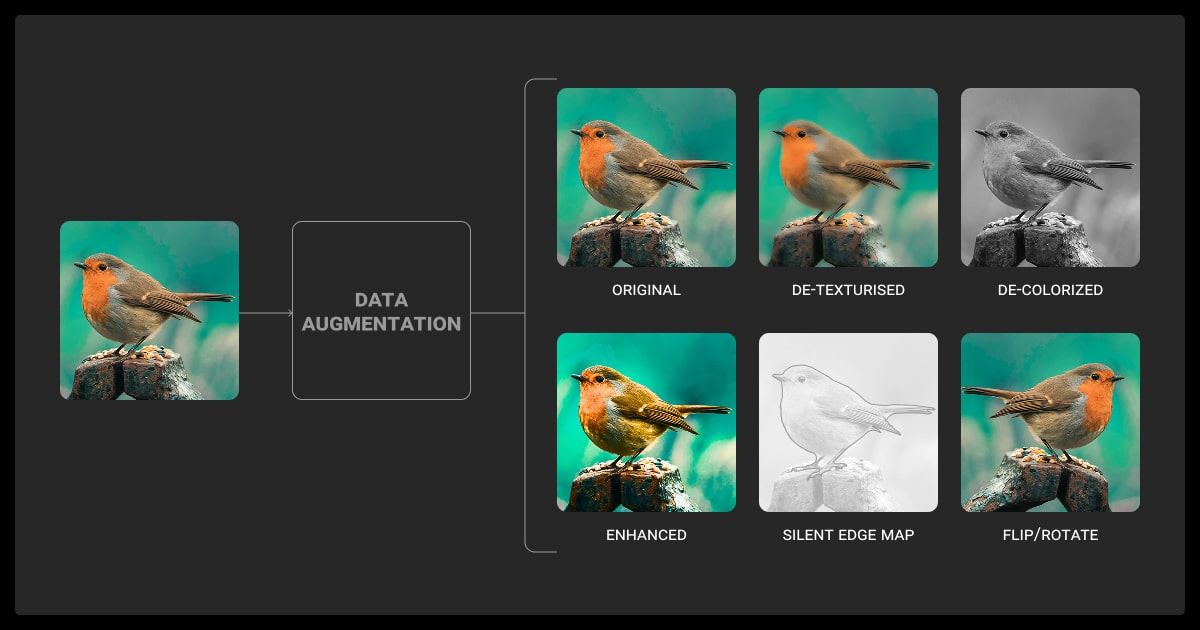
Data augmentation is the process of creating modified versions of existing data to improve model training without collecting more samples.
Most teams don’t need data augmentation by default. But when your dataset is small or lacks variation, it helps you get more out of your existing data annotation. In some cases, it works better than relabeling or collecting more data.
But it only helps in the right conditions. You’ll likely see gains in these cases:
- Your dataset is small. Helps prevent overfitting without collecting more data.
- Classes are imbalanced. Synthetic samples can balance training data.
- You need rare or edge-case coverage. Augmentation simulates uncommon but important scenarios.
- Sensors drift in multimodal setups. Injecting noise helps models stay stable across slight input shifts.
- Labeling is expensive. Augmenting existing labeled data saves cost.
These triggers signal that augmentation might be worth the effort. Otherwise, you may just be adding noise.
Core Data Augmentation Techniques by Data Type
Data augmentation in machine learning can stretch limited datasets. One study saw AUC (Area Under the Curve, measures how well the model separates classes) rise from ~83% to ~85% with flips and rotations. Another reported a 170% accuracy gain in noisy-label settings.
To understand what is data augmentation in practice, you need to look at how it’s applied across different data types. What works for images doesn’t always translate to text or time-series data.
Below are common data augmentation techniques that hold up in production pipelines, organized by data type:
Images
- Flipping and Rotation: Helps with symmetry-based tasks like image recognition, object detection or classification.
- Cropping and Scaling: Forces models to learn local features, not just global shapes.
- CutMix and MixUp: Blend multiple images and labels; works well when regular noise-based methods plateau.
- GAN-Based Local Edits: Synthetic patches or entire image generation to simulate edge cases or rare classes.
For teams working with video, annotation and augmentation often go hand in hand. You may need video annotation services to label action boundaries or key frames before augmentation can help.
Text
- Synonym Replacement: Easy to implement but risks semantic drift. Use with a vetted vocabulary.
- Back-Translation: Translate text to another language and back. Helps with generalization.
- Contextual Embedding Noise: Mask spans or insert plausible tokens using LLMs or transformers.
- Span Corruption: Inspired by pretraining setups (like BERT); forces better representation learning.
Time-Series
- Jittering: Add Gaussian noise to simulate sensor instability.
- Window Slicing: Extract overlapping segments to increase sample count.
- Resampling: Create synthetic sequences based on signal similarity.
- Bootstrapping: Works well with ECG or accelerometer data when the original set is small.
Audio
- Pitch and Speed Shifting: Makes speech or sounds more variable without losing semantics.
- Noise Overlays: Add ambient or environmental noise to simulate recording conditions.
- Reverberation and Filtering: Helps with generalization across device types or rooms.
- Phoneme-Level Masking: Similar to span corruption in text, especially for ASR tasks.
Random cropping with different aspect ratios gave us the best gains in recognizing tech product photos. A/B tests on 5,000 images showed a 23% accuracy increase versus using just flips and rotations.

 Founder, Salient PR
Founder, Salient PR
Mix-Based and Generative Methods That Outperform Standards
Classic data augmentation in machine learning, like flips and crops, only takes you so far. To go beyond, teams are using mix-based and generative approaches that create new, more informative samples instead of just tweaking existing ones.
Mix-Based Methods
Use these when your model starts overfitting or when regular augmentations plateau.
MixUp
Combines two images and their labels as a weighted average. Great for smoothing decision boundaries, especially in noisy datasets.
CutMix
Replaces a region of one image with a patch from another. This keeps spatial context intact and boosts performance on tasks like object detection.
Manifold Mixup
Blends data in feature space instead of pixel space. Often better when the raw inputs are noisy or hard to interpret.
Generative Methods
These methods need tuning, and often compute, but can help when you’ve hit diminishing returns with basic transformations.
GANs (Generative Adversarial Networks)
Common in medical imaging, rare class expansion, or face data. If trained well, GANs can generate samples that look real and diversify training data.
VAEs (Variational Autoencoders)
Better when interpretability matters. VAEs are easier to train than GANs and work well in domains like time-series or sensor data.
Diffusion models
Still early in practice, but promising for high-fidelity image generation where traditional methods fall short.
Applying elastic deformation to document layout analysis helped the model adapt to varied document styles and formats. Tests on 10,000 real user documents showed a 23% drop in processing errors compared to standard augmentations.
 CEO, FuseBase
CEO, FuseBase
Data Augmentation in Multimodal Pipelines
Multimodal setups make augmentation trickier. Each data type responds differently, and their alignment can break if you're not careful.
Common Use Cases
Text + Image
Example: image captioning or visual question answering (VQA). Augmenting only the image without updating the caption? Risky. If you flip or crop an image, regenerate the text or use models like BLIP or Flamingo to validate output.
Image + Sensor Data
In autonomous driving, LiDAR or GPS data often pairs with camera feeds. Augmenting the image without adjusting sensor coordinates can mislead the model. Use synchronized transformations or simulation tools like CARLA to keep inputs aligned.
Audio + Text
Think speech recognition or subtitle generation. If you alter pitch or speed on audio, time-aligned transcripts must shift too. Some toolkits (like torchaudio) handle this automatically; others don’t.
What to Watch
- Modality drift. If augmented pairs no longer represent the same context, training performance tanks.
- Timing mismatches. For sequential or time-aligned data, even small shifts matter.
- Label mismatch. Don’t forget to regenerate or realign your labels when data changes.
In multimodal pipelines, it’s not about stacking data augmentation techniques. You need to keep things in sync.
Evaluating the Effectiveness of Data Augmentation
You can’t just check accuracy and call it a day. Augmentation changes the distribution, so your evaluation has to account for that too.
What to measure:
Baseline vs. Augmented Performance
Always compare to a non-augmented run. Measure how much lift each technique actually gives you.
Ablation Tests
Systematically remove each augmentation method and see what breaks. Helps identify what’s useful vs. what just adds noise.
Augmentation-Aware Metrics
For tasks like image segmentation, use mIoU instead of plain accuracy. For classification, track precision/recall in edge cases.
Overfitting Check
If performance improves only on augmented validation sets but not on real-world data, you’re just overfitting to your synthetic noise.
Early Stopping Signals
Some augmentations help a lot in early epochs but plateau quickly. Use learning curves to watch for this; no need to overtrain.
You can also compare results across different machine learning algorithms to confirm whether augmentation benefits are model-specific or consistent.
Evaluation means knowing if your data augmentation actually works or just makes things look better in dev.
Back-translation (translating sentences into another language and back) helped generate diverse, natural text variations. It boosted F1 scores by 12% in multilingual intent classification, especially for informal or low-resource phrases.
 Founder & CEO, SalesDuo
Founder & CEO, SalesDuo
These augmented samples can also improve LLM fine tuning outcomes by expanding intent variation. Different types of LLMs respond differently to noise or synthetic examples, so validate augmentation effects per model.
Troubleshooting and Pitfalls
Data augmentation can help but it can also backfire. Here’s what to watch for:
Label Leakage
If your augmentation process changes the input but not the label appropriately (e.g. flipping an image with directional labels), you're leaking incorrect supervision into training.
Domain Shift
Synthetic examples might not match real-world conditions. Overfitting to augmented samples can hurt generalization.
Confirmation Bias
Some pipelines reinforce model errors by repeatedly sampling ambiguous or mislabeled regions during augmentation or active learning loops.
Overhead
Heavy augmentations, like GAN-based generation or per-sample augmentations, can slow training significantly if not done in advance or in parallel.
Monitoring
If you apply augmentations randomly and don’t log which ones were used, it’s hard to debug performance issues. Always track augmentation seeds or configs.
Good augmentation strategies need as much QA as your model architecture.
Scaling Augmentation for Production Workflows
Quick scripts don't scale. Once augmentation becomes part of your training pipeline, you need to build for repeatability, speed, and control. Many teams combine data annotation services with augmentation to balance real and synthetic data quality.
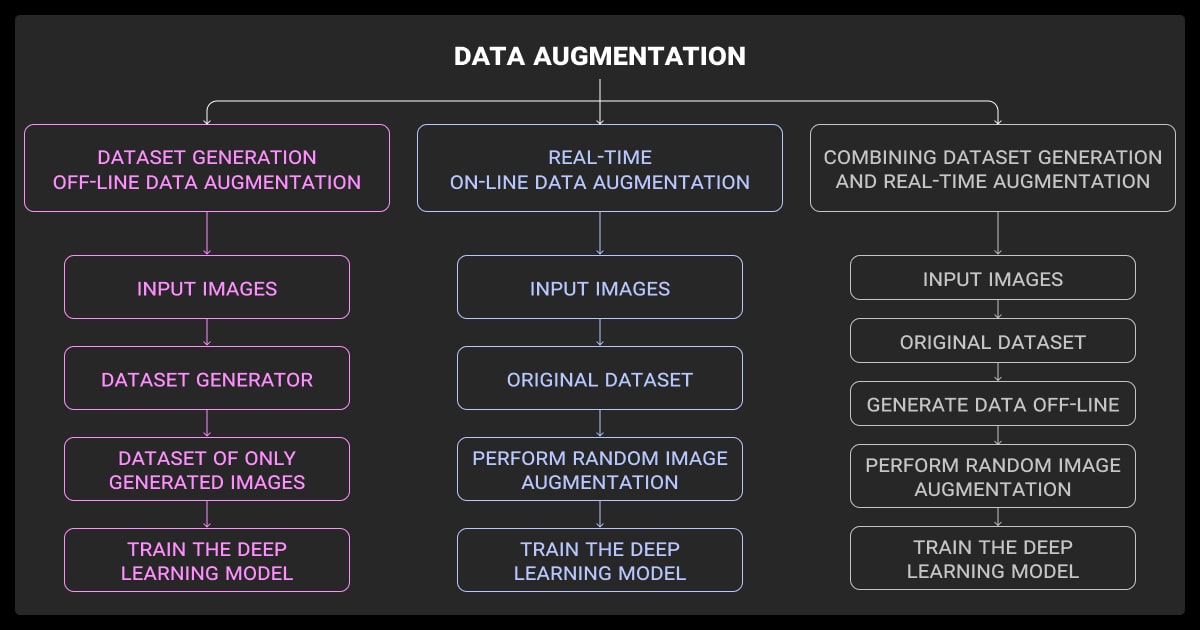
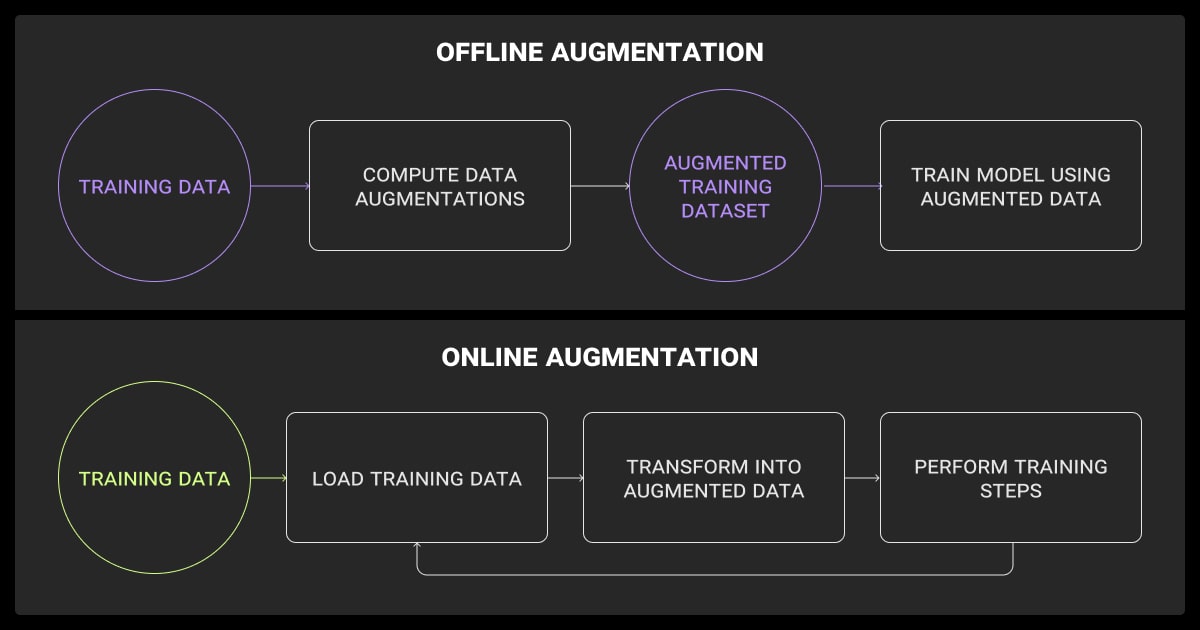
On-the-fly vs. Offline Augmentation
- On-the-fly: Augment during training. Saves storage but slows runtime. Works for lightweight transforms.
- Offline: Pre-generate augmented data. Faster training, but uses more disk space. Better for heavier transforms like GAN outputs or synthetic samples.
Distributed Processing
- Use parallel workers or GPUs to generate batches.
- Frameworks like Ray or Dask can help scale CPU-heavy tasks.
- Cloud-native workflows (e.g. AWS Batch + S3) work well at scale.
Logging and Seed Tracking
- Always log which augmentations were applied.
- Use deterministic seeds if you need reproducibility.
- Consider hashing each augmentation pipeline for traceability.
Tools that Help
- Images: Albumentations, torchvision, imgaug
- Text: nlpaug, TextAttack
- Audio: audiomentations, torchaudio
- Multimodal: custom wrappers + pipeline tools like Hugging Face Datasets
You can automate data augmentation with Python using libraries like Albumentations for images or nlpaug for text. These libraries let you apply transformations on-the-fly in training pipelines with minimal overhead.
Augmentation helps stretch limited budgets, especially when data annotation pricing is tied to per-object or per-token rates. Building this right saves time later.
Tips for ML Teams Using Data Augmentation
Before adding augmentation to your pipeline, step back and ask: do you need it? Is the problem really lack of data, or is it something else?
Audit Dataset Needs Before Augmenting
- Is your model underfitting or overfitting?
- Are errors happening on rare classes, edge cases, or noisy inputs?
- Is the data distribution skewed or imbalanced?
Augmentation helps with rare classes and overfitting. It won’t fix labeling errors or poor architecture.
Pick the Right Toolchain
- For images: Albumentations or torchvision
- For text: nlpaug or back-translation scripts
- For audio: torchaudio or audiomentations
- For tabular/time-series: tsaug, SMOTE (for class imbalance)
Don’t just pick what’s popular. Test what works on your dataset.
Know When to Add Augmentation vs Get More Data
Sometimes it's more effective to expand your dataset with fresh samples via data collection services instead of relying solely on augmentation.
- If your model still improves with new data, get more real data.
- If you're out of budget or the data is hard to collect, augmentation can help.
- Mix both when possible: real data expands generalization, synthetic data covers blind spots.
Always assess your machine learning dataset for balance, noise, and gaps before deciding how to augment. And if your in-house team is blocked, outsourcing to a data annotation company can be faster than over-augmenting low-quality data.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is meant by data augmentation?
Data augmentation means creating modified versions of your existing data to make your machine learning model more accurate. You apply transformations, like flipping, rotating, or cropping an image, to generate new training samples without collecting more data.
What is data augmentation in CNN?
In Convolutional Neural Networks (CNNs), data augmentation is used to artificially expand the training dataset. By applying image-specific changes (e.g. scaling, flipping, color shifting), you help the model learn to recognize patterns more reliably across variations.
What is the difference between data enhancement and data augmentation?
Data augmentation in machine learning adds synthetic variety to the dataset (e.g. rotated or noised versions), while data enhancement usually means improving the quality of existing data (e.g. denoising or correcting errors). One increases quantity, the other improves clarity.
What are the two types of augmentation?
The two types are offline augmentation and online (or on-the-fly) augmentation. Offline means you generate and store the augmented data before training starts. Online applies transformations in real time during training, without storing new files. Each method suits different use cases, depending on your resources and workflow.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.