Synthetic Data: Benefits and Techniques for LLM Fine-Tuning

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

TL;DR
- Synthetic data fills gaps in training LLMs, boosting performance and reducing bias.
- Benefits include scalability, cost savings, privacy protection, and customization for specific scenarios.
- Key validation techniques involve statistical checks, expert reviews, and continuous quality monitoring.
- Effective synthetic data generation methods include GANs, distillation techniques, and model-in-the-loop approaches for realistic data.
- Challenges include ensuring realism, avoiding bias transfer, and maintaining data quality.
- Best practices suggest blending synthetic and real-world data, tracking data creation, and transparent generation processes
What is Synthetic Data?
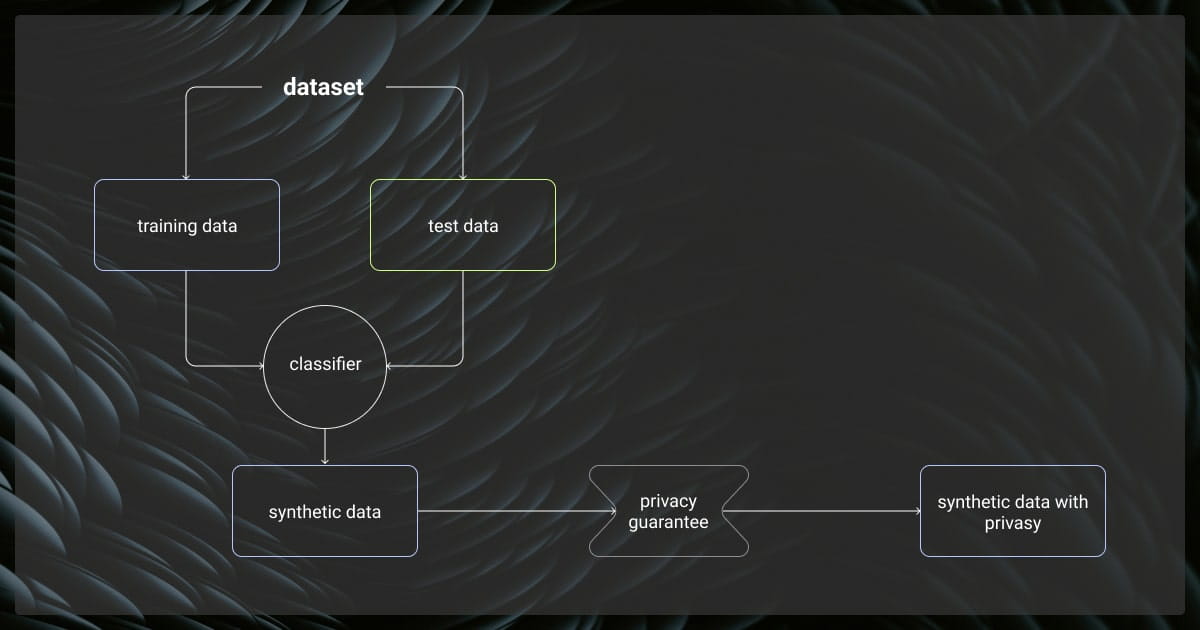
Synthetic data is created by algorithms to replicate real-world data.
Gartner projects that by 2030, synthetic data will fully surpass real data in AI models. Unlike real data, which comes from actual events, synthetic data is artificially made. It is designed to act like real data and can be customized for specific needs or rare scenarios.
Synthetic data is crucial for training large language models (LLMs). It fills gaps that traditional datasets leave behind. This provides more diverse and comprehensive training samples. As a result, models become better at handling different contexts and have fewer biases. For developers or researchers, synthetic data is a powerful tool for building robust and adaptable types of LLMs.
Human-Generated vs Synthetic Data
| Feature | Human-Generated Data | Synthetic Data |
| Source | Real-world events and interactions | Created by algorithms and simulations |
| Customizability | Limited customization | Highly customizable |
| Cost | Expensive to collect and annotate | More affordable to generate |
| Privacy Concerns | High (may include personal data) | Low (can be generated without real data) |
| Bias Potential | Inherent biases may exist | Can be tailored to reduce biases |
| Scalability | Time-consuming and resource-intensive | Easily scalable |
| Use in Rare Scenarios | Limited | Can be tailored for specific scenarios |
Benefits of Using Synthetic Data for LLM Fine-Tuning
Synthetic training data is created artificially instead of being sourced from real-world events. This type of data provides diverse and representative samples that can enhance LLM performance.
The importance of synthetic data for LLM training lies in its ability to address limitations in traditional datasets, such as bias and lack of variety. By creating balanced and varied synthetic datasets, you can train LLMs that are more robust and capable of understanding a wider range of contexts.
Here are the main benefits of using synthetic data:
Scalability
Synthetic data provides unparalleled scalability, allowing developers and researchers to generate large datasets rapidly for comprehensive model training without delays.
Cost-Effectiveness
Generating synthetic data is often cheaper than collecting real-world data. This makes it easier to allocate resources to other critical aspects, such as LLM fine-tuning and model optimization.
Privacy Protection
Synthetic data doesn’t include personal or sensitive information. This helps meet privacy regulations and ensures data compliance.
Bias Mitigation
Synthetic data can be designed to balance datasets. This helps reduce biases present in real-world data and leads to fairer, more inclusive models.
Accessibility for Testing
With synthetic data, developers can test models in rare or specific scenarios. This ensures that models are prepared for a wide range of real-world applications.
Custom Scenarios and Edge Cases
Allows models to be trained on unique or uncommon situations, improving their performance in specialized applications.
“Validating the authenticity of synthetic data in training large language models (LLMs) is essential, especially when real-world data is biased or limited. By analyzing real-world data to identify biases and limitations, synthetic data can be generated to balance out these biases.

 Data Scientist, Wavel AI
Data Scientist, Wavel AI
Techniques for Synthetic Data Generation

Creating synthetic data requires various techniques to produce realistic, diverse, and effective training data for LLMs, often paired with data annotation to ensure quality and accuracy. Here are some common methods used:
Generative Models
Generative models like Generative Adversarial Networks (GANs) are widely used for creating synthetic data. GANs are composed of two networks—a generator and a discriminator—that collaborate to create realistic data samples. Similarly, other models like Variational Autoencoders (VAEs) play a significant role in generating synthetic data.
Distillation and Self-Improvement
Distillation methods involve using larger models to create data that can train smaller models effectively. Self-improvement techniques leverage iterative outputs from models to refine data over time. These methods help produce data that closely mirrors real-world characteristics.
Model-in-the-Loop Approach
This approach integrates a feedback loop where models are involved in generating and validating synthetic data. The continuous feedback ensures that the synthetic data for LLM training remains relevant and valuable, adapting as needed to meet specific requirements.
| Technique | Generative Models | Distillation and Self-Improvement | Model-in-the-Loop Approach |
| Key Use | Create data using GANs and VAEs | Generate synthetic data from larger models and refine iteratively | Use model feedback to create and validate data |
| Strengths | Produces realistic, high-quality data, flexible for complex types | Produces refined, realistic data that mirrors real characteristics | Ensures continuous adaptation and relevance |
| Challenges | Complex to train and fine-tune | Depends on larger models, can be time-consuming | Requires ongoing monitoring and validation |
Synthetic Data Challenges and Considerations
While synthetic data offers many advantages, it comes with its own set of challenges. Understanding these is essential to ensure effective use for training and fine-tuning large language models.
Realism
One challenge is ensuring the synthetic data closely mirrors real-world complexity. If it lacks realism, models trained on it may perform well in theory but fail in real-world applications.
Bias Transfer
Synthetic data can carry over biases from the source data or generation process. If not managed carefully, it can amplify these biases, leading to skewed model outcomes.
Quality Control
Maintaining high data quality is crucial. Without proper validation and continuous feedback, synthetic data might compromise the performance of the models it trains.
To validate the authenticity of synthetic data, compare it against reliable real-world distributions. For instance, training data for specific applications should reflect actual demographic distributions sourced from trusted databases. Cross-referencing multiple sources and involving domain-expert reviews further ensure data relevance.
 Researcher and Data Scientist Lead, Chapin Hall at the University of Chicago
Researcher and Data Scientist Lead, Chapin Hall at the University of Chicago
Best Practices for Using Synthetic Data in LLM Fine-Tuning
To get the most out of synthetic data, it’s important to follow best practices that ensure effective training results.
Combine Synthetic and Real-World Data
Using a blend of synthetic and real-world data can optimize model training. This combination leverages the scalability of synthetic data while preserving the nuanced context found in real data. For example, combining synthetic customer interactions with real conversations helps maintain the model’s relevance and context awareness.
Implement Continuous Quality Checks
Regular validation and feedback from models ensure that synthetic data remains effective. Implement automated evaluation pipelines that compare model outputs against expected results. Incorporating such checks throughout the training cycle ensures data integrity and highlights areas for refinement.
Reflect Real-World Diversity
Ensure that synthetic data reflects the variety and complexity of real-world scenarios. Introduce controlled randomness and domain-specific features to avoid uniformity in generated data. This helps prevent overfitting and enhances the model's adaptability to various use cases, making it more effective in production settings.
Maintain Transparent Data Generation Processes
Document and maintain transparency on how synthetic data is generated, including the algorithms and models used. This helps in tracking sources of potential biases and ensures that data generation aligns with the ethical standards and goals of the project.
A comprehensive approach is necessary when validating synthetic data. The dual-layer validation process combines statistical verification with human-in-the-loop (HITL) assessment. This step is crucial for detecting subtleties that statistical methods might miss, such as ethical considerations and cultural nuances.
 Co-Founder, AI Tools
Co-Founder, AI Tools
Real-World Applications of Synthetic Data
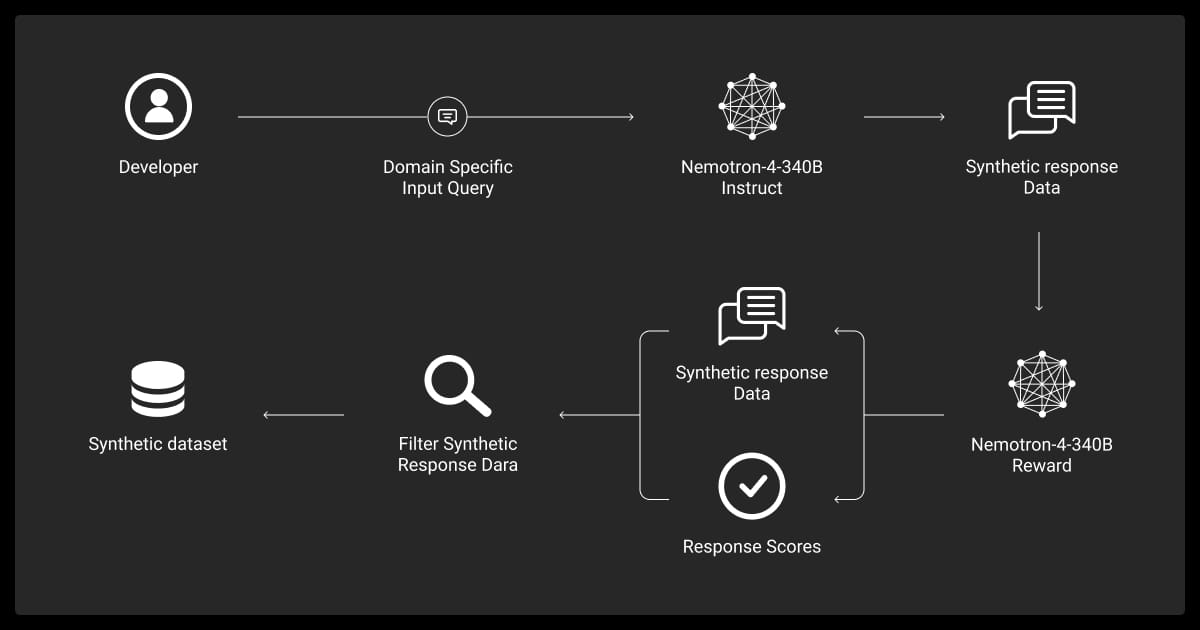
Synthetic data has proven to be highly valuable across various industries. Here are some examples of how it’s being used effectively:
Healthcare
Synthetic data for LLM training helps analyze medical records while protecting patient privacy. For example, hospitals use synthetic patient data to develop predictive models for diagnosing diseases without risking sensitive information.
Finance
In the financial sector, synthetic data is used to train LLMs for fraud detection and risk assessment. This data allows for the simulation of rare market conditions and fraudulent activities, ensuring that models can respond effectively to unexpected situations.
Autonomous Systems
Developers in the autonomous vehicle industry rely on synthetic data to train models for various road scenarios, including rare and dangerous events. This method significantly enhances the safety and reliability of self-driving systems without real-world testing risks.
NVIDIA has demonstrated the power of synthetic data in autonomous vehicle development through their DRIVE Sim platform, which generates high-fidelity, realistic data to train AI models. This approach helps simulate complex driving situations, improving the models’ ability to handle unexpected conditions and boosting overall performance.
Education and Research
Stanford University utilized synthetic data for instruction tuning, refining LLMs to understand and follow complex instructions. By using the Self-Instruct method, researchers fine-tuned Meta’s LLaMA 7B model with 52,000 synthetic instruction examples. This reduced the need for human-created data and showed that synthetic data could help models understand and follow tasks better.
The Alpaca model’s success, similar to advanced models like OpenAI’s text-davinci-003, shows us how synthetic data can improve LLM performance for complex, specific uses.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is an example of synthetic data?
Synthetic data could be an artificially generated dataset that mimics real-world data, such as simulated user interactions or fabricated sensor readings for testing models.
What is synthetic training data?
Synthetic training data is artificially created data used to train machine learning models. It mirrors real data's characteristics but is generated through algorithms or simulations.
How to generate synthetic data to train LLM?
- Identify and select specialized tools or scripts for synthetic data generation based on real data structures.
- Preprocess your source data to create a strong template or seed for generating new data.
- Apply techniques like data augmentation, algorithmic simulations, or use smaller LLMs to create varied and realistic text data.
- Review and fine-tune the output to ensure it maintains coherence and relevance to the training goals.
- Use the synthetic data as part of your LLM training, adjusting parameters as needed for optimal results.
Can LLMs generate synthetic data?
Yes, LLMs can generate synthetic data by creating text outputs based on prompts or simulating conversations, which can be used for training or testing models.
How to create synthetic data for machine learning?
- Choose the appropriate method for your needs, such as generative models (e.g., GANs), rule-based algorithms, or data augmentation tools.
- Preprocess your existing dataset to ensure consistency and structure that the chosen method can work with.
- Implement the method for synthetic data generation that matches the characteristics of the original data.
- Validate the generated data by comparing it to real data to ensure quality and distribution alignment.
- Integrate the synthetic data into your machine learning pipeline for training or testing.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.