Data Labeling Outsourcing: Expert Guide for ML Teams

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

TL;DR
- Outsource labeling for volume spikes, multilingual data, or compliance-heavy projects; keep it in-house for unstable schemas or safety-critical tasks.
- Define schema and QA rules, pick the right vendor model, run a pilot, and set SLAs before scaling.
- Costs depend on task time and hourly rates, with hidden spend from schema churn, reviews, and rework.
- Managed services, platforms, and marketplaces fit different needs – check QA methods, expertise, and certifications.
- Prioritize vendors with model-in-the-loop support, RLHF/LLM skills, and ethical sourcing, and always begin with a pilot.
Top Use Cases for Data Labeling Outsourcing
ML teams often outsource data annotation when:
- Volume spikes overwhelm internal capacity and require rapid scale-up
- Multilingual datasets demand native speakers across many languages
- Compliance-heavy projects in healthcare or finance need vendors with HIPAA, ISO 27001, or SOC 2 certifications
Outsourcing is less effective when labeling rules change frequently, when errors could put safety at risk, or when tasks rely on deep proprietary expertise. In those cases, in-house or hybrid setups offer better control and context.
How to Outsource Data Labeling
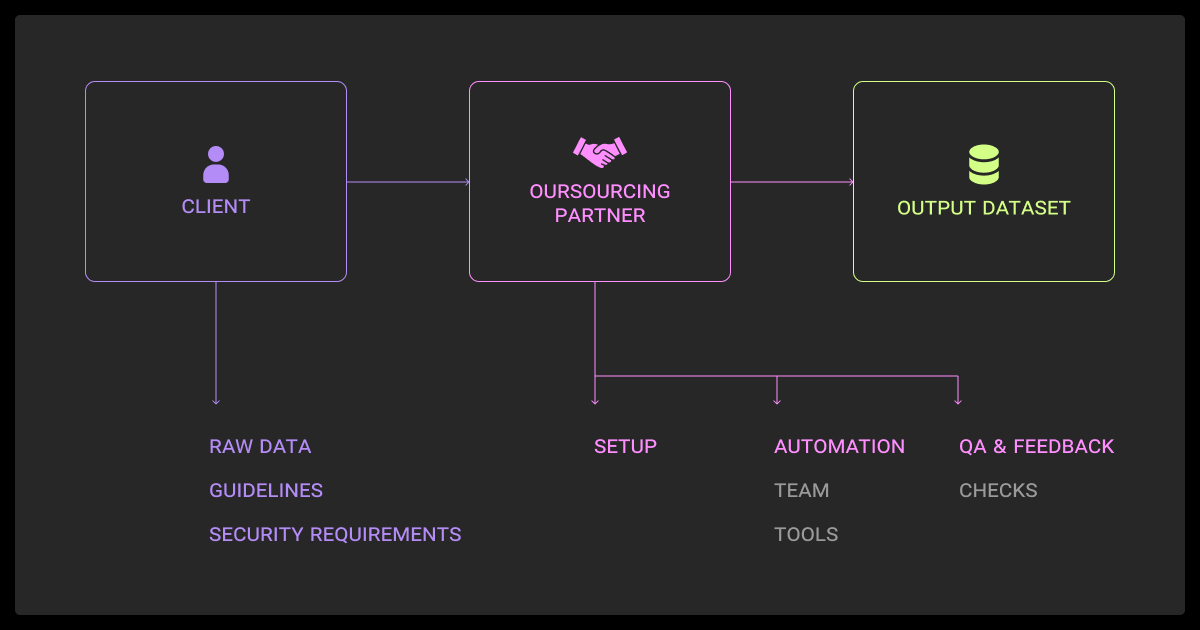
Data labeling outsourcing works best when you approach it as a structured process, not a hand-off. Here are 5 steps to keep your ML projects on track:
Set schema and QA
Start with clear instructions. Document label definitions, edge cases, and sample annotations. Create a small gold dataset to check vendor output. Set measurable standards such as 95% accuracy or ≥0.80 inter-annotator agreement. This preparation makes dataset quality measurable instead of subjective.
Pick vendor model
Vendors fall into three categories. Pick the model that matches your project’s data type, compliance needs, and tolerance for risk:
- managed services
- platforms with built-in workforces
- and open marketplaces
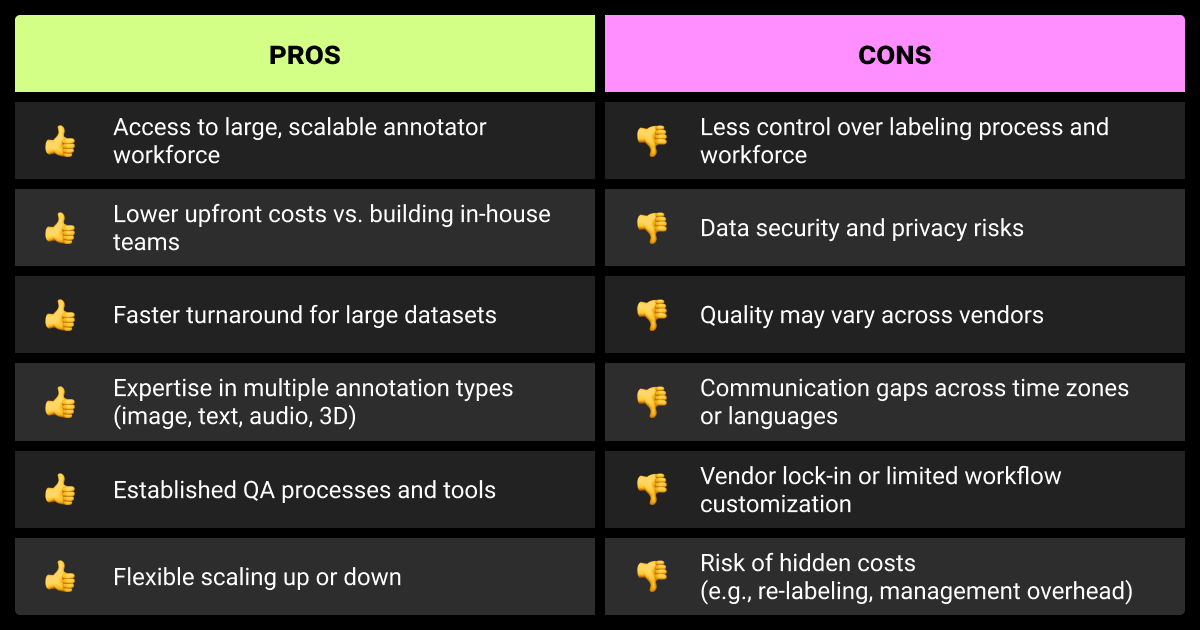
Managed data annotation services handle the full pipeline and fit complex, high-risk projects. A data annotation platform helps you balance control with outside labor. Marketplaces are cheap but require heavy internal oversight.
Run a pilot first
Always test before scaling. Use 1-5% of machine learning datasets, including edge cases. Measure accuracy, turnaround time, and how quickly the vendor adapts after feedback. Most providers offer free or discounted pilots – take them, and compare results across multiple data annotation companies in the US or else.
Lock down SLAs
Quality and speed should be written into the contract. Define accuracy thresholds, throughput commitments, and timelines for rework. Set escalation paths with clear contacts and response times. A vendor unwilling to commit to numbers is unlikely to deliver consistently.
Audit outputs
Even after rollout, keep auditing batches against your gold data, track inter-annotator agreement, and watch cost trends. Flag drops in accuracy early, and review edge-case handling regularly. If results don’t hold, adjust scope or switch vendors before the impact reaches model performance.
General instructions are never enough. Even small inconsistencies in labeling can drag down model performance. Today I’d invest more upfront in detailed annotation guides, edge-case scenarios, and feedback loops to align expectations early.

Managing Cost, QA, and SLAs in Practice
Outsourcing data labeling saves time only if data annotation pricing is predictable and quality holds steady. Check the main drivers of spend, common hidden costs, and the QA and SLA practices that keep projects on track.
Cost drivers and formula
The base formula is:
| Total cost = items × minutes per item × hourly rate × (1 + review + rework) |
Bounding boxes average $0.02-$0.04 per object, while polygon or semantic segmentation usually starts at $0.06 per label and rises with complexity. Hourly rates range from $4–6 in lower-cost regions to $30+ for domain experts in North America or Europe. Adding QA and rework pushes prices higher.
Vendors often frame budgets in tiers. For example, $5k–$10k+ for mid-size annotation-only projects.
Hidden costs
Schema changes force retraining and slow output. Internal reviews and feedback cycles eat into your team’s time. Tooling or custom integrations may add setup fees. Poor quality creates the biggest drain: fixing large volumes of mislabeled data delays model training and adds vendor or staff rework.
SLA essentials
Write clear targets into the contract:
- Accuracy thresholds (often 95–97%, higher for safety-critical work)
- Throughput commitments (e.g., 10k images every 2 weeks)
- Rework turnaround (usually 24-48 hours)
- Escalation contacts and response times
Vendors unwilling to commit to numbers or rework terms should be ruled out.
Quality management
Strong QA combines vendor checks with your own audits. Common methods:
- Tiered reviews: multiple layers of review, often hitting 98–99% accuracy in production
- Gold datasets: hidden test items to track annotator accuracy
- Inter-annotator agreement: target ≥0.80 for consistency
- Active learning: send uncertain samples flagged by your model for manual review, cutting label volume by up to 30–70%
Risk mitigation
Check for compliance certifications (ISO 27001, SOC 2, HIPAA, and GDPR are the certifications data annotation experts maintain at Label Your Data). Define IP ownership in contracts. For sensitive data, consider hybrid setups that keep the most critical samples in-house. Ask vendors about workforce practices – ethical sourcing reduces churn and quality issues.
I once chose a vendor mainly on low cost and ignored data lifecycle value. The result was higher relabeling expenses that erased any savings. The real lesson: look at accuracy, scalability, and long-term impact – not just the invoice.

 Founder, Deep AI
Founder, Deep AI
How to Vet Data Labeling Outsourcing Vendors
Choosing the right vendor is as important as setting the right process. A weak partner will cost you in rework and delays. A strong one will deliver quality data you can trust. Here’s how to evaluate providers effectively.
Data labeling outsourcing models
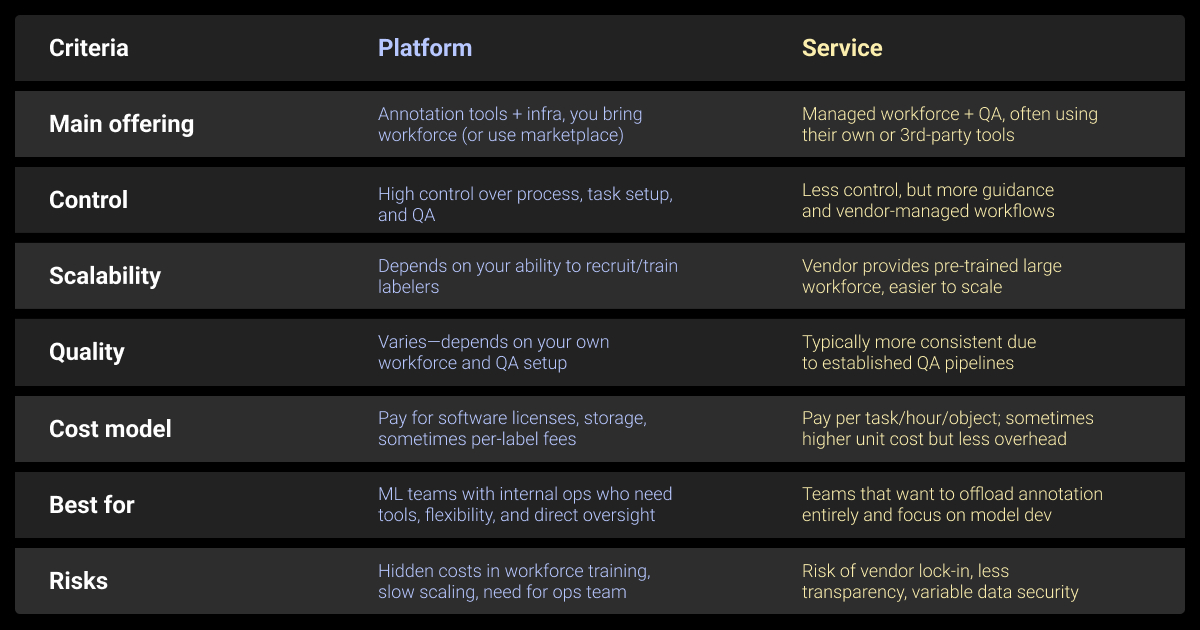
Three main options exist:
- Managed service. Full-package providers that handle workforce, tools, QA, and project management. Best for complex or regulated work.
- Platform + workforce. Annotation tools with an on-demand pool of annotators. Suits teams that want visibility and some control.
- Marketplaces. Open crowdsourcing platforms. Cheap and flexible but demand heavy internal QA and aren’t suited for sensitive data.
Key evaluation criteria
Ask vendors about their:
- QA process. How do they measure accuracy? Look for multi-level review, gold sets, or inter-annotator checks.
- Domain expertise. Do they have proven projects in your industry, like medical imaging, geospatial, NLP, or defense tech?
- Security and compliance. ISO 27001, SOC 2, HIPAA, or GDPR, depending on your domain.
- Integration. Can their platform connect with your ML pipeline or preferred tools?
- Scalability. How fast can they add annotators without quality drop?
Red flags
Avoid vendors who:
- Refuse pilot projects or trials
- Are vague about QA methods or accuracy metrics
- Promise “unlimited scale” or “100% accuracy”
- Delay or avoid sharing references
- Have no clear answers on security or compliance
Which vendor setup should you pick?
| Use case | Managed service | Platform + workforce | Marketplace |
| Complex, high-risk domains | ✅ Strong fit | ⚠ Needs domain training | ❌ Weak fit |
| Large, standard tasks | ⚠ Costly | ✅ Balanced choice | ✅ If QA is strong |
| Regulated industries | ✅ Best for compliance | ⚠ Check certifications | ❌ Risky |
| Tight budgets | ❌ Expensive | ⚠ Moderate | ✅ Cheapest |
| Long-term partnership | ✅ Reliable | ✅ Stable | ⚠ High turnover |
Pick a data annotation company based on project type, internal QA capacity, and compliance needs. The right model depends less on vendor marketing and more on how well their strengths align with your dataset and risk profile.
Making the Right Data Labeling Outsourcing Decision
The choice between in-house vs outsourcing data annotation depends on your data and goals. This year, three factors stand out:
- Model-in-the-loop. Vendors that support AI-assisted pre-labeling save cost and surface edge cases faster.
- RLHF and LLM tasks. Not every provider can handle preference ranking or nuanced text annotation; check this early.
- Ethical sourcing. Worker conditions now affect stability and reputation. Favor vendors with transparent practices.
Use this quick guide:
- Outsource for scale, multilingual data, or strict compliance.
- Hybrid if you want control of edge cases or sensitive data while outsourcing bulk work.
- In-house for unstable schemas, safety-critical projects, or proprietary expertise.
Before signing, ask every vendor:
- How do you support model-in-the-loop workflows?
- What experience do you have with RLHF or LLM labeling?
- What accuracy rates and QA methods do you commit to?
- Which certifications (ISO 27001, SOC 2, HIPAA, GDPR) do you hold?
- Can we start with a pilot on our data?
These questions separate vendors who fit your needs from those selling generic promises.
We learned precision at scale doesn’t come from automation – it comes from alignment. Clear documentation isn’t enough; you need interactive onboarding, smaller pilot batches, and direct communication channels to keep annotators aligned with your goals.

Why You Need to Run a Pilot Before Committing
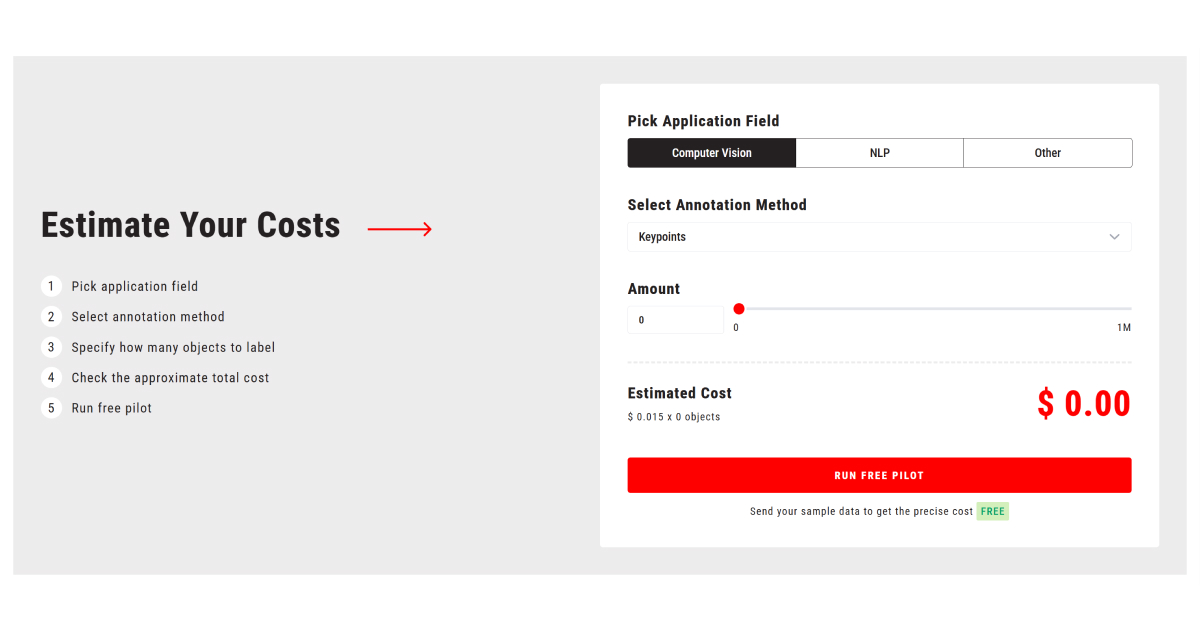
A pilot is the lowest-risk way to test a vendor before locking into a contract. Skipping this step often leads to mislabeled data, higher costs, and weeks of lost work.
During a pilot, measure:
- Error rates. Compare results to your gold set to see if accuracy meets your bar
- Throughput. Check if the team delivers batches at the pace you need
- Rework. Track how many items come back for correction and how quickly they are fixed
- Edge cases. Seed tricky samples and see how annotators handle them
After the pilot, you’ll know if the vendor can meet your standards. If results are solid and issues are fixable with feedback, scale the engagement. If not, you can exit early with minimal cost.
Many providers now offer free pilots, including Label Your Data, where you can run a no-commitment test of data labeling outsourcing services or platform risk-free. This lets you validate quality before spending on full-scale labeling.
About Label Your Data
If you choose to delegate data labeling, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What are the biggest risks in data labeling outsourcing?
The main risks are quality drift, hidden costs, and security gaps. Vendors that miss accuracy targets can force expensive relabeling and delay model training. Changing schemas mid-project adds retraining overhead. Compliance failures can expose you to regulatory fines if sensitive data is mishandled. There’s also reputational risk if vendors underpay or mistreat annotators.
These risks can be managed with pilots, clear SLAs, continuous audits, and by working only with vendors that hold certifications like ISO 27001, SOC 2, or HIPAA.
What is a data labeling service?
A data labeling service is a provider that tags raw data, like images, text, audio, or video, so it can be used to train machine learning models. Services range from simple bounding boxes to complex tasks like semantic segmentation, text sentiment labeling, or medical image annotation. Providers may also supply tools, quality checks, and workforce management.
When does it make sense to outsource data labeling instead of building an in-house team?
Outsourcing makes sense when your data volumes are too large for a small internal team, when you need rapid scaling, or when projects require multilingual coverage. It’s also practical in regulated industries (healthcare or finance, for example), where certified vendors can meet compliance faster than building processes internally.
Startups and smaller ML teams often outsource early to save on headcount and infrastructure, while enterprises use it to cover spikes or long-tail labeling needs.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.