10 Best Databricks Competitors & Alternatives (Ranked & Compared)

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- How Databricks Competitors Fill the Platform Gaps
- Label Your Data: Best Databricks Alternative for Training Data Annotation
- Snowflake: Best Cloud Data Platform Alternative
- Google BigQuery: Best Serverless Data Warehouse Alternative
- Amazon Redshift: Best Data Warehouse in AWS Ecosystem
- Azure Synapse Analytics: Unified Analytics on Microsoft Cloud
- Cloudera Data Platform: Hybrid Data Cloud Alternative
- Amazon EMR: Best Managed Spark/Hadoop Alternative
- Google Cloud Dataproc: Lightweight Managed Spark/Hadoop
- Teradata Vantage: Enterprise Analytics & MPP Alternative
- IBM Cloud Pak for Data: AI & Analytics Platform Alternative
- How to Choose Databricks Competitors for Your ML Stack Needs
- The Missing Layer in Most Databricks Pipelines
- About Label Your Data
- FAQ

TL;DR
- Databricks is one of the most widely adopted cloud data platforms for analytics, ML, and lakehouse workloads.
- But not all teams need the full Databricks stack. Some teams need tools Databricks simply doesn’t offer (like human-in-the-loop data labeling).
- Top Databricks competitors landscape spans multiple categories: data warehouses, lakehouse platforms, MPP systems, Spark engines, and annotation platforms.
- The right Databricks alternative depends on your stack, including your team’s maturity, regulatory needs, and ML workflow.
How Databricks Competitors Fill the Platform Gaps
Databricks is a leading choice for teams building data and ML pipelines. It combines lakehouse storage, Spark processing, and ML tooling in one platform. But not every team needs the full Databricks stack, and some need features Databricks simply doesn’t offer.
Human-in-the-loop data annotation is one major gap. At this point, ML teams start looking for the best Databricks competitors 2025.
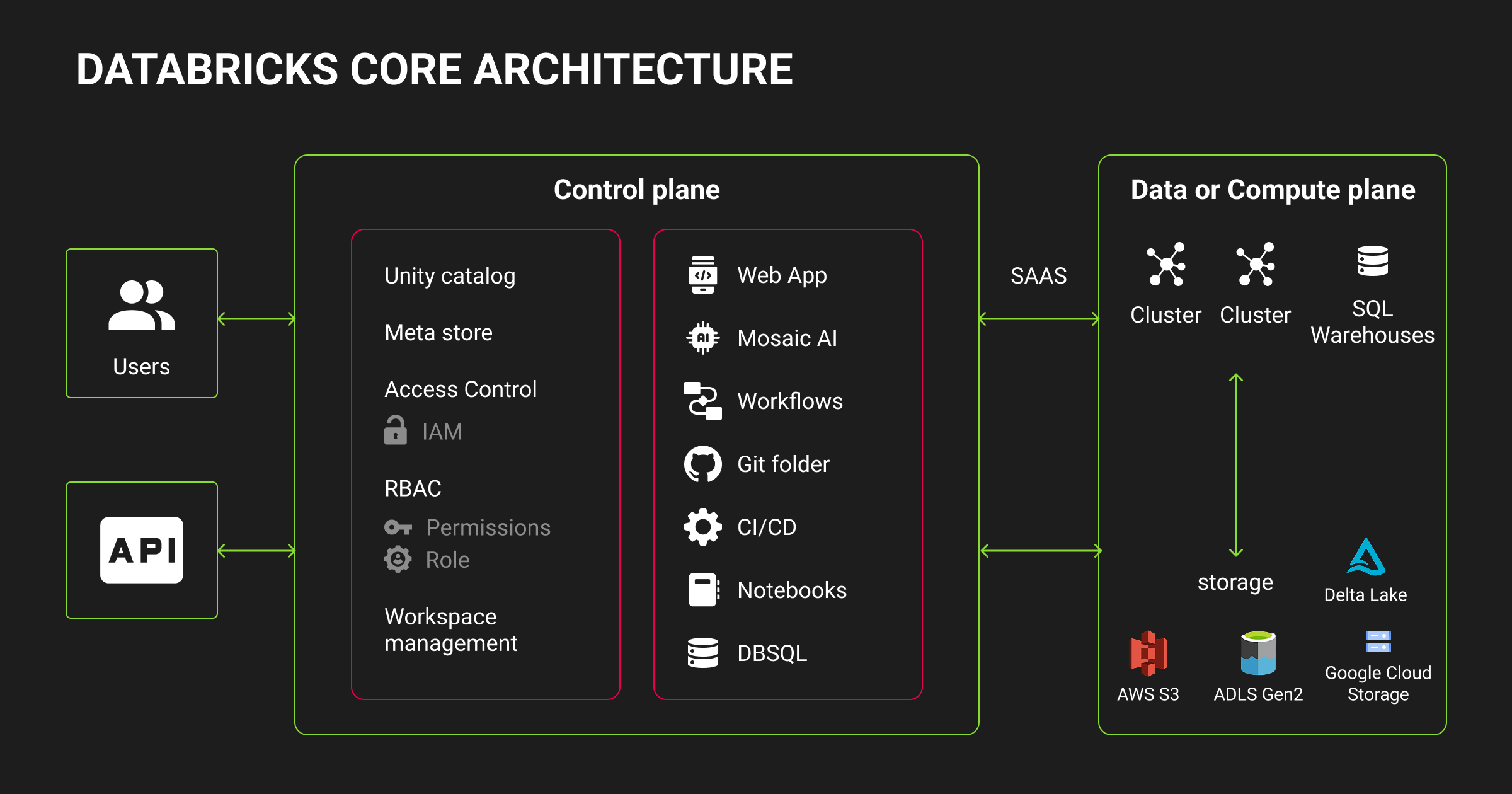
Databricks has no native annotation system. ML teams using it often need a separate provider for labeling, QA, and dataset management. That’s where Label Your Data comes in — a top Databricks alternative built specifically for training data workflows, domain-specific labeling, and scalable annotation operations.
Beyond annotation, the Azure Databricks alternatives landscape includes cloud data warehouses (like Snowflake and BigQuery), Spark-native engines (like EMR), hybrid data platforms (like Cloudera), and enterprise analytics stacks (like IBM Cloud Pak).
This article compares the 10 strongest Databricks competitors across cloud data, analytics, and ML infrastructure, starting with the one alternative that solves Databricks’ biggest gap.
Label Your Data: Best Databricks Alternative for Training Data Annotation
Databricks is built for analytics, Spark compute, and ML model development. But it doesn’t solve a key problem in real-world ML: sourcing and managing labeled training data. Without high-quality data annotation services, even the most advanced pipelines fail to generalize. And this is where Databricks stops short.
Label Your Data fills this gap with dedicated human-in-the-loop annotation services and a self-serve data annotation platform for computer vision tasks. While Databricks integrates with tools like Labelbox, it lacks built-in QA workflows, domain-expert labeling teams, or validation loops. ML teams still need a reliable partner to build, verify, and maintain training datasets at scale.
Where Databricks falls short:
- No built-in annotation UI or workflow tools
- No quality control or human validation layers
- No support for regulated domains or custom taxonomies
- No scalable workforce for manual labeling
What Label Your Data offers instead:
- Dedicated annotators trained in domains like medical imaging, retail classification, and OCR
- Built-in QA layers: gold sets, consensus review, inter-annotator agreement
- Seamless API integration
- Project oversight, feedback loops, and flexible data annotation pricing for scaling teams
If your ML models depend on accurate, diverse, and audit-ready datasets, Label Your Data is the most complementary alternative to Databricks, purpose-built for the step Databricks doesn’t cover.
Databricks changed expectations by linking data, labeling, and pipelines, so credible alternatives must meet or exceed that bar. The critical dimensions include dataset versioning, lineage, and access control; real pre‑labeling and active learning; unified DevEx and experiment tracking; strong compliance; cost visibility and drift monitoring; and extensibility for custom validators or document workflows. These are the foundations for scalable document AI.

 CGO & Co-founder, Addepto
CGO & Co-founder, Addepto
Snowflake: Best Cloud Data Platform Alternative
Snowflake is often the top alternative to Databricks for teams focused on scalable, SQL-first analytics. While Databricks emphasizes Spark compute and ML workflows, Snowflake wins on simplicity, concurrency, and performance for structured data workloads.
It offers a fully managed, cloud-native warehouse with strong support for semi-structured data, automatic scaling, and a usage-based pricing model that separates storage and compute. For teams running BI dashboards, ELT pipelines, or analytics-heavy workloads, Snowflake is often easier to adopt and operate than Databricks.
Where Snowflake excels:
- Native SQL interface and deep ecosystem integration (Tableau, dbt, Fivetran)
- Fast performance with automatic scaling and clustering
- Strong governance, access control, and secure data sharing (Data Clean Rooms)
- Marketplace of third-party datasets and apps
Where it differs from Databricks:
- No native Spark engine or ML-focused tooling
- Limited flexibility for custom workflows or large-scale ML training
- Stronger focus on analytics over ML experimentation
Snowflake is ideal for teams who need fast, reliable querying on large datasets without the overhead of managing Spark clusters or complex ML pipelines.
Google BigQuery: Best Serverless Data Warehouse Alternative
BigQuery is Google Cloud’s fully managed, serverless data warehouse built for lightning-fast SQL analytics at scale. It’s a strong Databricks alternative for teams prioritizing cost-efficient, low-ops querying over ML-native workflows.
BigQuery eliminates infrastructure setup; queries run instantly across massive machine learning datasets using a pay-per-use model. It integrates tightly with Google’s data stack (Dataflow, Looker, Vertex AI) and supports federated queries across formats like Parquet, CSV, and JSON in Cloud Storage.
Why teams choose BigQuery:
- No provisioning or tuning required (serverless by design)
- Competitive pricing via on-demand or flat-rate billing
- SQL-native experience with strong BI tool support
- Federated queries and materialized views for modern ELT
How it compares to Databricks:
- Prioritizes analytics, not Spark or ML workflows
- Not optimized for iterative ML development
- Limited support for real-time feature engineering or custom pipelines
For teams with SQL-heavy workloads, dashboards, or cost-sensitive analytics at scale, BigQuery delivers speed and simplicity without the Spark overhead of Databricks.
Amazon Redshift: Best Data Warehouse in AWS Ecosystem
Redshift is Amazon’s managed, petabyte-scale data warehouse designed for teams building analytics pipelines inside the AWS ecosystem. If you already use S3, Lambda, or SageMaker, Redshift offers tight integration and predictable performance without Databricks’ Spark-based stack.
Built on a Massively Parallel Processing (MPP) architecture, Redshift supports complex joins, fast aggregations, and high concurrency. It also offers Redshift Spectrum for querying data in S3 directly, and ML-powered features like materialized views, auto-scaling, and data sharing.
Why Redshift is a Databricks alternative:
- Seamless with AWS services: S3, Glue, Athena, SageMaker, etc.
- Strong performance for BI workloads, especially with concurrency scaling
- Easier for SQL teams to onboard vs. Spark environments
- Redshift ML enables SQL-based model training without switching platforms
Limitations vs. Databricks:
- Less suited to flexible ML pipelines or model development
- Not designed for lakehouse architectures or multimodal datasets
- Fewer options for custom pipeline orchestration or annotation integration
Redshift is ideal if you're already deep in AWS and need a performant, SQL-native analytics engine without switching to Databricks' Spark-heavy paradigm.
Azure Synapse Analytics: Unified Analytics on Microsoft Cloud
Azure Synapse Analytics blends SQL data warehousing and Apache Spark into one hybrid analytics platform. It’s built for Microsoft-first teams that need unified data storage, transformation, and analytics in one place, without adopting a full Databricks deployment.
Synapse supports both serverless and provisioned compute, offers native integration with Azure Machine Learning, and works seamlessly with tools like Power BI and Azure Data Factory. For teams already operating in Microsoft environments, it eliminates the overhead of stitching together services.
Why Synapse is a Databricks alternative:
- Combines T-SQL and Spark notebooks in one interface
- Deep integration with Microsoft tools (Excel, Power BI, Azure ML)
- Security and governance via Azure Active Directory and Purview
- Lower operational overhead for teams standardizing on Azure
Limitations vs. Databricks:
- Fewer options for advanced ML workflows and custom environments
- Not optimized for large-scale unstructured or multimodal data
- Less community adoption and third-party integration flexibility
If your data team uses Microsoft tools across the stack, Synapse is one of the best native, manageable alternatives to Databricks with smoother collaboration across engineering and business users.
Cloudera Data Platform: Hybrid Data Cloud Alternative
Cloudera Data Platform (CDP) is built for enterprises that need flexible deployment: public cloud, private cloud, or on-premises, without compromising on data lakehouse capabilities. It appeals to teams in finance, government, and healthcare where security, compliance, and data residency are non-negotiable.
CDP combines Hadoop, Hive, Impala, and Spark under one secure platform with fine-grained access control. It supports data engineering, streaming, ML, and BI workloads across hybrid environments. That makes it ideal for legacy migrations or regulated data pipelines.
Why Cloudera is a Databricks alternative:
- Supports hybrid and on-prem deployments
- Strong governance and lineage with Apache Atlas
- Built-in security (Kerberos, Ranger), meets strict compliance needs
- Integrates with ML tooling and workload management
Limitations vs. Databricks:
- More complex to manage and deploy compared to SaaS-first platforms
- Slower iteration velocity without managed services
- Less focus on deep learning and unstructured data at scale
Cloudera is a strong Databricks alternative for enterprises that prioritize control, governance, and hybrid architecture over fast cloud-native adoption.
Amazon EMR: Best Managed Spark/Hadoop Alternative
Amazon EMR is AWS’s managed cluster platform for big data frameworks like Apache Spark, Hadoop, Hive, and Presto. It’s one of the most direct infrastructure-level alternatives to Databricks, especially for teams that already build in the AWS ecosystem and want granular control over cluster configuration and cost.
EMR lets you spin up Spark clusters quickly and integrate them with S3, Glue, Redshift, and SageMaker. For ML teams running large-scale preprocessing, ETL, or custom pipelines, EMR offers flexibility without vendor lock-in.
Why EMR is a Databricks alternative:
- Native Spark support without Databricks’ platform overhead
- Deep AWS service integration: IAM, VPC, S3, CloudWatch, Lake Formation
- Cost control via spot instances and auto-scaling
- Highly customizable runtime environment for specialized workloads
Limitations vs. Databricks:
- No built-in notebooks, MLflow integration, or collaborative UI
- Steeper learning curve and more ops overhead
- Requires manual tuning for performance and reliability
Amazon EMR is best for engineering teams that value infrastructure-level flexibility, already use AWS, and want full control over Spark-based data and ML workloads.
Google Cloud Dataproc: Lightweight Managed Spark/Hadoop
Google Cloud Dataproc is a managed Spark and Hadoop service built for teams that want fast, cost-effective batch and streaming pipelines. It’s a leaner, simpler alternative to Databricks for Spark-native workflows, especially when paired with other GCP tools like BigQuery, Vertex AI, and Cloud Storage.
Dataproc clusters spin up in under 90 seconds and can autoscale, shut down when idle, and use custom machine types. For ML and analytics teams that need flexibility without platform lock-in, Dataproc offers a lower-overhead path to run Spark jobs at scale.
Why Dataproc is a Databricks alternative:
- Native Spark/Hadoop support with lightweight GCP integration
- Seamless connection to GCS, BigQuery, Pub/Sub, and Vertex AI
- Fine-grained resource control and preemptible VM support
- Compatible with open-source tooling and custom JARs/scripts
Limitations vs. Databricks:
- No integrated notebooks or MLflow UI
- Manual job orchestration and monitoring
- Lacks the collaborative, all-in-one experience of Databricks
Among many competitors of Databricks, Dataproc is best for teams on Google Cloud that want fast, flexible Spark/Hadoop jobs without the extra costs or constraints of an opinionated ML platform.
Teradata Vantage: Enterprise Analytics & MPP Alternative
Teradata Vantage is an enterprise-grade data platform that combines massively parallel processing (MPP), SQL analytics, and hybrid cloud deployment. It appeals to teams with legacy Teradata investments or those prioritizing high concurrency, strong governance, and deep enterprise integration.
Vantage supports advanced analytics across cloud and on-prem environments, with a focus on workload management, operational efficiency, and enterprise SLAs. While not built for Spark-native ML workflows, it’s a strong Databricks competitor for structured data processing at scale.
Why Teradata is a Databricks alternative:
- Mature MPP engine with high-performance SQL analytics
- Optimized for mixed workloads across data warehouses and lakes
- Hybrid cloud/on-prem deployment options for regulated industries
- Integrated governance, lineage, and role-based access controls
Limitations vs. Databricks:
- No Spark-native engine or native ML tooling
- Less flexibility for custom workflows or model development
- Smaller developer community and limited open-source integrations
Teradata is ideal for large enterprises modernizing legacy analytics environments that still demand hybrid infrastructure and high SLAs without migrating fully to Spark or lakehouse platforms.
IBM Cloud Pak for Data: AI & Analytics Platform Alternative
IBM Cloud Pak for Data is a unified platform for data, AI, and governance designed for enterprise ML and analytics pipelines. It offers an all-in-one architecture for building, deploying, and managing AI models, with strong emphasis on explainability, compliance, and secure collaboration.
Built on Red Hat OpenShift, Cloud Pak supports hybrid and multicloud environments. It includes tools for data virtualization, AutoML, model monitoring, and pipeline orchestration. While more heavyweight than Databricks, it’s preferred by teams requiring full lifecycle governance and auditability.
Why IBM Cloud Pak is a Databricks alternative:
- Enterprise-ready ML lifecycle tooling (Watson Studio, ModelOps, etc.)
- Integrated data governance, lineage, and privacy tooling
- Hybrid and multicloud deployment via OpenShift
- Designed for regulated industries with strict compliance needs
Limitations vs. Databricks:
- Less agile and developer-friendly for rapid experimentation
- Higher learning curve and infrastructure requirements
- Less Spark-native; slower iteration speed for small teams
IBM Cloud Pak for Data is best for enterprise ML teams prioritizing governance, security, and long-term model reliability, especially in regulated sectors like healthcare, finance, and government.
When scaling ML in enterprise environments, the key is whether a platform fits your existing Microsoft stack without extra integration work. The most impactful improvements come from systems that connect cleanly to SharePoint, Power BI, and Azure data lakes and expose annotation quality metrics directly in dashboards. Platforms that surface agreement rates, drift, and data lineage help teams fix label issues early instead of tuning models blindly.
 CEO, Netsurit
CEO, Netsurit
How to Choose Databricks Competitors for Your ML Stack Needs

Choosing the right solution among these Databricks main competitors depends on your team’s goals, cloud environment, and pipeline needs. Here's how to decide:
- Need lakehouse architecture? Use Snowflake for strong lakehouse features with SQL-native access and broad ecosystem support.
- Need a serverless data warehouse? Choose Google BigQuery or Amazon Redshift for analytics-heavy workloads and fast SQL execution at scale.
- Need Spark-based processing? Amazon EMR or Google Dataproc closely match Databricks’ Spark engine, offering flexible, lower-cost compute options.
- Need hybrid or on-premise deployment? Go with Cloudera or Teradata, which support hybrid workloads and strict data residency requirements.
- Need training data annotation? Pick Label Your Data, the only Databricks-compatible alternative purpose-built for scalable human-in-the-loop annotation.
- Need tight Microsoft integration? Use Azure Synapse Analytics for unified Spark and SQL in Microsoft-native environments.
- Need enterprise governance and AI lifecycle tools? Consider IBM Cloud Pak for Data for regulated, large-scale enterprise AI deployments.
Teams evaluating Azure Databricks competitors should focus on how well a platform integrates with existing governance, identity, and security controls. A strong alternative offers smoother end‑to‑end MLOps workflows with automated compliance checks and unified access management, reducing friction between data scientists and security teams rather than simply matching Databricks on features.

Choosing a platform that supports your machine learning algorithm type, from simple regression to transformer-based models, is key to infrastructure fit.
The Missing Layer in Most Databricks Pipelines
Databricks remains a top-tier platform for data engineering, analytics, and ML. But it’s not the only choice. Depending on your team’s needs, architecture, and workflows, alternatives to Databricks like Snowflake, BigQuery, and Amazon EMR may offer a better fit.
For ML teams building real-world pipelines, Databricks lacks a critical layer: human-in-the-loop data annotation. That’s where Label Your Data fills the gap by offering domain-specific labeling, QA, and scalable workflows that integrate seamlessly into training data pipelines.
Choose between the best Databricks main competitors 2025 we’ve outlined in this article based on what you’re optimizing for, and don’t overlook the role of labeled data in making your entire AI stack work.
About Label Your Data
If your Databricks pipeline needs human-verified training data, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
Do you really need Databricks?
Not always. Databricks is powerful for teams running large-scale data pipelines, Spark jobs, and ML workflows, but it’s overkill for simpler analytics or SQL workloads. If you don’t need lakehouse architecture, streaming, or model training, a warehouse like Snowflake or BigQuery may be a better fit.
Why is Databricks so expensive?
Databricks can be costly due to its compute-heavy Spark jobs, complex workloads, and premium features (like MLflow, Unity Catalog, Delta Live Tables). Pricing is usage-based but can escalate without careful job tuning, autoscaling, and cluster lifecycle management.
Who are Databricks competitors?
Top Azure Databricks competitors include Snowflake, Google BigQuery, Amazon Redshift, Azure Synapse, Cloudera, and IBM Cloud Pak. Plus, alternatives for specific layers like Spark engines (EMR, Dataproc) and hybrid data labeling solutions like Label Your Data.
Are Snowflake and Databricks competitors?
Yes. Snowflake and Databricks both offer cloud-native analytics platforms but differ in approach: Snowflake focuses on SQL-first data warehousing, while Databricks is Spark-based with strong ML and lakehouse support.
Is Snowflake or Databricks better?
It depends on your workload. Choose Snowflake for fast SQL analytics and native integrations. Choose Databricks if you need ML pipelines, Spark workloads, or unified lakehouse storage.
Are Databricks and Palantir similar?
No. Databricks is a cloud-native analytics and ML platform, while Palantir builds custom operational intelligence systems. They target different buyers and use cases: Databricks for engineering teams, Palantir for enterprise ops and defense analytics.
Is Databricks better on AWS or Azure?
Databricks runs well on both, but the experience depends on your existing cloud stack. Azure Databricks has deeper native integration with Microsoft tools (Active Directory, Synapse, Power BI), while AWS may offer more flexibility for Spark-native teams using S3 and EMR.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.