Labeled Data: Core to Training Supervised ML Models

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

TL;DR
- Labeled data links inputs to known outputs for tasks like classification and regression.
- It's critical for training models that generalize well in production.
- Manual labeling is resource-intensive; consider hybrid or semi-supervised workflows.
- Annotation strategies include in-house teams, outsourcing, crowdsourcing, and synthetic data.
- The right labeling method depends on scale, budget, domain complexity, and quality needs.
What Is Labeled Data in Machine Learning?
As the name suggests, labeled data (aka annotated data) is when you put meaningful labels, add tags, or assign classes to the raw data that you've collected for training a machine learning algorithm.
What is a label in machine learning? Let’s say you are building an image recognition system and have already collected several thousand photographs. You did this yourself or through expert data collection services. Labels would be telling the AI that the photos contain a ‘person’, a ‘tree’, a ‘car’, and so on.
The machine learning features and labels are assigned by human experts, and the level of needed expertise may vary. In the example above, you don't need highly specialized personnel to label the photos. However, if you have, say, a set of x-rays and need to train the AI to look for tumors, it's likely you will need clinicians to perform data annotation. Naturally, due to the human resources necessary, hand-labeling data is much more expensive than gathering raw unlabeled data.
What Is Labeled and Unlabeled Data in Machine Learning?
We've already discussed the major differences of labeled vs unlabeled data in our previous article but it won't hurt to remind the basics.
| UNLABELED DATA | LABELED DATA |
| Used in unsupervised machine learning | Used in supervised machine learning |
| Obtained by observing and collecting | Needs human to label |
| Comparatively easy to get and store | Expensive, hard and time-consuming to get and store |
| Often used to preprocess sets of data | Used for complex predicting tasks |
So we can see that, while labeled data is expensive and hard to get, it also offers a much wider array of possibilities. In a battle of labeled vs unlabeled data, the former ipso facto wins. Surely, you can (and should) use unlabeled data to train your AI. But you'll miss quite a lot of potential if you don't label it next.
What Can Labeled Data Do?
Labeled data makes the training process much more efficient and simple. The idea behind labeling data is to teach the AI to recognize patterns according to the task or target. This way, after the training process, the input of new unlabeled data will lead to predictable labels.
To put it simply, this means that you add labels to data and set a target, and the AI learns by example. The process of assigning the target labels is what we know as annotation. After the training period ends, your machine will be able to identify the presence of a 'person', a 'car', or a 'tree' in the new photos. Not only that but the AI trained on labeled data can be used for complex forecasting (e.g., predicting the prices on the stock market or suggesting additional products for the customer). Sounds fascinating, right?
Labeled Data in Machine Learning Models?
Labeled data is used mostly in supervised learning but also semi-supervised learning, in combination with unlabeled data. Let's take a deeper look into both of these types. We've included a bunch of examples to better explain the utility of labeled data.
Supervised Learning: Label Your Data
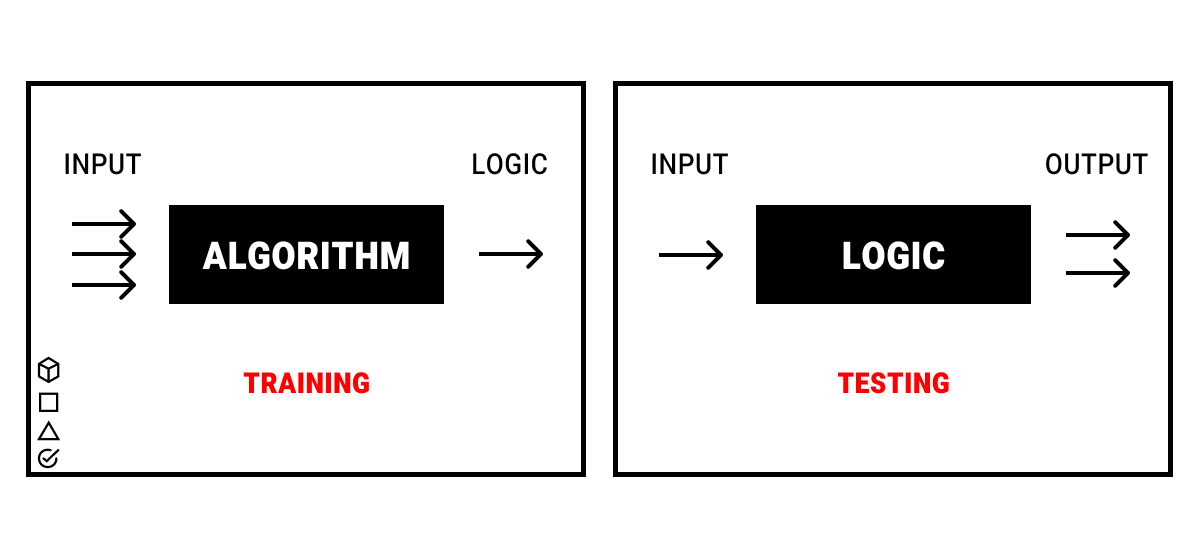
According to AltexSoft, "supervised machine learning entails training a predictive model on historical data with predefined target answers". Your machine learning dataset is used to teach the machine with a specific goal in mind. For a set of labeled emails, for example, you might need the AI to recognize patterns to predict buying behaviors.
Supervised learning (SL) is using machine language to classify and process data. According to these two major types of tasks, there are two main groups of methods in SL.
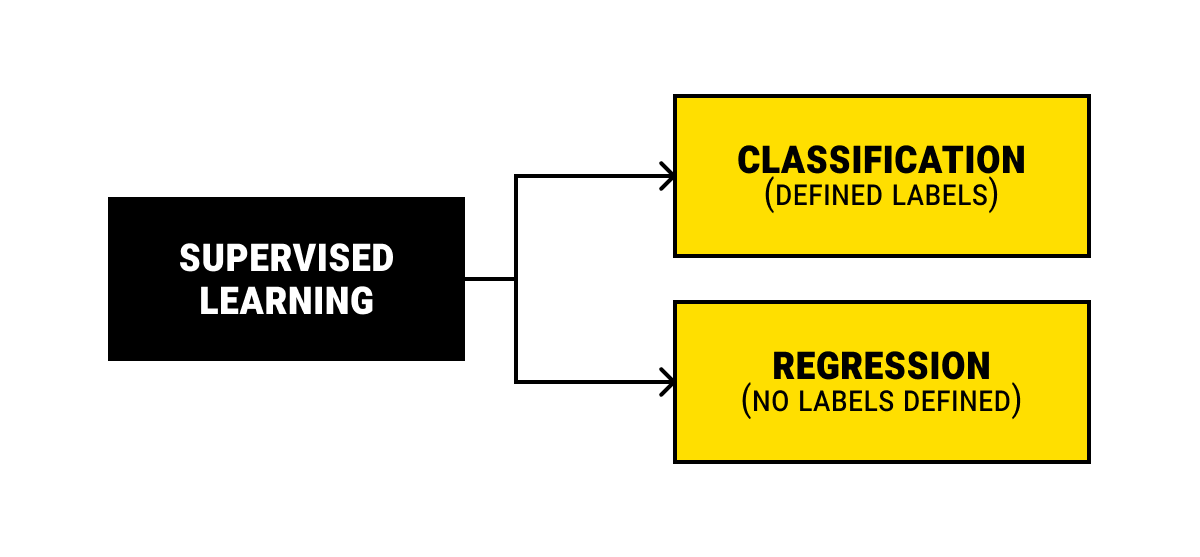
Classification
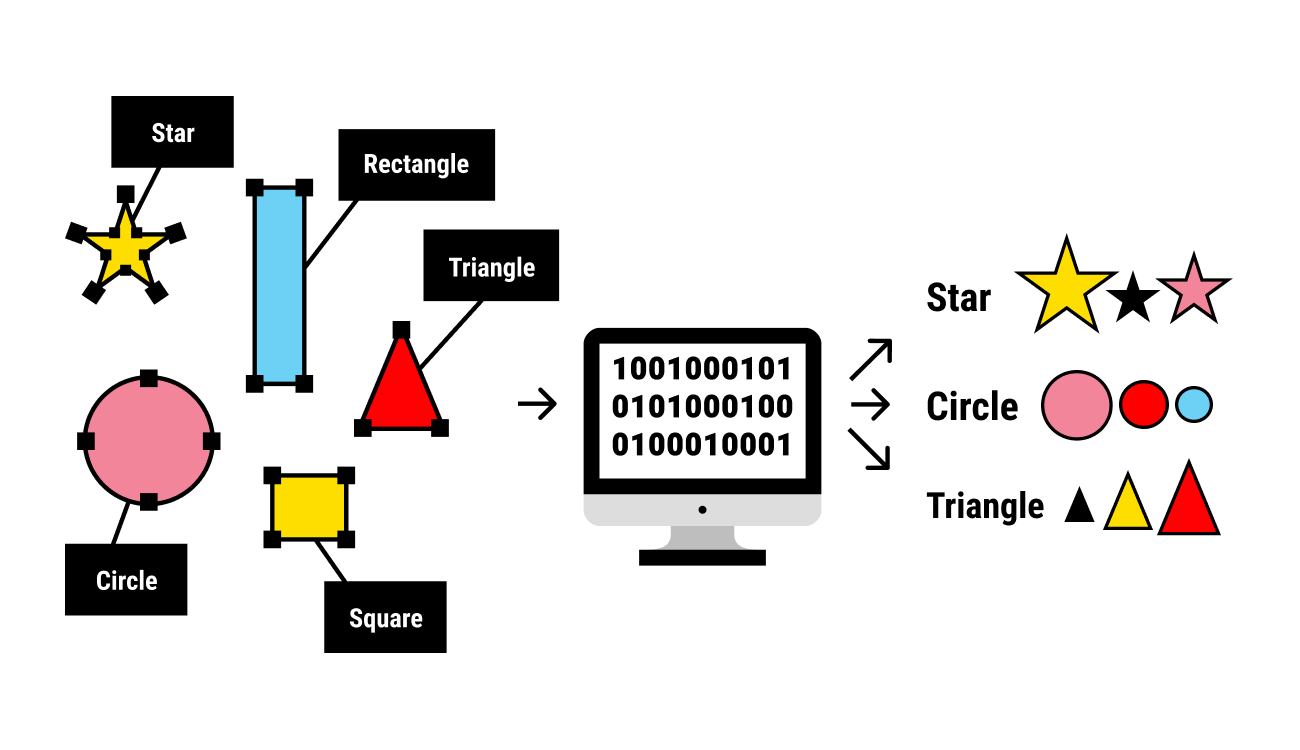
When you need the machine to tell the class of the data that you input, you use classification to train it. This group of methods are based on the analysis of data and spotting patterns in order to get qualitative responses (e.g. if a letter is spam or no, or if a photo has a car in it or a bicycle). While unlabeled data allows clustering the photos into groups, it cannot tell what those groups are. Labeled data used in supervised learning, on the other hand, trains AI not only to recognize different objects on the photos but also to tell what classes those objects belong to.
Now let's see how this works in practice. If you have a set of 10.000 emails labeled with 'spam' or 'not spam', classification trains your model to tell if the letters are spam. When the training is over, newly input letters will be classified into one of these two groups.
The input element can belong to several categories at once. When you train your AI on a set of photos tagged with 'person', 'car', 'tree', and 'house', it will be able to tell which objects are present on the new photos you add to the set. In addition, the model will tell you how confident it is about these predictions.
Linear Regression
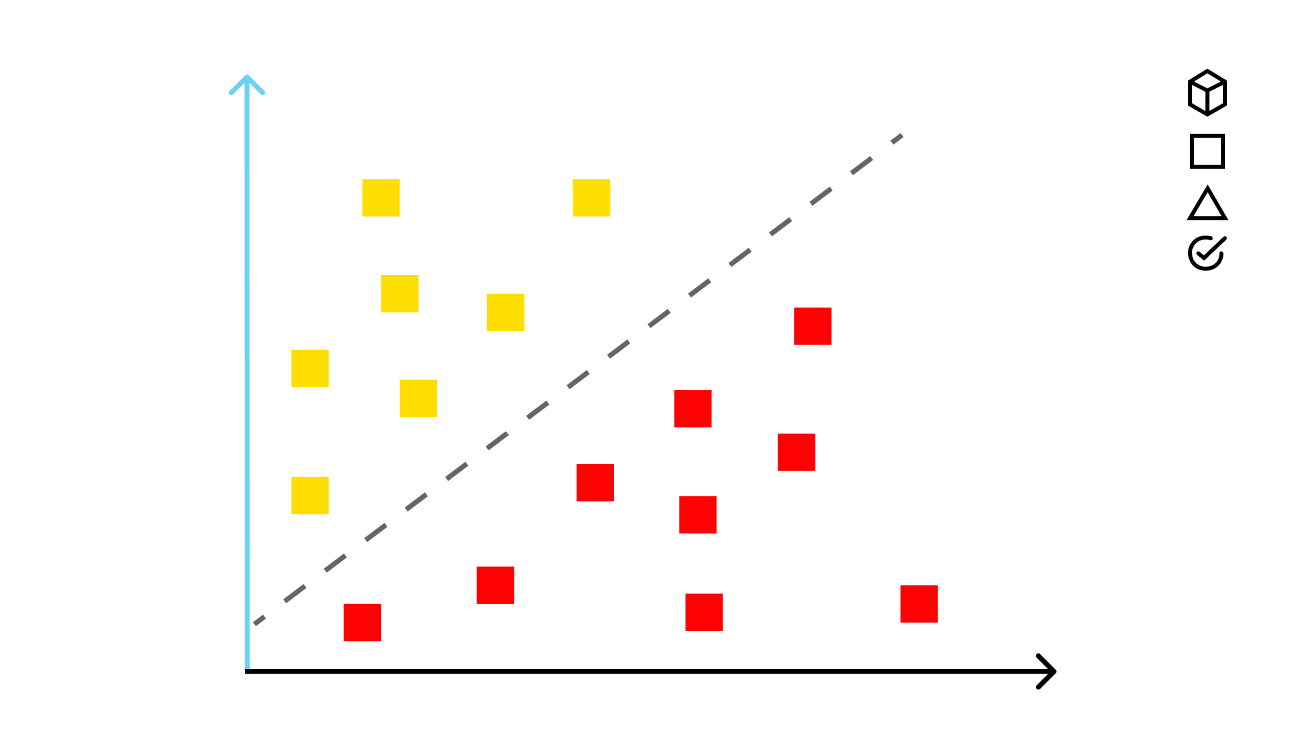
Linear regression (sometimes referred as reduction) methods take a different approach. They are used to recognize relationships in quantitative data by producing numerical values. E.g. within the example of the 10.000 emails, linear regression can answer the question if there is a relationship between additional marketing expenses and click-through rates (CTRs), and how strong it is.
Similarly to classification, regression problems usually have more than one input variable that impacts the target outcome. In addition to marketing expenses, the CTRs can be influenced by an increased number of products/services, a growing number of customers, etc. Such a type of regression is known as multiple linear regression.
Semi-Supervised Learning: Combining Labeled and Unlabeled Data
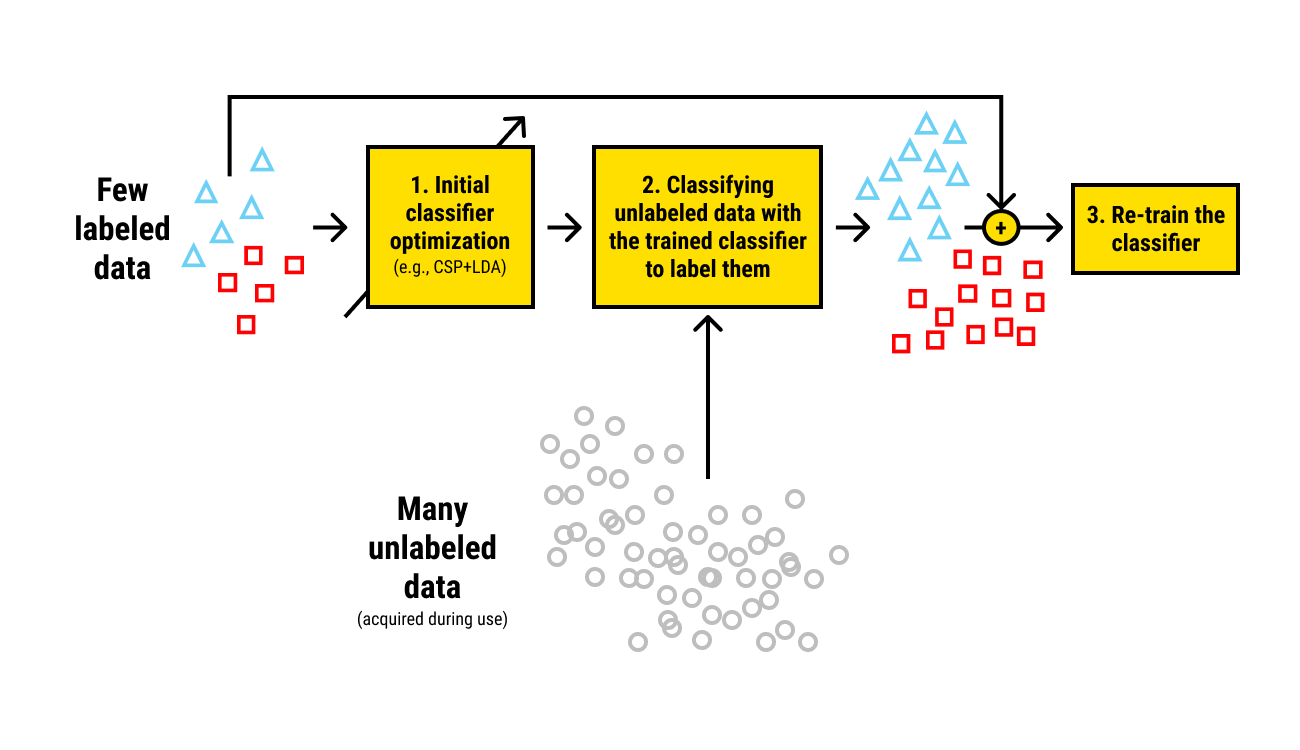
Obviously, labeled data is exactly what you need. However, you don't always have enough of it to train your AI. It is expensive and time-consuming to label thousands of images or emails, even more so if your field is highly specialized and requires highly skilled professionals to do the job. So what do you do?
Work with what you have. Combine the labeled data with unlabeled, an approach to machine learning known as semi-supervised learning. For these types of models, you don't need all of your data labeled; you just need certain data points. Semi-supervised learning allows you to use a small batch of labeled data to train your AI, and then apply this to the rest of the data that has no labels yet. Usually, you will need only around a quarter of your data labeled to build an effective semi-supervised model. As an outcome, you will get a big set of pseudo-labeled data.
Now let's return to that image recognition system you were supposedly building. You have 10.000 photos, only 2.500 of which are annotated with the labels 'car', 'house', 'person', etc. First, you use clustering on all your data to group it. Then you train the model on the labeled data. Afterward, you can maximize the effect on the rest of the batch to make sense of these clusters.
How to Label Data for Machine Learning?
Now that we know how to use labeled data, it’s time to ask another question: what is data labeling in machine learning as a process? The annotation starts with setting your goal and preparing the data. Then you choose between annotating all of it or a small sample that you'll use as an AI training ground in a semi-supervised learning model.
In order to label data, you need specialized software that allows adding labels to certain highlighted areas. You should choose an annotation method in accordance with your problem and the type of collected data (images, text, video, or audio). Here are a few of the most popular data annotation services:
- Polygon annotation
- Polylines annotation
- Semantic segmentation
- Bounding boxes
- Landmark annotation
- 3D cuboid annotation
You should choose an annotation method in accordance with your problem and the type of collected data (images, text, video, or audio). This becomes even more important when working with large language models, as different types of LLMs may require specific LLM data labeling strategies to match their use case and training objectives.
Know Your Options: Where to Get Annotation?
Keep in mind that the process of annotation is time-consuming and expensive. Let's take a look at the ways that you can go to label your data, their benefits and drawbacks, and the situations, for which each of these can be the best solution.
| Options | Benefits | Drawbacks | Ideal for |
| In-House | - Control - Adequate accuracy and quality | - Expensive - Time-consuming - Requires training the team of labelers | Big companies with the constant need for data annotation |
| Outsource | - High quality guaranteed - Less expensive - You focus on strategic tasks | - Lack of control | Short-time or small projectsLong-term partnerships for seasonal or periodic projects |
| Crowdsource | - Very cost-effective - Fast - Flexible | - Doubtful quality - Inconsistent annotation tools - Lack of control - Risk of missed deadlines | Small businesses that lack resources but can be more flexible with quality demands |
| Synthetic | - Time-effective - Large volumes of new data - High quality - No human factor | - Very expensive - Requires a lot of computational power | Hi-tech companies with very strict deadlines |
| Programmatic | - Time-effective - Automated | - Poor quality - You need a team of data reviewers | Businesses with QA teams and the opportunity to check for mistakes |
| Transfer learning | - Time-effective | - Finding team willing to share - Defining elements useful for a new problem | Training neural networks |
In-House
As the name suggests, this option requires you to build your own team of data professionals. It's a great approach if you are a big company that has a permanent flow of unlabeled data that needs annotation. The major benefit of this approach is that you have a lot of control over your team, as well as the annotation process. This ensures not only timeliness but also the quality of performance. However, you will need to allocate resources for the team of annotators, which is not always a viable option.
Outsource
Another common approach is to look for an expert data annotation company that specializes in data labeling, including image annotation services and video annotation services. They can ensure the quality and professional approach. The external group will not give you the fullest control over your project but will take a load off your shoulders instead and allow you to focus on strategic tasks instead. This is a great alternative for smaller companies or short-time projects. Also, if you know you'll be coming back from time to time with new batches of data, outsourcing gives you the opportunity to form long-term partnerships with added benefits of trust and improved communication.
Crowdsource
There are multiple platforms that allow you to enlist people from all over the world to work on your project. A huge appeal of this approach is its speed and flexibility: freelance data labelers take the tasks as soon as they become available. Besides, they are also quite cost-effective due to the high competitiveness of the field. On the other hand, mind the risk of missed deadlines and the inconsistency of annotation tools that vary from one platform to the other. In addition, these platforms cannot guarantee the high quality of the outsourcing option nor give the control that you have over the in-house team. Still, crowdsourcing a data labeling project is a good option for a small business that doesn't have enough resources but is flexible with quality demands and the use of annotation tools.
Synthetic
Aside from using human labelers, it's possible to generate new data by synthetic labeling. A popular way to do so is by using generative adversarial networks, or GANs. These create extremely realistic fake data with the necessary attributes from pre-existing sets of unlabeled data. We mentioned GANs in the article on unlabeled data , follow the link to learn more. The synthetic annotation approach is very time-effective since it doesn't require building a team of labelers. However, it still needs a lot of computational powers, which means this option is quite costly. You should consider synthetic labeling in case you are a hi-tech company that already has computational resources and time on your projects is of utmost importance.
Programmatic
Another option that doesn't require hiring data labelers is programmatic annotation. This option relies on the scripts and codes of machine learning that label data automatically. This means two things: first, it's time-effective, and second, it lacks quality. The latter specifically leads to the necessity of having not data labelers but data reviewers, a team of experts who will check the labeled data as it is being annotated by computers. Still, it's a good option if you have a quality assurance team, as well as room for checking mistakes.
Transfer Learning
Finally, yet another option to skip the need of hiring people to do the data labeling. Transfer learning allows repurposing the labeled data that was used for training AI in other projects. There are a lot of similar machine learning problems, so it makes sense to take the labeled data from other annotation teams. This way, you save time and human efforts. But the problem with this approach is finding the team willing to share their dataset and defining the essential elements that you can appropriate for your problem. Transfer learning is a great option for training neural networks (e.g. image recognition systems, human motion models, image segmentation, etc.).
So these are your choices. Most companies usually choose between in-house vs. outsourcing data annotation. To make the best decision, look at the resources at your disposal, consider the requirements of your project, and choose the option that suits you best.
Did You Have Your Data Labeled Yet?
Without a doubt, unlabeled data can be useful. But it can only be used for a limited number of tasks. If you want to train your AI properly, you cannot do without labeled data.
Annotating data opens a lot of opportunities and solutions. First and foremost, labeled data is used in supervised machine learning. The methods of classification and regression help to solve problems in the areas from bioinformatics (think fingerprint or facial recognition in modern smartphones) to automatic speech recognition to customer recommendation engines.
So how do you get annotated data? Well, you can do it yourself by training an in-house team or spending a handsome sum on computational power to do the job for you. Or you can transfer this problem to us! We'll take the burden of planning, training annotators, and control off your shoulders and let you concentrate on more strategic tasks. On our side, we guarantee you high quality and security of your data, and the results delivered right on time. You can also check our transparent data annotation pricing.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is meant by labeled data?
Labeled data is data that already has the correct answer attached. For example, a photo might be labeled “dog” or a review might be labeled “positive.” This kind of data is used to train machine learning models. It helps the model learn how to make predictions by showing examples of what the right answer looks like.
What is meant by data labels?
Data labels are the tags added to describe raw data. They tell the model what each piece of data is. Think of them as simple answers like “car,” “happy,” or “approved.”
What is a label data type?
A label data type is the kind of format the label uses. It might be a word (like “cat”), a number (like 1 or 0), or something more complex like coordinates.
Different tasks, like image classification vs. object detection, need different types. For example, image classification uses category labels, while object detection uses boxes with numbers to mark positions.
What are labeled examples?
Labeled examples are pieces of data paired with correct answers. A single labeled example might be an email marked as “spam” or “not spam.”
They are used to teach machine learning models how to make decisions. The more labeled examples you have, the better your model can learn.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.