Imbalanced Dataset: Strategies to Fix Skewed Class Distributions

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- Why Imbalanced Datasets Break ML Models
- Evaluation Metrics for Imbalanced Dataset Performance
- Resampling Techniques to Balance the Dataset
- Algorithmic and Model-Level Fixes for Imbalanced Dataset
- Adjusting the Prediction Threshold
- Choosing the Right Strategy to Fix Imbalanced Dataset
- About Label Your Data
- FAQ

TL;DR
- Imbalanced datasets can mislead ML models, leading to poor generalization and biased predictions.
- Traditional accuracy metrics are insufficient; consider precision, recall, F1 score, ROC-AUC, PR-AUC, and balanced accuracy.
- Resampling techniques can help balance datasets but may increase the risk of overfitting or information loss.
- Algorithmic solutions include class weighting, cost-sensitive learning, ensemble methods, and specialized loss functions.
- Adjusting prediction thresholds based on ROC or PR curves can improve model performance on minority classes.
- Selecting the right strategy depends on dataset characteristics and problem context.
Why Imbalanced Datasets Break ML Models
In many real-world scenarios, it’s easy for a machine learning dataset to become imbalanced, meaning one class significantly outnumbers the others. This often happens because a standard machine learning algorithm optimizes for overall accuracy or unweighted loss, which gets skewed by the dominant class.
This imbalance can cause machine learning models to become biased toward the majority class, leading to several issues:
Bias in Predictions
Models may favor the majority class, neglecting the minority class, which could be critical, for example, fraud detection in financial datasets.
Misleading Accuracy
High accuracy might be achieved by simply predicting the majority class, masking poor performance of the minority class. For example, an image recognition program may correctly identify the more common facial features but falter with things like ears.
Poor Generalization
Models trained on imbalanced data may not generalize well to new, unseen data, especially for the minority class.
These challenges make it necessary to use specialized strategies to ensure different types of LLMs perform well across all classes. You should start with a high quality of labeled datasets — whether through in-house efforts or data annotation providers.
Evaluation Metrics for Imbalanced Dataset Performance
Traditional accuracy is not a reliable metric for imbalanced datasets. Data collection services get better results from the following:
Precision
Here is the ratio of true positives to the sum of true and false positives. It measures the accuracy of positive predictions.
Recall (Sensitivity)
The ratio of true positives to the sum of true positives and false negatives. It assesses the model’s ability to identify positive instances.
F1 Score
The harmonic mean of precision and recall, providing a balance between the two.
ROC-AUC
Receiver Operating Characteristic - Area Under Curve (ROC-AUC) measures the model’s ability to distinguish between classes across all thresholds. It may, however, give overly optimistic results on highly imbalanced datasets.
PR-AUC
Precision-Recall Area Under Curve (PR-AUC) focuses on the performance of the positive class and is especially useful when the positive class is rare.
Balanced Accuracy
The average of recall obtained on each class, accounting for imbalanced class distribution.
Matthews Correlation Coefficient (MCC)
A balanced metric that considers all four confusion matrix values and is robust even for imbalanced datasets.
Choosing the right metric depends on the specific problem and the costs associated with false positives and false negatives.
Resampling Techniques to Balance the Dataset
Resampling adjusts the class distribution in the training dataset to mitigate imbalance.
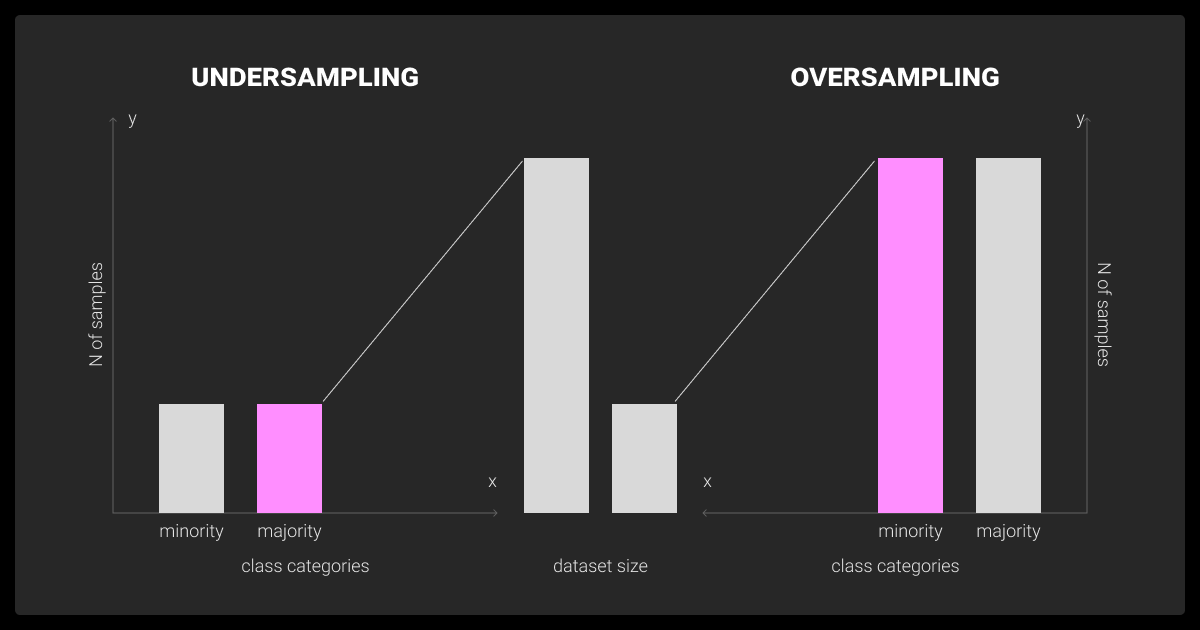
Oversampling and Undersampling
In oversampling, you duplicate or synthesize instances of a minority class to balance your dataset. This can improve model performance, but it also increases the risk of overfitting if the synthetic data doesn’t add much new information.
In undersampling, you remove instances from the majority class. It reduces the dataset size and can lead to loss of important information.
A data annotation company will follow up by using Tomek Links or Edited Nearest Neighbors (ENN) to clean noisy or borderline examples after resampling.
SMOTE and Variants (Borderline, ADASYN, etc.)
These techniques aim to correct an imbalanced dataset and make it machine learning ready.
- SMOTE (Synthetic Minority Over-sampling Technique): Generates synthetic samples for the minority class by interpolating between existing instances in feature space.
- Borderline-SMOTE: Focuses on generating synthetic samples near the decision boundary, where misclassification is more likely.
- ADASYN (Adaptive Synthetic Sampling): Generates synthetic data adaptively, focusing more on difficult-to-learn examples.
SMOTE assumes that you have a continuous feature space. For categorical data, you need a modification like SMOTE-NC.
These techniques are often supported by modern data annotation services, especially when synthetic data needs to be validated or combined with manually labeled samples.
When Resampling Backfires
While resampling can be beneficial, it may also introduce challenges such as:
- Overfitting: Especially with oversampling, models may memorize synthetic or duplicated instances.
- Loss of Information: Undersampling may discard valuable data from the majority class.
- Increased Complexity: Synthetic data can add noise or unrealistic features. It reshapes existing patterns but doesn’t add new signals.
You need careful consideration and validation when applying resampling techniques.
The key evaluation metric I always use is the F1-score and precision-recall curves, not accuracy, which is misleading with imbalanced data. For that fraud detection project, our precision went from 12% to 78% and recall improved from 31% to 85% after implementing these techniques.

 Owner, tekRESCUE
Owner, tekRESCUE
Algorithmic and Model-Level Fixes for Imbalanced Dataset
Now, let’s look at how to deal with imbalanced dataset. Beyond data-level adjustments, algorithmic strategies can address class imbalance during model training.
Class Weights and Cost-Sensitive Learning
You come across an imbalanced dataset example, but you don’t want to change the dataset too much:
- Class Weights: You’ll assign higher weights to the minority class in the loss function, penalizing misclassifications more severely.
This is supported in most ML libraries like Scikit-learn, XGBoost, LightGBM.
- Cost-Sensitive Learning: This incorporates the cost of misclassification into the model, guiding it to minimize costly errors.
These approaches help models focus more on the minority class without altering the dataset.
Ensemble Approaches: BalancedBagging, EasyEnsemble, Balanced Random Forests

Sometimes you need to learn how to handle imbalanced dataset using a more nuanced approach. Here are some ideas:
- BalancedBagging: This combines bagging with undersampling, creating balanced subsets for training multiple models.
- EasyEnsemble: This trains multiple classifiers on different balanced subsets and aggregates their predictions.
- Balanced Random Forests: These are a useful ensemble method that combines random forests with class-balanced bootstraps.
EasyEnsemble often pairs well with boosting methods like AdaBoost or Gradient Boosted Trees.
Specialized Loss Functions (Focal Loss, AUC Optimization)
These loss functions tailor the learning process to better handle imbalanced dataset:
- Focal Loss: Down-weights easy examples and focuses training on hard negatives, useful for addressing class imbalance.
- AUC Optimization: This directly optimizes the area under the ROC curve, aiming to improve ranking performance.
Focal Loss was originally designed for object detection, for example, RetinaNet, but is adaptable to binary classification with tuning.
Ensemble methods paired with cost-sensitive learning create a powerful combination for imbalanced classification tasks. Instead of forcing balance through resampling... this shifts the model's attention toward the hard-to-predict cases without sacrificing performance on the majority class.
 Owner & Finance Director, ABC Finance
Owner & Finance Director, ABC Finance
Adjusting the Prediction Threshold
Models often output probabilities, which are converted to class labels using a threshold (commonly 0.5). Adjusting this threshold can improve performance on the minority class.
- ROC Curve Analysis: This helps identify the threshold that balances true positive and false positive rates.
- Precision-Recall Curve: This is useful for selecting a threshold that balances precision and recall, especially in imbalanced datasets.
- Youden’s J Statistic or Cost Curves: You can use these to formally determine the optimal cut-off points.
Don’t just rebalance your data when you're dealing with imbalance. Rebuild the rare. Make the story of the minority class so that the model doesn’t just see more examples, but better ones.
 Owner, Weidemann.tech
Owner, Weidemann.tech
Choosing the Right Strategy to Fix Imbalanced Dataset
Selecting the appropriate method depends on various factors:
| Scenario | Recommended Strategy |
| Severe imbalance with small dataset | SMOTE or ADASYN |
| Large dataset with redundant majority class | Undersampling or BalancedBagging |
| High cost of false negatives | Cost-sensitive learning or Focal Loss |
| Need for model interpretability | Class weighting or threshold adjustment |
| Complex patterns in data | Ensemble methods like EasyEnsemble |
LLM fine-tuning services often find it beneficial to combine multiple strategies and validate their effectiveness through cross-validation and performance metrics. While this increases data annotation pricing slightly, the improvement in accuracy is well worth the effort.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is an imbalanced dataset?
An imbalanced dataset is where the distribution of classes is uneven, with one class significantly outnumbering the others. This imbalance can lead to biased models that perform poorly on the minority class.
Is 60/40 imbalanced data?
A 60/40 split is moderately imbalanced. While not as severe as 90/10, it can still impact model performance, especially if the minority class is of particular interest or if the dataset is small. That’s why you should also evaluate metrics like F1 or PR-AUC and the class-specific error costs.
Is the F1 score good for imbalanced datasets?
Yes, the F1 score balances precision and recall, making it suitable for evaluating models on imbalanced datasets, especially when both false positives and false negatives are important. It helps you work out whether you have a balanced vs imbalanced dataset.
Should I balance the validation or test sets?
No. Validation and test sets should reflect the true class distribution of the real world to measure performance realistically. You should instead focus on the imbalanced dataset classification.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.