LLM Data Labeling: How to Use It Right

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- How to Use LLM for Data Labeling Process
- Benefits of LLM for Data Labeling
- Top 5 LLMs for Data Labeling
- Practical Applications and Use Cases for LLM Data Labeling
- Types of LLM Data Labeling Tasks to Automate the Process
- Best Practices for Efficient LLM Data Labeling
- Challenges of LLM for Data Labeling
- Future Trends in LLM Data Labeling
- About Label Your Data
- FAQ

TL;DR
- LLMs automate labeling tasks like entity recognition and sentiment analysis, reducing manual effort.
- Steps include schema definition, prompt creation, API usage, and output mapping.
- Benefits include faster labeling, better accuracy, scalability, and adaptability across data types.
- Top LLMs for text annotation are GPT-4, BERT, RoBERTa, Turing-NLG, and mBART.
- Challenges include accuracy, bias, resource costs, and overconfidence, requiring human oversight and QA.
How to Use LLM for Data Labeling Process
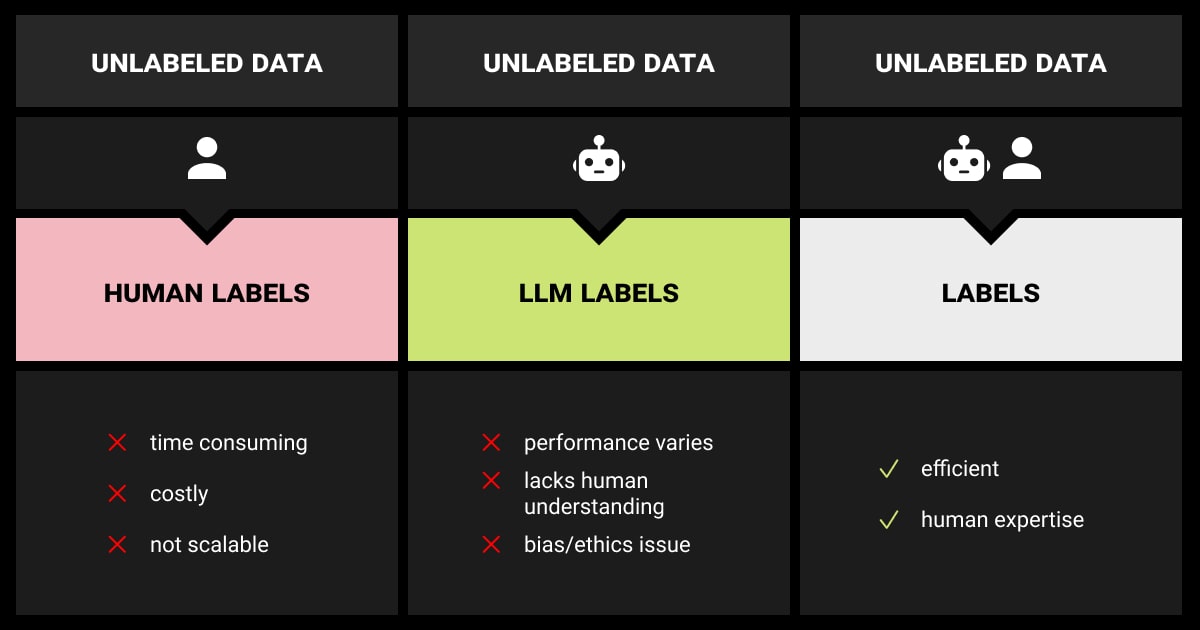
Data scientists spend over 80% of their time preparing data, including data annotation. With the rise of large language models like GPT-4, we now have the tools to streamline this process significantly.
Let’s compare it to the traditional human-led annotation process to understand better how LLM data labeling works.
First, you must define the annotation task and schema required based on the ML project objective. For example, in entity recognition, the schema would include labels like “person,” “organization,” “location,” and “date.” Next, human annotators label data samples by following the established guidelines and delivering expert text annotation services.
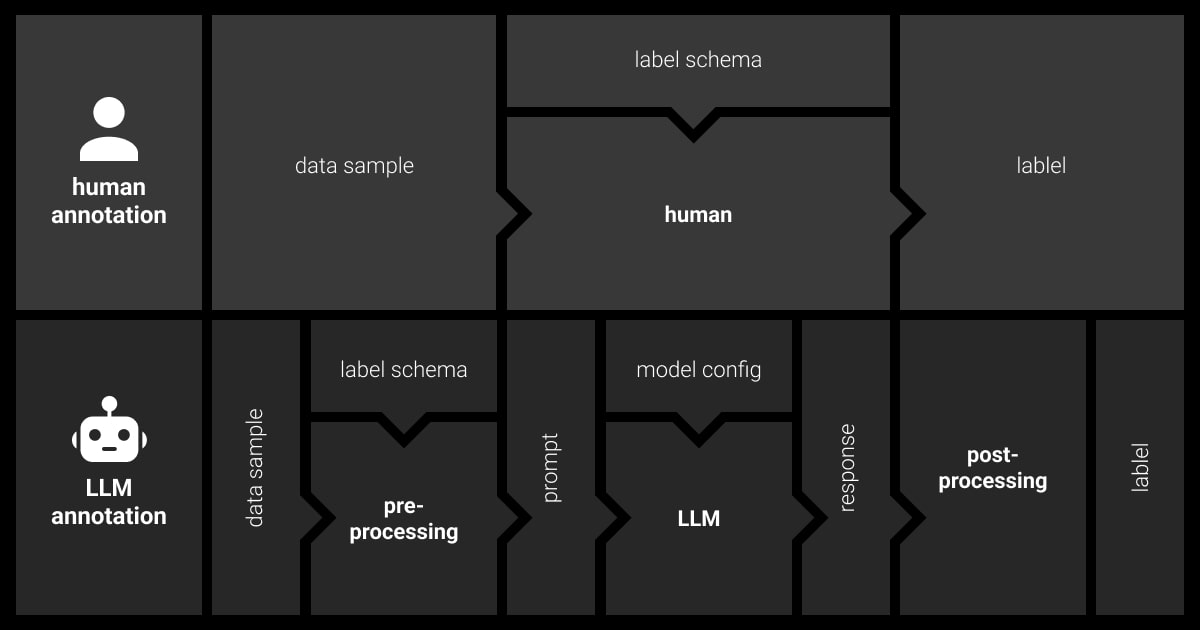
With LLMs, things are different. The main steps within LLM data labeling are as follows:
Model Selection
Choose an LLM (e.g., ChatGPT, Llama) and configure it (e.g., set the temperature parameter).
Pre-processing
Create a prompt instructing the LLM on the labeling task and including labeled examples if needed.
Calling LLM API
Send the prompt to the LLM via an API for large-scale annotation. Ensure prompts are within the LLM’s token limits.
Post-processing
Parse the LLM’s response, extract the label, and map it to your schema. This step can be challenging due to the potential noise in free-text outputs.
By carefully managing these steps, you can effectively use LLM for data labeling, reducing reliance on human annotators while maintaining accuracy.
Benefits of LLM for Data Labeling
Automation of Labeling Tasks
LLMs can automate and expedite the data labeling process, significantly reducing the time and effort required for manual annotation.
Improving Accuracy and Consistency
LLMs achieve higher accuracy and consistency in labeled data by learning complex patterns from large datasets, surpassing traditional rule-based systems.
Scalability
LLMs offer scalability advantages, efficiently handling large datasets and maintaining performance across varying volumes of data.
Greater Accuracy and Consistency
LLMs excel at learning intricate patterns from extensive datasets, providing accuracy and consistency that exceeds rule-based approaches.
Adaptability
LLMs are versatile and capable of handling diverse data types, including text, images, and audio, making them suitable for various applications.
Continuous Improvement
LLMs continuously improve their performance by updating with new data and feedback, ensuring they remain effective over time.
Top 5 LLMs for Data Labeling
| LLM | Type | Strengths |
| OpenAI GPT-4 | Commercial | Advanced language understanding and generation, effective for a wide range of data labeling tasks. |
| Google's BERT | Open-source | Strong in understanding context and nuance, excels in detailed text analysis and labeling. |
| Microsoft's Turing-NLG | Commercial | Focused on natural language generation, creates high-quality labeled datasets. |
| Hugging Face's RoBERTa | Open-source | Optimized version of BERT, performs well in text labeling due to extensive pre-training. |
| Facebook's mBART | Open-source | Specialized in multilingual tasks, excels in labeling datasets across multiple languages. |
Practical Applications and Use Cases for LLM Data Labeling
LLMs are still evolving, yet much research shows how great these models are for automating data labeling.
The research found that using LLMs, specifically Flan-UL2 and Mistral-7B, helped generate weak labels for the stance classification of YouTube comments. The LLMs achieved high accuracy in determining stances. Combined with other weak signals in a data programming model, this resulted in robust final stance labels. The integration of LLM-generated labels improved the overall quality and efficiency of the labeling process.
Another research shows that fine-tuning models on LLM-generated labels achieved performance close to those fine-tuned on human-annotated data. This approach significantly reduced the reliance on human annotations while maintaining high accuracy, demonstrating the potential of LLMs to automate and streamline the labeling workflow effectively.
Types of LLM Data Labeling Tasks to Automate the Process
Large Language Models (LLMs) are versatile in handling automated data labeling. Their advanced language processing capabilities allow them to perform some critical tasks in LLM data annotation:
Named Entity Recognition (NER)
LLMs identify and label names of people, organizations, locations, dates, and more within text data. This is essential for extracting specific entities from large datasets.
Sentiment Analysis
LLMs analyze the sentiment in text data, categorizing it as positive, negative, or neutral. This is useful for understanding opinions and attitudes in the text.
Intent Detection
LLMs determine the intent behind a text, classifying it into categories like questions, requests, or commands. This is crucial for natural language understanding (NLU) systems.
Part-of-Speech (POS) Tagging
LLMs assign grammatical tags to words in a sentence, indicating their syntactic roles, such as nouns, verbs, or adjectives. This is fundamental for parsing and syntactic analysis.
Semantic Role Labeling (SRL)
LLMs identify the roles entities play in relation to the main verb in a sentence, such as agent or patient. This helps in understanding sentence structures and meanings.
Topic Categorization
LLMs classify text data into predefined topics based on content. This aids in document classification and content recommendation.
Data Extraction
LLMs extract key data points such as events, participants, times, and locations. They also detect and label temporal expressions like dates and durations. This capability is crucial for information retrieval, event tracking, and handling time-related data.
Best Practices for Efficient LLM Data Labeling
To make the most of LLM for data labeling, follow these best practices that enhance performance and accuracy:
Prompt Engineering
Selecting the right prompts is crucial for improving LLM labeling. Balance descriptive instructions with clarity. Use:
- Zero-shot Prompts: Provide simple, task-specific instructions with examples.
- Few-shot Prompts: Combine human instructions with labeled examples to enhance annotation accuracy.
Model Selection and Fine-Tuning
Selecting the appropriate LLM for your task and using top LLM fine-tuning tools ensures better performance and reduces biases.
- Model Selection: Choose the right LLM based on task requirements.
- LLM Fine-Tuning: Choose the right LLM fine-tuning method to train the model with domain-specific data for improved results.
Tool Integration
Integrate LLMs with existing data annotation tools and platforms to streamline workflows.
- Seamless Integration: Ensure compatibility with current annotation tools.
- Workflow Automation: Automate parts of the annotation process for efficiency.
- Data Management: Use integrated platforms to handle data more effectively and maintain consistency.
Human Oversight
Incorporate human expertise to enhance LLM outputs:
- Human-in-the-Loop: Combine LLM pre-annotation with human refinement for higher accuracy.
- Feedback Mechanisms: Use human and automated feedback loops to improve model performance continually.
Model Parameters Optimization
Adjusting model parameters helps optimize the LLM’s output quality and adaptability to specific tasks.
- Temperature Settings: Fine-tune temperature settings to control the randomness of outputs.
- Other Parameters: Adjust other relevant parameters to suit specific tasks.
LLM Annotations Evaluation
Regularly evaluate LLM annotations against benchmarks:
- General Evaluation: Use methods like manual reviews and the “Turing Test” for accuracy and originality.
- Task-Specific Metrics: Apply appropriate metrics for different applications, ensuring diverse and reliable annotations.
By adhering to these best practices, you can maximize the efficiency and accuracy of LLM data labeling.
Challenges of LLM for Data Labeling

To effectively use LLM for data labeling, addressing inherent challenges is crucial:
Accuracy
Ensuring high accuracy is crucial as LLMs can handle basic labeling but require thorough QA to review edge cases—instances where the context or meaning is ambiguous or complex, making accurate labeling more challenging.
Bias and Fairness
LLMs can inherit biases present in their training data, potentially leading to unfair outcomes in labeled data. Addressing these biases is crucial to ensuring the labeling process is fair and equitable.
Data Privacy
Maintaining data privacy and security is paramount in LLM data annotation. Ensuring that sensitive information is protected throughout the data labeling process is essential for compliance with data protection regulations and building trust with stakeholders.
Cost and Resource Management
Deploying LLMs for data labeling can be resource-intensive, requiring significant computational power and associated costs. Efficiently managing these resources is necessary to balance performance and cost-effectiveness.
Text Data Limitation
While LLMs are primarily designed for text data, they are less effective for other data types, such as images or audio. This limitation necessitates integrating additional tools or models to handle diverse data types.
Continuous Maintenance
LLMs require regular updates and retraining to maintain high-quality annotations. This ongoing maintenance ensures that the models stay current and effective as new data and requirements emerge.
Overconfidence
LLMs can sometimes provide incorrect labels with high certainty, undermining the labeled data’s reliability. Implementing mechanisms for uncertainty estimation and human oversight can help mitigate this issue.
Overcoming these challenges will help your LLM data labeling systems remain fair, reliable, and accountable.
Future Trends in LLM Data Labeling
We can expect next-generation LLMs to bring significant improvements to data labeling tasks. Enhanced adaptability will enable future LLMs to handle a wider range of data types, including text, images, and audio. Additionally, upcoming advancements will focus on reducing inherent biases in LLMs.
The potential new applications of LLMs in data labeling will include cross-domain labeling and real-time data annotation. Moreover, personalized learning models will become more prevalent, allowing LLMs to adapt to specific industry needs and provide tailored solutions for data labeling tasks.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
Can LLM label data?
Yes, LLMs can label data by leveraging their advanced language understanding capabilities to classify and annotate text. However, human oversight is often necessary to review edge cases and ensure high accuracy.
How do I select the right model for LLM data labeling?
- Identify the type of data you need to label (e.g., text, images, audio).
- Determine the complexity of the annotations required and the level of accuracy you need.
- Research LLMs that have strong performance on tasks similar to yours.
- Compare models based on scalability and their ability to handle large datasets efficiently.
- Ensure the LLM can integrate smoothly with your existing workflows and tools.
Why is a data labeling step critical when building and deploying LLMs?
Data labeling creates the structured, high-quality datasets LLMs need to learn effectively. Accurate labels improve the model’s predictions, reduce errors, and ensure reliable performance in real-world applications.
What is a LLM in data?
An LLM (Large Language Model) is an AI model trained on vast text datasets to understand and generate human-like language. It’s used for tasks like text classification, sentiment analysis, and data labeling.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.