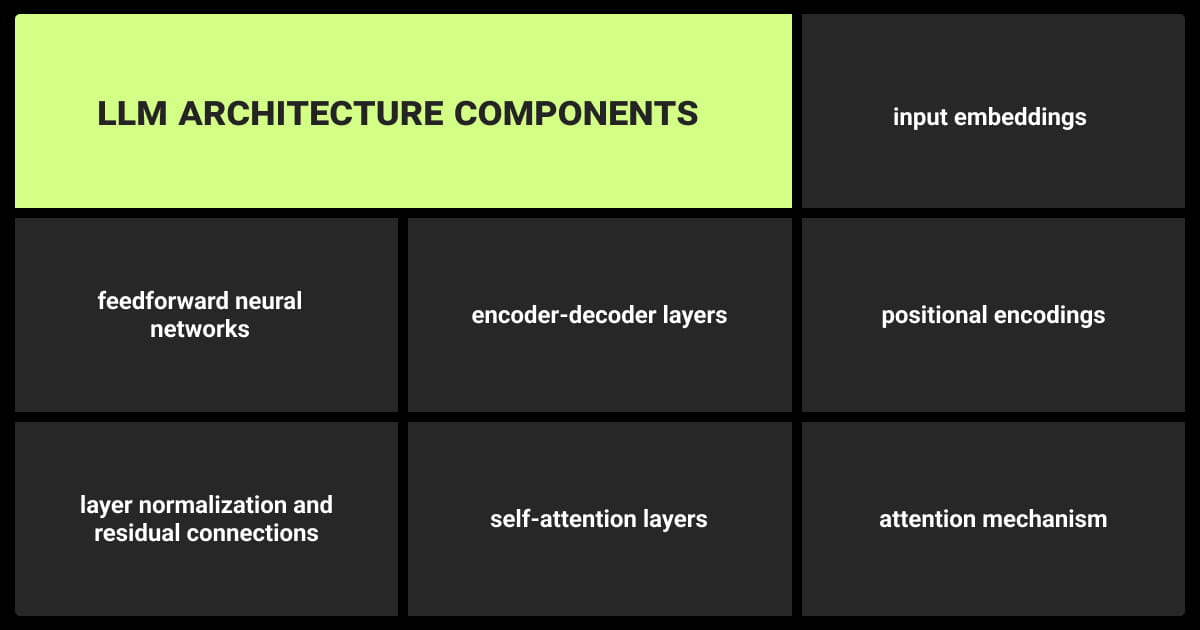
LLM Architecture: Possible Model Configurations

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- Optimizing LLM Architecture for Efficient Development
- How to Choose the Best LLM Architecture for Your Use Case
- Key Design Considerations for Efficient LLM Development
- Top Training and Optimization Techniques for LLMs
- Evaluating and Selecting the Right LLM for Your Needs
- Best Practices for Large Language Model Development
- Hardware and Software Requirements for LLM Deployment
- Optimizing LLM Deployment: Bare Metal vs. Virtual Environments
- Emerging Trends in LLM Architecture: What to Expect in 2024
- About Label Your Data
- FAQ

TL;DR
- Use Transformer LLM architecture for scalable, high-performance language models.
- Opt for Encoder-Decoder models like T5 for translation and summarization tasks.
- Leverage Causal Decoder models like GPT for text generation and completion.
- Fine-tune pre-trained models to meet domain-specific requirements and save on costs.
- Implement data, model, and pipeline parallelism to optimize large-scale LLM training.
- Evaluate using perplexity for text generation, F1-score for classification, or ROUGE/BLEU for summarization and translation.
Optimizing LLM Architecture for Efficient Development
With 61.6% of organizations already using LLMs for various tasks, the demand for scalable and efficient models is growing.
Given that the architecture of LLM directly impacts its performance, optimizing the model’s setup can make a large language model more efficient. This is key for businesses using LLMs in real-world applications, whether for customer support, data analysis, or content generation.
At Label Your Data, we focus on LLM fine-tuning to ensure they perform at their best. In this article, we’ll walk you through the different types of LLM architecture, how they work, and what it takes to optimize them. By the end, you’ll see why choosing the right configuration—and the right team to fine-tune it—matters for success.
How to Choose the Best LLM Architecture for Your Use Case
Selecting the right LLM architecture is key to achieving specific objectives like fine-tuning for domain-specific tasks or scaling efficiently.
LLM Transformer Architecture

The foundation of most modern types of LLMs. LLM transformer architecture uses self-attention to process entire sequences in parallel, rather than one token at a time. This ability allows it to capture dependencies across long sequences efficiently.
For example, the transformer's multi-head attention mechanism allows the model to concentrate on multiple sections of the input data at the same time. It is crucial for large-scale tasks like machine translation or question answering. By parallelizing these operations, the transformer reduces training time significantly compared to previous architectures.
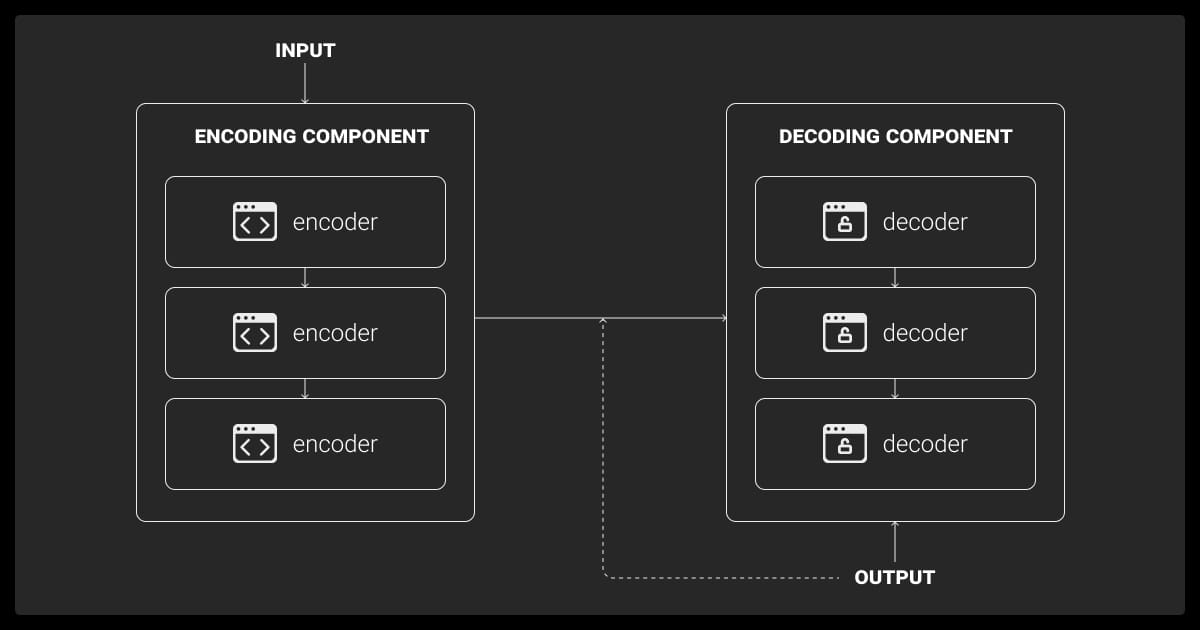
Encoder-Decoder Architecture

The encoder-decoder LLM model architecture consists of two distinct components. The encoder transforms the input data into vectors that capture its main features. The decoder then processes these vectors to generate output.
For instance, in the T5 model, the encoder reads an input text, and the decoder predicts the output based on that encoding. This architecture tackles tasks like translation and summarization. Here, the relationship between input and output requires careful interpretation and generation of structured text.
Causal Decoder Architecture

Causal decoder architectures, like those in the GPT series, use a unidirectional approach. Each token only has access to previous tokens. This structure makes it ideal for autoregressive tasks like text generation, where the model must predict the next token based on past inputs.
In GPT-3 LLM chatbot architecture, the causal decoder architecture allows the model to generate fluent and coherent text at scale. This makes the model powerful for applications like content generation and conversational agents.
When selecting the optimal architecture for a large language model (LLM) to ensure scalability and efficiency, the specific use-case requirements are paramount. Techniques like model distillation can help maintain effectiveness while reducing size, making deployment more manageable.

 CEO, Software House
CEO, Software House
Key Design Considerations for Efficient LLM Development
Your design choices directly affect the model’s performance and ability to generalize to different tasks.
Pre-Training and Fine-tuning
Pre-training and fine-tuning are two critical stages in LLM development. Pre-training involves training a model on large, general datasets to develop a broad language understanding. LLM fine-tuning tools, however, customize the model to a specific task by adjusting its parameters on a smaller, domain-specific dataset.
30.1% of industry professionals say fine-tuning is their top area of interest when working with LLMs. This approach allows companies to use the model’s general knowledge while tailoring it to their unique requirements. For example, by fine-tuning a model like GPT-3 for customer support, businesses can improve response accuracy in niche areas.
Attention Mechanisms
Attention mechanisms are the core of transformer-based architectures. They allow the model to assign varying importance to different parts of the input data. For example, the scaled dot-product attention used in transformers calculates a weighted sum of values, where the weights are based on the similarity between queries and keys.
This mechanism ensures that relevant tokens in a sequence receive more attention. It is critical for tasks like reading comprehension or summarization.
Activation Functions
Activation functions determine how the model processes data. In LLMs, GeLU (Gaussian Error Linear Unit) is commonly used because it smooths the output in a way that helps the model generalize better.
Compared to traditional functions like ReLU, GeLU provides a more continuous and differentiable output. It can improve performance in complex tasks, such as natural language generation.
Positional Embeddings
Since transformers don’t process data sequentially like RNNs, they need positional embeddings to understand the order of tokens. Learned positional embeddings are the most commonly used in LLMs today.
These embeddings are added to the input data to give the model a sense of position in the sequence. This improves the model’s ability to handle tasks that require understanding word order, such as machine translation.
Balancing model size and complexity with hardware resources for efficiency is critical. Parallelism (model and data) ensures scalability, while modular design allows flexibility across different use cases.
 Founder & CEO, Konstellate
Founder & CEO, Konstellate
Top Training and Optimization Techniques for LLMs
Efficient training and optimization are crucial to developing powerful and scalable LLMs. These processes directly impact the model’s ability to handle large datasets and its performance on specific tasks.
Data Gathering
The quality of the training data is critical to the performance of any LLM. Data preprocessing techniques like quality filtering, data deduplication, and privacy reduction ensure the model isn’t overloaded with noisy or redundant information. High-quality datasets allow for better generalization during pre-training and more accurate fine-tuning.
Domain-specific datasets are often needed during fine-tuning to align the model’s output with specific industry requirements, whether for legal documents, medical records, or technical manuals.
Optimization Techniques
LLMs require significant computational resources for training, but there are ways to optimize this process. Techniques like data parallelism and model parallelism are commonly used to distribute the training workload across multiple GPUs.
Tensor parallelism breaks down large models by distributing different parts of the same layer across devices. Pipeline parallelism splits layers across GPUs and processes different parts of the model in a pipeline. Libraries such as DeepSpeed and Megatron-LM help streamline these parallelism techniques, ensuring that large-scale LLMs can be trained efficiently even with limited hardware.
Regularization and Scaling
Regularization techniques help prevent overfitting, a common issue in large models. Dropout and weight decay are widely used to ensure the model remains robust across different datasets and tasks.
As models scale up, researchers use scaling laws to find the optimal balance between dataset size, model parameters, and computation power. This allows companies to predict how much performance gain can be expected when scaling a model from a smaller version to a larger one.
Gradient checkpointing can reduce memory usage during training, helping efficiently train and deploy large models, even on hardware with limited capacity.
 Director of Customer Success, Aspire
Director of Customer Success, Aspire
Evaluating and Selecting the Right LLM for Your Needs
After training and optimizing an LLM, the next critical step is evaluating its performance and selecting the most suitable model. Effective evaluation ensures that the model performs as expected in real-world applications.
Evaluation Metrics
Various metrics are used to measure the performance of LLMs:
| Metric | Use Case |
| Perplexity | Evaluates how well the model predicts the next word in text generation tasks. |
| Accuracy | Measures the percentage of correct predictions in classification tasks. |
| F1-score | Balances precision and recall for tasks like classification and information extraction. |
| ROUGE | Compares generated summaries to reference texts, often used for summarization tasks. |
| BLEU | Compares translated text to reference translations, commonly used for translation tasks. |
Model Selection Criteria
Selecting a suitable model depends on several factors. They include model size, computational resources, and the specific application it will be used for.
For example, smaller models might be more appropriate for applications with limited computing power, such as mobile devices. Meanwhile, larger models can be deployed for tasks that require high accuracy and complexity.
It's also essential to consider the trade-off between model performance and inference time. Fine-tuning smaller models for specific tasks can often yield better results with lower costs than using a generic, larger model.
Ready to optimize your LLM for specific tasks? Discover how our LLM fine-tuning services can maximize performance and efficiency for your business.
Best Practices for Large Language Model Development
Now, let’s cover the most critical methods to streamline LLM workflows.
Normalization
Normalization techniques ensure that models converge faster and more consistently during training. In LLMs, LayerNorm is widely used to standardize the output of each layer by normalizing across the feature dimension. This prevents issues like exploding or vanishing gradients.
Additionally, pre-layer normalization is often applied before multi-head attention (MHA) to stabilize the training process. It can be particularly beneficial in deep models where instability is a common challenge.
Softmax Layer
The softmax layer is crucial for converting the model's raw output into a probability distribution over possible outcomes. This is typically the final step in models that perform tasks like text generation.
The softmax function outputs probabilities for each token in the vocabulary. These probabilities are used to select the most likely next word in a sequence. Two common approaches for word selection are greedy decoding (selecting the token with the highest probability) and random sampling (picking a token based on the probability distribution).
Top-K and Top-P Sampling
Both top-K and top-P sampling techniques help control the randomness of generated text. Top-K sampling limits the choices to the K highest probability tokens, while top-P (nucleus) sampling chooses tokens from the smallest set of tokens whose cumulative probability exceeds a threshold P. These techniques help to balance creativity with coherence, giving users control over the model’s output behavior.
Temperature
The temperature parameter adjusts the model's prediction randomness. A higher temperature value increases the randomness and diversity of the generated output, which can be helpful in creative tasks. Conversely, a lower temperature produces more deterministic and predictable results, often preferred in applications requiring high accuracy.
Adaptability is achieved through effective transfer-learning capabilities. Fine-tuning specific portions of the model for different domains guarantees both efficiency and versatility.
 Chief Operating Officer, Gorrion
Chief Operating Officer, Gorrion
Hardware and Software Requirements for LLM Deployment
Choosing the right infrastructure ensures that models can be scaled and optimized effectively.
GPUs
Graphics Processing Units (GPUs) are essential for training and running LLMs due to their ability to handle parallel computations. Modern LLMs require immense computational power, and GPUs—particularly from NVIDIA—are commonly used to accelerate training.
Specialized hardware, like A100 GPUs, can drastically reduce training time by supporting larger batch sizes and faster matrix operations. Using multiple GPUs in parallel can scale model training for larger datasets and more complex architectures.
Distributed Computing
For large-scale LLMs, distributed computing is key to managing the computational load. Techniques like data parallelism and model parallelism spread the training workload across multiple GPUs or machines. This allows models to train on much larger datasets and more layers than would be possible on a single machine.
Additionally, libraries such as DeepSpeed and Megatron-LM offer tools to optimize distributed training, minimizing the overhead associated with multi-node computations.
Inference
After training, inference—the process of generating predictions from the trained model—can be run on GPUs, TPUs (Tensor Processing Units), or CPUs. It depends on the application and available resources.
For real-time applications, inference speed is crucial. Here, using optimized hardware (like TPUs for large-scale workloads) ensures quick responses without sacrificing accuracy. Efficient inference setups can reduce latency and the cost of deploying LLMs at scale.
Optimizing LLM Deployment: Bare Metal vs. Virtual Environments
LLM deployment architecture requires careful consideration of the environment, infrastructure, and configuration to ensure the model performs efficiently in production settings.
Bare Metal Deployment
Bare metal deployment involves physical servers, offering complete control over hardware and software. It’s ideal for high-performance applications with low-latency needs, such as real-time chatbots. Bypassing virtualization reduces overhead, and InfiniBand can boost node communication, making it perfect for large-scale LLM training and inference.
Virtual Environment Deployment
Virtual environments offer flexibility and scalability. VMs or containers allow businesses to adjust resources on demand without managing physical hardware. Cloud platforms like AWS, GCP, and Azure simplify LLM deployment by providing GPU instances and simplifying updates and maintenance with versioned containers.
Deployment Considerations
Before deploying LLMs, several factors need to be considered:
- Security: Protect models and data during training and inference, especially in sensitive fields.
- Scalability: Ensure the environment scales with usage, especially for real-time applications.
- Maintainability: A well-maintained, documented setup reduces downtime and enables faster iteration.
Emerging Trends in LLM Architecture: What to Expect in 2024
LLM architecture is rapidly evolving, with new trends pushing the limits of what these models can achieve.
In-Context Learning
In-context learning enables LLMs to adapt quickly without extensive fine-tuning. By using relevant prompts, the model aligns its output with specific contexts, making it ideal for fast, domain-specific tasks.
Agents and Tools
LLM agents are gaining traction for their ability to perform tasks autonomously. These agents learn from their actions, allowing businesses to automate complex workflows and reduce human oversight.
Design Patterns
New design patterns, such as combining encoder-decoder models for structured tasks and causal decoders for content creation, are emerging. These innovations allow for more tailored, efficient LLM configurations across industries.
Looking for tailored LLM solutions? Get in touch with our experts to discuss your project requirements and get a personalized solution.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is LLM architecture?
LLM architecture implies the design and structure of a large language model. It determines how the model processes and generates language through attention mechanisms, layers, and embeddings. These components define how the model learns and performs tasks.
What is the difference between GPT and LLM?
GPT (Generative Pretrained Transformer) is a type of LLM chatbot architecture based on a causal decoder. LLM, instead, is an umbrella term that encompasses various architectures (like GPT, T5, BERT). GPT models are specifically designed for tasks such as text generation and completion.
What is the structure of a LLM model?
The structure of an LLM typically includes an LLM transformer architecture with layers of attention mechanisms, normalization, activation functions, and embeddings. Depending on the model, it can also feature encoder-decoder or causal decoder configurations to handle specific tasks.
What are LLM models primarily used for?
LLM models are used for various tasks, including natural language understanding (NLU), text generation, translation, summarization, question-answering, and more. They are applied across industries, from customer support automation to content creation and beyond.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.