Pre-Training vs Fine Tuning: Choosing the Right Approach

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

TL;DR
- Pre-training builds general language understanding using large datasets for versatile use.
- Fine-tuning adapts pre-trained models to specific tasks with labeled datasets.
- Use pre-training for adaptability and fine-tuning for precision in tasks.
- Techniques include MLM, CLM, and parameter-efficient fine-tuning.
- Applications include general-purpose LLMs and specialized tools like speech and image recognition.
Key Concepts: Pre-Training vs Fine-Tuning
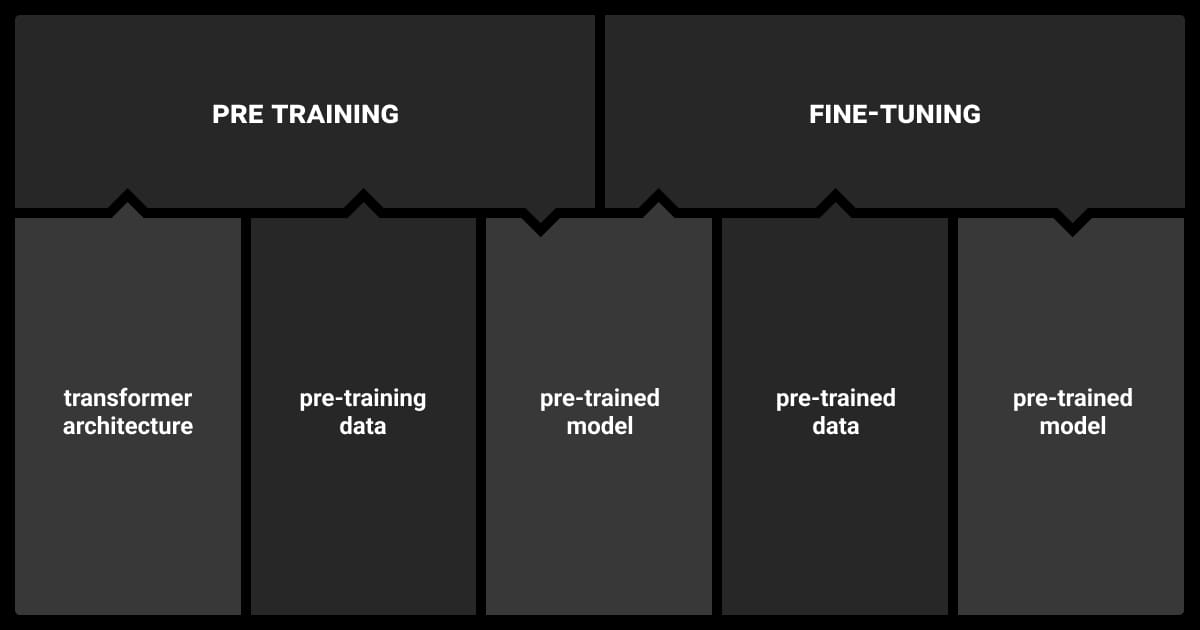
The performance of Large Language Models (LLMs) lies on two critical processes: pre-training and fine-tuning. Understanding these stages allows designing models that are both versatile and highly effective for specific tasks.
Pre-training equips the model with a broad understanding of language, while fine-tuning refines its capabilities to address specific domain-related tasks. Let’s break down these concepts further.
What is Pretraining?
Pre-training is the foundation of modern LLMs, using large datasets and unsupervised learning to identify language patterns and create versatile models.
Key Pre-Training Techniques
| Technique | Description | Example Models |
| Masked Language Modeling | Predicts missing words in a given sentence to understand context deeply. | BERT, RoBERTa |
| Causal Language Modeling | Predicts the next word in a sequence to generate natural, coherent text. | GPT series, GPT-4 |
| Sequence-to-Sequence Learning | Trains models to handle both input and output as text for task flexibility. | T5, BART |
These techniques allow pre-trained models to develop a general understanding of language. They become adaptable for downstream tasks.
Advantages of Pre-Training
- Scalability: Models trained on diverse datasets can generalize across multiple tasks.
- Reusability: Once pre-trained, the model serves as a foundation for various fine-tuning efforts.
- Cost Savings in Downstream Tasks: Pre-trained models significantly cut resource costs by eliminating the need to build task-specific training models from the ground up.
Challenges of Pre-Training
Pre-training can be computationally expensive, often requiring weeks on specialized hardware. Moreover, the quality of pre-trained models heavily depends on the datasets used. If the data is noisy or biased, the model’s performance will reflect those flaws. Ensuring high-quality data through reliable data annotation services is essential to mitigate these issues and improve model outcomes.
Pre-training is resource-intensive, requiring massive datasets and computational power. It’s ideal for creating general-purpose models but impractical for many businesses due to its costs and time demands.

What is Fine-Tuning?
LLM fine-tuning refines pre-trained models using smaller, labeled datasets to optimize performance on tasks like sentiment analysis or translation.
Key Fine-Tuning Techniques
| Technique | Description | Example Use Cases |
| Full Fine-Tuning | Updates all model parameters for task-specific learning. | Sentiment analysis, classification |
| Parameter-Efficient Methods | Optimizes specific model layers (e.g., LoRA, Adapters) to save computational resources. | Domain-specific tasks, low-resource scenarios |
| Few-Shot/Zero-Shot Tuning | Leverages minimal (or no) labeled examples, relying on pre-trained model prompts. | Rare language tasks, NLU |
Fine-tuning techniques provide flexibility in tailoring models for a wide range of real-world applications while balancing resource constraints.
Advantages of Fine-Tuning
- Precision: Adapts models for domain-specific or task-specific accuracy.
- Efficiency: Requires fewer resources compared to pre-training.
Challenges of Fine-Tuning
- Small datasets can lead to overfitting.
- Careless fine-tuning risks erasing the general knowledge learned during pre-training.
Differences Between Pre-Training vs Fine-Tuning
While both pre-training and fine-tuning aim to enhance model capabilities, they differ significantly in scope, resources, and application.
| Aspect | Pre-Training | Fine-Tuning |
| Purpose | General foundational learning | Task-specific optimization |
| Dataset Size | Massive, diverse datasets | Small, curated datasets |
| Computational Cost | High (weeks to months) | Low (hours to days) |
| Scalability | Applicable across multiple domains | Limited to the fine-tuned task |
| Techniques Used | MLM, CLM, Seq2Seq | Full, Parameter-Efficient, Few-Shot |
Pre-training focuses on creating a versatile knowledge base, while fine-tuning hones in on the specifics required for real-world applications.
Pre Training vs Fine Tuning: Which One to Use?
Selecting the right approach — pre-training or fine-tuning — depends on your objectives, available resources, and the complexity of the task. Understanding the strengths of each method ensures efficient model development and deployment.
When to Use Pre-Training
Pre-training is ideal when building a foundational model from scratch. It can also be used for general-purpose use across multiple domains. This stage involves extensive resource allocation and is typically undertaken by large organizations or research labs.
- Development of Foundational Models: Creating models like GPT or BERT that can later be adapted for a variety of tasks.
- Applications Requiring Broad Coverage: Ideal for tasks in multilingual or multi-domain environments where general knowledge is crucial.
- Advancing State-of-the-Art: For research projects aimed at pushing the boundaries of AI.
As an example, OpenAI’s GPT-4 is pre-trained on massive datasets to perform various tasks. This foundational pre-training allows users to apply GPT-4 without needing extensive fine-tuning for common tasks.
When to Use Fine-Tuning
Fine-tuning is more suitable when a pre-trained model exists, and the goal is to customize it for a specific domain or task. This approach optimizes resources by leveraging the foundational knowledge of a pre-trained model.
- Task-Specific Optimization: Adapting a pre-trained model for applications such as sentiment analysis, legal document review, or medical diagnosis.
- Low-Resource Training Environments: Organizations with limited datasets or computational power can use fine-tuning to achieve high accuracy.
- Domain-Specific Applications: Tailoring models for niche industries, such as finance or healthcare.
An example of fine-tuning can be a healthcare startup BERT model. It's fine-tuned on medical records to create a model capable of identifying key patient information, such as symptoms and treatments.
Fine-tuning allows you to take an existing pre-trained model and mold it to your specific needs with focused, relevant data. It’s quicker, cheaper, and a lot more efficient for most use cases.

 Martech Expert, InboxArmy
Martech Expert, InboxArmy
Choosing the Right Approach
The decision to pre-train or fine-tune depends on key factors, such as:
Resource Availability
Pre-training demands extensive compute resources and data, while fine-tuning is more cost-effective.
Task Complexity
Fine-tuning is sufficient for most task-specific use cases, but pre-training is required to build foundational capabilities.
Time Constraints
Pre-training takes weeks or months, whereas fine-tuning can be completed in hours or days.
For tasks requiring high precision and domain-specific adaptation, LLM fine tuning offers an efficient way to leverage pre-trained models and customize them for specific business or research needs.
The choice between pre-training and fine-tuning boils down to the problem’s complexity, available resources, and the need for specificity. Fine-tuning is often faster and more practical for businesses targeting niche applications.
 Full-Stack Developer, Penfriend
Full-Stack Developer, Penfriend
Combined Strategies
Sometimes, the best results are achieved by combining both approaches:
Intermediate Pre-Training
Pre-train on domain-specific datasets (e.g., financial data) before fine-tuning for a specific task (e.g., fraud detection).
Parameter-Efficient Fine-Tuning
Techniques like Adapters can be used to fine-tune specific layers without requiring full fine-tuning.
Geospatial Annotation for Domain-Specific Models
Models focused on mapping or geographic tasks can benefit from pre-training on datasets with geospatial annotation, followed by fine-tuning to adapt to applications like urban planning or environmental monitoring.
Pre Training vs Fine Tuning Metrics
Metrics evaluate performance in pre-training and fine-tuning, ensuring robust foundational models and task-specific accuracy.
| Metric | Description | Stage | What It Shows |
| Loss Function | Measures the difference between predicted and actual tokens (e.g., cross-entropy loss). | Pre-training, Fine-tuning | Indicates learning progress; lower loss reflects better model performance. |
| Perplexity | Evaluates how well the model predicts a sequence of words. | Pre-raining | Lower perplexity indicates improved language modeling. |
| Accuracy | Measures the proportion of correct predictions for classification tasks. | Fine-tuning | Higher accuracy means better task-specific performance. |
| Precision, Recall, F1 Score | Evaluates task-specific success by balancing true positives and false negatives. | Fine-tuning | Useful for imbalanced datasets (e.g., detecting rare events). |
| BLEU/ROUGE Scores | Assesses the quality of machine translation (BLEU) or text summarization (ROUGE). | Fine-tuning | Higher scores indicate better adherence to expected outputs. |
| Diversity Metrics | Ensures models learn varied representations and avoid repetitive outputs. | Pre-training | Helps prevent overfitting or dataset memorization. |
| Validation Loss | Tracks loss on a separate validation dataset during training. | Pre-training, Fine-tuning | Helps monitor overfitting or underfitting trends. |
The Role of Metrics in Model Development
Each metric offers distinct insights into model performance:
Pre-training Metrics
Focus on ensuring that the model learns generalized, diverse representations of language without overfitting to specific patterns. Proper data annotation is crucial here, as it directly impacts the quality of datasets used for training.
Fine-Tuning Metrics
Prioritize task-specific accuracy, balancing precision and recall to meet specific use-case demands. BLEU, ROUGE, and F1 scores gauge how well the fine-tuned model adapts to its intended tasks.
Why Metrics Matter
- Optimized Learning: Monitoring loss functions ensures that both pre-training and fine-tuning converge efficiently without wasting resources.
- Real-World Alignment: Task-specific metrics like BLEU or F1 scores verify the model’s readiness for deployment.
- Avoiding Pitfalls: Validation loss and diversity metrics help mitigate overfitting and ensure robustness, even in edge cases.
With well-selected metrics, teams can strike a balance between pre-training’s generalization and fine-tuning’s precision, creating versatile yet task-ready models.
Pre Training vs Fine Tuning Applications
Pre-training and fine-tuning enable a wide array of applications across industries. While pre-training provides the foundation for versatile language understanding, fine-tuning tailors these models for specialized tasks. Together, they form a powerful toolkit for creating adaptable, high-performing AI systems.
Applications Powered by Pre-Training
Pre-trained models power general-purpose and domain-specific applications, such as image recognition or medical imaging, with minimal customization.
Partnering with a reputable data annotation company can ensure clean, structured, and diverse data, which significantly enhances the performance of foundational models.
| Application Type | Description | Examples |
| General-Purpose LLMs | Models pre-trained on diverse datasets for wide-ranging use cases. | GPT-4, capable of writing, summarizing, translating, etc. |
| Domain-Specific Models | Pre-trained on industry-specific data for better relevance in niche areas. | Financial models trained on market data; legal models for contracts. |
| Low-Resource Language Support | Models trained to understand underrepresented languages, improving inclusivity. | Multilingual BERT for cross-lingual tasks. |
Pre-training applications are particularly effective when broad adaptability and foundational capabilities are critical, such as in multilingual tools or industry-agnostic AI systems.
Fine-Tuning Applications

Fine-tuning adapts pre-trained models to meet specific requirements. This process is especially useful for targeted tasks requiring high accuracy or domain relevance. For example, fine-tuned models are commonly used in automatic speech recognition systems to improve accuracy for specific accents, dialects, or industries.
By focusing on task-specific datasets, fine-tuning ensures these models perform optimally in their intended environments.
| Application Type | Description | Examples |
| Sentiment Analysis | Tailoring models to detect emotions in text for marketing or customer service. | Fine-tuned BERT to analyze product reviews. |
| Healthcare NLP Tools | Adapting models for processing clinical notes or patient data. | Fine-tuned BioBERT for symptom recognition. |
| Customized Chatbots | Fine-tuned for personalized, context-aware conversational AI. | Customer support bots for e-commerce brands. |
| Document Summarization | Models tuned for concise, accurate summaries of lengthy texts. | Fine-tuned T5 for legal contract summarization. |
Fine-tuning ensures precision and relevance, making it indispensable for businesses seeking high-impact, task-specific AI tools.
Pre Training vs Fine Tuning: Combined Applications
In many real-world scenarios, pre-training and fine-tuning work in synergy. Teams often use pre-trained models as a foundation. They add fine-tuning to achieve high performance in specific applications.
- Customer Support Systems: A pre-trained GPT model is fine-tuned to understand a company’s FAQs. It also works with the tone of voice and policies, enabling seamless customer interactions.
- Legal Document Analysis: Pre-trained models are first specialized on legal texts (domain-adaptive pre-training). They are fine-tuned for tasks like clause extraction or compliance checks.
- Financial Predictions: Pre-training on financial news data followed by fine-tuning for specific stock market prediction models.
By leveraging both approaches, teams can build AI systems that balance general knowledge with domain-specific expertise.
About Label Your Data
If you choose to delegate data annotation, run a free pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is pretraining and fine-tuning?
Pre-training is the process of teaching model foundational knowledge by exposing it to a vast and diverse dataset. This stage helps the model learn patterns, relationships, and structures inherent in language. Fine-tuning builds on this foundation by focusing the model on a specific domain. It uses a smaller and more targeted dataset to refine its capabilities.
What is the difference between fine-tuning and pre-training in generative AI?
Pre-training equips a model with broad, general knowledge by exposing it to large-scale, often unsupervised data. It’s like giving the model a well-rounded education. Fine-tuning narrows the focus, customizing the pre-trained model to excel at a particular task. For example, in summarization or sentiment analysis, it trains it on task-specific data.
Is fine-tuning done before pre-training?
No, fine-tuning is always done after pre-training. Pre-training lays the groundwork, providing the model with general language understanding. Fine-tuning then builds on that foundation, adapting the model for specialized applications or tasks.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.