LLM Reasoning: Fixing Generalization Gaps

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

TL;DR
- LLM reasoning includes deductive, inductive, abductive, and commonsense logic.
- Main challenges are generalization gaps, memorization, and weak multistep logic.
- Techniques to improve reasoning include CoT prompting, self-consistency, fine-tuning, and multi-agent collaboration.
- Evaluation uses MMLU, Big-Bench, accuracy, coherence, and explainability tests.
- Applications include AI in healthcare, legal tech, customer support, and scientific research.
What Is Reasoning in Language Models?
LLM reasoning is the ability of a large language model to process information, draw logical conclusions, and solve complex problems beyond simple text prediction.
This differs from simple text prediction because the model can infer meaning and analyze relationships. Reasoning allows LLMs to go beyond memorized patterns to make decisions. LLM architecture defines how models process and structure reasoning, influencing their ability to generalize beyond training data.
It’s not as complex as human problem-solving skills, but it allows various types of LLMs to tackle increasingly difficult issues. As a result, there’s a growing focus on enhancing these capabilities for real-world LLM applications.
Types of LLM Reasoning
You’re looking at four basic types here:
| Type of LLM reasoning | Description | Example |
| Deductive Reasoning | Drawing logically certain conclusions. | All humans are mortal. Socrates is human, so Socrates is mortal. |
| Inductive Reasoning | Generalizing based on observations. | The sun rises every day, so it will rise tomorrow. |
| Abductive Reasoning | Inferring the most likely explanation. | The streets are wet, so it probably rained. |
| Commonsense Reasoning | Everyday problem-solving and assumption-based logic. | Ice cream melts in the sun. |
Key LLM Reasoning Challenges
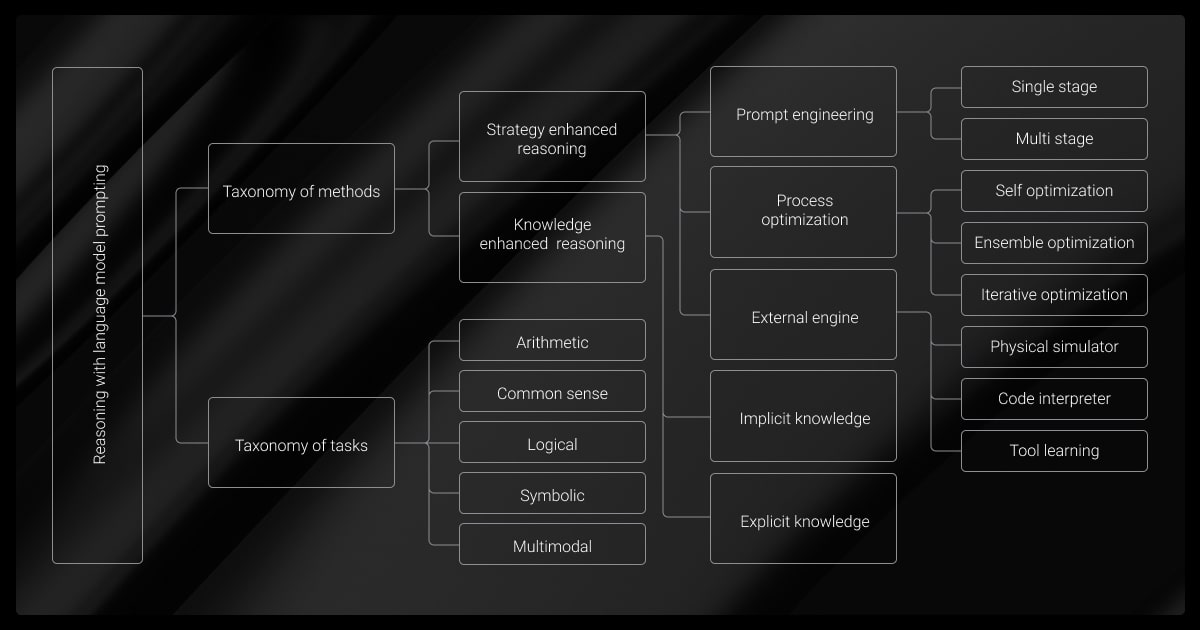
Some of the best large language models have improved, but they still struggle with reasoning. Common problems include:
Generalization Issues
AI may battle to deal with tasks outside its training data. Which means it may make errors if it encounters unfamiliar problems.
Reliance on Memorization
Machines lack human-like reasoning and often rely on pattern recognition instead of true logic. The way LLM parameters are tuned plays a role in how well a model generalizes beyond training data.
Struggles with Multi-Step Logic
The tendency to look for patterns makes it hard for machines to manage multistep tasks and complex logical chains. There can be breakdowns in the logic between each step.
Besides, LLM hallucination happens when models generate false but confident responses due to gaps in training data or weak reasoning steps. To improve these aspects, we have to change our training and LLM data labeling methods.
Techniques for Enhancing Reasoning in LLMs

Cornell University found that their GraphReason project was useful in verifying how well LLMs reasoned out problems. They also found that feeding these graphs into LLMs improved their reasoning capabilities without extra training.
But, are there other ways to improve logical consistency and problem-solving? Let’s take a look.
Chain-of-Thought (CoT) Prompting
This guides your model through a series of logical progressions, step-by-step. Remember in school how your teacher taught you to break down complex math equations into simple steps? By simplifying the problem in this way, you found it easier to get to the answer.
A Chain-of-Thought reasoning LLM works similarly. You ask the machine learning algorithm to explain its processes at each stage, so you can see if it makes any mistakes. LLM inference plays a role in how efficiently the model processes these reasoning steps and generates responses. LLM chain of thought reasoning can boost the correctness of answers because the model thinks through each step like a human would.
The downside is that the model can still make mistakes. So, even if it does take these smaller steps, it could use faulty logic. Your results depend on the LLM model size and how well you design the prompts.
Chain-of-thought prompting helps the model navigate the reasoning landscape more effectively. A study by Google Research showed that this method improved performance on complex reasoning tasks by up to 20% in some cases. We’ve also seen a 15% reduction in chatbot escalations by guiding responses through logical steps rather than jumping to conclusions.

Self-Consistency Decoding
With this technique, the LLM generates a few reasoning paths. This means that it comes up with several different solutions and compares the results. It will then choose the one that seems the most logical.
For example, if an LLM is solving a math word problem, it generates multiple step-by-step solutions instead of one. It then compares the results and selects the most common or logically sound answer. This reduces errors caused by random guesses or flawed single-step reasoning.
Fine-Tuning with Explanation-Based Datasets
LLM fine-tuning methods improve reasoning by using well-structured logical arguments during training. An example is using a dataset like GSM8K, a math problem-solving set. This teaches your LLM to reason each step out. AI learns how logical reasoning actually works rather than just identifying patterns, using LLM fine-tuning tools.
Multi-Agent Collaboration
Who says you need to stick to one model when so many LLM agents are available? With LLM orchestration, you can coordinate multiple models to simulate discussions and refine reasoning. Each model will think the problem through, share insights, and collectively generate more accurate conclusions.
Think of it like a brainstorming session in a staff meeting. Your colleague might bring up things you’d never have thought of because of their unique experiences.
ReAct (Reasoning + Acting)
This technique combines a series of reasoned steps and real-world actions. Models using this approach break problems down into smaller stages and explain their reasoning. This makes it easier for them to solve more complex issues. It also makes their processes more transparent to end users.
An example of this in action might be a virtual assistant helping a customer find products. The AI would scan the customer history and activity on the website. It would then recommend products accordingly.
Tree of Thoughts (ToT)
In this case, the model explores several logical paths in parallel. So, instead of following one linear chain, it evaluates branches off each core idea. It’s probably closest to mind mapping that we use to brainstorm.
It delivers highly accurate results for complex problems.
Reflexion
This is a continuous self-improvement loop. The model evaluates its responses and revises them as necessary. It works through several different cycles, improving the answers as it goes. This is a great way to improve accuracy because the model solves the problem in different ways.
One effective method to improve logical reasoning in LLMs is self-consistency decoding. Instead of relying on a single response, this approach generates multiple reasoning paths for the same prompt and selects the most consistent answer. By sampling different reasoning chains and aggregating the most frequent or logically sound conclusion, LLMs reduce errors caused by premature or biased reasoning.

 SEO Expert, Logik Digital
SEO Expert, Logik Digital
Tools and Benchmarks for Measuring LLM Reasoning

So, how do you determine how accurate your model is?
Tools for Reasoning Evaluation
You can choose one of the common tools or create your own evaluation pipeline:
- OpenAI Evals assesses LLM performance on reasoning tasks.
- Hugging Face Evaluate offers built-in metrics for logic benchmarks.
- Custom pipelines allow tailored evaluation but cost more.
LLM observability enables tracking of reasoning patterns and errors, helping fine-tune models for better logical consistency. You can also use tools that fine-tune reasoning-specific tasks. Tools like AllenNLP, focus on the tasks themselves rather than the model as a whole.
Key Benchmarks
The most important LLM reasoning benchmarks are:
- MMLU tests LLM reasoning in logic, math, and science using GPQA.
- Big-Bench (BBH) evaluates models on a wide range of reasoning tasks.
Pick the LLM reasoning benchmark that best measures your model’s accuracy and logical consistency.
Evaluation Metrics
There are three basic metrics we use to evaluate how well your model reasons:
- Accuracy: This is a simple test that tests how correct the answers are.
- Coherence: Checks if the model maintains consistent logic across answers.
Explainability: Here we look at how well a model justifies its reasoning.
The best way to improve logical reasoning in large language models is to incorporate symbolic solvers. These solvers allow the model to break down complex problems using step-by-step logic rather than relying entirely on pattern recognition. This improves accuracy in tasks such as solving equations, logical puzzles, and formal proofs.
 Founder, Agility Writer
Founder, Agility Writer
Practical Applications of Enhanced Reasoning in LLMs
So clearly, there’s a lot of work to do when it comes to large language models. This study laid out some of the main challenges and techniques for dealing with them. Despite the work we still need to do, reasoning LLMs are in use already.
Industry Use Cases
Here are some cases where reasoning LLM is particularly useful for different LLM use cases:
Healthcare
AI in healthcare is reading X-rays and analyzing symptoms to help doctors diagnose illness and suggest treatments. The implications are staggering. AI could pick up signs of disease that most doctors would miss, leading to earlier diagnoses.
Legal Tech
Imagine a world where contract analysis took seconds, and you could call up relevant case law in minutes. AI is helping attorneys review legal cases.
Customer Support
Reasoning is making chatbots more useful in solving complex user queries.
Scientific Research
Reasoning LLMs are poised to help science advance in leaps and bounds. AI can help us generate and test hypotheses in various fields.
Future Research Directions

Is this the end? No, let’s look at some of the advanced AI methodologies that researchers are working on.
Integrating Symbolic and Neural Reasoning
This approach combines symbolic, or traditional logic-based systems, with neural networks. This improves accuracy and interpretability. The hybrid model improves LLM’s performance in:
- Math
- Scientific explanations
- Legal reasoning
Reinforcement Learning for Logical Reasoning
Using LLM reinforcement learning to simulate multistep reasoning and enhance logical accuracy.
Applying reinforcement learning helps LLMs refine their logical reasoning skills by rewarding correct multistep solutions. This approach enhances performance in chess, theorem proving, and programming assistance.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
Does LLM have reasoning?
Yes, but it relies on learned patterns rather than true logical thinking. A chain of reasoning LLM improves consistency by breaking problems into steps. This helps it explain its answers more clearly.
How LLMs reason?
They use knowledge retrieval, pattern recognition, and structured logic to process information. This allows them to generate responses based on past data rather than deep understanding.
How to improve reasoning in LLM?
- Fine-tune on reasoning datasets: Use structured data like GSM8K for better logic.
- Apply self-consistency decoding:Compare multiple reasoning paths for accuracy.
- Use multi-agent collaboration: Let models refine answers through discussion.
- Implement Reflexion: Enable self-review and iterative improvement.
- Guide with chain-of-thought prompting: Structure prompts for step-by-step reasoning.
Can LLMs reason and plan?
Yes, techniques like ReAct and ToT help a chain of reasoning LLM analyze problems and make real-time decisions. This makes them useful for planning, scheduling, and problem-solving.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.