LLM Hallucination: Understanding AI Text Errors

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
TL;DR
- LLM hallucinations occur when models generate plausible but incorrect or irrelevant outputs.
- Common causes include incomplete training data, biases, and ambiguous prompts.
- Key types of hallucinations: factual errors and faithfulness errors.
- Mitigation strategies include fine-tuning, retrieval-augmented generation (RAG), and user feedback loops.
- Challenges in reducing hallucinations include high computational costs, bias amplification, and integration complexity.
What Is LLM Hallucination?
LLM hallucination happens when small language models produce responses that seem correct but are actually inaccurate or nonsensical. These errors are common because large language models generate text by predicting the most likely next word or phrase, not by verifying facts.
Hallucinations can appear harmless at first but pose serious challenges in fields like healthcare, finance, and education.

Why LLM Hallucination Is Problematic
Small language models are used in high-stakes applications where accuracy matters. Hallucinations can:
- Misinform users with false medical advice.
- Lead to poor decisions based on incorrect financial data.
- Spread misinformation in academic and professional settings.
Errors like these reduce trust in the reliability of LLMs. Check some LLM hallucination examples:
| Prompt | Model Output | Correct Information |
| Who invented the telephone? | “Thomas Edison invented the telephone.” | Alexander Graham Bell invented it. |
| Summarize the text about solar panels. | “Solar panels work by storing wind energy.” | Solar panels convert sunlight into energy. |
What Causes Hallucinations?
- Incomplete Training Data: Gaps or biases in the data lead to errors.
- Ambiguous Prompts: Vague or unclear input confuses the model.
- Algorithm Limitations: The probabilistic nature of LLMs prioritizes plausible responses over accuracy.
When using small language models, always double-check outputs for critical tasks. This ensures that you avoid relying on potentially misleading information.
Types of LLM Hallucinations

LLM hallucination generally falls into two categories: factual and faithfulness errors. Understanding these helps you identify and manage their impact.
Factual Hallucinations
These occur when an LLM generates outputs that contradict known facts. While the text may sound convincing, it is incorrect or unverifiable.
LLM hallucination examples:
Incorrect Facts
Claiming, “The Great Wall of China is visible from space,” despite evidence proving otherwise.
Fabricated Entities
Inventing historical figures or events, such as stating that “The Parisian Tiger was hunted to extinction in 1885.”
| Key Features | Description |
| Contradicts Verified Facts | Claims that oppose established information. |
| Fabricates Nonexistent Info | Introduces entities or events that don't exist. |
Faithfulness Hallucinations
Faithfulness errors occur when the model’s output diverges from the input prompt or provided context. The response may be internally consistent but fails to align with user expectations.
LLM hallucination examples:
Instruction Deviation
- Prompt: Translate “What is the capital of France?” into Spanish.
- Response: “The capital of France is Paris.” (Incorrectly answers instead of translating.)
Context Mismatch
- Provided Context: “The Nile originates in Central Africa.”
- Response: “The Nile originates in the mountain ranges of Central Africa.” (Adds incorrect details.)
| Key Features | Description |
| Instruction Mismatch | Output doesn’t follow the input instructions. |
| Context Divergence | Response introduces unverified or unrelated details. |
Intrinsic vs. Extrinsic Hallucinations
A more nuanced view divides LLM hallucination into intrinsic and extrinsic types:
Intrinsic Hallucinations
Errors within the provided input or context. Example: Misinterpreting or omitting key details from a document.
Extrinsic Hallucinations
Responses include unverifiable or fabricated information beyond the input context. Example: Adding unrelated facts about an unrelated topic.
| Type | What It Means |
| Intrinsic | Errors contradict the source material or context provided by the user. |
| Extrinsic | Includes additional information not present or verifiable in the source context. |
Understanding these types of LLM hallucination allows you to:
- Recognize the limits of small language models.
- Tailor inputs to reduce hallucinations.
- Use external validation for outputs in critical applications.
These distinctions highlight the complex challenges in ensuring accurate and reliable outputs from different types of LLMs.
Why Do Hallucinations Occur in LLMs?

LLM hallucination happens for several reasons. For example, hallucinations in LLMs often arise from biased or insufficient training data, a challenge similar to those faced in image recognition, where limited data diversity can lead to inaccurate classifications.
Understanding these root causes can help you minimize the LLM hallucination problem.
Data-Related Issues
LLMs rely on vast amounts of data during training. Problems in the dataset related to data annotation can directly lead to hallucinations. Common issues include:
- Incomplete or outdated data: Missing or stale information creates knowledge gaps.
- Biases in training data: Models can inherit and amplify biases from their sources.
- Misinformation: Training on low-quality or even unlabeled data (e.g., unverified web content) leads to false outputs.
LLM data labeling plays a critical role in reducing hallucinations by providing high-quality training data tailored to specific use cases.
Start by ensuring that the data used to train the model is clean, diverse, and representative of the scenarios you want the LLM to handle. This minimizes biases and gaps while guiding the model to generate more accurate and relevant responses.

 Founder & CTO, Evinex
Founder & CTO, Evinex
Model Design Limitations
The way small language models are structured contributes to their tendency to hallucinate:
- Probabilistic Nature: LLMs predict likely next words without verifying accuracy.
- Overfitting: Too reliant on specific patterns in training data.
- Underfitting: Generalizes too broadly, causing errors in complex cases.
- Lack of Real-World Knowledge: No true understanding or fact-checking ability.
Prompt Issues
Ambiguity in how you frame a query can confuse the model. Common problems include:
- Vague Prompts: Unclear questions cause misinterpretations, resulting in unrelated facts instead of a direct answer.
- Overly Complex Prompts: Complicated instructions increase error likelihood.
| Cause | Description | Example |
| Incomplete Data | Missing or outdated information leads to gaps. | A model trained pre-2020 might lack recent events. |
| Biases in Training | Inherent bias in machine learning datasets affect responses. | Gendered assumptions in job roles. |
| Prompt Ambiguity | Vague or overly complex instructions cause errors. | “Tell me about Paris” generating irrelevant details. |
Algorithmic Shortcomings
- Lack of Context Awareness: LLMs often lose track of earlier parts of a conversation or text.
- Decoding Strategies: Methods like stochastic sampling can prioritize creativity over accuracy.
These factors collectively make hallucinations an inherent challenge in small language models. While LLM hallucination problem can’t be completely avoided, you can reduce their occurrence by improving inputs, selecting better datasets, leveraging data annotation services, and using external verification tools.
When I first worked on AI-driven projects, I noticed that vague or overly broad prompts led to hallucinations, where the model would generate information that wasn't accurate or relevant. Over time, I realized that the more precise and relevant the input, the more grounded the output becomes.
 Sr. Technical Consultant, WPWeb Infotech
Sr. Technical Consultant, WPWeb Infotech
How to Detect and Mitigate LLM Hallucination
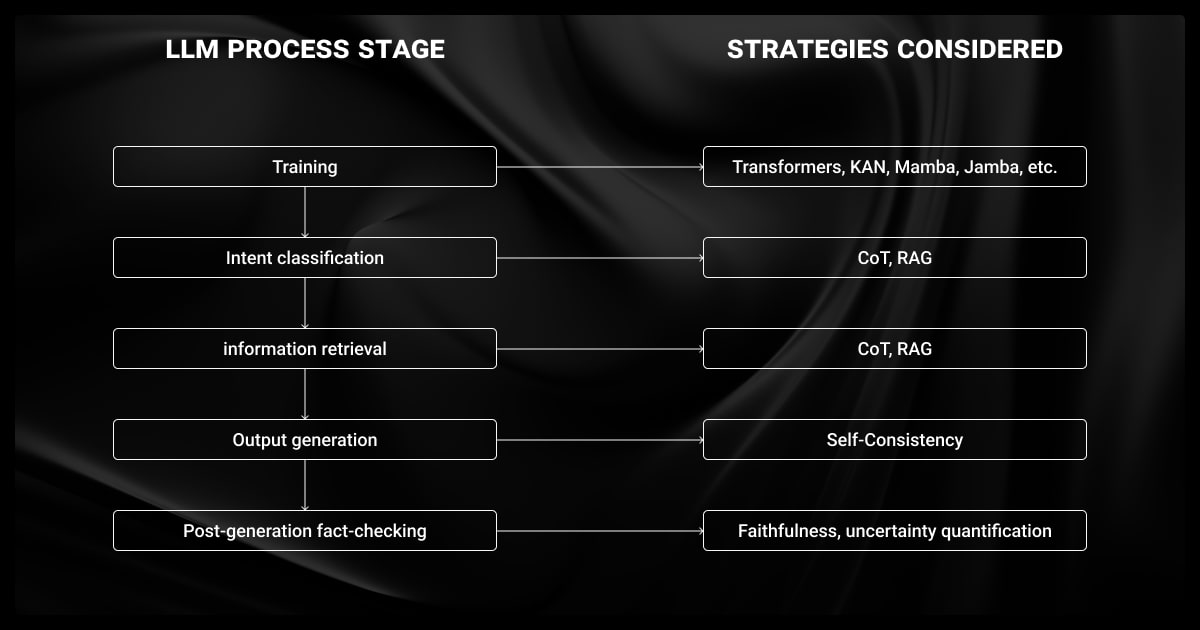
Detecting and mitigating LLM hallucination in small language models is critical for improving their reliability. While these errors can’t be entirely eliminated, there are practical strategies you can apply to identify and reduce them.
Detecting LLM Hallucination
You can use these techniques for hallucination detection LLM:
Cross-Referencing Outputs
Compare the model’s response against trusted external sources. Example: Verify historical facts or scientific data with reputable databases.
Context Consistency Checks
Ensure the output aligns with the input prompt or context. Example: If asked to summarize, check that the response doesn’t include unrelated details.
Automated Tools
Use a machine learning algorithm like semantic entropy to flag potential hallucinations by measuring uncertainty in the model’s output. Employ fact-checking systems that compare generated text to verified datasets.
Human Oversight
Involve domain experts to manually review outputs, especially for sensitive applications like medicine or law.
The most effective strategy I've developed is what we internally call the 'Contextual Verification Cascade' – a multi-stage validation framework. This involves semantic similarity matching, probabilistic confidence scoring, and machine learning models trained to detect and flag potential hallucinations.
 Senior AI Infrastructure Engineering Lead at LinkedIn
Senior AI Infrastructure Engineering Lead at LinkedIn
Mitigating LLM Hallucination
To reduce hallucinations, consider the following methods:
Improve Training Data
Use high-quality, diverse datasets to reduce gaps in knowledge. Filter out biased or incorrect data during preprocessing. LLMs trained on incomplete or inconsistent datasets can produce hallucinated outputs, a problem also seen in object detection models.
Refine Prompts
Write clear, concise instructions to minimize ambiguity. Example: Instead of “Tell me about Paris,” specify “List three historical events that occurred in Paris.”
Apply Retrieval-Augmented Generation (RAG)
Combine LLMs with external knowledge sources to ground responses in factual data. This method retrieves relevant documents before generating a response.
Iterative Fine-Tuning
Continuously update models with corrected data based on observed errors.
Set Output Constraints
Limit the model’s response scope using probabilistic thresholds or rule-based systems. Example: Restrict outputs to specific datasets in domains like finance or healthcare.
Implement Guardrails and Filters
Apply safety nets like fact-checking filters and domain-specific rule sets. Example: A filter that blocks responses if confidence levels are too low.
Proactive Monitoring
- Continuous Testing: Evaluate the model’s performance regularly using test cases. Focus on high-risk outputs, such as medical or legal responses.
- Feedback Loops: Allow users to flag errors, feeding this data back into model improvements.
By combining LLM hallucination detection and mitigation techniques, you can significantly reduce the risks. Always validate critical outputs, especially when using these models in high-stakes or sensitive domains.
Emerging Tools and Technologies to Address LLM Hallucination
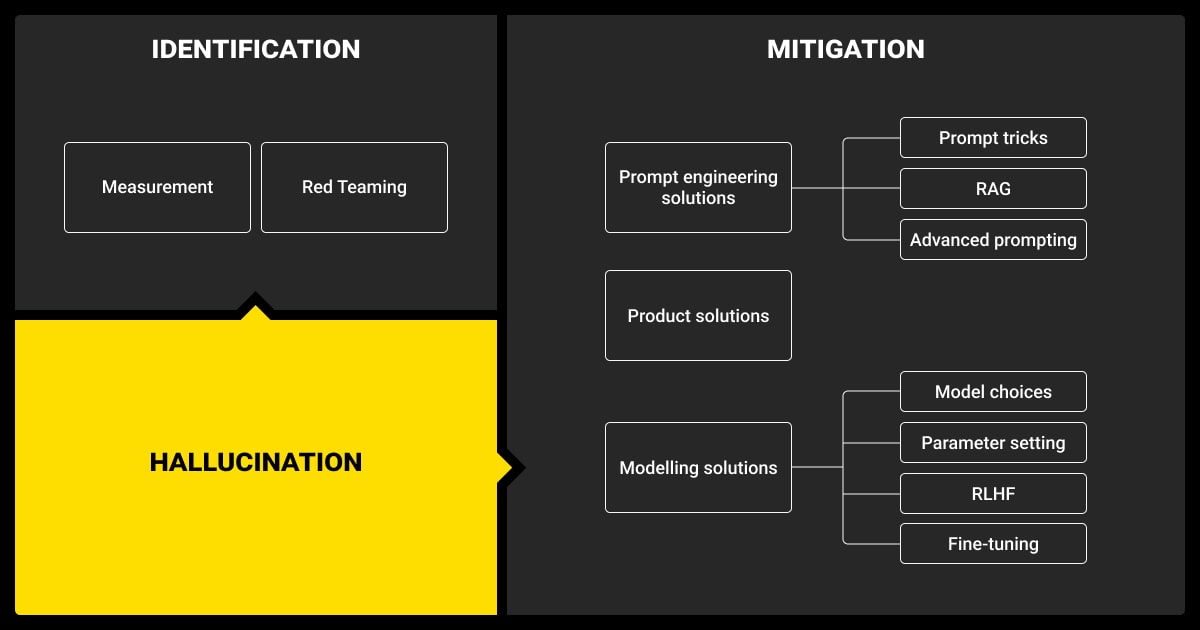
Advancements in tools and technologies are making it easier to detect, mitigate, and monitor LLM hallucination in small language models. These developments provide practical solutions for improving the accuracy and reliability of AI systems.
Continuous Monitoring with LLMOps
LLMOps integrates machine learning operations (MLOps) principles with LLM-specific tools. This ensures reliable performance while minimizing hallucinations. Key features include:
- Automated Monitoring: Tracks model outputs for errors in real time.
- Version Control: Identifies and addresses hallucination-prone model versions.
- Feedback Integration: Collects user feedback to enhance future iterations.
Retrieval-Augmented Generation (RAG)
RAG LLM combines language models with external databases to provide fact-based responses:
- How It Works: The model retrieves relevant information from verified sources before generating text.
- Applications: Effective in domains like healthcare and legal research where accuracy is non-negotiable.
Domain-Specific Fine-Tuning
LLM fine-tuning with domain-specific data reduces hallucinations by focusing on precise knowledge. For example, training a healthcare-focused model using curated medical data ensures safer and more accurate responses.
However, this approach requires expertise in LLM fine-tuning methods, access to high-quality datasets, and domain-specific oversight. Partnering with a specialized data annotation company can provide the expertise and accurate training data needed to tackle LLM hallucination problem.
Advanced Detection Tools
Innovative LLM hallucination detection methods are emerging to flag hallucinations before they reach end users:
- Semantic Entropy: Measures uncertainty in outputs to identify potential errors.
- Fact-Checking Algorithms: Automates validation against external databases.
| Tool/Technology | Functionality | Use Case |
| LLMOps Monitoring | Tracks and manages model behavior in real time. | Ongoing quality assurance for deployed models. |
| Retrieval-Augmented Gen | Integrates external data for grounded responses. | Fact-based outputs in healthcare, legal, etc. |
| Semantic Entropy | Flags responses with high uncertainty. | Identifies likely hallucinations. |
Guardrails and Filters
Using programmable safety systems ensures outputs remain relevant and accurate:
- Rule-Based Filters: Block outputs that don’t meet predefined criteria.
- Confidence Thresholds: Suppress low-confidence responses to reduce errors.
With the right LLM fine-tuning tools and technologies, you can build systems that produce more reliable and accurate outputs. Adopting a combination of monitoring, fine-tuning, and advanced hallucination detection LLM ensures better results, especially in high-stakes applications.
Key Obstacles to Mitigating LLM Hallucination
Here’s a quick look at the challenges you might face when tackling LLM hallucination in small language models, along with practical solutions to help you overcome them:
| Challenge | Description | Solution |
| Computational Overhead | High resource demand for methods like RAG slows performance. | Optimize pipelines and use lightweight models. |
| Data Quality | Incomplete or biased datasets limit accuracy. | Curate diverse, verified datasets; automate cleaning. |
| Bias Amplification | Fine-tuning can amplify existing biases. | Audit models for bias and balance training datasets. |
| Context Awareness | Models lose track of long interactions, causing inconsistencies. | Use memory-augmented models or segment conversations. |
| Integration Complexity | Advanced tools can complicate workflows. | Choose modular, plug-and-play tools for easy adoption. |
| Feedback Loops | Scaling user feedback is difficult, limiting learning. | Automate feedback collection with human oversight. |
Along with ensuring accurate datasets, we at Label Your Data provide LLM fine-tuning services to help improve your model’s performance and reduce LLM hallucination. Plus, our flexible data annotation pricing ensures cost-effective solutions tailored to your needs.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
Why do LLMs have hallucinations?
Hallucination in LLM occur because they generate text based on probabilities, not fact-checking. If the training data is incomplete, biased, or outdated, the model may produce outputs that sound plausible but aren't accurate. They lack a true understanding of facts, so errors arise when predicting the most likely next word in a sequence.
What is the hallucination metric in LLM?
The LLM hallucination metric measures how often a model generates incorrect or unverifiable information. It’s typically assessed using benchmarks or specific datasets designed to evaluate factual consistency, faithfulness to prompts, or alignment with ground truth data.
Why does ChatGPT hallucinate?
ChatGPT, like other LLMs, hallucinates because it doesn’t inherently know what’s true or false. It relies on patterns in its training data and generates responses probabilistically. When asked about topics where its data is incomplete or ambiguous, it can fabricate answers that sound convincing.
How to reduce hallucinations in my LLM outputs?
- Use clear and specific prompts to guide the model.
- Train the LLM on diverse, high-quality datasets.
- Validate responses with external tools like fact-checking or retrieval-augmented generation (RAG).
- Regularly review outputs and apply feedback for continuous improvement.
Can fine-tuning help reduce hallucinations in LLMs?
Yes, fine-tuning LLMs with high-quality, domain-specific datasets significantly reduces hallucinations. By narrowing the model’s focus, you ensure its responses are more accurate and aligned with your specific needs, especially in areas like healthcare, legal research, or finance.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.