Data Drift: Detection and Monitoring Techniques

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

TL;DR
- Data drift means input distributions shift over time, while concept drift changes the relationship between inputs and labels, both leading to model degradation.
- Detecting drift involves statistical tests (KS, Chi-square), divergence metrics (PSI, KL), and continuous monitoring of performance on labeled or delayed data.
- Not every drift signal requires action; teams should confirm that distribution changes actually affect model accuracy before retraining.
- When retraining is necessary, versioning both datasets and models ensures stability and allows safe rollbacks if new models underperform.
- Open-source and commercial tools streamline drift detection and make it easier to integrate into production pipelines.
Fighting Data Drift with Smarter Test Data
Drift is a challenge for any machine learning algorithm, no matter how well it’s designed, because models depend on stable input distributions.
Machine learning models are trained on historical data, but real-world inputs rarely stay the same. Over time, the statistical properties of incoming data shift – a phenomenon known as data drift. When this happens, a model that once performed well can start producing inaccurate or unstable predictions.
Drift is one of the most common challenges in deploying ML systems, since user behavior, environments, and external conditions constantly change. The key is not to “prevent” drift but to detect and manage it quickly through monitoring and retraining strategies.
This article explains what data drift machine learning is, how to detect it, and which practices help keep models reliable in production.
What Is Data Drift?
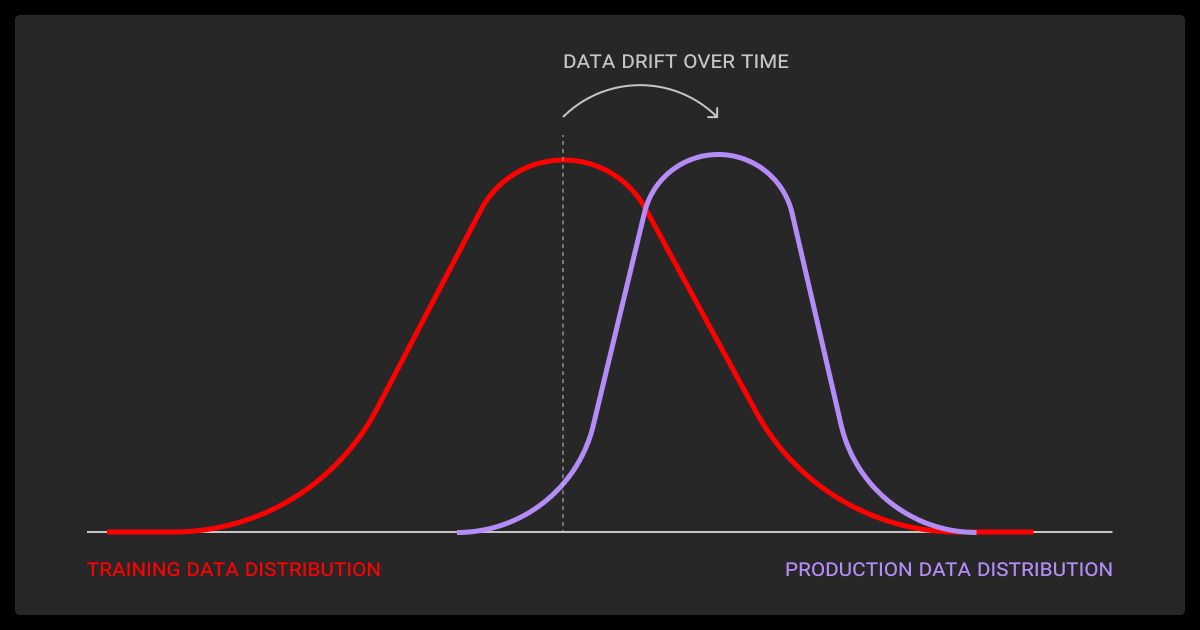
A machine learning model is first trained on historical data, where it learns statistical patterns that link input features to target outputs. Once trained, the model does not adapt automatically; it applies the learned patterns to any new data it receives.
This approach works as long as the incoming data is similar to the training distribution. But when the statistical properties of input features change, the model’s predictions often degrade. This phenomenon is known as data drift. Detecting and addressing drift is critical for maintaining reliability in production environments.
A clear example comes from retail: a demand forecasting model trained on consumer behavior before the pandemic may fail once buying patterns change drastically: face masks, sanitizers, and online purchases suddenly dominate.
Without retraining, the model produces inaccurate forecasts and decisions. Such changes directly affect machine learning datasets, since the data collected during training no longer reflects real-world conditions. At a broader scale, even large foundation models face similar challenges – debates like Gemini vs ChatGPT often touch on how these systems handle drift resilience, data quality, and the need for ongoing retraining.
Types of data drift
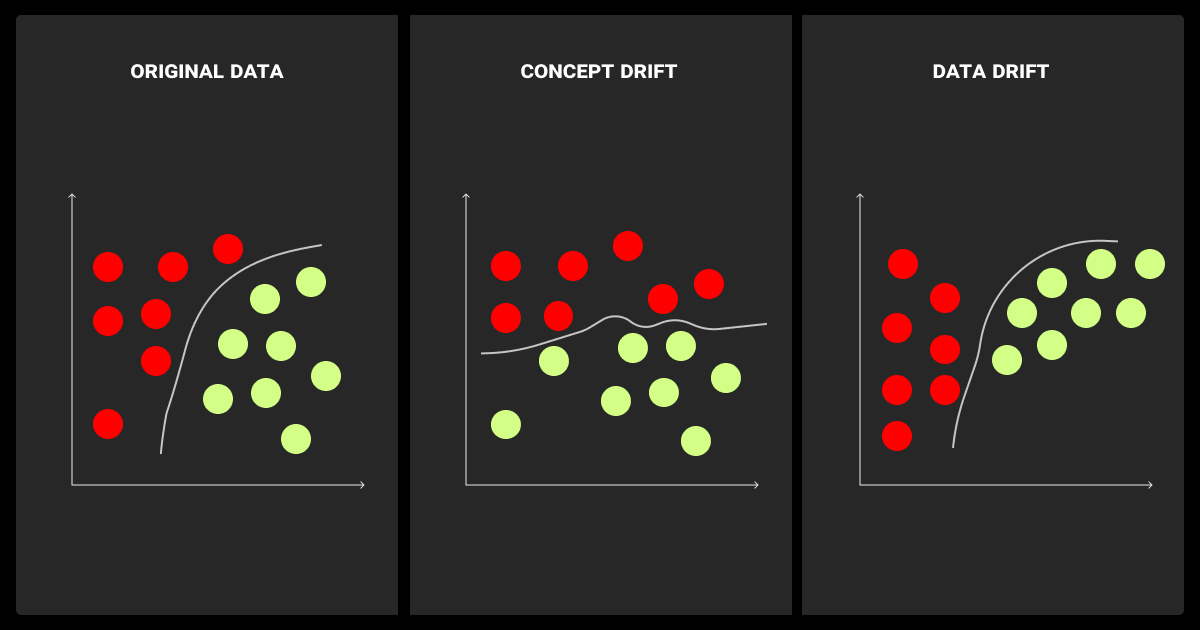
In production ML systems, understanding the difference between data drift vs concept drift is essential.
Data drift captures shifts in feature or label distributions, while concept drift refers to changes in the input–output relationship. Both degrade models but require different monitoring and remediation.
| Type | Definition | Detection/Handling | Example |
| Covariate shift | Input feature distributions change; label mapping stays stable. | Compare feature distributions (KS test, PSI); retrain if metrics degrade. | Credit scoring model fails when consumer spending shifts post-pandemic. |
| Label drift (prior probability shift) | Target label distribution changes even if inputs are stable. | Track class balance; resample or retrain with updated priors. | Spam detector trained on 10% spam sees 40% spam after new campaign. |
| Concept drift | Input–label relationship itself changes over time. | Monitor prediction errors; retrain on fresh labels. | Fraud models break as fraudsters adopt new behaviors. |
Each drift type requires different strategies. Practitioners often compare concept drift vs data drift to clarify whether the issue lies in feature distributions or target relationships. Some also use model drift vs data drift to emphasize the difference between external data shifts and the resulting internal model degradation.
For example, in image recognition tasks, small shifts in lighting or camera quality may not change inputs much statistically, but they alter how the model interprets objects.
For handling, detection metrics alone aren’t enough. You must tie drift signals to actual model performance before deciding whether to retrain.
Measurements of performance degradation are more important than drift statistics. For example, our fraud detection accuracy fell 3% in two weeks, even though drift looked minor by PSI. I use a tiered system: automate retraining on small drifts, human review for moderate ones, and emergency intervention for severe shifts.

 CTO / Software Engineer, AlgoCademy
CTO / Software Engineer, AlgoCademy
How to Detect and Manage Data Drift in Production
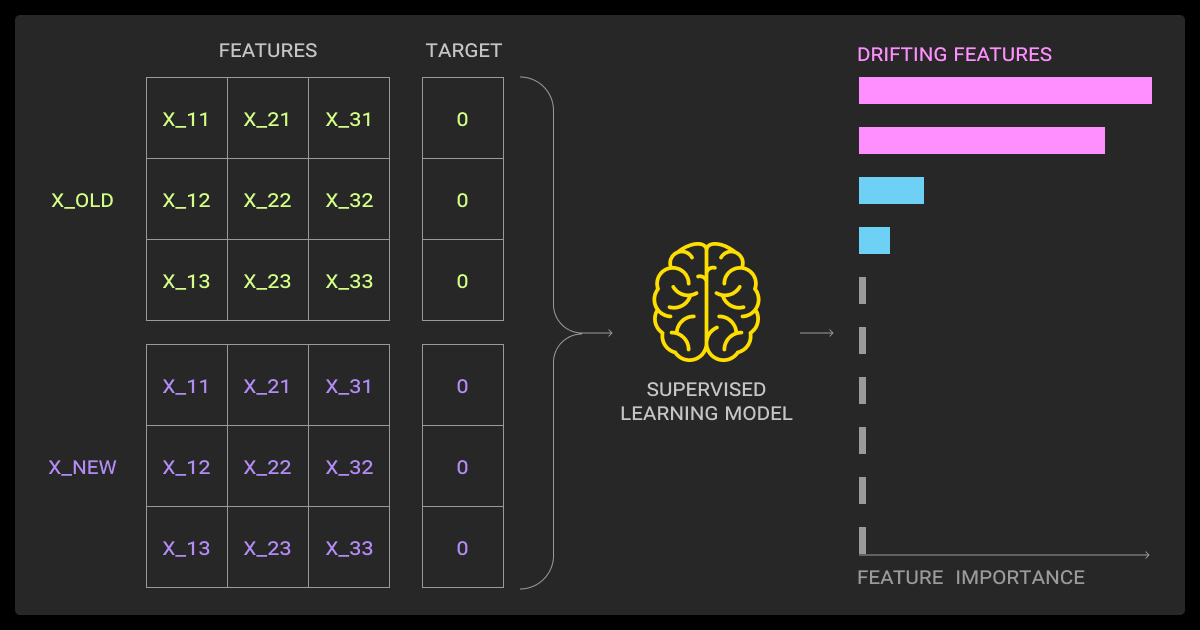
Effective data drift detection goes beyond manual observation. You need monitoring pipelines that continuously compare production data with training distributions and highlight shifts that may impact model reliability.
Data drift detection methods
One of the most common practices is applying statistical tests such as the Kolmogorov-Smirnov test for continuous variables or the Chi-square test for categorical ones. These highlight distributional differences between training and production data.
Statistical tests alone may signal distribution changes, but human-in-the-loop checks such as data annotation are often used to confirm whether predictions remain accurate.
Real-time monitoring is also used, where dashboards track input distributions and flag anomalies when drift occurs. Such systems compare production data against training baselines and alert users when new patterns appear that were not present during training.
In practice, many teams combine statistical tests with dedicated monitoring tools. Open-source libraries like EvidentlyAI provide built-in drift reports, while platforms such as Arize AI and Fiddler AI integrate drift detection with model performance dashboards. These tools make it easier to operationalize monitoring without building everything from scratch.
Many teams combine statistical methods with data annotation services to validate predictions on fresh samples and confirm whether drift is actually harming accuracy.
Data drift management tips
The first and most common way to handle data drift machine learning is by retraining or fine-tuning the model with a new dataset. This process updates the model so it can learn patterns that match the changed statistical properties of the inputs.
While this method often works, it is equally important to version both datasets and models used for training. Versioning makes it possible to roll back quickly if a newly trained model introduces errors or shows weaker performance than the previous one.
Thorough validation is also essential to check all the changes the model has gone through. By testing against both historical and recent data, you can confirm that the model continues to produce reliable results. Only after passing validation should the retrained model be deployed into production.
Partnering with a reliable data annotation company like Label Your Data can speed up the process of labeling new data for retraining.
Test Data Strategies to Prevent Drift
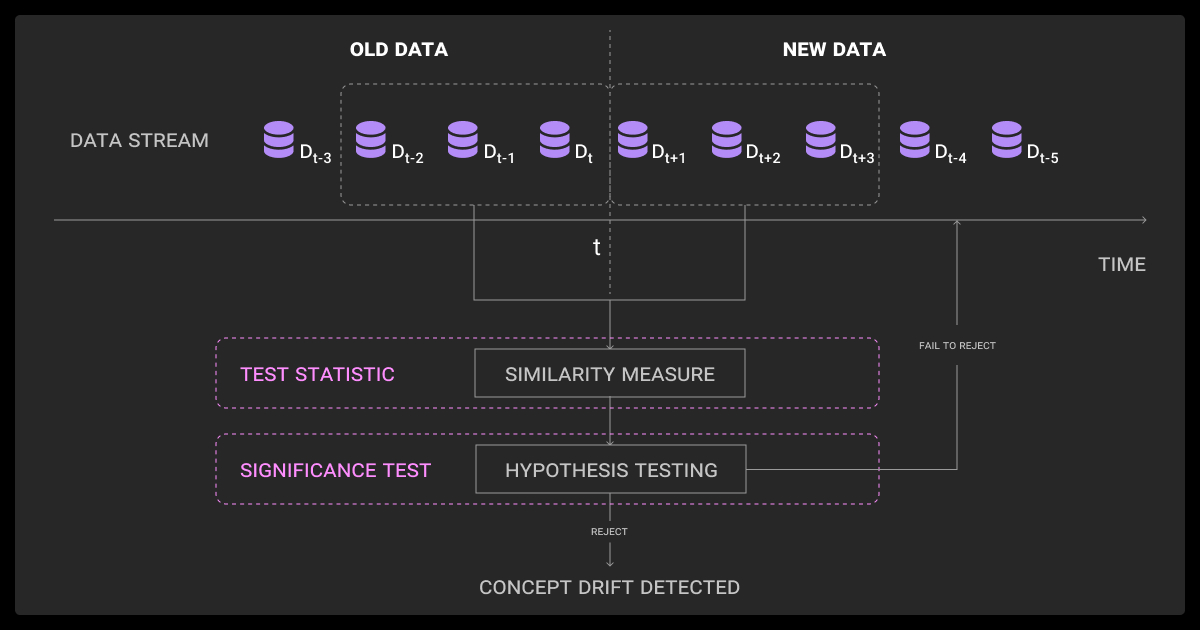
A solid test data strategy helps ensure your model performs reliably across different scenarios it may encounter in the real world. This includes normal input patterns, edge cases, and negative scenarios.
Three common approaches are:
Synthetic test data
Synthetic test data is artificially created for testing purposes. It is especially useful for evaluating how a model behaves in rare or hypothetical situations that may occur in the future. For example, financial fraud scenarios can be simulated to test how the model responds to previously unseen patterns.
testRigor, as an AI QA automation tool, is one of the best tools available in the market for simulating such test scenarios. In ML-specific contexts, simulation frameworks and synthetic data generators are more commonly used to create controlled test datasets for drift evaluation.
Edge cases
Edge cases are situations that occur infrequently but may have a significant impact when they do. They cannot be ignored. For instance, an autonomous vehicle may handle standard driving conditions, but edge-case testing evaluates how it reacts to sudden obstacles or unusual road events.
Production-parity test sets
This strategy aligns test data as closely as possible with live production data. Teams should not rely only on historical datasets to evaluate models. For monitoring drift, creating test sets that mirror production inputs is critical. This allows retraining to happen quickly and ensures the model adapts to real-world data patterns.
I treat data drift as a security risk. We use heatmaps and statistical tests to detect minor changes in traffic patterns before they become system failures. Regular retraining, or sooner when performance drops, helps prevent attackers from exploiting vulnerabilities.
 CEO and Founder, REDSECLABS
CEO and Founder, REDSECLABS
Why Continuous Monitoring Matters

Data drift is unavoidable in production machine learning systems. Input distributions, label balances, and even feature-label relationships will shift over time as real-world conditions change.
What matters is not preventing drift but detecting it early, validating its impact, and retraining when performance declines. Versioning both data and models, combined with systematic validation, allows teams to respond quickly and roll back when needed.
In this context, it’s useful to think about data drift vs model drift. Data drift describes changes in the input data, while model drift refers to the resulting degradation in a model’s predictive performance. Model drift often happens because of data drift or concept drift, which is why continuous monitoring must track both data distributions and actual model outcomes.
By treating monitoring as an ongoing process rather than a one-time setup, ML teams keep their models aligned with current conditions and ensure predictions remain reliable in production.
Keeping models current means aligning with business goals and choosing the right approach among the many types of LLMs available.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What does data drift mean?
Data drift refers to changes in the statistical properties of input data compared to the data the model was trained on. When live features no longer match the training distribution, model predictions may become less accurate.
What is the difference between data shift and data drift?
Data shift is a broad term for any change in the data distribution between training and production. Data drift is a specific type of shift, usually describing changes in input feature distributions. Concept drift, by contrast, focuses on changes in the input–label relationship.
How to fix data drift in machine learning?
- Monitor inputs and outputs continuously to detect shifts in feature distributions or prediction patterns.
- Evaluate impact on performance to confirm whether the drift is harmful.
- Retrain or fine-tune the model with updated data that reflects current conditions.
- Version datasets and models so you can roll back if a new model performs worse.
- Consider cost factors such as data annotation pricing when planning large-scale retraining, since frequent updates can be resource intensive.
What is concept drift vs data drift?
Data drift means feature distributions change while the mapping from features to labels stays the same. Concept drift means that mapping itself changes (for example, when fraud tactics evolve so that old patterns no longer indicate fraud). The distinction between data drift vs concept drift matters because they require different detection methods: distribution monitoring for data drift, and performance or error monitoring for concept drift.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.