Automation with an OCR Algorithm: Your Low-Key Workflow Superhero

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

This is the second part of a large article that tackles the topic of automated data capturing systems. We already talked about digitization of paper workflows with OCR and automated data collection systems. Now, we would like to continue our discussion of automation as a great way to organize and manage your business processes efficiently.
While computer vision in ML is that sexy field of AI that everyone likes to talk about, professional NLP services that work with text are actually far more useful for modern business. This is especially true for medium-sized and large companies that routinely deal with massive volumes of data. Think about all the reports and protocols, presentations, corporate letters and legal forms, invoices, receipts, ID cards, and so on, and so forth.
The average document flow of a modern company is truly massive. In fact, a commonly cited McKinsey report shows that employees spend around 1.8 hours daily, or 9.3 hours each week, searching for the information they need for their jobs. Naturally, a document with searchable text is better than a photo or a scan of a document. You can just hit “Find” to look for the specific word or phrase, which significantly facilitates your work with the data.
Statistical data confirms that paper documents cost more to a business than the process of creating and managing digital copies. Not to mention that reliance on paper documents is one of the largest vulnerabilities of information security. These facts speak for themselves: modern businesses would be saving quite a handsome sum just by switching from analog to digital workflows. Still, while statistics makes its case against using paper, the research suggests businesses still rely on it. And this is where Optical Character Recognition algorithms appear to save the day.
What Is an Optical Character Recognition Algorithm, and Why Is It Useful?
As part of image processing, Optical Character Recognition (OCR) is the type of annotation that allows the transcription of images of typed or handwritten messages into machine-recognizable text.
While it commonly goes unnoticed, an optical character recognition system is an irreplaceable helper when we talk about automation. It eliminates manual data entry, as well as the flow of unnecessary paper documents. It allows you to classify, organize, store, manage, and share information while avoiding security risks related to the physical nature of paper documents.
And the scope of usability for OCR gets even bigger. You have most definitely seen it in scanners for cinema tickets or at airports and train stations. It is used for OCR data extraction and security surveillance (consider license plates of the cars or street signs). E-signatures are another form of OCR. But arguably the most common use for OCR is to turn images of business documents into digital text that can be searched, edited, and managed. So, you’re probably wondering, how does OCR work?
Let's imagine a situation. You attend an important meeting. Your business partner shows you a document; you take out your smartphone and take a quick photo. It seems that you have the information you need, but it's in the form of an image. You cannot work with the document directly. Instead, you need to translate the pixels of the photo into a readable format so that you could edit and process the information it contains.
In addition, OCR-based automation is not just about sharing information in a digital form. When you have a lot of documents, machines can use them as data entries to look for patterns and trends. Visualization becomes easier too: if you need a graph, a scheme, or a spreadsheet, it's much quicker to use digital documents than compile a visually pleasing report by hand. OCR allows you to spend much less time on processing each new document, to save costs on human resources, and instead focus on value-adding strategies.
Cracking the OCR Process Flow: How Does an OCR Algorithm Work?
People are great at recognizing text characters, even when they're handwritten. For machines, however, it is a tough task. They require an ML algorithm to learn how to read the way people read. For this, the optical character recognition algorithm needs to go through a lot of training to be able to process an image of a text.
In order to understand the OCR process flow and how the OCR algorithm works, first, we'd like to tell you more about the text and its attributes. Why? Because that's how the machines see text: as part of an image.
Text Attributes for an OCR Algorithm

There is a big difference between the texts that you can find in a business setting and the texts that exist “in the wild”: on the streets, in handwritten notes, in the form of CAPTCHAs, etc. A well-structured, neat scan of a quarterly report is miles away from random graffiti caught on camera by a surveillance drone. Yet these two examples showcase a number of attributes that help to explain the image of a text to a machine learning algorithm in OCR.
- Density. In a document scan, the text is usually denser than in a text that you can see on the photo of a street corner.
- Structure. The difference is between the orderly lines of printed text vs poor structure (or lack thereof) in, say, a handwritten shopping list.
- Fonts and size. Rigid font and same-size letters are much easier to recognize compared to the stylistic inconsistency of street signs or a free style of handwriting.
- Character type. This attribute indicates the presence of not only letters but also numbers, symbols, and special characters. In addition, language is also important. A document is usually composed in a single language; on the other hand, a sign or a graffiti can include messages in several languages.
- Noise. It's important to pay attention to what means were used to get the image (scanning or photocopying for documents; photographing for signs and license plates). Depending on the method, photos tend to get more noise compared to scans.
- Location of text on the image and alignment. Scans are usually positioned front and center, with little skew. Photos, on the other hand, do not provide any semblance of a strict layout: text can be located in any part of the image, and it can also be photographed from the side.
As you can see, there's more to text than just a few rows of characters. Naturally, text attributes contribute to the nuance of building an OCR algorithm.
Now that we know how different texts can be, let's see how the OCR algorithm works.
The Process of Building, Labeling, and Training Text Recognition Algorithms
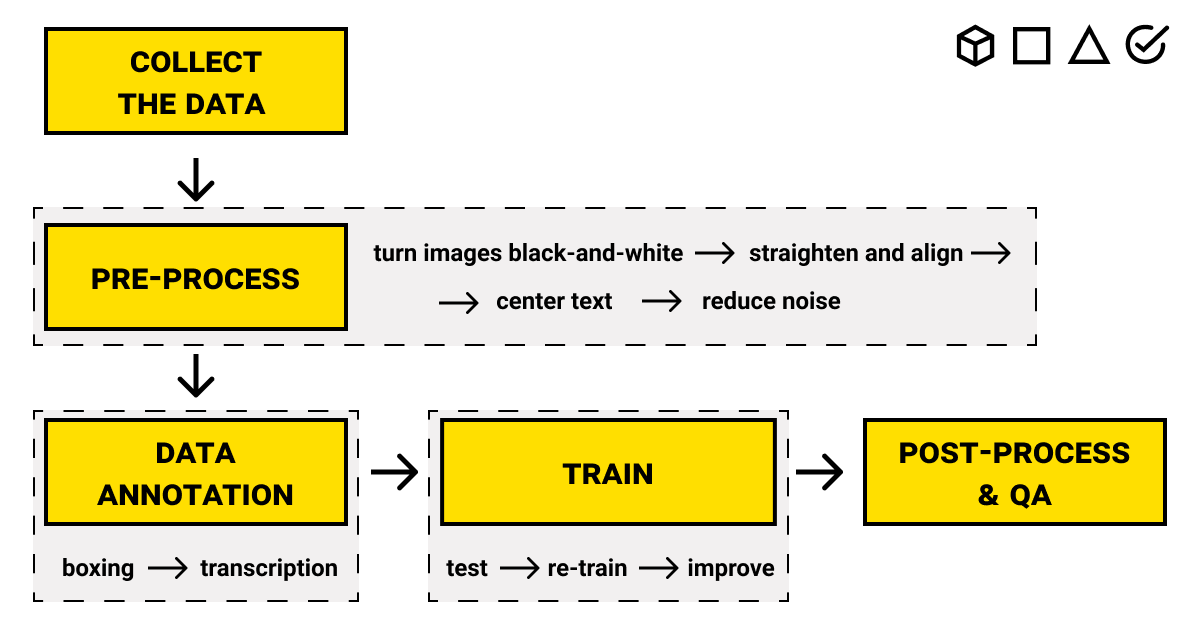
A typical OCR workflow involves several distinct steps when building a model from the ground up.
Tip: This is a short rundown of the major steps required for building an OCR engine. If you want a more detailed breakdown, follow this link to the long-read on the lifecycle of an AI project.
— Step 1. Collecting
The first thing you need to do is collect the database of documents, either by turning to expert data collection services or by gathering data yourself. You can already possess the paper documents that you wish to digitize. But, in order to build an Optical Character Recognition algorithm, you need to choose a representative sample of sufficient size. This means that the set of documents you choose should be relevant to your final goal.
In addition, this step includes scanning, photocopying, or photographing the documents. It would greatly benefit and facilitate the training process if the quality of the images is high. Read more about the features of a good dataset in our article.
— Step 2. Preprocessing
Before you can start the recognition of the text, it is essential to prepare the images of documents, to clean and optimize them for an OCR algorithm. There are quite a few issues that lead to poor quality of images: insufficient lighting, paper glints and reflections, bad camera or scanner, skewed angles, missing or poorly printed characters, etc.
If you want to train an OCR algorithm properly, here are the crucial OCR processing steps you should consider doing before moving on to the next one:
- Turn the images to black and white. Removing colors leaves less ambiguity for the detection of the text.
- Straighten and align. Weird angles significantly complicate the detection process.
- Cut and center the text. Leave only what's important: the text should be front and center, not hidden somewhere in the corner.
- Apply filters to reduce the noise. Separate characters should stand out from the background. Keep in mind that scans are usually cleaner when compared to photographs.
— Step 3. Data annotation
This is the key step for an OCR algorithm, and that's what we're here to help you with. The text recognition process consists of two tasks: detecting the text and recognition.
- We use boxing to highlight and contour the text areas. This tells the OCR algorithm what to look for in an image.
- Then, our labelerstranscribe (manually put in the words on) the image. Later, the OCR algorithm will be able to use image classification to find the patterns between the set of pixels and the types of characters.
Additionally, we throw in a couple of rounds of QA. Compared to the machines, people are much better at recognizing text in the images, but even so, we like to make sure we don't miss anything.
This step of data labeling takes up a lot of time and labor, but you don't have to worry about any of it. We'll gladly take this task off your shoulders, as OCR services is one of the specialties at Label Your Data. Give us a call now to learn more!
— Step 4. Training
Now that you have your annotated documents, you can start training the OCR algorithm. This step depends on the type of strategy you use to build your OCR algorithm. The strategies vary widely, from classic CV techniques, like image recognition, to specialized deep learning-based OCR algorithms based on building neural networks.
Computer vision services can enhance OCR model training by aiding in data preprocessing, image enhancement, text region localization, and post-processing, but their necessity depends on the specific project requirements.
Each strategy has its advantages. When selecting OCR methods, whether opting for deep learning OCR or ML-based ones, ML algorithm training usually doesn't work on the first try. Re-training and improving is common practice. Do not be disheartened if the OCR algorithm doesn't deliver the perfect accuracy of text recognition immediately. With practice and persistence, you'll get there!
— Step 5. Post-processing and QA
Actually, QA is needed on every step if you don't want to re-do all the work. But this is the final step of an OCR process flow and making your OCR algorithm live. It's time to reap the results of your hard work and finally digitize the document workflow to save time and money for your business.
On a Final Note
While not often discussed outside the ML industry, Optical Character Recognition has one of the highest usability ratings in AI. Businesses still operate based on massive volumes of paper documentation, which is an outdated and almost harmful practice. OCR can help a business deal with it by digitizing old documents or any other paper workflow and automating text recognition with machine learning.
Moreover, the scope of application for OCR doesn't end there. Any text, whether a neatly arranged report, a random shop sign, or a handwritten note, can be processed and transformed by OCR into a machine-readable text. This is the step toward automation of big data.
Curiously, despite building text recognition algorithms not being a new technique, it is as challenging as ever. Sure, the public has access to open-source OCR datasets. But if you want a state-of-the-art text recognition model that would serve your specific purposes, it's best to build one for yourself. And we can help you with it!
Tell us about your project, and we'll expertly annotate the documents to train your OCR algorithm.
FAQ
How does an automated OCR technology impact document digitization efficiency?
Automated OCR technology streamlines the process of digitizing documents by automatically recognizing and transcribing text from images or scanned pages. This reduces the need for manual data entry and enhances data accessibility and searchability in various applications, such as document management, data extraction, and archival digitization.
What are the methods of optical character recognition (OCR)?
The OCR methods can include classic computer vision techniques, specialized deep learning models, and standard deep learning approaches for text detection and recognition. Additionally, they may also incorporate NLP techniques to improve text recognition accuracy and post-processing steps for enhancing the extracted text’s quality.
Is OCR an input or output?
Optical Character Recognition is primarily an input process, as it takes images or scanned documents as input and converts them into machine-readable text or data.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.