Audio Annotation: How to Prepare Speech Data for ML

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- Understanding the Importance of Audio Annotation in ML
- Core Audio Annotation Techniques
- Best Practices for Preparing Speech Data
- Leveraging Automation in Audio Annotation
- Addressing Data Privacy and Security in Audio Projects
- Improving Audio Annotation Dataset Quality Over Time
- About Label Your Data
- FAQ

TL;DR
- Audio annotation is essential for training high-performance speech models.
- Techniques like transcription, speaker diarization, and segmentation drive real-world performance.
- Combining human insight with automation improves scalability and accuracy.
- Outsourcing to expert audio annotation partners can reduce overhead and boost quality.
Understanding the Importance of Audio Annotation in ML
Are you working on an audio-based application? Then you need to pay special attention to preparing the speech data. Whether you’re working on a voice assistant, transcription service, or call center AI, your data annotation must be on point.
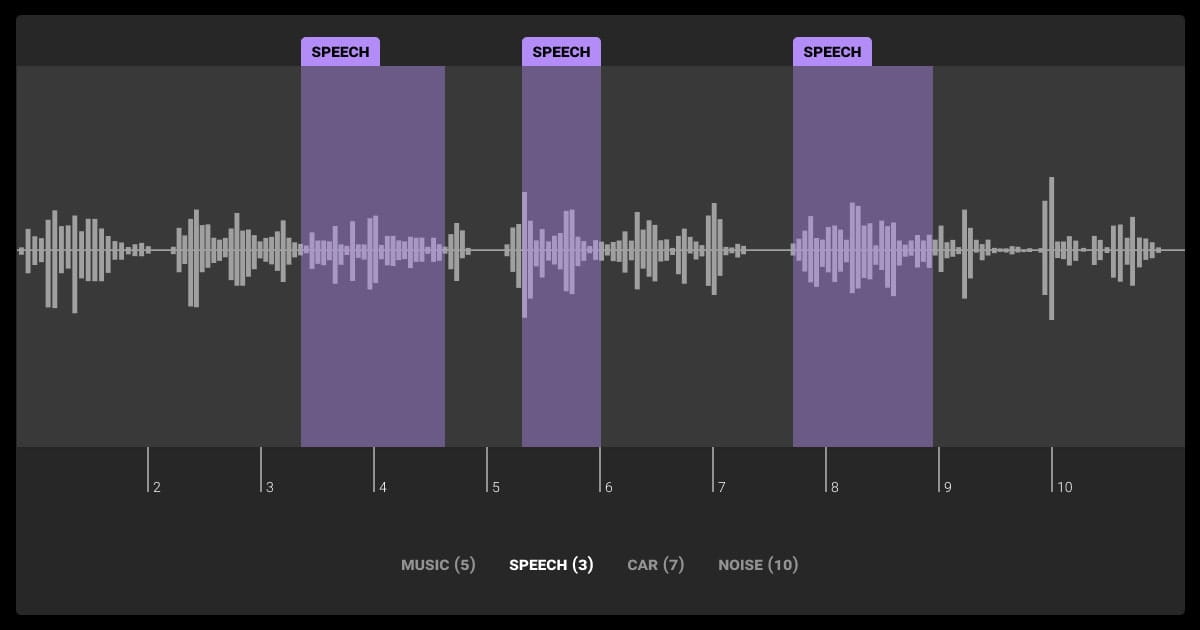
How Annotated Audio Improves ML Models
Audio annotation is the secret sauce that allows supervised machine learning models to learn. Audio labeling services convert raw sound into structured labels such as transcripts, speaker turns, and timestamps — either manually or with the help of models.
They then apply labels, so the model can distinguish between different voices and timestamp annotations to improve alignment and time-based predictions.
Better audio data annotation means:
- More accurate speech recognition
- Enhanced speaker identification
- Smoother end-user experiences in voice-driven applications
Challenges in Audio Annotation
Data annotation services can work on various data types, from image recognition to audio, to give your machine learning algorithm a solid grounding.
Working with audio isn’t easy. You have to account for:
Speech variation
People speak with different accents, dialects, intonations, and speeds. These can all impact how well the machine understands what’s being said.
Noise interference
Real-world audio often includes background noise, interruptions, or multiple speakers talking over one another.
Audio annotation services have to balance linguistic diversity and audio quality, which makes this one of the more complex labelling tasks.
Core Audio Annotation Techniques
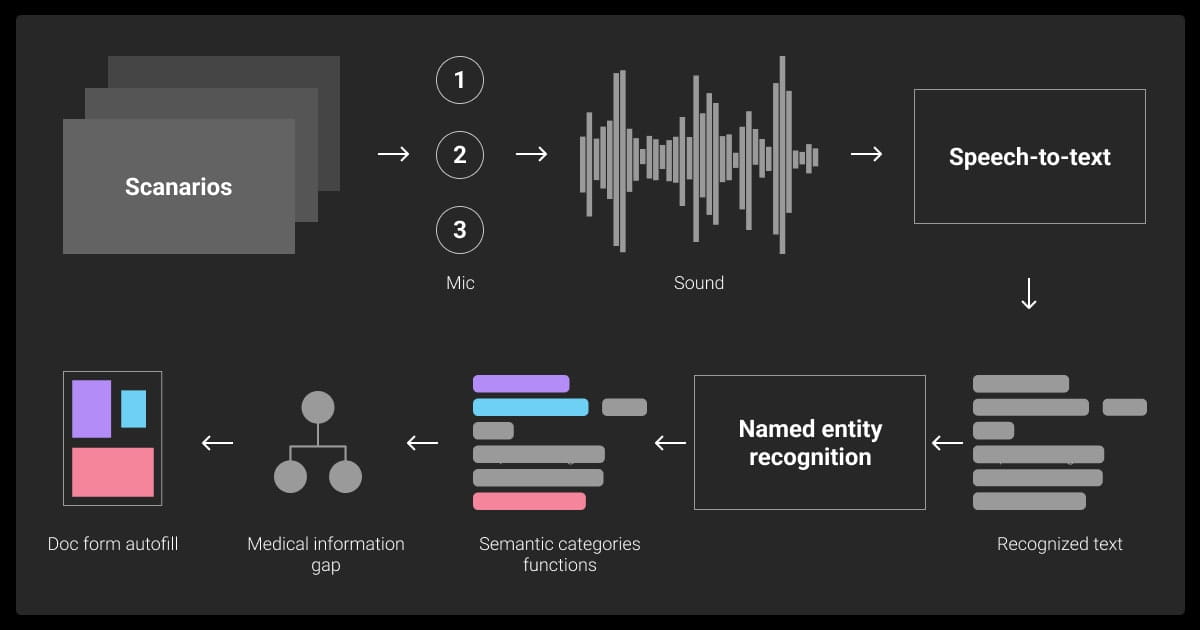
Before you prepare your dataset, you must understand the major types of annotations commonly used in speech projects.
Speech-to-Text Transcription
The most basic and often most popular technique. Here, you transcribe the audio into text. You’ll need to keep an eye on:
- Accuracy: Incorrect transcriptions introduce noise into your model.
- Ambiguity: Human annotators must resolve unclear or garbled segments, making guidelines crucial.
Speaker Diarization
Speaker diarization answers the question, “Who spoke when?” Here you’ll identify individual speakers and label their speech segments. Accurate diarization supports personalization and context-awareness in voice-based AI.
You might use this in cases like:
- Meeting transcription tools
- Interview or podcast processing
- Call center analytics
Open-source frameworks like pyannote-audio offer pretrained speaker diarization models that can help bootstrap this process in real-world scenarios.
Note: Speaker diarization identifies distinct speaker segments, but doesn’t necessarily link them to known identities. If you need named speaker identification, that’s a separate task requiring labeled speaker IDs.
Audio Segmentation with Timestamps
- Marking the start and end times of speech segments.
- Importance for aligning transcripts with audio.
Segmentation is the process of marking the speech boundaries, or when someone starts or stops talking. You need timestamps so you can align transcripts and enable downstream NLP tasks. For transcript alignment, forced alignment tools like Montreal Forced Aligner (MFA) or Gentle can automate timestamping with high precision.
High-quality segmentation supports downstream tasks like audio search by isolating relevant segments for indexing and retrieval.
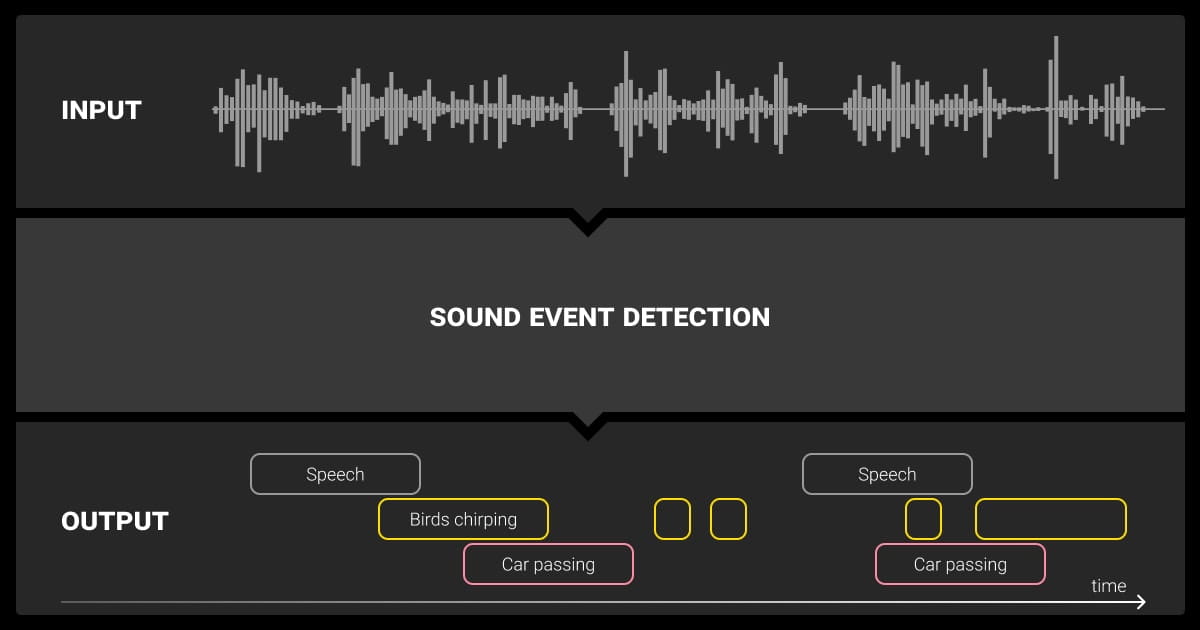
Non-Speech Event Labeling
Real-world audio includes more than just speech. You also need to label events like coughing, laughter, door slams, or background music, so your model can separate speech from other sounds.
You’ll use this for applications like:
- Automatic speech recognition
- Voice activity detection
- Emotion recognition
- AI sound recognition and noise filtering
When dealing with overlapping speakers, I've found success using a multi-pass approach where we first identify primary speakers, then layer in secondary voices while tracking confidence scores to flag segments needing human review.

 CEO, PlayAbly.AI
CEO, PlayAbly.AI
Best Practices for Preparing Speech Data
If you want effective audio annotation, you need to start long before the labeling phase. Your data collection and curation have a massive impact on the final quality of your ML model.
Smart Data Collection
You should start with diverse, representative datasets that incorporate various accents, age groups, and speaking styles. You should also gather audio for your machine learning dataset from different environments like quiet rooms, outdoor settings, and noisy offices.
But, before you start recording everyone, make sure the speakers give you informed consent. You shouldn’t record sensitive data unless it’s absolutely necessary. Even then, you must anonymize it fully.
If you’re working with data collection services, make sure they’re meeting these standards too.
Quality Assurance in Audio Annotation
You have to invest in quality assurance. You need to:
- Implement multi-pass reviews to make sure the labels are accurate.
- Set up careful guidelines and train your annotators carefully to maintain consistency.
The quality of annotation directly impacts model performance metrics like Word Error Rate (WER) and Character Error Rate (CER) in ASR systems.
Handling Accents and Dialects
Even the best models can trip up when it comes to dialects and regional accents. Annotators should:
- Familiarize themselves with linguistic variations.
- Tag accented speech to support dialect-specific fine-tuning.
- Build inclusive models that cater to diverse populations.
Tools and Platforms for Audio Annotation
You can choose an audio annotation tool to make things easier. Some popular options are:
- Audacity, ELAN, Praat for manual segmentation and phonetic labeling.
- Label Studio and Prodigy for integrated audio annotation workflows.
How do you find the right audio annotation platform for your needs? You need to carefully consider your use case. Do you need to use a lot of high-quality data sources? Do you need specialist knowledge like medical audio annotation or does a more audio annotation for NLP make sense?
Medical audio annotation often requires domain experts due to complex vocabulary, clinical context, and strict privacy regulations like HIPAA.
Look into the audio annotation tools that specialize in your particular use case. Not sure where to start? It may be time to call in an audio annotation service like Label Your Data. Outsourcing to a data annotation company gives you cost-effective access to the skills you need while improving turnaround times and consistency.
In one of our recent MilTech projects, we supported air target detection by annotating complex multi-speaker, noisy audio data for defense applications. Plus, you can check our data annotation pricing and try our free cost calculator there.
We use advanced source separation techniques to isolate speakers and reduce background noise, allowing for cleaner annotations. We flag and route particularly difficult segments through a secondary quality-control layer with context-aware labeling tools.
 Founder, OddPlug
Founder, OddPlug
Leveraging Automation in Audio Annotation
Automation can reduce the manual burden — if you use it wisely.
When to Use Automated Labeling Tools
Pre-labeling tools can automatically generate:
- Preliminary transcriptions
- Speaker separation
- Segment boundaries
But you need to be careful to balance automation and human oversight. Errors in pre-labels can mislead annotators. Tools like Whisper by OpenAI can be used for automatic transcription in the pre-labeling phase, especially when working with general-purpose or noisy audio.
Active Learning for Audio Data
Active learning helps optimize your annotation budget by:
- Letting your model label what it’s confident about
- Highlighting uncertain or misclassified samples for human review
This creates a feedback loop where the model improves faster, and annotation becomes more targeted and efficient. Popular strategies in active learning include uncertainty sampling (e.g., based on model confidence scores) and disagreement-based methods for ensemble models.
We overlay a dynamic confidence heatmap on the audio timeline instead of flat timestamps. Annotators can quickly see which segments are flagged as low certainty by an AI pre-pass due to high noise or distortion… According to recent studies, the use of visualization tools in audio annotation has led to a significant increase in accuracy and efficiency that is up to 70% higher compared to traditional methods.
 Founder, Deep AI
Founder, Deep AI
Addressing Data Privacy and Security in Audio Projects

Audio can include personally identifiable information (PII) — even unintentionally. You must build privacy and security into your annotation process.
Anonymizing Sensitive Information
Techniques include:
- Redacting names, locations, or account numbers from transcripts.
- Masking audio segments with tones or beeps.
You must always follow data privacy laws like GDPR, HIPAA, or CCPA when handling customer-facing or medical audio.
Secure Storage and Access Controls
You can protect your datasets by:
- Encrypting stored files and using secure file transfer protocols.
- Restricting access to authorized team members only.
- Auditing who accessed what, and when.
If you’re working with external vendors, confirm they follow industry standards (like PCI DSS Level 1 compliance).
Improving Audio Annotation Dataset Quality Over Time
Your first version of an annotated dataset is just the beginning. To build a scalable pipeline, plan to iterate.
Measuring Annotation Accuracy
You need to keep an eye on two important metrics for high-quality ML datasets:
- Inter-Annotator Agreement (IAA): Measures how consistently different annotators label the same data.
- Label Error Rate (LER): Helps identify annotation errors during QA.
Spotting inconsistencies early can prevent model drift and reduce retraining costs.
Evolving Audio Annotation Guidelines
As your model improves and your goals shift, your annotation schema should evolve. Revisit your guidelines regularly:
- Get feedback from annotators on unclear or edge cases.
- Document updates and version guidelines to prevent confusion.
A living annotation protocol leads to smarter, more adaptable AI systems.
Need high-quality audio labels without the overhead? Work with Label Your Data to streamline your model deployment.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is audio annotation?
Audio annotation is the process of labeling audio files with metadata like transcripts, speaker tags, or timestamps to train machine learning models.
What is an example annotation?
A simple example: in a call recording, one segment might be labeled as “Speaker A: Hello, how can I help you today?” with a timestamp marking the start at 00:03.25.
What is a common tool used for audio annotation?
Tools like Label Studio, Praat, or Audacity are widely used depending on the annotation task (e.g., transcription, segmentation, phoneme labeling).
What is speech annotation?
Speech annotation is a subset of audio annotation that specifically focuses on labeling spoken language — including what is said, who said it, and when.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.