Image Classification Models: Top Picks for Your ML Pipeline

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

TL;DR
- EfficientNetV2 fine-tunes efficiently on small to mid-sized datasets; good balance of accuracy, latency, and deployment cost.
- ConvNeXt is a modern CNN, easier to train than ResNets, and competitive with Swin at similar compute.
- ViT and Swin offer high accuracy with large-scale pretraining; Swin often edges ViT-B/16 at comparable size but both have higher latency.
- MobileNetV3 remains the go-to for mobile and edge; quantizes well for low-power devices.
- ResNet, DenseNet, RegNet, MixNet are stable baselines; not SOTA, but reliable and well-supported in production.
Top Image Classification Models in 2025
In 2025, image classification is less about chasing raw leaderboard wins and more about balancing trade-offs. Convolutional neural network (CNN) families like ConvNeXt and EfficientNetV2 still deliver state-of-the-art accuracy under limited compute or data, while Transformer-based models (ViT, Swin) shine with large-scale pretraining and high-resolution fine-tuning.
Model choice depends on more than top-1 accuracy — latency, throughput, memory footprint, and robustness to distribution shift (e.g., ImageNet-C) all shape deployment decisions. These models power many applied tasks in image recognition and serve as benchmarks when evaluating any machine learning algorithm for vision.
Which image classification model is best for your needs? Let’s go over the top options.
EfficientNetV2
EfficientNetV2 hit a strong balance at launch and still holds up. It fine-tunes efficiently on small to mid-sized datasets from pretrained weights and generalizes well. Production teams like it because you don’t need large GPUs to fine-tune, yet you get strong accuracy.
It’s a natural fit for transfer learning: grab a pretrained checkpoint, adjust the final layers, and you’re ready. Common in on-device retail product recognition and defect detection, where cost and latency matter.
ConvNeXt
ConvNeXt rethinks CNNs with lessons from transformers. It simplifies and modernizes ResNet design, scaling better and training more smoothly. With modern training (AdamW, advanced augmentation, label smoothing, EMA), it competes directly with Swin at similar compute.
If you want a CNN that feels familiar but performs like newer architectures, ConvNeXt is one of the best image classification models. It’s your safe bet for scalable production pipelines.
ViT and Swin Transformer
Transformers reshaped computer vision. ViT splits images into patches like tokens in NLP. Swin adds a hierarchical shifted-window approach, making it more efficient at higher resolutions.
Swin often achieves slightly better top-1 accuracy than ViT-B/16 at similar parameter counts and compute. Both shine with large-scale pretraining (IN-21k/JFT) and higher-resolution fine-tuning. Without that, CNNs like ConvNeXt or EfficientNetV2 can match or beat ViT-B at 224px.
These image classification algorithms excel when accuracy is top priority and compute isn’t a bottleneck; commonly used in research and high-stakes domains like medical imaging.
Segment Anything
Segment Anything Model (SAM) was built for segmentation, not classification. Some teams reuse SAM embeddings for downstream classification in multi-task setups, but this is niche.
Note: SAM has very high inference cost, so it’s impractical for typical classification pipelines.
MobileNetV3
If you’re shipping a mobile app, IoT product, or embedded system, this is usually the best of the machine learning models for image classification. MobileNetV3 is still the workhorse for edge and mobile deployments. Optimized for low-power devices, it offers strong accuracy for its size.
With transfer learning, you can adapt it quickly, and with INT8 quantization it achieves excellent real-time performance on phones, IoT, and embedded systems. For cost-sensitive teams, deployment also depends on the budget for data annotation pricing, since high-quality labeled images remain the biggest driver of model performance.
Additional picks
A few architectures remain widely used for their stability:
- ResNet: Still everywhere; modern recipes push ResNet-50 near 80% top-1.
- DenseNet: Parameter-efficient in some cases.
- RegNet: Scales predictably; production-friendly.
- MixNet: Flexible kernel sizes; efficient in edge cases.
These aren’t SOTA in 2025 but remain lightweight, stable, and well-supported in production.
Edge-Optimized Transformers
Newer transformer families target edge latency while keeping accuracy competitive:
- EfficientFormer
- TinyViT
Both deep learning models for image classification are strong alternatives if you want transformer features on device rather than CNNs.
EfficientNetV2-L has been the most reliable image classification model for me this year, but not straight out of the box. I retrained it with a carefully curated, domain-specific dataset instead of relying on the standard ImageNet weights. The breakthrough came during a medical imaging deployment for early-stage diabetic retinopathy detection, where we had to run on modest GPUs in rural clinics. The performance metrics convinced me: 91.3% F1 score and a 42% drop in inference latency compared to our old ResNet152 setup.

 CEO & Tech Entrepreneur, InTechHouse
CEO & Tech Entrepreneur, InTechHouse
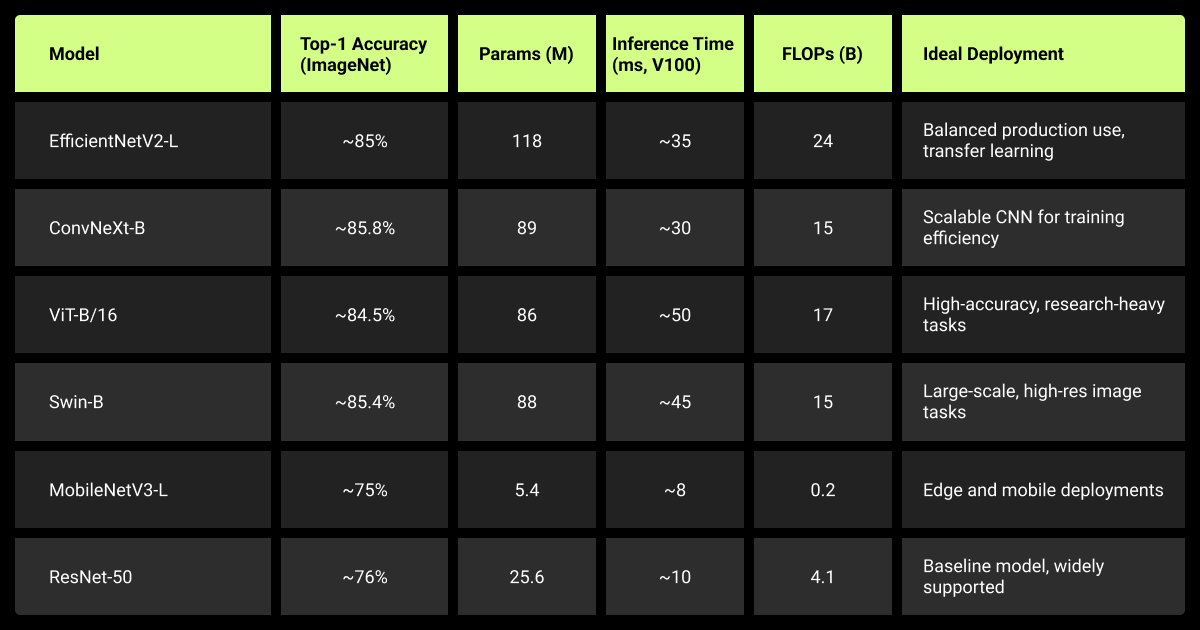
Comparison Table of the Best Image Classification Models
The table below summarizes top image classification models with their ImageNet-1k accuracy, size, and deployment considerations.
| Model | Top-1 Accuracy (ImageNet-1k) | Params (M) | FLOPs (B) | Notes |
| EfficientNetV2-L | 86.8–87.3% (IN-21k → IN-1k, 480/XL) | 120–208 | 53–94 | Strong balance; efficient fine-tuning; production-friendly |
| ConvNeXt-B | 83.8% (IN-1k only, 224) / 85.8% (IN-22k → IN-1k, 224) | 89 | 15.4 | Modern CNN; scales well; matches Swin at similar compute |
| ViT-B/16 | 81.2% (224, IN-21k → IN-1k) / ~85.4% (384, AugReg) | 86–87 | 17.6–55.5 | Needs large-scale pretraining & higher res; higher latency |
| Swin-B | 85.2% (224, IN-22k → IN-1k) / 86.4–87.3% (384–512) | 88 | 15.4–47 | Hierarchical windows; often outperforms ViT-B/16 |
| MobileNetV3-Large (224) | ~75.2% | 5.4 | 0.2 | Edge/mobile; quantizes well; real-time on device |
| ResNet-50 (modern recipe) | ~79–80.4% (with RandAug, CutMix, label smoothing) | 25.6 | 4.1 | Still the baseline; huge ecosystem & tooling |
Note: Reported inference latency varies widely depending on batch size, input resolution, hardware, and software stack (PyTorch vs TensorRT, ONNX, etc.). For reproducibility, it’s better to compare FLOPs and throughput under a specified setup rather than raw “ms on V100.”
How to Choose the Best Model for Your Task
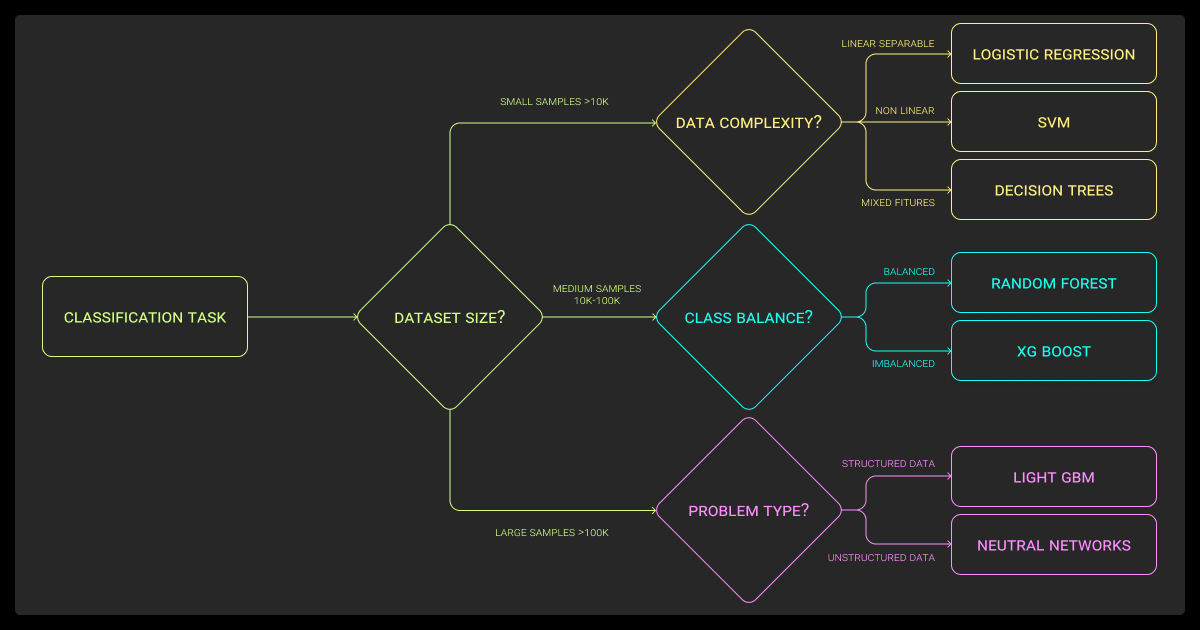
Choosing isn’t just about leaderboard numbers. The right model depends on your deployment context — cloud vs edge, available compute, and latency requirements.
Performance vs resources
If you’re training in the cloud with powerful GPUs, ViT or Swin are strong options. For real-time edge workloads, MobileNetV3 is usually the best fit. EfficientNetV2 and ConvNeXt sit in the middle, offering high accuracy without large compute costs.
If you don’t have large-scale pretraining or high-resolution data, ConvNeXt and EfficientNetV2 often outperform ViT-B at 224px. For edge, plan early for INT8 quantization or pruning — MobileNetV3 and EfficientNetV2 compress well while keeping accuracy.
Dataset factors
Model choice also depends on your dataset. Small, clean machine learning datasets benefit from transfer learning with EfficientNet. For imbalanced data, use class-balanced sampling, focal loss, or augmentation methods like mixup and cutmix. Monitor per-class F1 or balanced accuracy, not just top-1.
In messy, real-world settings, robustness often matters more than chasing small gains on ImageNet.
For financial fraud detection specifically, we’ve had remarkable success with ensemble methods combining ResNet-50 variants for transaction image classification. Swift’s anomaly detection platform saw a 60x speed improvement when we eliminated their memory bottleneck — the metric that convinced us was time-to-detection dropping from hours to minutes on the same hardware.
 CEO, Kove
CEO, Kove
Where to Find Pre-Trained Image Classification Models
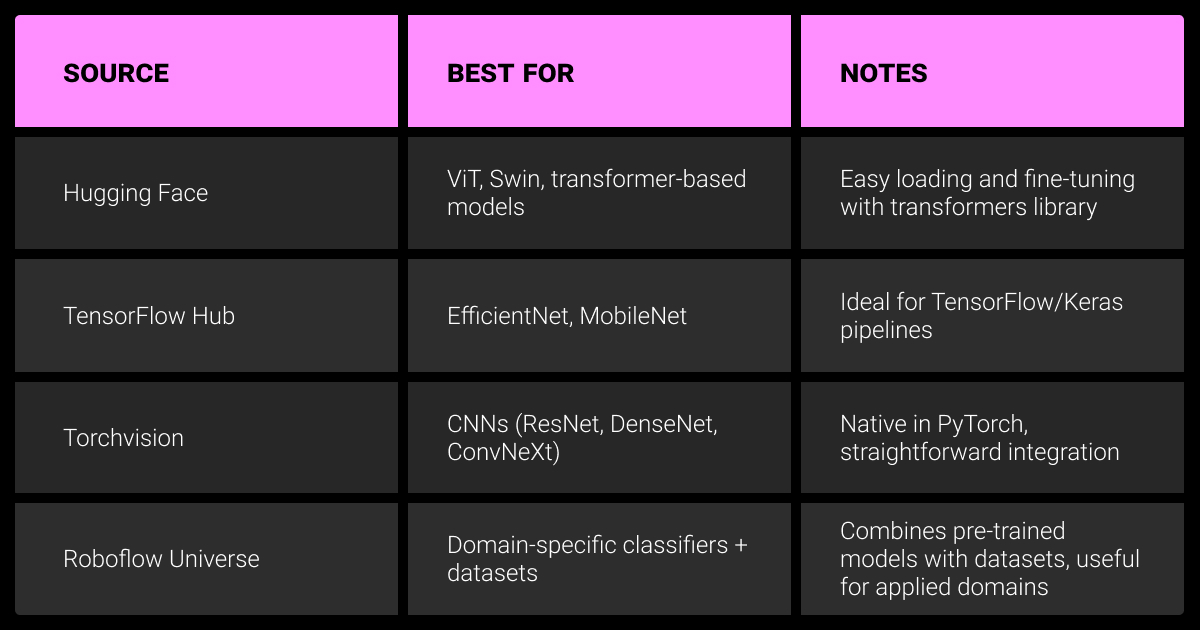
You don’t need to start from scratch. Most practitioners use one of these sources when looking for pretrained image classification models.
Hugging Face
Best for transformer-based models like ViT, Swin, and ConvNeXt-V2. The Transformers and timm integrations make fine-tuning straightforward. Model cards usually include training data, resolution, and recipes — check these details before citing accuracy.
TensorFlow Hub
A go-to for EfficientNet and MobileNet variants. It fits naturally into TensorFlow/Keras workflows and provides ready-to-use saved models for quick deployment.
Torchvision and timm
Torchvision remains the standard source for CNNs such as ResNet, DenseNet, and ConvNeXt. For broader coverage, the timm library offers hundreds of architectures and modern training recipes, making it the most complete resource for PyTorch users.
Roboflow Universe
Useful when you need both datasets and models in specific domains. It’s more community-driven and less standardized than Hugging Face or Torchvision, but valuable if you’re experimenting with domain-specific classifiers.In practice, most pipelines combine transfer learning with these repositories, making them the primary sources of pre-trained models for image classification.
Swin Transformer has been the most effective for us in B2B product catalog automation and lead generation. The key was its precision–recall balance when classifying subtle variations in product images. That accuracy in extracting product variations directly improved lead quality and sales outreach.
 CEO, Bookyourdata
CEO, Bookyourdata
Best Practices with Pretrained Models
Using a pretrained checkpoint is only the starting point. To get stable results in production, you need to adapt and validate the model carefully.
Fine-tuning vs. feature extraction
With limited data, freeze most layers and retrain only the classification head. A slightly larger dataset allows fine-tuning of higher blocks with a lower learning rate. For large datasets, unfreeze the whole network and fine-tune end to end, often with differential learning rates across layers.
Data labeling quality
High-quality, consistent labels matter more than small architecture differences. Class balance and data annotation consistency often drive accuracy gains beyond switching from one model family to another. This is where working with an experienced data annotation company can matter more than the choice of architecture.
Evaluation and monitoring
Validation accuracy is not enough. Check robustness to corruptions or distribution shifts using benchmarks like ImageNet-C or ImageNet-P. In production, monitor for drift and performance degradation over time. For edge deployments, always test quantized or pruned versions separately, since compression can reduce accuracy.
In summary, getting the most out of pretrained models means combining the right fine-tuning strategy, strong annotation practices (or outsourcing to expert data annotation services), and careful evaluation under real-world conditions.
About Label Your Data
If you choose to delegate data labeling, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What are image classification models?
They are deep learning models for image classification, trained to assign labels to images such as cats vs dogs or defective vs non-defective parts. Most are built on CNN or transformer backbones.
What is the popular model for image classification?
ResNet is still a widely used baseline. In 2025, EfficientNetV2 and ConvNeXt are strong choices for production tasks, while ViT and Swin are common in research and accuracy-driven applications.
Which AI model is best for image classification?
There’s no single best model. EfficientNetV2 offers a balance of accuracy and efficiency for general production. ViT and Swin reach top accuracy with large-scale pretraining. MobileNetV3 is best suited for mobile and edge deployments.
Is Adam or SGD better for image classification?
AdamW is the standard choice for transformer models due to stable convergence. For CNNs, SGD with momentum and a cosine learning rate schedule often generalizes better. Many pipelines start with Adam/AdamW and then fine-tune with SGD.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.