Instance Segmentation: Identify and Classify Objects Precisely

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- What Is Instance Segmentation?
- How Does Instance Segmentation Work?
- Tools and Frameworks for Instance Segmentation
- Challenges in Instance Segmentation
- How to Overcome These Challenges
- Applications of Instance Segmentation
- How to Get Started with Instance Segmentation
- Future Trends in Instance Segmentation
- About Label Your Data
- FAQ

TL;DR
- Instance segmentation identifies and labels individual objects in an image with pixel-level precision.
- Combines object detection and segmentation using models like Mask R-CNN, YOLACT, and DETR.
- Key applications include autonomous driving, healthcare, retail analytics, and robotics.
- Requires high-quality data labeling, handles occlusions poorly, and demands significant computational resources.
- Focus on real-time processing, transformer-based models, scalable annotation, and expanded industry adoption.
What Is Instance Segmentation?
Instance segmentation is a computer vision technique that identifies and separates each object in an image. Unlike other segmentation methods, it not only detects objects but also labels every pixel belonging to each object, providing precise boundaries for individual instances.

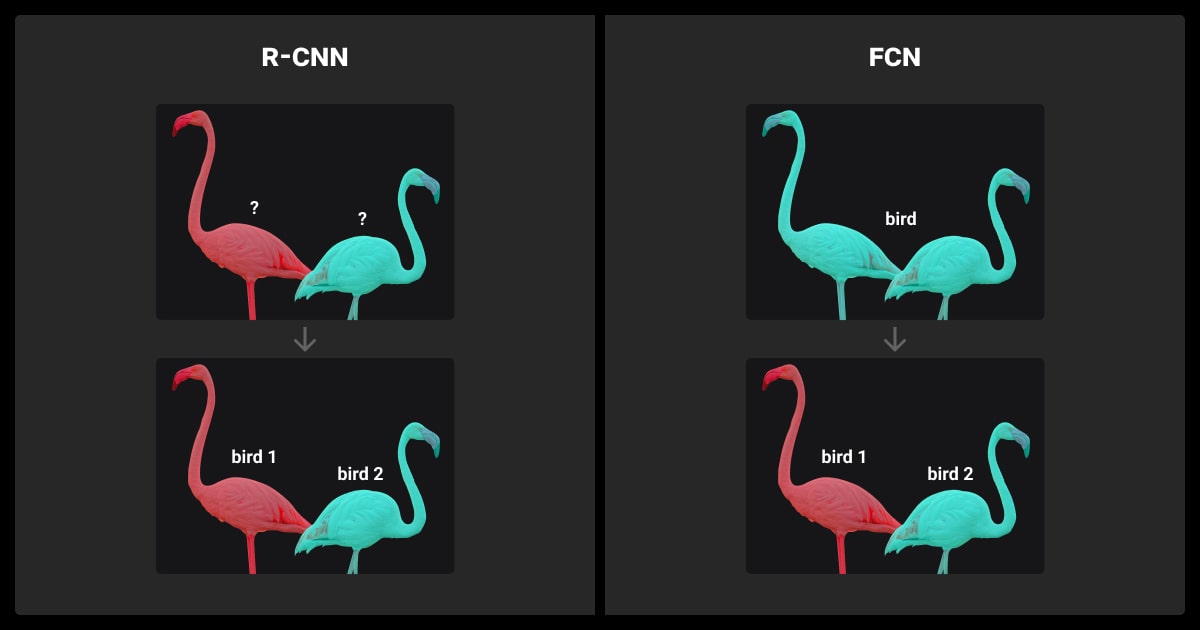
How Is Instance Segmentation Different?
Here’s a quick comparison with similar tasks to help you understand the difference between semantic segmentation vs instance segmentation, and also object detection:
| Task | What It Does | Limitation |
| Object Detection | Detects objects using bounding boxes. | Cannot provide pixel-level boundaries. |
| Semantic Segmentation | Labels all pixels by class (e.g., “car,” “tree”). | Fails to differentiate between multiple objects of the same class. |
| Instance Segmentation | Identifies and segments each object instance with pixel-level precision. | Requires more computational resources and data. |
Key Features of Instance Segmentation
- Pixel-level precision: Determines the exact shape and boundaries of objects.
- Individual object detection: Separates overlapping or adjacent objects, even if they belong to the same class.
- Context awareness: Allows detailed analysis of scenes, critical for applications like autonomous vehicles or medical imaging.
Instance Segmentation Benefits
Instance segmentation plays a critical role in applications that demand precise identification and separation of individual objects. Its ability to label every pixel belonging to a specific object makes it a key tool for solving real-world challenges:
- Enhanced precision: Provides pixel-level accuracy for tasks requiring fine detail.
- Improved automation: Enables AI systems to handle complex visual tasks independently.
- Greater context awareness: Helps systems understand spatial relationships between objects.
Instance segmentation combines object detection and pixel-level labeling to provide more meaningful insights into images, making it a key tool in modern AI applications.
How Does Instance Segmentation Work?
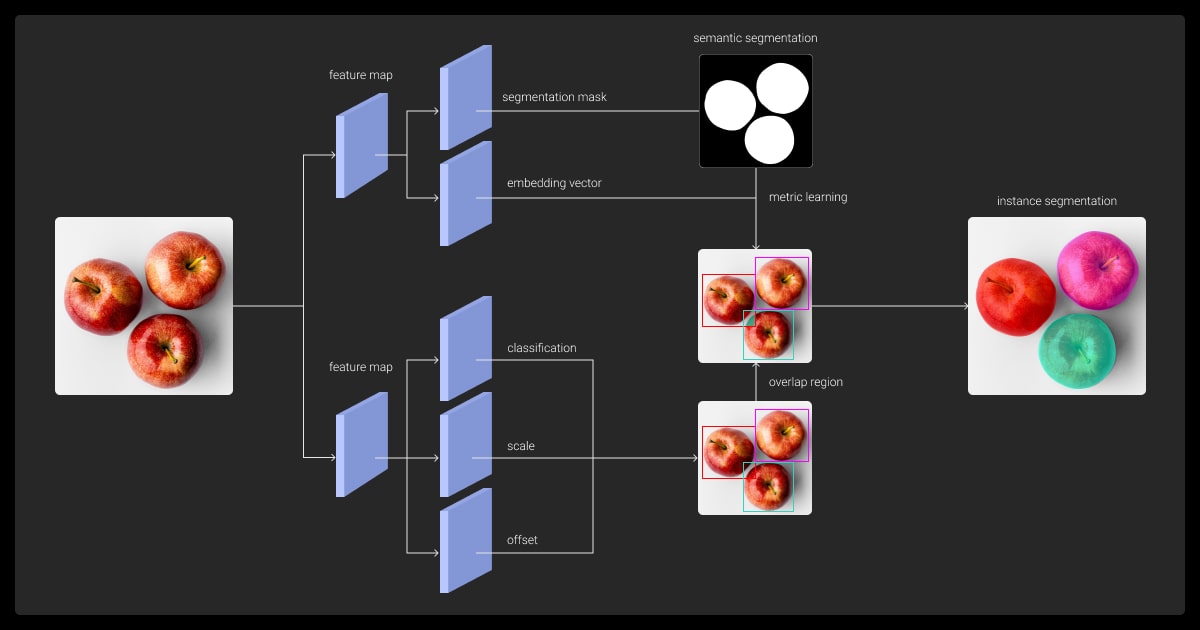
Instance segmentation combines object detection and pixel-level segmentation to identify and label each object in an image. It involves multiple steps to achieve high precision in detecting and segmenting individual instances.
Instance segmentation offers a more advanced approach compared to traditional image recognition by delivering detailed object masks
The Process of Instance Segmentation
Feature Extraction
- The model first processes the image to extract important visual features using a backbone network like ResNet or VGG.
- These features represent patterns such as edges, textures, or shapes.
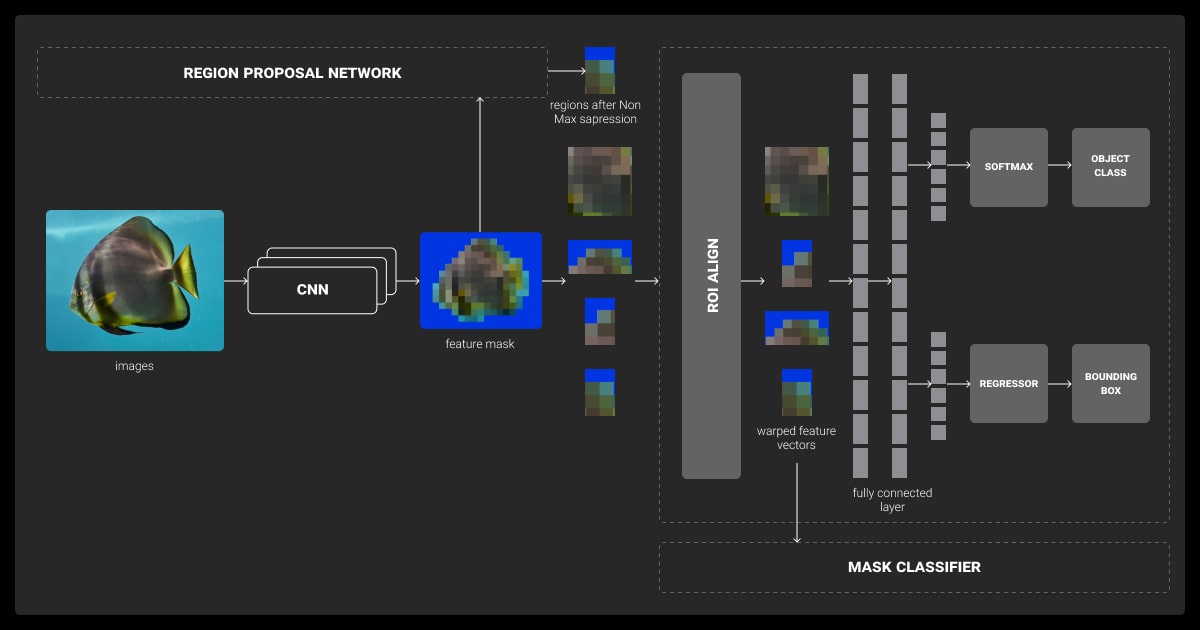
Object Detection
- A region proposal network (RPN) identifies potential object locations in the image, usually by generating bounding boxes.
- This step ensures the model focuses only on areas likely to contain objects.
Segmentation Mask Creation
- For each detected object, a segmentation mask is generated to label each pixel that belongs to the object.
- Models like Mask R-CNN use a fully convolutional network (FCN) to predict the mask.
Refinement
- Layers like RoI Align improve accuracy by aligning features with the object’s region of interest.
- The final outputs include class labels, bounding boxes, and pixel-level masks.
Unlike unsupervised methods that work with unlabeled data, instance segmentation requires pixel-perfect annotations for training accurate models. Besides, understanding the differences in image classification vs. object detection is essential for grasping how instance segmentation extends these techniques to achieve pixel-level precision.
Popular Instance Segmentation Models
- Mask R-CNN: A two-stage model that combines object detection with mask prediction. It is widely used due to its accuracy and flexibility.
- YOLACT (You Only Look At Coefficients): A single-stage model designed for faster segmentation, suitable for real-time applications.
- DETR (Detection Transformer): Uses transformers for segmentation tasks, offering scalability and improved accuracy for complex scenes.
Key Techniques
- Two-stage approach: Separates object detection and segmentation into two steps (e.g., Mask R-CNN).
- Single-stage approach: Handles detection and segmentation in one step, offering speed over accuracy (e.g., YOLACT).
- Attention mechanisms: Transformer-based models like DETR improve segmentation by focusing on relationships between image regions.
Instance segmentation leverages these techniques to achieve detailed and accurate segmentation, making it essential for applications like autonomous vehicles, medical diagnostics, and industrial automation.
The integration of Feature Pyramid Networks (FPN) with Mask R-CNN delivers superior instance segmentation results by enabling multi-scale feature learning. By incorporating a top-down pathway with lateral connections, we achieve up to a 37% improvement in Average Precision (AP) compared to baseline models, particularly for small object detection and precise mask generation.

 CEO & Founder, EvolveDash
CEO & Founder, EvolveDash
Tools and Frameworks for Instance Segmentation
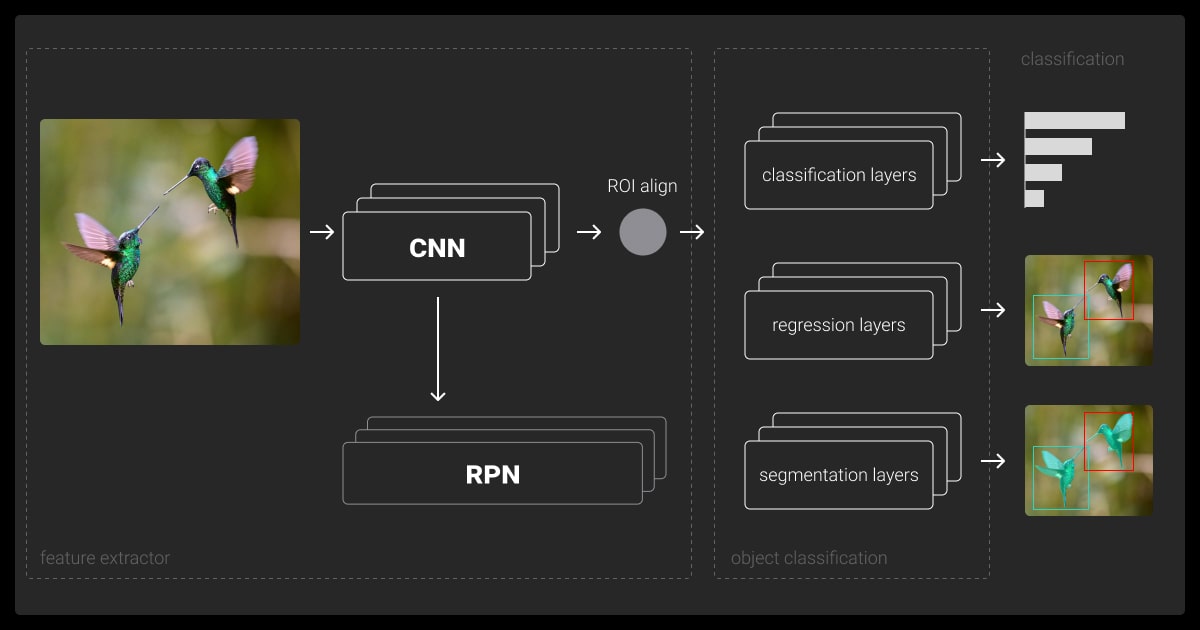
Instance segmentation relies on advanced tools and frameworks to handle the complexity of detecting and segmenting individual objects. These resources simplify the process of model development and deployment for real-world applications.
Popular Open-Source Libraries
| TensorFlow | PyTorch | MMDetection |
| - Offers pre-built instance segmentation models like Mask R-CNN. - Flexible for training custom or pre-trained models. | - Includes Detectron2, optimized for instance segmentation. - Easy to customize with high performance. | - PyTorch-based toolbox supporting multiple models like Mask R-CNN. - Suitable for research and production. |
Pre-Trained Models
- Mask R-CNN: The most widely used model for instance segmentation, offering a balance of accuracy and usability.
- YOLACT: Faster and suitable for real-time applications, like robotics and autonomous vehicles.
- DETR (Detection Transformer): A newer transformer-based approach with improved accuracy for complex tasks.
Industry-Grade Solutions
| NVIDIA DeepStream | AWS Rekognition |
| - Optimized for video analytics like surveillance and traffic management. - Includes tools for deploying instance segmentation models at scale. | - Cloud-based service for image and video analysis, including segmentation. - Ideal for businesses preferring managed services over in-house setups. |
Choosing the Right Tool
When selecting a tool or framework for instance segmentation, consider:
- Ease of use: Libraries like Detectron2 and MMDetection simplify training and deployment.
- Performance needs: For real-time applications, prioritize faster models like YOLACT.
- Infrastructure: Cloud-based solutions like AWS Rekognition can reduce the need for local resources.
These tools and frameworks provide the building blocks for instance segmentation, allowing us to implement cutting-edge computer vision solutions with greater efficiency.
Challenges in Instance Segmentation
Despite its potential, instance segmentation comes with its own set of challenges. These limitations often arise from the complexity of separating individual objects in highly detailed and dynamic visual data.
Data Labeling Complexity
- Challenge: Instance segmentation requires pixel-perfect datasets, best handled with data annotation services.
- Impact: Poorly labeled data can lead to inaccurate results, making training unreliable.
Handling Occlusion
- Challenge: Overlapping objects can confuse models, especially when objects belong to the same class (e.g., multiple cars in a traffic scene).
- Impact: Models may fail to separate objects accurately, reducing segmentation precision.
High Computational Requirements
- Challenge: Instance segmentation models, particularly two-stage ones like Mask R-CNN, demand significant hardware resources for both training and inference.
- Impact: This limits accessibility for teams without high-performance GPUs or cloud infrastructure.
Limited Generalization
- Challenge: Models fine-tuned on specific datasets often struggle when applied to new environments or domains.
- Impact: Retraining or fine-tuning becomes necessary, increasing time and cost.
One of the most effective techniques for improving instance segmentation involves training on diverse, high-quality datasets. The more varied the data, the better the model becomes at distinguishing between objects in different contexts.

How to Overcome These Challenges
Use High-Quality Data Annotation
Collaborate with a professional data annotation company to ensure accurate and efficient dataset preparation.
Optimize Models
Use lightweight models like YOLACT for faster processing and lower resource requirements.
Leverage Pre-Trained Models
Fine-tune pre-trained models to save time and reduce computational load.
Augment Training Data
Apply techniques like data augmentation and synthetic data generation to improve model robustness.
By addressing these challenges with the right strategies, instance segmentation can be effectively applied to complex visual tasks, driving innovation across industries.
Applications of Instance Segmentation
Instance segmentation is a powerful tool in computer vision with diverse applications across industries. Its ability to provide pixel-level precision and distinguish individual objects makes it essential for solving real-world problems.
| Industry | Use Case | Example | Impact |
| Autonomous Driving | Identifying vehicles, pedestrians, and road signs | Segmenting pedestrians in a crosswalk | Enhances safety and decision-making in real-time |
| Healthcare | Segmenting organs, tumors, or cells | Detecting cancerous cells in MRI or CT scans | Improves diagnostic accuracy and treatment plans |
| Retail | Tracking products on shelves | Identifying low-stock or misplaced items | Streamlines inventory management |
| Satellite Imagery | Mapping buildings, roads, and natural features using geospatial annotation | Distinguishing individual buildings in urban areas | Enables better urban planning and disaster response |
| Manufacturing & Robotics | Picking, sorting, and assembling components | Detecting defective items on assembly lines | Reduces production errors and increases efficiency |
| Surveillance | Tracking individuals or objects in crowded environments | Segmenting faces and bodies in video analytics | Strengthens monitoring and incident detection |
Instance segmentation’s versatility enables industries to solve complex challenges with greater precision and efficiency. For example, combining OCR deep learning with instance segmentation can enhance document analysis by segmenting individual fields or text regions.
Its wide-ranging applications demonstrate its importance in advancing automation and analytics.
How to Get Started with Instance Segmentation
Getting started with instance segmentation requires a combination of the right tools, datasets, and best practices. Here’s a straightforward guide to help you implement it effectively.
Choose the Right Model
- Pre-Trained Models: Use pre-trained models like Mask R-CNN, YOLACT, or DETR to save time and resources.
- Task-Specific Models: Fine-tune models based on your specific application, such as autonomous driving or medical imaging.
Prepare a High-Quality Dataset
- Data Collection: Gather images relevant to your application.
- Annotation: Use annotation tools to label images at the pixel level. Consider leveraging data annotation services to ensure accuracy and efficiency.
- Balance Classes: Ensure datasets are balanced to avoid bias toward overrepresented classes.
Train Your Model
- Use frameworks like PyTorch or TensorFlow for training.
- Set parameters like learning rate, batch size, and epochs to optimize training.
- Augment your dataset with techniques like flipping, cropping, or rotating images to improve model robustness.
Evaluate and Refine
- Validation: Test the model on a validation dataset to check its accuracy.
- Metrics: Use metrics like Intersection over Union (IoU) or mean Average Precision (mAP) to measure performance.
- Refinement: Adjust parameters or expand the dataset if the model underperforms.
Deploy and Monitor
- Deploy the model to your production environment, ensuring compatibility with your hardware or cloud infrastructure.
- Regularly monitor its performance and retrain with updated data as needed.
Instance segmentation becomes manageable by breaking it into these steps. With the right approach and tools, you can implement accurate and efficient models for real-world applications.
Augmenting the training dataset with variations like flipping, rotating, or scaling images helps the model generalize better and handle real-world variations. At the same time, fine-tuning the model architecture—like adjusting the backbone network or tweaking hyperparameters—can make a big difference in accuracy.
 Full-Stack Developer, Penfriend
Full-Stack Developer, Penfriend
Future Trends in Instance Segmentation
Instance segmentation continues to evolve, with advancements in AI and hardware shaping its future applications. Here are the key trends:
Transformer-Based Models
Transformer architectures like DETR are improving segmentation accuracy by capturing long-range dependencies. These models are particularly effective for complex scenes and large-scale tasks.
Real-Time Processing
Lightweight models like YOLACT are being developed to enable real-time instance segmentation. This makes on-device applications and immediate decision-making more practical.
Hybrid Models
Combining instance segmentation with semantic and panoptic segmentation is creating models that offer better contextual understanding. This hybrid approach is valuable in fields like autonomous driving and robotics.
Scalable Data Annotation
Semi-automated and collaborative annotation tools are helping reduce the time and costs associated with labeling data for instance segmentation. This makes training large datasets more efficient.
Sustainability in AI
Optimizing models for lower energy consumption is becoming a priority, aligning with the push for environmentally sustainable AI practices.
Expanded Industry Adoption
Instance segmentation is seeing growing use in industries like retail, logistics, and energy. This expansion is opening up new opportunities for automation and advanced analytics.While instance segmentation is becoming more accessible, data annotation pricing remains a challenge for many organizations—our free pilot can help you get started without upfront costs.
About Label Your Data
If you choose to delegate data annotation, run a free pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is meant by instance segmentation?
Instance segmentation is a computer vision technique that identifies and separates individual objects in an image, labeling each pixel that belongs to a specific object. It combines object detection and pixel-level precision to provide detailed segmentation for each instance.
What is the difference between semantic and instance segmentation?
Semantic segmentation labels every pixel in an image by class (e.g., all pixels belonging to “cars” or “trees”), but it doesn’t differentiate between multiple objects of the same class. Instance segmentation, on the other hand, identifies and separates individual objects, even if they belong to the same class. Here’s how you can understand the difference between instance vs semantic segmentation.
What best describes instance segmentation?
Instance segmentation is a method that detects objects in an image and outlines their precise boundaries at the pixel level. It not only identifies the object’s class but also distinguishes between different instances of the same class.
What is the difference instance and semantic segmentation?
The difference between semantic vs instance segmentation lies in the fact that the latter focuses on identifying and labeling each object separately, providing a unique segmentation for each instance. Semantic segmentation classifies all pixels into categories but doesn’t distinguish between individual objects within a category.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.