Unlabeled Data: How to Use It in Machine Learning

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- What Is Labeled and Unlabeled Data in Machine Learning?
- Understanding Labeled vs. Unlabeled Data in Machine Learning
- Unsupervised Machine Learning: Why Use Unlabeled Data?
- Semi-Supervised Machine Learning: When You Have Both Labeled and Unlabeled Data
- What to Do with All That Unlabeled Data on Your Hands
- About Label Your Data
- FAQ

TL;DR
- Labeled data drives supervised learning, while unlabeled data is suited for unsupervised approaches.
- Unlabeled data enables pattern recognition, clustering, and data exploration without annotations.
- Semi-supervised learning leverages small labeled sets with large unlabeled ones to boost training efficiency.
- Reinforcement learning uses reward-based feedback, applying it to tasks like robotics and gaming.
- High-quality annotation enhances ML performance, turning raw unlabeled data into valuable assets.
What Is Labeled and Unlabeled Data in Machine Learning?

Machine learning is the hottest trend of our tech-savvy age. You can see its application everywhere you look, from image recognition technology to complex business forecasting models. However, we are mostly dealing with the labeled data, the expensive and complex type. Labeled data is essential for supervised machine learning tasks, from standard classification to advanced models like LLM fine-tuning.
But what about machine learning without labeled data? Can unlabeled data be used here? The short answer to this question is: yes! Unlabeled data can be successfully used in ML even though its scope of use is relatively smaller, and commonly requires further data annotation of the data or part of the elements to have labels. Still, unlabeled data is an effective and useful tool for developing your AI.
Understanding Labeled vs. Unlabeled Data in Machine Learning
You can read our detailed article where we’ve explored what is labeled data in machine learning and how it works. After that, you can continue exploring this piece, where we’ll focus more on the unlabeled data. This way, you can get a clear picture of labeled and unlabeled data in ML.
What is unlabeled data, exactly? Techopedia defines it as ‘pieces of data that have not been tagged with labels identifying characteristics, properties, or classifications’. Unlabeled data has no labels or targets to predict, only features to represent them. Think of a list of emails without tags that mark them as ‘spam’ or ‘not spam’. Or a set of images without identifiers like ‘people’, ‘cars’, ‘animals’, etc. So, unlabeled data is basically raw data that has not been annotated by human experts.
However, unlabeled data can be quite effective for machine learning. It is mostly used for unsupervised learning (aka exploratory data analysis). Similarly, labeled data allows supervised learning, where label information about data points supervises any given task.
Let’s look closer into the crucial difference between labeled and unlabeled data in machine learning. The list of differences provided is not exhaustive but gives the most essential points of distinction.
Battle of Annotation: Labeled vs Unlabeled Data
| UNLABELED DATA | LABELED DATA |
| Used in unsupervised machine learning | Used in supervised machine learning |
| Obtained by observing and collecting | Needs human/expert to annotate |
| Comparatively easy to get and store | Expensive, hard and time-consuming to get and store |
| Often used to preprocess datasets | Used for complex predicting tasks |
Okay, great. There is unsupervised machine learning, and then there is supervised. These large domains help us better understand the complex issue of labeled data vs. unlabeled data in ML. But what does this all mean, and how does it apply to your business?
Main Types of Machine Learning Models
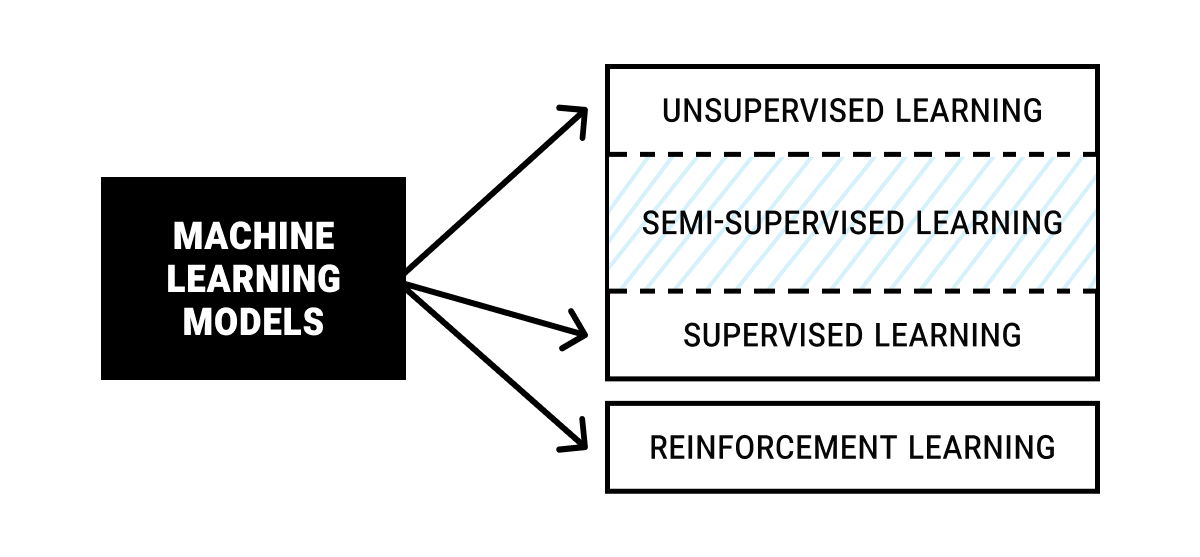
AI can be used to solve a variety of problems, from predicting housing market prices to playing (and winning!) games such as chess or go. But these problems don’t seem similar at all. That’s why it’s useful to group similar models of machine learning based on the type of tasks they need to solve.
Unsupervised Machine Learning
Unsupervised learning (UL) is a machine learning algorithm that works with datasets without labeled responses. It is most commonly used to find hidden patterns in large unlabeled datasets through cluster analysis. A good example would be grouping customers by their purchasing habits.
Supervised Machine Learning
Unlike unsupervised, supervised learning (SL) has both input data and output variables, which means that the data is annotated and there is also a prediction goal. This is the most used ML approach due to its high practical value. A few examples of supervised learning are recommendations of purchases for the customers, prediction of stock market risks, weather forecasts, etc.
Semi-Supervised Machine Learning
Not exactly a separate type but a mixture of the previous two, the models that combine labeled and unlabeled data are widely popular today. These models use unlabeled data, with only certain data points annotated. This is very useful for self-training and co-training, which can be used to annotate unlabeled data. Let’s say you have a dataset of photographs with only some images bearing labels (e.g. car, person, house). In semi-supervised learning (don’t confuse with self-supervised aka SSL, where a human annotator is eliminated altogether), you use these labeled images to train AI to later make accurate predictions for the rest of the photos.
Reinforcement Machine Learning
Reinforcement learning has no data at all, only the environment and an agent with a goal. A set of punishments and rewards are used to guide the agent to the desired outcome. Cases of use include playing games like chess or Go, teaching warehouse robots, navigating self-driving cars around the city, etc.
Any data starts its life cycle as unlabeled: you need data collection services to get the right data in the form of photos, video, audio, or text. Then it undergoes the process of annotation, where human input adds labels to data points through data tagging services. This is what creates a truly valuable dataset!
Yet while it might seem that labeled data vs. unlabeled data implies superiority in every aspect for the former, don’t rush with the annotation! Sometimes, you might need professional additional services to process your labeled data before the annotation process. For example, you might need model verification, KYC, or data anonymization.
In case with unlabeled data, let’s see what you can do with what you already have instead of moving straight to the annotation stage.
Have a project in mind and look for a trusted partner in AI? Run free annotation pilot!
Unsupervised Machine Learning: Why Use Unlabeled Data?
The unsupervised machine learning models do not have any target to predict but still can be quite useful for developing your AI. Unsupervised learning algorithms are used for unlabeled data classification, to group separate cases based on similar characteristics, as well as naturally occurring patterns in the data. Thus, unsupervised learning is naturally used as a preprocessing step before annotating the data.
Another crucial point in analyzing labeled vs. unlabeled data is that the latter has a big advantage in ML. Unlabeled data is cheap and comparatively easy to get. You don’t need to invest time and resources into human annotators who will label the data. You don’t need fancy storage to keep the data protected. What you need is to know how to use the unlabeled data you already have.
There are two main methods of unsupervised machine learning: clustering and dimensionality reduction. Let’s look into both of them to understand what we gain by using unlabeled data.
Clustering: Similar Elements Belong Together
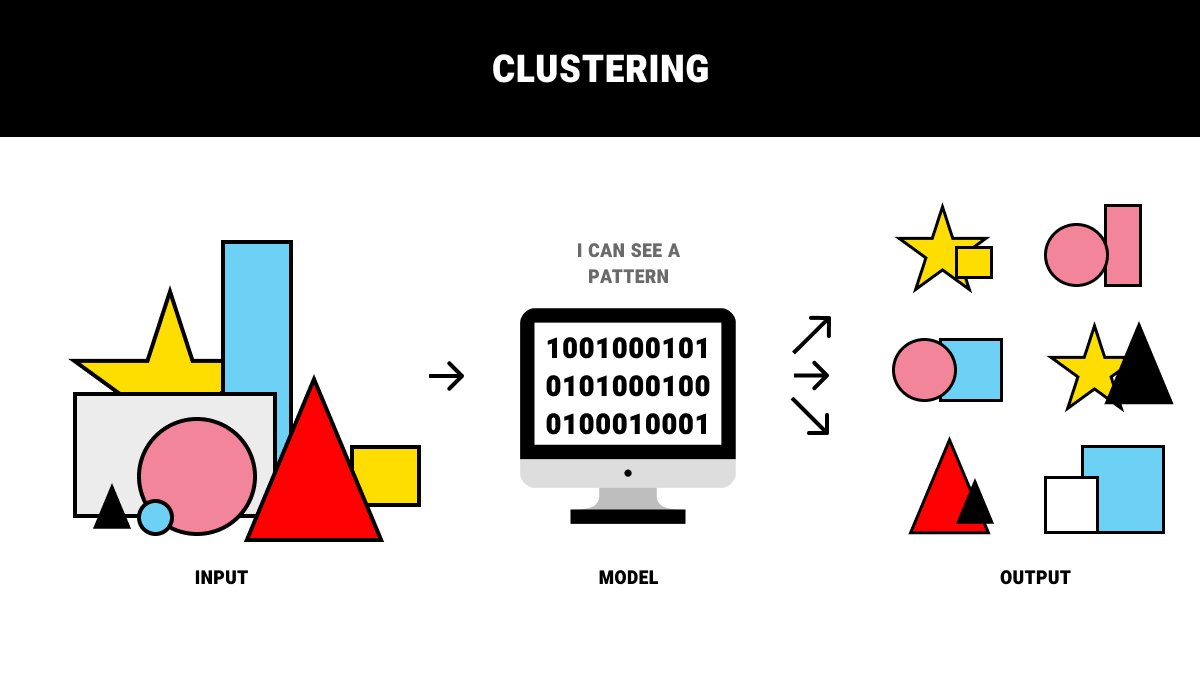
This method is the most commonly used in unsupervised machine learning. Its basic idea is to group elements based on their similarity. Machine learning models can evaluate and group similar elements even without the labels.
Now, it’s all good in theory but what about practice? Here’s an example of using clustering in machine learning. Let’s say that you have a list of 100.000 subscription emails. They have no labels so you use clustering to group them by the number of recipients and the frequency of response activity. This will give you several groups that you can later use to prioritize one or several of them and readjust your mailing strategy. Sounds pretty useful, doesn't it?
Dimensionality Reduction: Combine and Simplify Unlabeled Data
This method of unsupervised machine learning (also known as an association method) is used to simplify the sets of unlabeled data by describing its elements with fewer, more general features. It allows decreasing the number of features while losing as little valuable information as possible.
Let’s take that same dataset of 100,000 emails from the previous example. They have the following features:
- Recipients in Northern America
- Recipients in Europe
- Recipients in Asia
- Clicking update links in the emails
- Renewing subscription to your product
- Sending feedback on new features
You can already see where this is going, can’t you? Dimensionality reduction decreases six features into two: the number of recipients (globally) and the frequency of response activity.
You can use such simplification for its own merits, or as a step that prepares your unlabeled data for further processing in machine learning.
Semi-Supervised Machine Learning: When You Have Both Labeled and Unlabeled Data
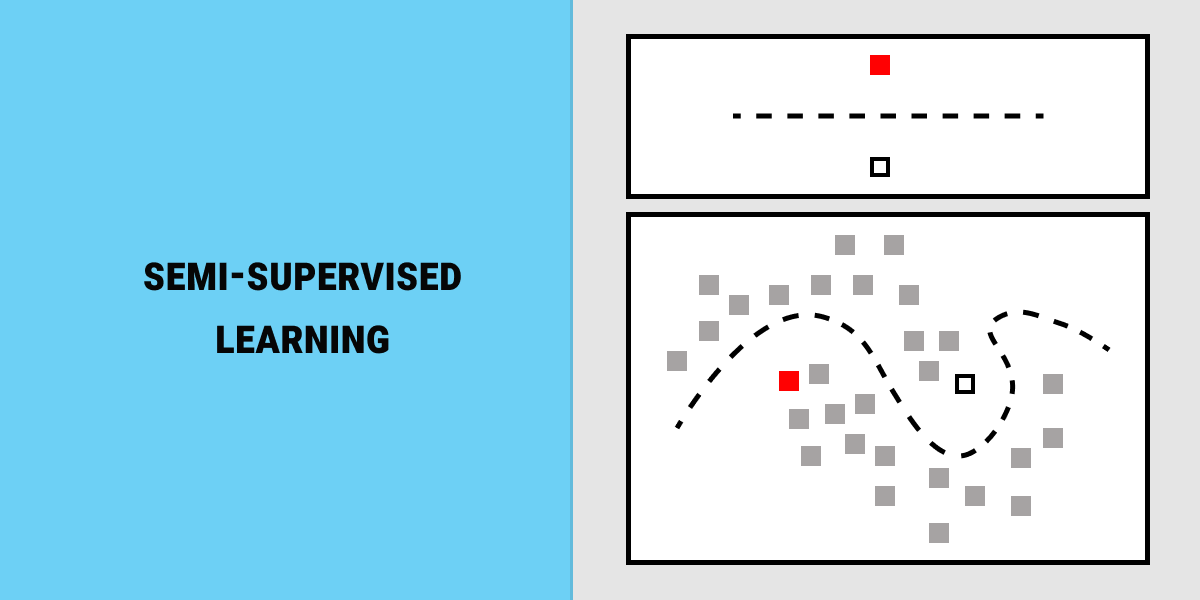
Now, let’s say you have both types, labeled data and unlabeled data. For example, out of the large dataset of emails, only 10% is labeled as either ‘spam’ or ‘not spam’. What do you do next? Annotating every email will take away a part of your valuable resources and time, as it’s one of the most pressing data labeling challenges. Instead, you can use the machine learning algorithms that combine both types of data.
Semi-supervised machine learning has gained a lot of appreciation in recent years. In fact, it is so efficient that it can well become the future of image and video classification. There are a lot of considerations that add to the value of semi-supervised learning. Getting data is a challenge. In certain specialized environments, data can be highly protected or lack consistency. Moreover, even the collected data may be unreliable, biased, or inefficient. Besides, the inflow of unlabeled data can come in larger volumes than your annotation crew can handle. For such cases, combining the learning programs for both labeled and unlabeled data can be your most efficient strategy.
How does it work? So you have a dataset of 100,000 emails, but only 10,000 of them are labeled. You don’t need to annotate the rest; instead, use the labeled elements to train your AI. After this, you can use the expectation-maximization machine learning algorithm to automate the process of annotation for the whole set of unlabeled data. This way, you get the unique combination of predictive and descriptive algorithms from supervised and unsupervised learning, respectively.
Tip: if none of your data is labeled, you can use the same mechanism. Label a small sample, train your AI, then maximize this process to the rest of the emails.
What about the practical use cases? Both labeled vs. unlabeled data have their weak spots. In unsupervised ML they include limited tasks and inability to predict, while in supervised learning the main vulnerabilities are the time and expenses required. However, semi-supervised machine learning is already used ubiquitously for modern AI development.
Enhanced clustering and detection of anomalies are just a couple of real-life use cases that semi-supervised learning can support. And here’s another one that elaborated on traditional machine learning frameworks: SGANs.
Semi-Supervised GANs
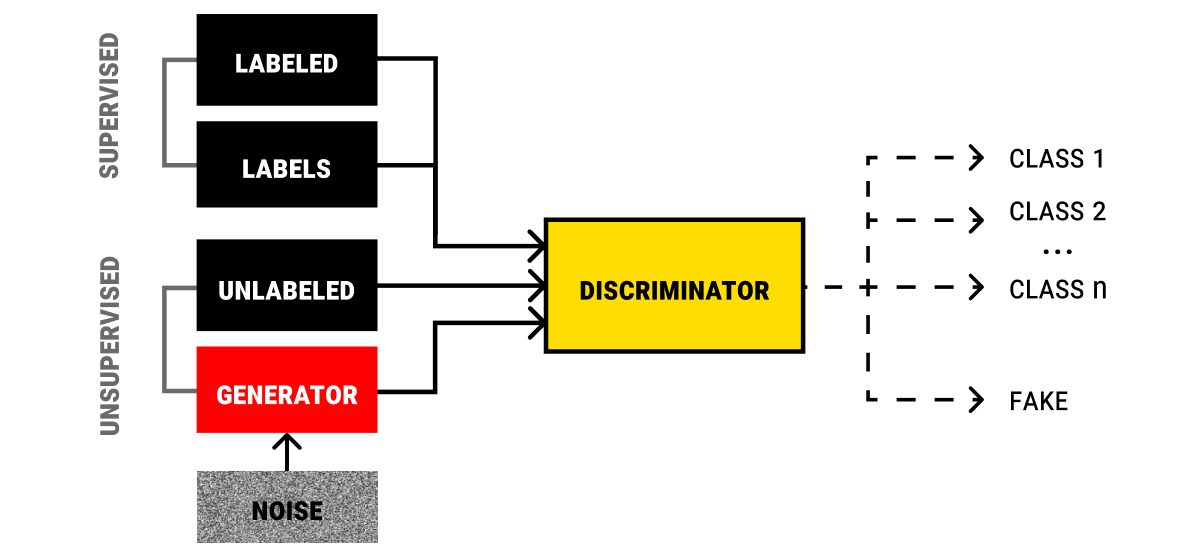
Traditionally, a GAN (Generative Adversarial Network) is used in unsupervised learning to detect fake (auto-generated) elements in a set of unlabeled data. With SGANs (short for semi-supervised GANs), the scope of tasks and the efficiency of the algorithms is increased as it includes not only unlabeled data but also supervised tasks that involve labels. This way, SGANs simultaneously work in two modes: unsupervised using unlabeled data for detecting fake elements and supervised for classification purposes.
By way of illustration, let’s look back at that imaginary dataset of 100,000 emails you have. Within the scope of unsupervised machine learning, a GAN will generate fake but seemingly authentic emails. However, semi-supervised GANs can additionally classify the emails into the given classes (like ‘spam’, ‘not spam’, ‘personal’, ‘promotions’, etc.). This way, the efficiency of such a model is much greater compared to a traditional GAN that uses only unlabeled data and is built to identify fake vs real emails.
Adversarial Training with Unlabeled Data: Machine Learning Against Deception

And now for another useful application of semi-supervised learning: adversarial training. It is used to train AI models by introducing deceptive input elements (such as adding noise to a photo). This method of machine learning is effective for creating more secure AI. Specifically, this involves detecting noise, simulating threats and attacks, as well as designing countermeasures.
Semi-supervised learning provides a great basis for adversarial training since it works with unlabeled data, as well. It does not require labels but identifies the probability for each element to contain the specific label. For the elements with labels, we define a new label. For example, in an email, we identify the label as 40% spam, 30% promotions, 10% personal email. For the unlabeled data, the model predicts the labels before the deceptive element tries to maximize the discrepancy between the predicted and correct labels. This way, the unlabeled data is used in machine learning to develop reliable AI when you don’t have sufficient labeled data.
What to Do with All That Unlabeled Data on Your Hands
Let’s now summarize what we know about the distinction between labeled data and unlabeled data in machine learning, as well as their uses.
Obviously, supervised learning is the most flexible and efficient type of ML (coincidentally, that's what we do best ;) ). However, labeled data is expensive to get and keep. Besides, you can still do a lot for machine learning with unlabeled data pieces. Here are your options:
- Use the algorithms of unsupervised learning to simplify your unlabeled data or group it in accordance to your goals. Principles of unsupervised machine learning can be used even for the labeled datasets to preprocess them before supervised learning begins.
- Combine the elements of unsupervised and supervised learning in a semi-supervised learning model. This approach will train your AI to maximize the annotation process from the small sample onto a large set of unlabeled data, saving your resources and time while developing a more secure and robust AI.
Naturally, you will still need annotated data to get the best results. Now that your unlabeled data is simplified and fine-tuned to your specific goals, you can start annotating it. And when this time comes, we will help you with the labeling process, whether you need it for all of your unlabeled data or just a small sample of it.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What is an example of unlabelled data?
Unlabeled data refers to raw data that hasn’t been tagged with labels or categories. For instance, imagine a large collection of images with no descriptions—such as photos of various animals without any labels identifying them as "cat," "dog," etc. The data is there, but it’s up to the algorithm to find patterns without any guidance.
What is labeled vs unlabeled data?
Labeled data is data that has been tagged with information to identify characteristics, like assigning a label "spam" or "not spam" to emails. Unlabeled data, on the other hand, lacks these tags and is often used to discover patterns or groupings within the data without predefined categories.
What does unsupervised learning do with unlabeled data?
Unsupervised learning algorithms analyze unlabeled data to uncover hidden patterns or group similar items together. Techniques like clustering group similar data points, helping to reveal structures and relationships within the data without needing prior labels.
Which type of machine learning is used for unlabeled data sets?
Unsupervised learning is primarily used for working with unlabeled data. It allows the model to explore the data's natural patterns or clusters, which can be helpful in areas like customer segmentation, anomaly detection, and data preprocessing.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.