Data Collection Methods: Choose the Right Approach

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents

TL;DR
- Choosing the right data collection method is the foundation of any successful ML pipeline.
- Both qualitative (interviews, observations) and quantitative data collection methods (sensors, APIs, surveys) play a role, depending on your use case.
- The process involves acquisition, augmentation, generation, preprocessing, and data labeling; each step impacts model performance.
- Poor data collection leads to bias, missing values, or imbalance, which can limit the model’s ability to generalize.
- In applied data collection methods in research, quality, consistency, and relevance of data are just as important as volume.
Where Data Collection Fits into ML Workflows
Machine learning starts with data. But for this data to work, several processes must be carried out. One of them is data collection.
Simply put, data collection is the process of gathering data relevant to your AI project’s goals and objectives. You eventually obtain a dataset, which is essentially your collection of data, all set to be trained and fed into an ML model. How hard can it be?
As simple as it may seem at first, data collection is in fact the first and most fundamental step in the machine learning pipeline. It’s part of the complex data processing phase within an ML lifecycle. From this comes another important point: data collection directly impacts the performance of an ML model and the final results. But let’s talk about everything in order.
Data Collection in the ML Pipeline
Here’s a detailed machine learning framework, which shows the role of data collection in the entire pipeline:
- Defining the project’s goal
- ML problem statement
- Data processing (data collection, data preprocessing, feature engineering)
- Model development (training, tuning, evaluation)
- Model deployment (inference, prediction)
- Tracking the performance of an ML model

While data collection methods in research vary widely, in machine learning projects, the choice between qualitative data collection methods and quantitative data collection methods depends on your use case and the type of insights your model needs to generate.
Improper data collection methods become a significant barrier to efficient machine learning. Hence, data collection has recently become a hotly debated issue in the global tech community for primarily two reasons. The first reason is that as machine learning is employed more often, we are witnessing new applications that may not have enough labeled data. Second, deep learning algorithms, unlike conventional ML techniques, automatically produce features, saving on feature engineering expenses but potentially requiring more annotated data.
Why Poor Data Collection Methods Slow Down ML
However, the accuracy of the predictions or recommendations produced by ML systems depends on the training data. Yet, several issues might occur during ML data collection that affect the accuracy rate:
- Bias. Since humans who construct ML models are prone to bias, data bias is very difficult to prevent and eliminate.
- Inaccurate data. The gathered data might not be relevant to the ML problem statement.
- Missing data. For some classes of prediction, missing data can represent empty values in columns or missing images.
- Data imbalance. Some groups may be over- or underrepresented, which can skew model performance and reduce fairness.
Learning about data collection methods is crucial to understanding how to create a dataset and gaining a deeper knowledge of machine learning overall. Having quality data on hand guarantees success with any task in ML.
With that said, let’s get straight to data collection!
Data Collection Methods for Machine Learning Explained

At this point, it makes sense to recall a good old principle in ML: garbage in, garbage out, which means a machine is said to learn exactly what it’s taught. More specifically, feeding your model with poor and low-quality data won’t produce any decent results, regardless of how sophisticated your model is, how skilled a data scientist is, or how much money you’ve spent on a project.
AI systems need data just as much as living things need air to function properly, which is why massive volumes of both structured and unstructured data enabled a recent boom in the practical use of machine learning. Thanks to ML, we now have excellent recommendation systems, predictive analytics, pattern recognition technology, audio-to-text transcription, and even self-driving vehicles.
Unstructured text data is used by 68% of AI developers, making it the most common type of data. With 59% utilization, tabular data is the second most common type of data.
The key actions in the data collection phase include:
- Label: Labeled data includes tags that help a model learn. If missing, it must be added manually or with automation.
- Ingest and Aggregate: Incorporating and combining data from many data sources is part of data collection in AI.
To understand the process and the main idea behind different methods of data collection, one should also figure out the basics of data acquisition, data annotation, and the improvement methods of the existing data and ML models. In addition, the combination of ML and data management for data collection constitutes a much bigger trend of big data and AI integration, creating new opportunities for data-driven businesses that learn to master this process.
Most ML workflows prioritize quantitative data collection methods (sensor readings, transaction logs, or structured survey results) since these provide measurable, model-ready inputs. However, qualitative data collection methods, like interviews or open-ended feedback, can also be useful when paired with NLP models that extract meaning from unstructured text.
We’ve prepared a brief overview of the most important types of data collection methods, which are all part of data collection in machine learning. Keep reading to find out more about what is a data collection method and some useful data collection tools (provided in brackets):
Step 1: Data Acquisition
Given that some companies have been collecting all of their data for years, there shouldn’t be any issues for them regarding data collection for machine learning. However, if you lack data, don’t despair. You can simply use a reference dataset that you can find online to complete your AI project. We have an entire article covering the most popular sources where you can find online ML datasets.
You can discover new data and share it by using three data collection methods: collaborative analysis (DataHub), web (Google Fusion Tables, CKAN, Quandl, and DataMarket), and collaborative & web (Kaggle). In addition to these platforms, there are systems designed for data retrieval, such as data lakes (Google Data Search) and web (WebTables).
Enterprise machine learning projects often rely on data from multiple sources, including legacy systems, cloud platforms, and data lakes. This is where data migration consulting becomes valuable, helping organizations transfer and validate data while maintaining quality and consistency.
A well-executed migration reduces preprocessing challenges and provides a stronger foundation for accurate machine learning outcomes.
Step 2: Data Augmentation
Begin the process of collecting your own data in the appropriate shape and format while evaluating the retrieved dataset. If that suits your needs, it might be in the same format as the reference dataset; otherwise, if the difference is significant, it might be in a different format.
Yet, if you don’t have enough sample data, you need data augmentation. Even if we were unable to find a dataset that completely matched all of our criteria but still had some basic data, we can still use it. However, we must use augmentation techniques on our dataset to expand the amount and size of samples.
Adding external data to existing datasets is another method of data collection, which makes your dataset richer. Techniques applied for data augmentation include deriving latent semantics, entity augmentation, and data integration.
Step 3: Data Generation
Another method is to create a machine learning dataset manually or automatically if there aren’t any already that can be used for training. Crowdsourcing (Amazon Mechanical Turk, an AI data collection company) is the go-to method for manual collection of the necessary pieces of data that together form the generated dataset.
If you’ve been dealing with data collection of images, you’re good for now, but what if you have tables with data but not enough data? How can we get more of it? In this particular case, we can use synthetic data generators. It’s an alternative method to automatically create synthetic datasets (using GANs). However, to employ them correctly, we must comprehend the principles and laws governing the formation of ML datasets.
We can now begin the actual machine learning, since we have all the required data.
Next Steps for Building Your Dataset
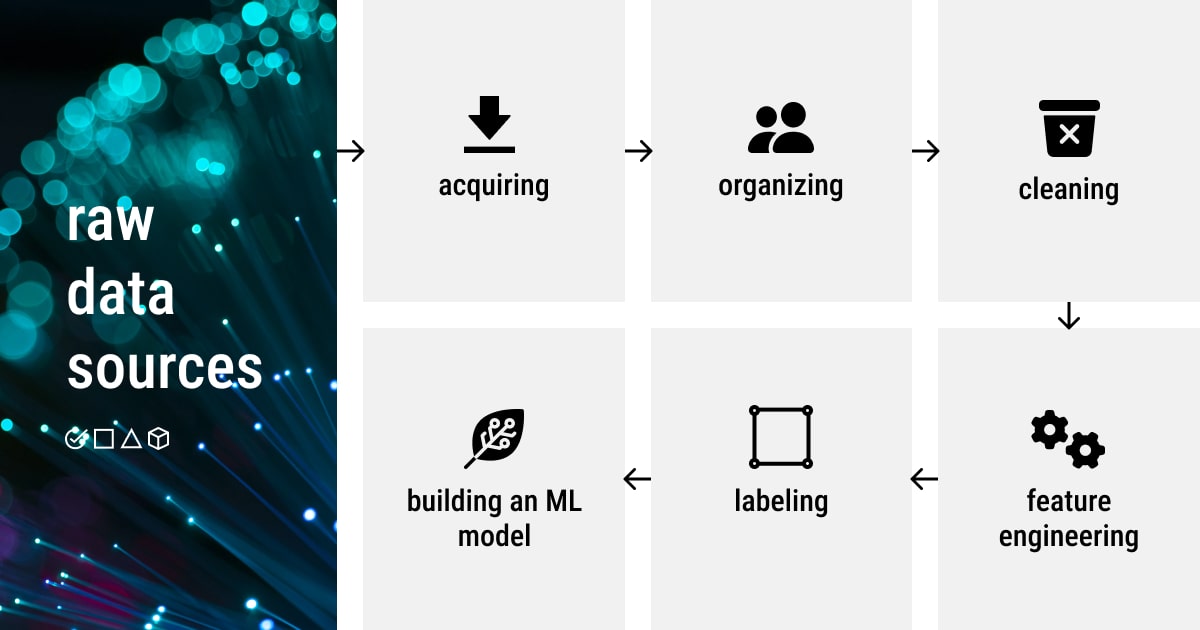
Now that we have all the necessary data, we can start doing the actual machine learning, which is extracting meaningful knowledge from data and making it readable for an ML model. Preparing data for machine learning is improving the existing data that you have to ensure that the model will generate the most accurate and trustworthy results.
The following steps that we’ll examine bring us closer to the process of creating a dataset (i.e., classification dataset) for a machine learning model and preparing it for further training, evaluation, and testing.
Step 4: Data Preprocessing
No matter where you got the dataset from, it needs to be cleaned up, filled, refined, and generally made sure you can actually get relevant information out of it before you use it to develop an ML system.
It’s necessary to preprocess the data after it has been collected to make it ready for an ML task. Data preprocessing is a broad term that encompasses many different tasks, from data formatting to feature creation. Let’s take a look at each of the processes!
Formatting
Unfortunately, we don’t live in a perfect world, where the data is already cleaned and formatted before a data scientist collects it. In a real-case scenario, the data is gathered from various sources and, thus, needs to be formatted. When working with text data, the end dataset is frequently an XLS/CSV file, an exported spreadsheet from the database, or both. If you have image data to preprocess, you must organize it into catalogs to make things simpler for ML frameworks.
Cleaning
Once the data is formatted, it can be easily fed into the model for further training. However, formatted data doesn’t mean it’s free of errors and outliers (aka anomalies) and that all data is properly arranged. The preparation of data before further preprocessing matters since the correct, accurate data has a strong impact on the outcome. This is why data cleaning (or cleansing) is a crucial activity. Data that has been added or categorized incorrectly is removed using manual and automated data cleaning processes, which also helps in dealing with missing data, duplicates, structural errors, and outliers.

Feature Engineering
This one is quite an intricate and laborious process, which consists of handling categorical data, feature scaling, dimensionality reduction, and feature selection. Besides, the key feature engineering methods applied at this stage include filter methods, wrapper methods, embedded methods, and feature creation. This basically entails the development of additional features that would enhance the model more than those that already exist. It requires different processes, including discretization, feature scaling, and data mapping to new spaces.
Pro tip: It’s the quality of the features, not their quantity, that matters for an effective machine learning model development.
Step 5: Data Labeling
Data preparation for machine learning doesn’t stop at the preprocessing stage. There’s one more task we have to accomplish, which is annotating data. Building and training a versatile and high-performing ML algorithm requires a significant amount of labeled data. Depending on the task at hand and the individual dataset in question, labels can vary for each specific dataset.
When the algorithm’s full functionality is not required, this process can be skipped. However, in the age of big data and intense competition, data annotation becomes imperative because it’s a link that enables machines to perform human activities. Data annotation, however, involves a lot of time and manual labor, which is why many companies seek out data annotation partners rather than doing it themselves.
Contact our team if you’re looking for such a partner for your AI project. Make your ML algorithm work for you with our assistance!
Beyond Data Collection Methods: Prepping Data for ML Success

AI data collection has proven to be a complex, multi-layered process of turning data into suitable and usable fuel powering machine learning models. Now that you understand how crucial correct data collection methods are, you can get the most out of the ML algorithm.
Here’s a little bonus we have for you! When collecting data, keep in mind the following points:
- Know the API’s restrictions before using a public API. One such restriction on query frequency is implemented by some APIs.
- It’s best if you have a lot of training examples (aka samples). Your model will generalize better as a result.
- Make sure there aren’t too many uneven sample numbers for each class or topic, meaning that each class should include an equal number of samples.
- Ensure that your samples sufficiently represent the range of potential inputs, and not just the typical options.
With this knowledge about primary data collection methods in mind, you are now ready to prepare any data required for your specific project in machine learning. However, if you want to save time and costs on handling this task on your own, send your data to us, and we’ll annotate your data and do all the tedious work for you!
About Label Your Data
If you choose to delegate LLM fine-tuning, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
Rely on consistent, high-quality output for complex datasets, detailed taxonomies, and edge cases.
Get quality engineered into every step through onboarding, evolving guidelines, QA, and continuous feedback.
Adjust team capacity, project size, and delivery model as you scale, with no setup fees or long-term lock-ins.
Align on goals, workflows, and expectations with a team that integrates into your process from day one.
Work with former annotators who understand annotation complexity, quality standards, and high-volume delivery.
FAQ
What are the 5 methods of data collection?
The five core types of data collection methods used in ML projects are surveys, sensor data, web scraping, API access, and manual labeling.
Surveys and forms allow structured input from users. Sensor-based data, such as LiDAR or IoT streams, captures real-world conditions. Web scraping automates information gathering from websites, while APIs provide structured datasets from third-party sources like Quandl or FRED. Finally, manual data labeling or crowdsourcing ensures accuracy for complex tasks like image or text annotation.
These methods are often combined to create robust, ML-ready datasets.
What are the 4 types of data collection?
Data collection is typically categorized into four types: observational, experimental, self-reported, and third-party.
Observational data is gathered passively, such as from camera feeds or system logs. Experimental data comes from controlled setups like A/B testing or simulations. Self-reported data includes feedback from forms or interviews. Third-party data is sourced externally, often through public datasets, APIs, or scraping services.
Each type offers different advantages depending on your ML use case and data availability.
What is a data collection method?
A data collection method refers to the process you use to gather the raw information needed to train machine learning models. This might involve collecting real-world behavior data, capturing sensor input, or retrieving structured data from online platforms. Good data collection methods ensure the resulting dataset is accurate, representative, and usable for supervised or unsupervised learning.
What are the three 3 major techniques in data collection?
The three major techniques in data collection for machine learning are manual collection, automated collection, and synthetic data generation.
Manual collection involves human effort and is often used for nuanced or subjective tasks. Automated collection uses APIs, scrapers, or sensors to gather large volumes of structured or unstructured data efficiently. Synthetic data generation, such as using GANs, fills in gaps when real data is unavailable or too costly.
Choosing the right mix of these techniques is essential for building scalable and high-performing ML models.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.